我们使用整容手术数据说明两种中心化类型。将此文件加载到SPSS中。
假设我们要中心化的变量BDI。首先,我们需要找出BDI的平均得分。我们可以使用一些简单的描述性统计信息。
数据中心化
选择进入对话框。选择BDI并将其拖到标有Variable(s)的框中,然后单击并仅选择均值。
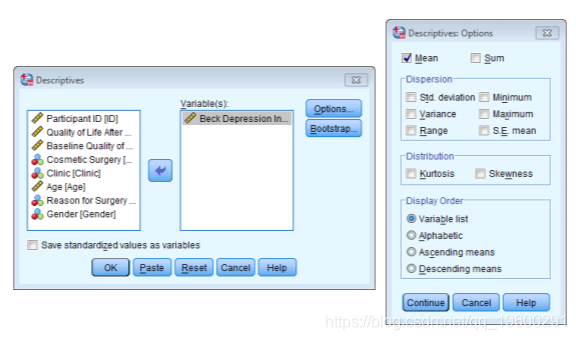
结果输出告诉我们平均值为23.05:
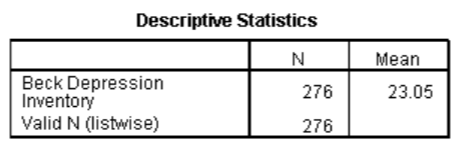
我们使用此值将变量中心化。通过选择访问计算命令。在出现的对话框中,在标有“目标变量”的框中输入名称BDI_Centred,然后单击并为变量指定一个更具描述性的名称。选择变量BDI并将其拖动到标记为Numeric Expression的区域,然后单击,然后键入平均值(23.05)。完成的对话框如图所示。
单击,将创建一个名为BDI_Centred的新变量,该变量以BDI的平均值为中心。这个新变量的均值应约为0:运行一些描述性统计数据。
可以在语法窗口中通过输入以下内容执行相同的操作:
COMPUTE BDI_Centred = BDI−23.05.
EXECUTE.组均值中心化
组均值中心化要复杂得多。第一步是创建一个包含组均值的文件。让我们再试一次以获取BDI分数。我们希望将此变量在Clinic的2级变量中中心化。我们首先需要知道每个组中的平均BDI,并以SPSS形式保存该信息。我们要使用aggregate命令。在此对话框(图3)中,我们要选择Clinic并将其拖动到标有Break Variable(s)的区域。这说明着将使用变量Clinic来分割数据文件(换句话说,当计算平均值时,它将对每个诊所分别进行处理)。然后,我们需要选择BDI并将其拖动到标记为变量汇总的区域。一旦选择了此变量,默认值就是SPSS将创建一个名为BDI_mean的新变量,这是BDI的平均值(显然是由Clinic分割)。我们需要将此信息保存在一个文件中,以便以后使用。

默认情况下,SPSS会将名称为aggr.sav的文件保存在默认目录中。如果您想将其保存在其他位置或使用其他名称,则单击以打开一个普通的文件系统对话框,可以在其中命名文件并导航至要保存在其中的目录。单击创建此新文件。
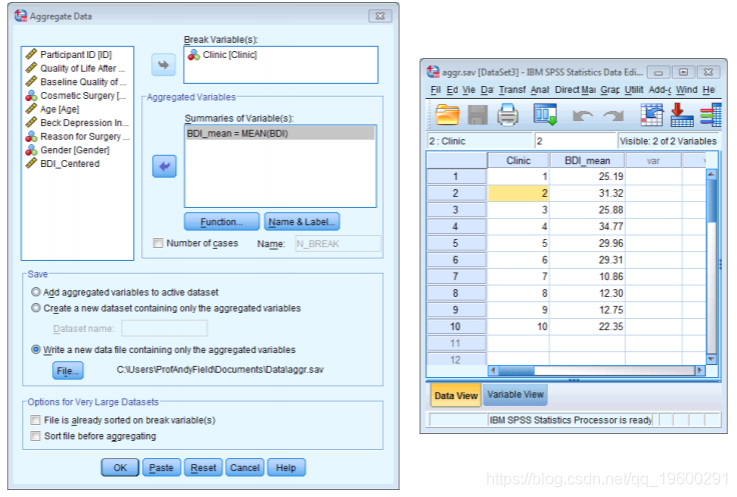
如果打开生成的数据文件,则会看到它仅包含两列,其中一列带有一个数字,用于指定数据来自的诊所(共有10个诊所),第二个包含每个诊所内的平均BDI得分。
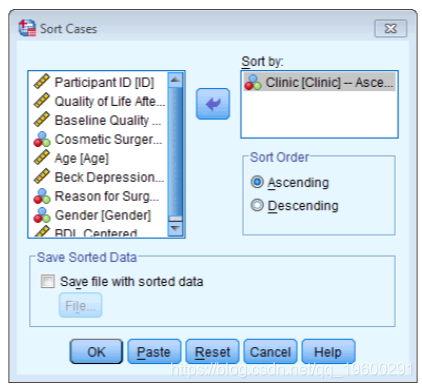
当SPSS创建汇总数据文件时,它将按从最低到最高的顺序对诊所进行排序(无论它们在数据集中的顺序如何)。因此,为了使我们的工作数据文件与该聚合文件匹配,我们需要确保从诊所1到诊所10也订购了来自各个诊所的所有数据。这可以通过使用sort cases命令轻松完成。

要访问sort cases命令,请选择select。出现的对话框如图所示。选择您要对文件进行排序的变量(在本例中为Clinic),并将其拖动到标有“排序依据”的区域(或单击)。可以选择按升序排列文件(诊所1到诊所10),或降序排列(前往诊所1的诊所10)。单击对文件排序。
下一步是在汇总文件中使用这些临床方法,以将BDI变量放在我们的主文件中。为此,我们需要使用match files命令,可以通过选择进行访问。这将打开一个对话框,其中列出了所有打开的数据文件(在我的情况下,除了我正在工作的文件之外,其他所有文件都没有打开,因此该空间为空白)或询问您选择SPSS数据文件。单击并导航到您决定存储聚合值文件的位置(在我的情况下为aggr.sav)。选择此文件,然后单击以返回到对话框。然后单击进入下一个对话框。
随时关注您喜欢的主题
在下一个对话框中,我们需要匹配两个文件,这只是告诉SPSS两个文件已连接。为此,请单击。然后,我们还需要专门连接Clinic变量上的文件。为此,select告诉SPSS无效的数据集(即,汇总分数文件)应视为与关键变量上的工作数据文件匹配的值表。我们需要选择此关键变量是什么。我们要匹配Clinic变量上的文件,因此在“排除的变量”列表中选择此变量,并将其拖到标有“关键变量”的空间(或单击)。
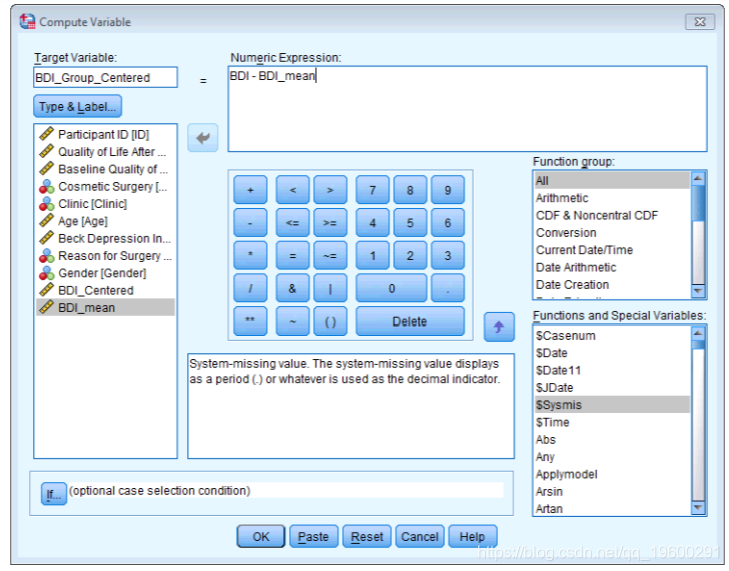
数据编辑器现在应包含一个新变量BDI\_mean,其中包含我们文件aggr.sav中的值。基本上,SPSS已匹配诊所变量的文件,因此BDI\_mean中的值对应于各个诊所的平均值。因此,当临床变量为1时,BDI\_mean已设置为25.19,但是当临床变量为2时,BDI\_mean已设置为31.32。我们可以再次在compute命令中使用这些值来使BDI中心化。通过选择访问计算命令。在出现的对话框(图7)中,在标有“目标变量”的框中输入名称BDI\_Group\_Centred,然后单击并为变量指定一个更具描述性的名称。选择变量BDI并将其拖到标有“数字表达式”的区域,然后单击,然后键入“ BDI_mean”或选择此变量并将其拖到标有“目标变量”的框中。单击,将创建一个新变量,其中包含以组为中心的均值。
另外,可以使用以下语法来完成所有操作:
AGGREGATE
/OUTFILE='C:\\Users\\Dr. Andy Field\\Documents\\Academic\\Data\\aggr.sav'
/BREAK=Clinic
/BDI_mean=MEAN(BDI).
SORT CASES BY Clinic(A).
MATCH FILES /FILE=*
/TABLE='C:\\Users\\Dr. Andy Field\\Documents\\Academic\\Data\\aggr.sav'
/BY Clinic.
EXECUTE.
COMPUTE BDI\_Group\_Centred=BDI − BDI_mean.
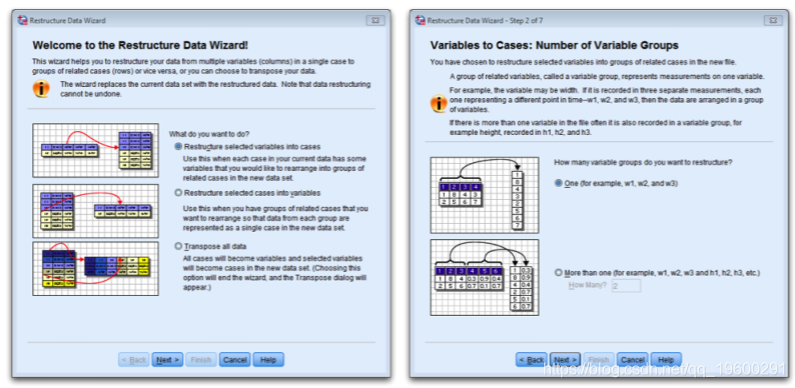
EXECUTE.要访问“重组数据向导”,请选择。向导中的步骤如图所示。在第一个对话框中,您需要说是否要将变量转换为案例,还是将案例转换为变量。我们在不同的列(变量)中具有不同的时间级别,并且希望它们在不同的行(案例)中,因此我们需要选择。
单击以移至下一个对话框。该对话框询问您是要从旧数据文件的不同列中在新数据文件中仅创建一个新变量,还是要创建多个新变量。
在我们的案例中,我们将创建一个代表生活满意度的变量。默认,SPSS在新数据文件中创建一个名为id的变量,该变量告诉您数据来自哪个样本(即原始数据文件的哪一行)。它通过使用原始数据文件中的案例编号来实现。然后从数据文件中选择一个变量以充当新数据文件中的标签。
其余对话框非常简单。接下来的两个处理索引变量。SPSS创建一个新变量,该变量将告诉你数据源自哪一列。在我们有四个时间点的情况下,这将意味着变量只是一个从1到4的数字序列。
多层(等级)线性模型
将BDI,年龄和性别包括在内作为固定效果预测指标。
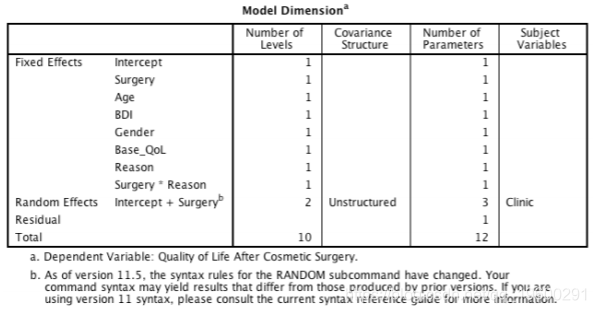
单击以移至主对话框 。首先,我们必须指定结果变量,即手术后的生活质量(QoL),因此选择Post_QoL并将其拖动到标有因变量的空间(或单击)。
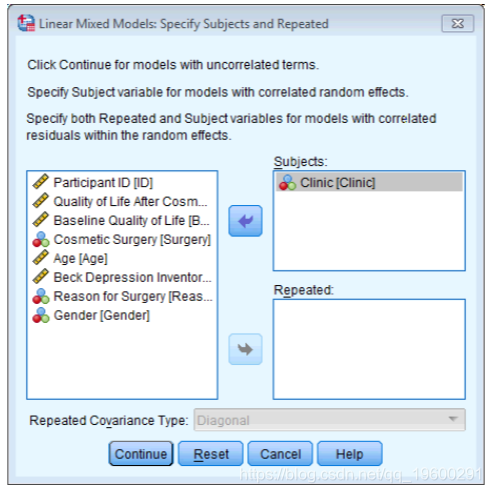
选择 ,然后通过从变量列表中选择Clinic并将其拖动到标有Subjects的框中来指定 变量(或单击)。
我们需要将预测变量作为固定效应添加到我们的模型中,因此单击,按住Ctrl并在标记为Factors和Covariates的列表中选择Base_QoL,Surgery,Age,性别,Reason和BDI。
现在,我们需要请求随机截距和随机斜率以达到手术效果。
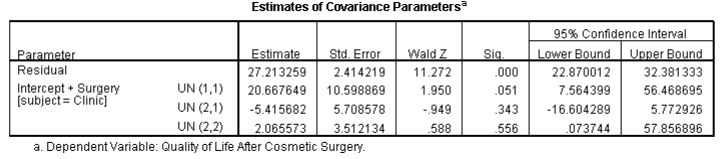
单击并选择。单击以返回到主对话框。在主对话框中,单击并请求参数估计和协方差参数的检验。单击以返回到主对话框。要运行分析。输出如下:

就此新模型的整体拟合而言,我们可以使用对数似然统计:
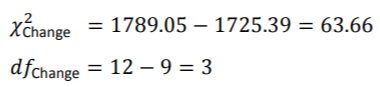
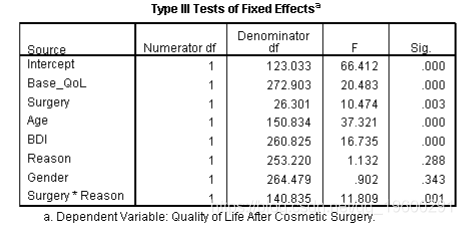
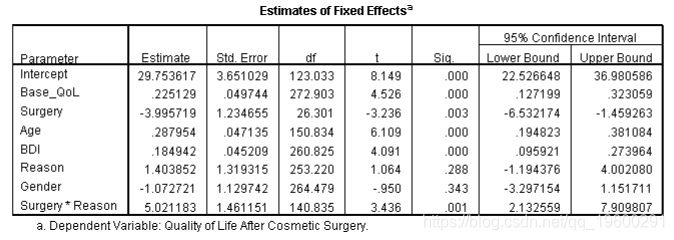
卡方统计的临界值为7.81(p <.05,df = 3);因此,这一变化意义重大。包括这三个预测变量可以改善模型的拟合度。年龄,F(1,150.83)= 37.32,p <.001,BDI,F(1,260.83)= 16.74,p <.001,显着预测了手术后的生活质量,但性别没有,F(1,264.48 )= 0.90,p = 0.34。包括这些因素的主要区别在于,Reason的主要影响变得不显着,并且Reason×Surgery交互作用变得更加重要(其b从4.22,p = .013变为5.02,p = .001)。
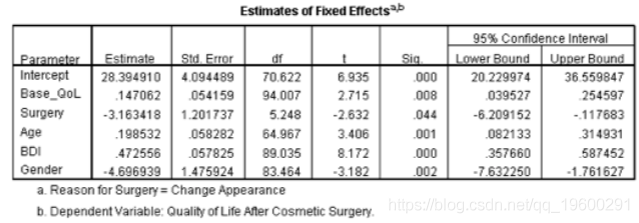
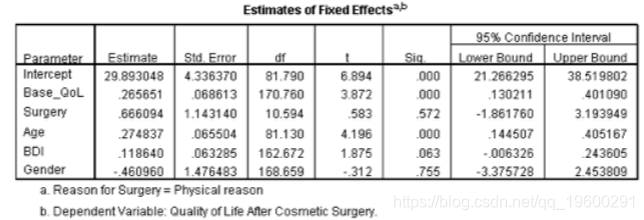
我们可以通过拆分并运行更简单的分析来分解此交互,如本文所述(没有交互和Reason的主要影响,但包括Base_QoL,Surgery,BDI,Age和Gender)。如果进行这些分析,将获得输出中所示的参数表。对于那些只为改变外观而进行手术的患者,手术显着预测了手术后的生活质量,b = –3.16,t(5.25)= –2.63,p = .04。与不包括年龄,性别和BDI的情况不同,这种影响现在很明显。负系数表明,与对照组相比,这些人的手术后生活质量较低。但是,对于那些通过手术解决身体问题的人,手术并不能显着预测生活质量,b = 0.67,t(10.59)= 0.58,p = 0.57。从本质上讲,年龄,性别和BDI的纳入对后一组几乎没有什么影响。但是,该斜率是正的,表明接受手术治疗的人的生活质量得分比等候名单上的得分高(尽管不是很明显!)。因此,相互作用的影响反映了在进行身体问题手术的患者(轻微的正斜率)和仅出于虚荣心进行手术的患者(负的斜率)中手术斜率作为生活质量预测指标的差异。
改变外貌的手术
身体问题的手术
 R软件线性模型与lmer混合效应模型对生态学龙类智力测试数据层级结构应用
R软件线性模型与lmer混合效应模型对生态学龙类智力测试数据层级结构应用 SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究
SPSS modeler关联规则、卡方模型探索北京平谷大桃产业发展与电商化研究 数据分享|spss modeler用贝叶斯网络分析糯稻品种影响因素数据可视化
数据分享|spss modeler用贝叶斯网络分析糯稻品种影响因素数据可视化 R语言分析糖尿病数据:多元线性模型、MANOVA、决策树、典型判别分析、HE图、Box’s M检验可视化
R语言分析糖尿病数据:多元线性模型、MANOVA、决策树、典型判别分析、HE图、Box’s M检验可视化

