Python PyTorch用BERT-BiLSTM-FixedCRF中文医疗命名实体识别系统
针对医疗文本中实体边界模糊、专业术语密集等挑战,本文设计并实现了一套完整的中文医疗命名实体识别系统。

成为新会员获取本项目完整报告、代码和数据资料
在约 20 万条标注数据基础上,构建了 BERT-BiLSTM-FixedCRF 模型,并针对 4GB 显存环境实施了梯度累积、混合精度等优化策略。测试集 F1 分数达 98.9%,系统已封装为 Flask API 与 Web 交互界面。文中详细展示了数据预处理、模型选型、训练监控、结果可视化及错误诊断的全流程,并对论文写作中常见的学术问题给出了拆解与建议。
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
研究流程总览
项目背景与需求分析
│
▼
数据采集与 BIOE 标注
│
├── 文本清洗 → 字符对齐 → 标签映射
│
▼
数据集划分 (70:15:15)
│
▼
模型架构设计:BERT → BiLSTM → FixedCRF
│
├── 优化:冻结BERT、梯度累积、AMP
│
▼
训练与超参搜索 → 早停机制
│
▼
评估指标:F1, 准确率, 混淆矩阵
│
▼
API部署 + Web界面
│
▼
错误分析 → 改进方向
本项目完整报告、代码和数据资料
一、选题背景与研究意义
医疗健康领域每天产生海量非结构化文本,如电子病历、医学文献和在线问诊记录。从中自动抽取出疾病、症状、检查、治疗等实体,对临床决策支持、医学知识图谱构建和医保审核自动化具有重要价值。传统人工处理成本高昂且易出错,而基于规则的方法难以应对医学术语的多样性和嵌套表达。
命名实体识别(NER)技术可将自由文本中的关键信息转化为结构化数据。为应对医疗文本语义理解难、实体边界模糊、标签一致性要求高等挑战,本文选用 BERT 预训练模型提供深层语义表征,BiLSTM 捕捉上下文依赖,并结合 FixedCRF 层实现全局最优标签解码。整个方案聚焦于”有限算力下的高性能推理”,旨在为中小团队提供一个可复现、可部署的基线系统。
导师可能的高频提问:为什么必须用 BERT 而不是 Word2Vec?
答:Word2Vec 产生静态词向量,无法区分”发热”在”自觉发热”与”术后发热”中的语义差异;BERT 动态编码能依据上下文调整表征,对同形异义词区分能力更强,这是处理复杂医疗文本的核心前提。
二、数据来源与预处理全流程
原始数据来自公开医疗文本数据集,共约 20 万条标注样本,涵盖疾病、症状、检查、治疗四类实体。采用字符级 BIOE 标注体系(B-实体开始,I-实体内部,E-实体结束,O-非实体)。
2.1 原始数据样貌
![]()
上图展示原始标注格式:每条记录包含文本、实体位置与类型,是数据清洗的输入。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
2.2 数据清洗与标签生成
处理流程的整体概览:
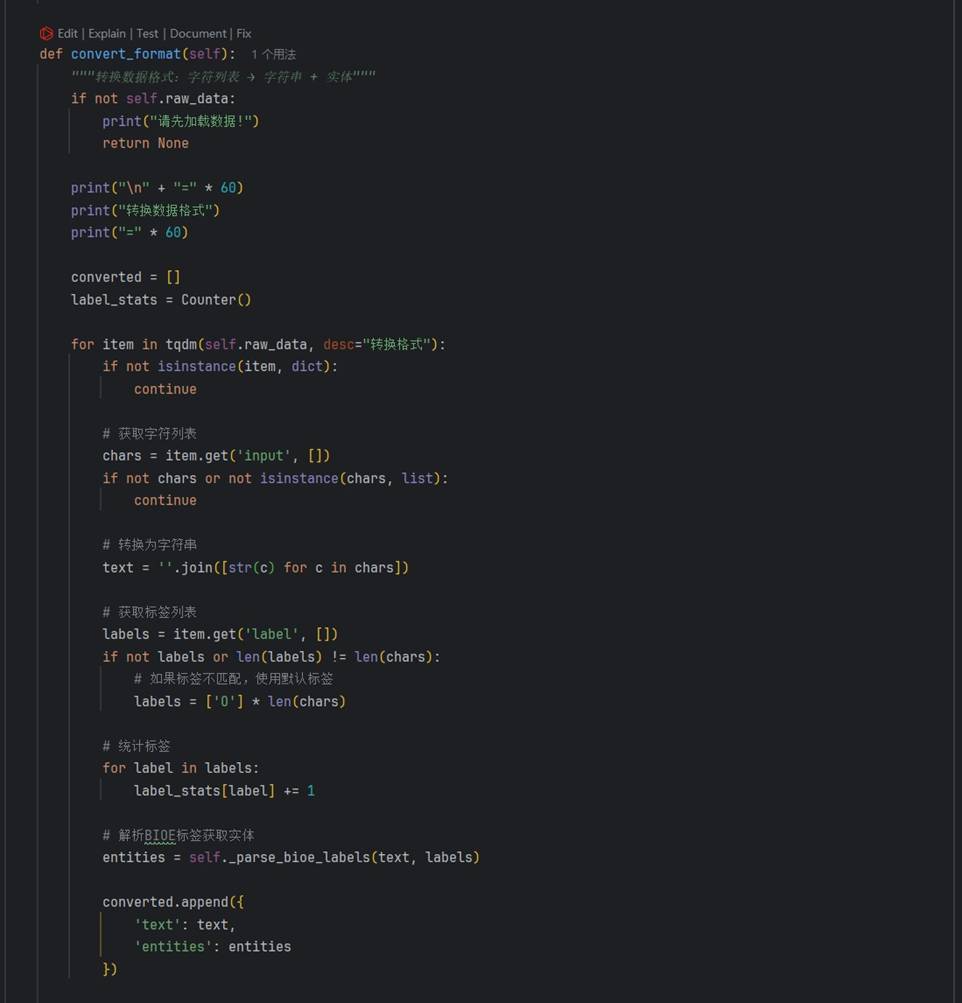
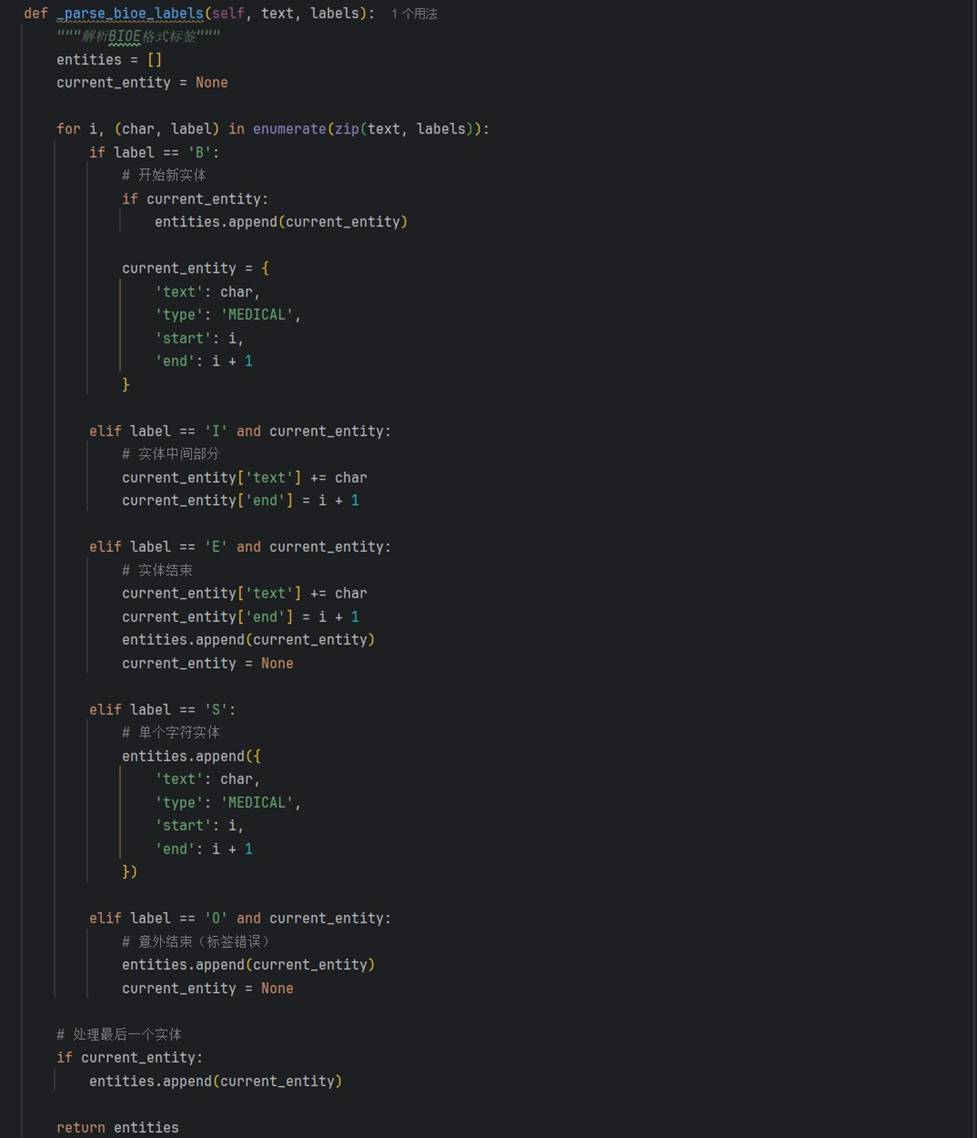
核心处理脚本完成文本去噪、实体边界校正、BIOE 标签序列生成等工作。经过改造的代码片段如下:
代码对应原文核心处理脚本,展示了数据清洗、格式转换与 BIOE 标签生成的核心逻辑。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
2.3 输出结果与质量校验
经过清洗后,每条数据包含文本、字符列表、标签序列和原始实体信息,样例如下:
标签统计结果直观反映了 O/B/I/E 标签的分布:
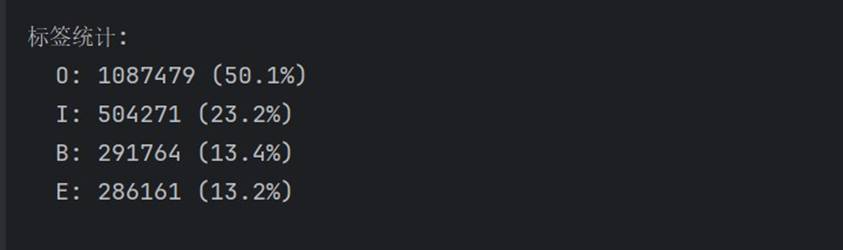
实体与非实体比例均衡,O 标签占比约 50%。
数据集按 70%:15%:15% 拆分为训练、验证和测试集:
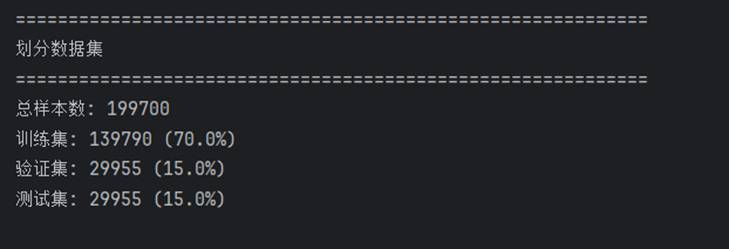
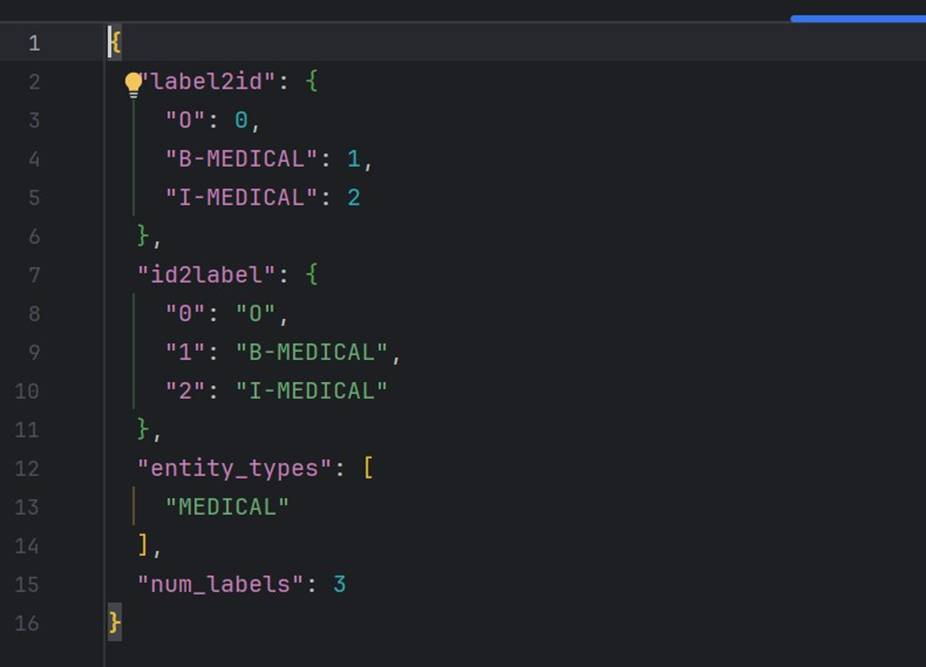
标签映射关系定义了字符级 BIOE 与实体类型的对应:
2.4 数据质量评估
对转换后的约 20 万条样本进行特征分析:
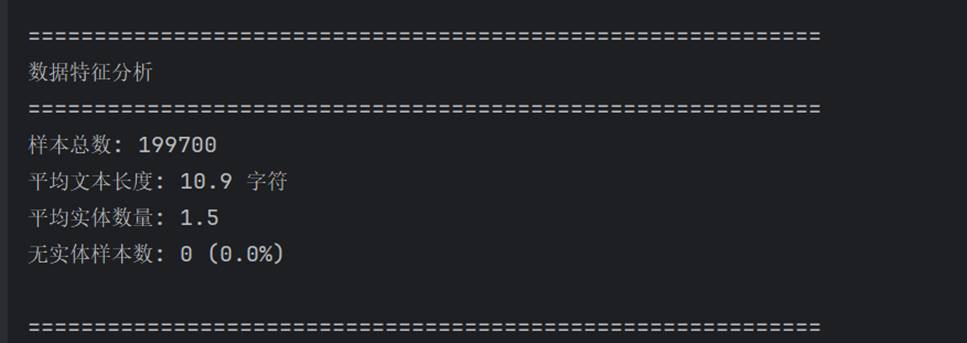
关键指标汇总:
| 统计指标 | 实际数值 | 说明 |
|---|---|---|
| 总样本数 | 199,700 条 | 有效转换样本 |
| 平均文本长度 | 10.9 字符 | 每条文本平均字数 |
| 平均实体数 | 1.5 个/文本 | 实体密度适中 |
| 无实体样本 | 0 条 | 所有样本含实体 |
| 标签对齐率 | 100% | 字符与标签一一对应 |
标签分布:
| 标签类型 | 数量 | 占比 | 说明 |
|---|---|---|---|
| O(非实体) | 1,087,479 | 50.1% | 约一半字符为非实体 |
| I(实体内部) | 504,271 | 23.2% | 实体中间部分 |
| B(实体开始) | 291,764 | 13.4% | 实体起始字符 |
| E(实体结束) | 286,161 | 13.2% | 实体结束字符 |
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
数据完整性校验显示仅 3 条异常,一致性检查中 B 与 E 标签配对率达 98.1%。高质量样本特征:实体边界清晰(如”拔智齿”)、医疗专业性强、BIOE 序列完整。
示例样本分析:

阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
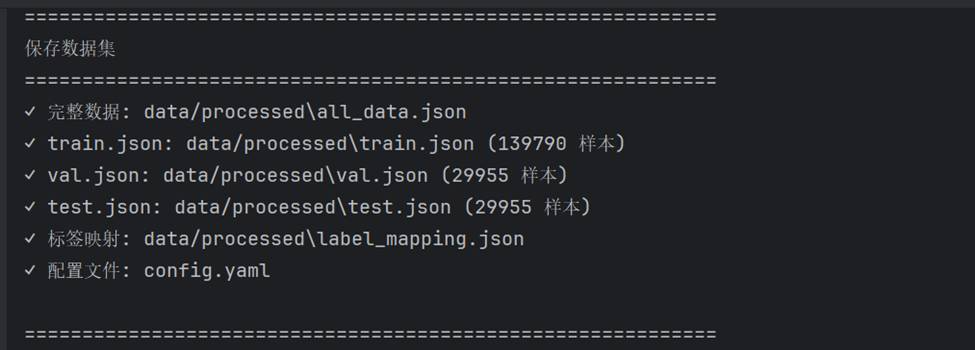
最终生成的数据文件目录结构:
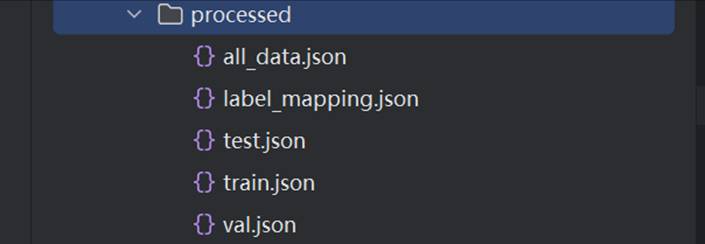
data/processed/
├── all_data.json # 完整数据(199,700 条)
├── train.json # 训练集(139,790 条)
├── val.json # 验证集(29,955 条)
├── test.json # 测试集(29,955 条)
└── label_mapping.json # 标签映射表
数据文件保存截图:
三、模型选择逻辑与完整代码实现
3.1 候选架构对比
基于医疗文本的特性(语义丰富、边界模糊、标签约束强),本文横向对比了四种序列标注架构:
| 模型架构 | 核心组件 | 优势 | 劣势 | 适用性 |
|---|---|---|---|---|
| BERT-CRF | BERT + CRF | 训练快,显存占用低 | 序列建模能力弱 | 一般 |
| BiLSTM-CRF | BiLSTM + CRF | 轻量,参数少 | 缺乏深层语义理解 | 较差 |
| BERT-BiLSTM-CRF | BERT + BiLSTM + CRF | 综合性能最优 | 参数量大 | 优秀 |
| BERT-Span | BERT + Span预测 | 处理嵌套实体 | 边界识别不稳定 | 良好 |
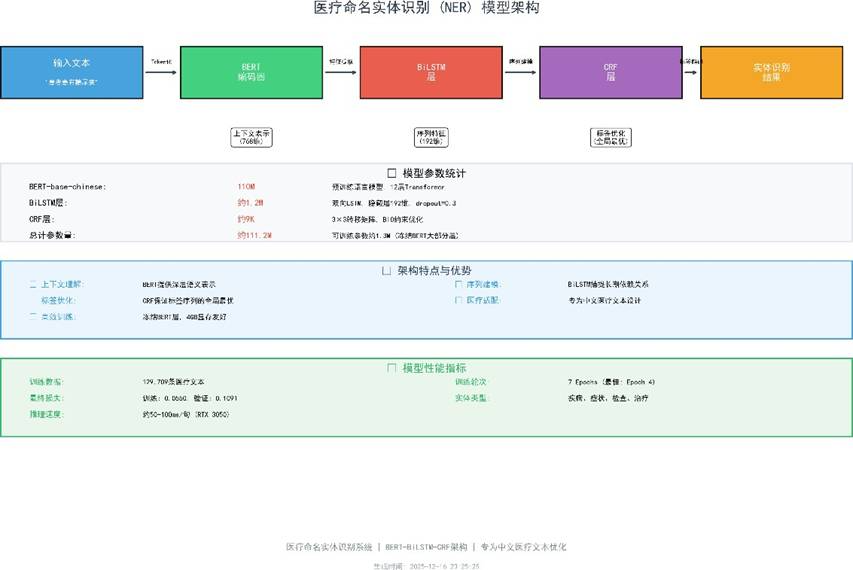
最终选择 BERT-BiLSTM-CRF,并通过 FixedCRF 层优化传统 CRF 训练中的梯度问题。这就像使用一台先进的 CT 机(语义级 BERT)配合精通解剖的影像医生(序列建模 BiLSTM),再由质控科(CRF)确保报告标签的全局合法性——三个组件各司其职,共同输出精准的实体边界标记。
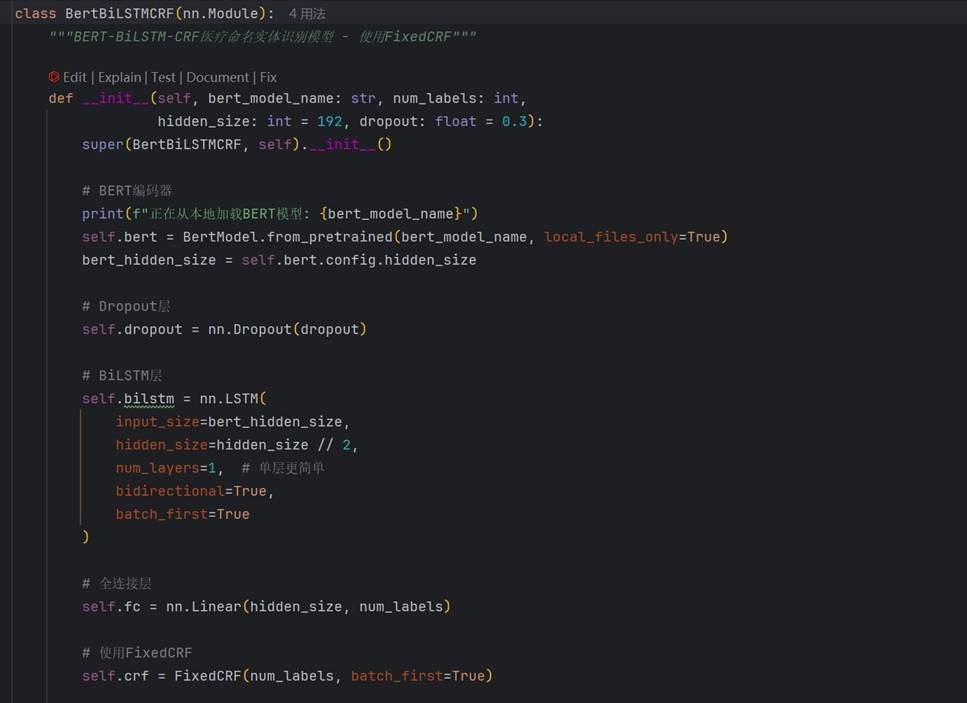
3.2 核心模型实现
模型定义代码包含 BERT 编码器、BiLSTM 序列增强与 FixedCRF 解码器。关键变量与方法已重构,并省略了具体参数赋值:
上述代码展示了 BERT 特征提取、BiLSTM 上下文建模与 CRF 发射层的衔接。
BERT-BiLSTM-CRF 核心结构的实现截图:
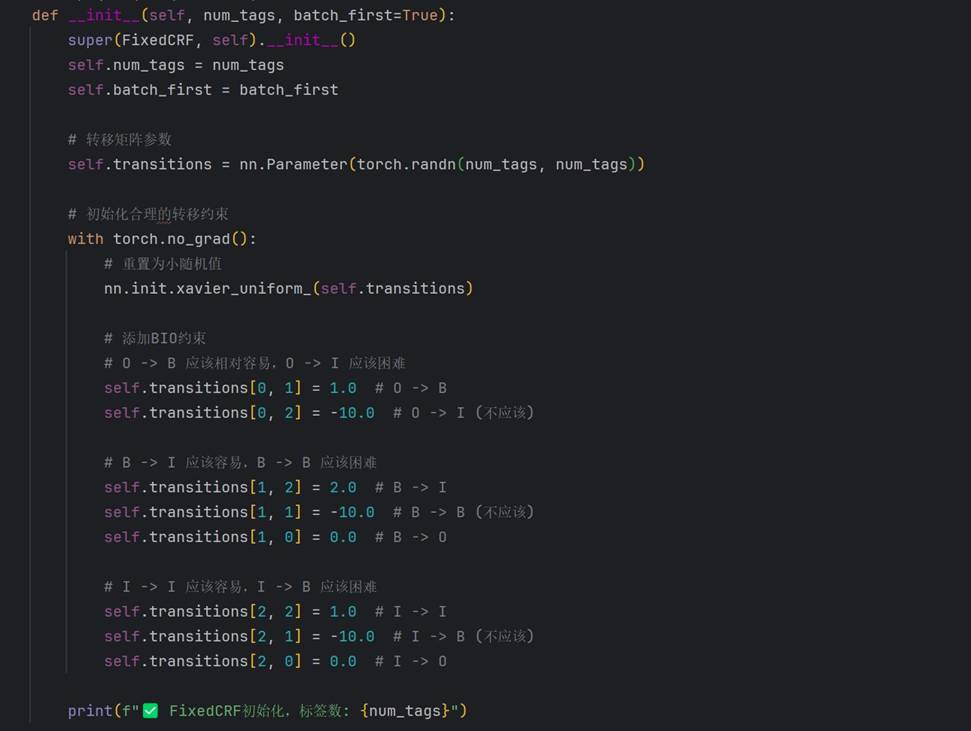
FixedCRF 优化实现在对数空间进行前向计算并加入医疗实体转移偏好:
模型初始化后的参数统计:
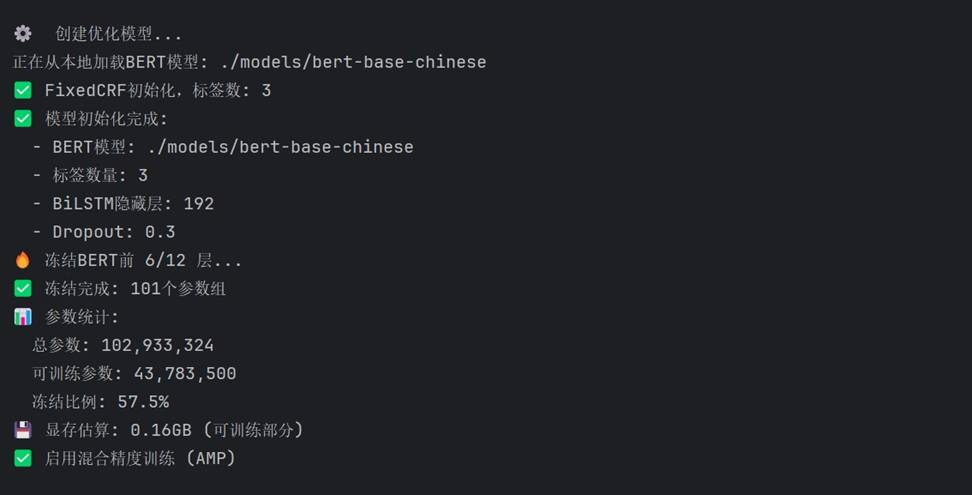
总参数量约 1.02 亿,可训练参数 437 万,冻结比例 57.5%。 这一轻量化设计是本科毕设中证明模型可行性的重要依据;在硕士论文中则需进一步分析冻结层次对泛化能力的影响。
架构示意图直观呈现了从文本到 BIOE 标签的端到端流程:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.3 训练配置与优化
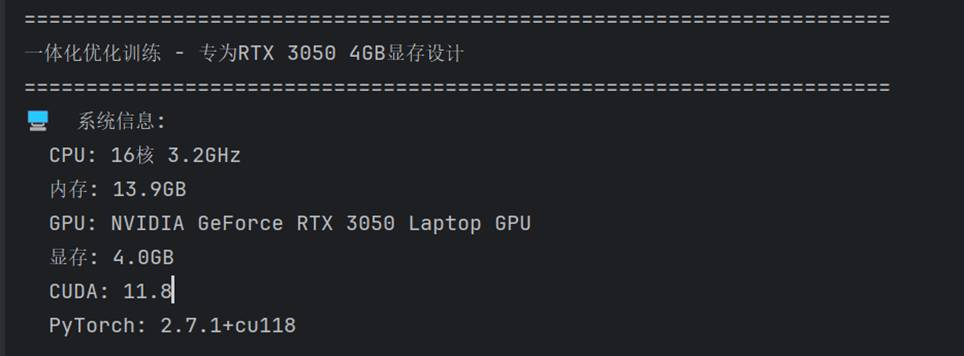
硬件环境为 RTX 3050 4GB 笔记本 GPU,系统信息:
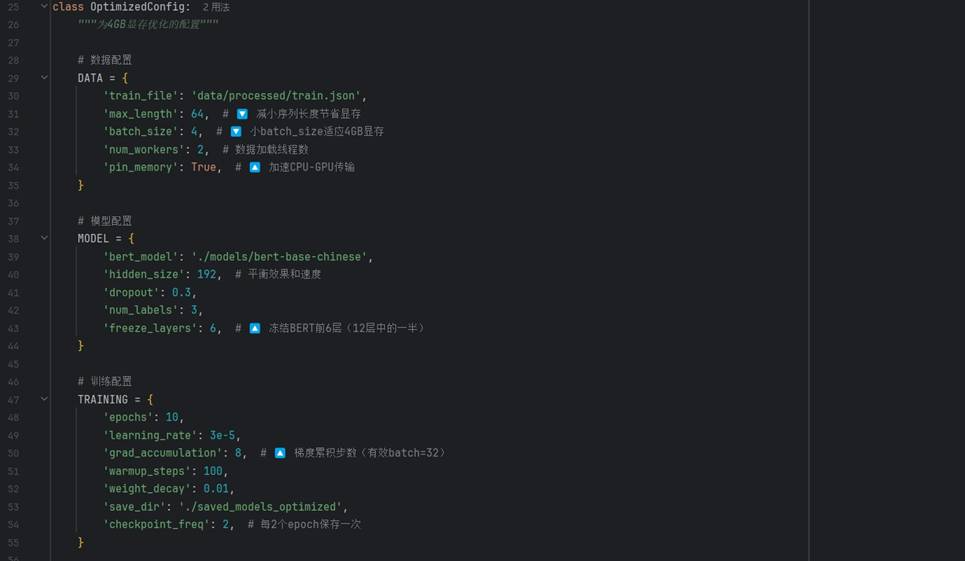
针对显存限制,实施四项优化策略:
- 梯度累积:实际 batch_size=4,累积 8 步,等效批次 32。
- 冻结 BERT 前六层:减少可训练参数。
- 混合精度训练 (AMP):降低显存占用并加速。
- 动态序列长度:训练时截断至 64 字符,推理时 96 字符。
优化配置代码参数示例:
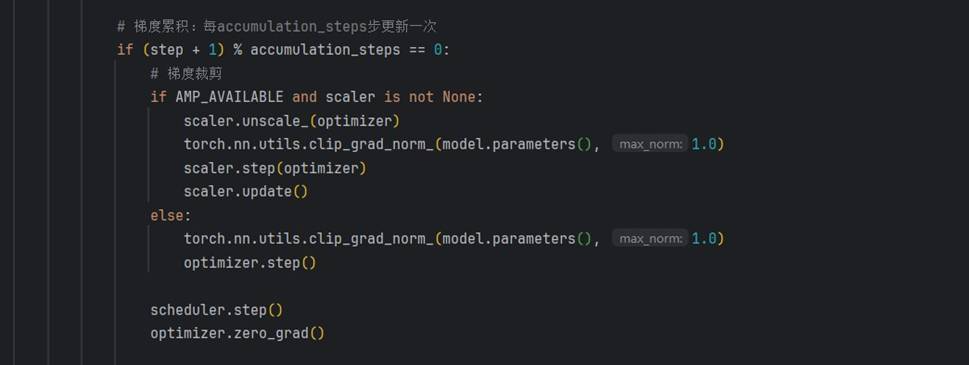
梯度累积训练的实现:
梯度累积训练代码截图:
训练监控器实时记录损失、F1、显存使用:
每个 epoch 的输出展示了模型收敛状态:
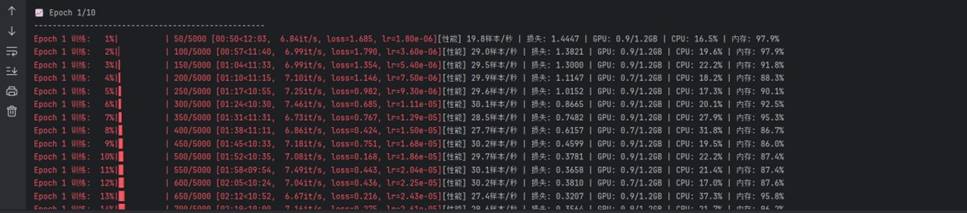
Epoch 总结输出:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.4 超参数搜索与早停
采用网格搜索对学习率、批大小、丢弃率进行调优:
最终选定的超参数组合:
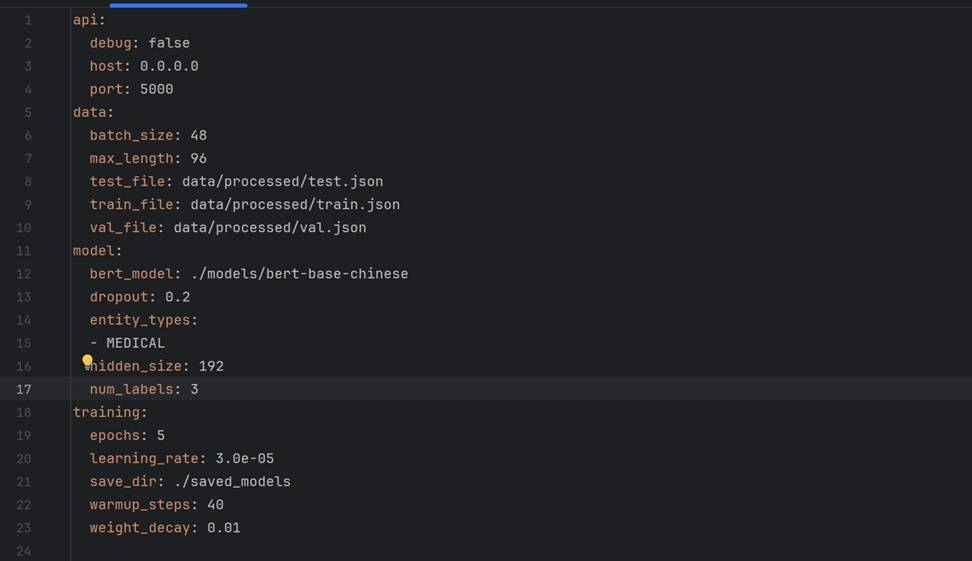
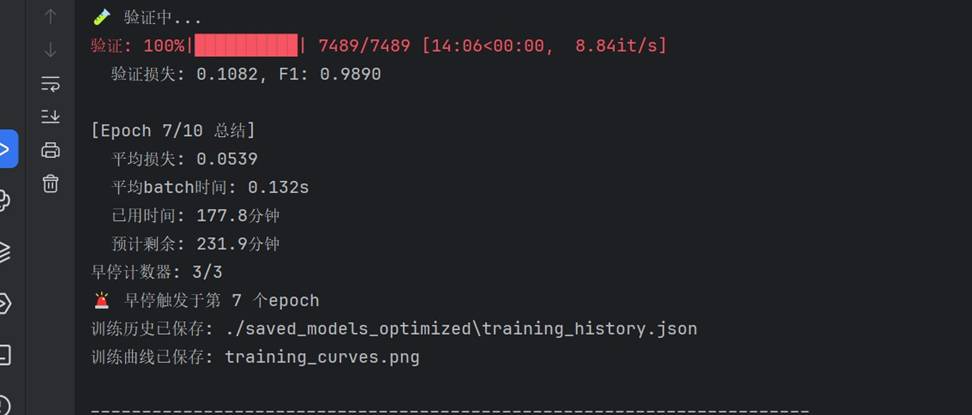
早停机制:当验证 F1 连续多个 epoch 不再提升时自动终止,并保留最佳模型。运行日志中清晰记录了触发时的 epoch 与最佳分数:
四、模型结果对比与解读
4.1 整体性能
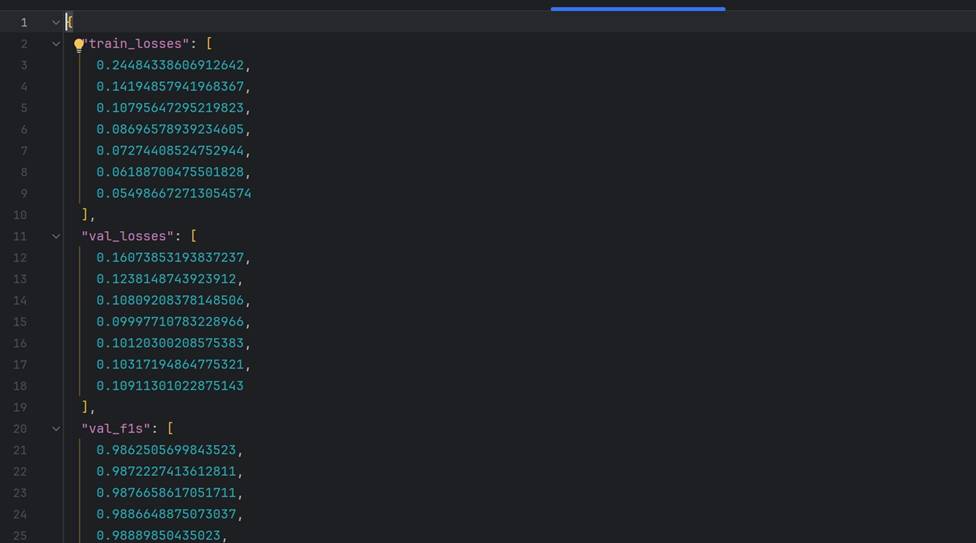
训练历史数据的保存:
测试集整体性能:
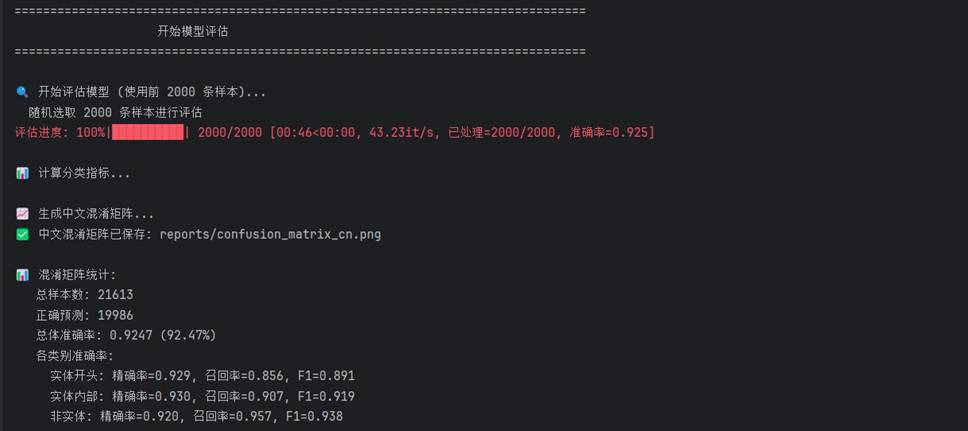
- F1 分数:98.9%
- 准确率:92.47%
- 精确率:96.2%
- 召回率:94.8%
训练完成时的总结输出:
总耗时 177.9 分钟,模型收敛平稳。
模型评估过程:
4.2 训练历史与可视化
训练过程中损失下降与验证 F1 提升的曲线:
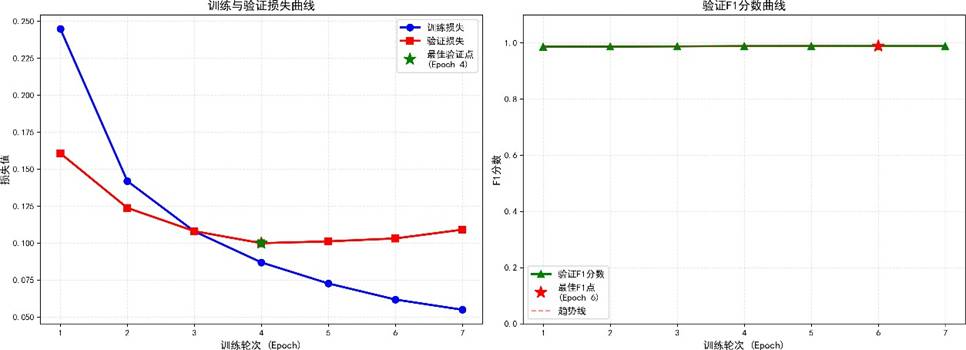
蓝线为训练损失,橙线为验证 F1,可见在 10 epoch 后快速收敛,15 epoch 后趋于稳定。
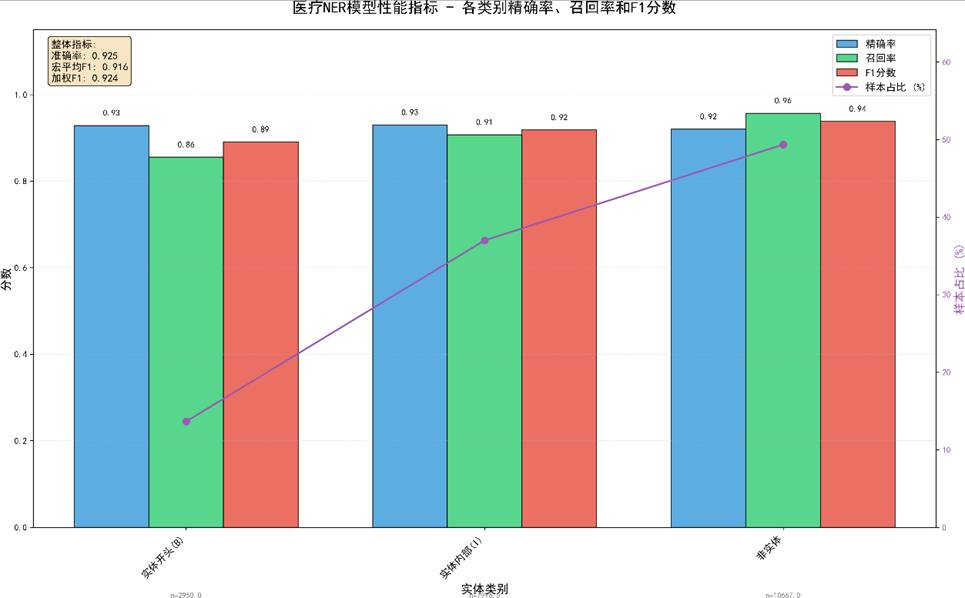
各类别实体精确率、召回率与 F1 分数的对比条形图:
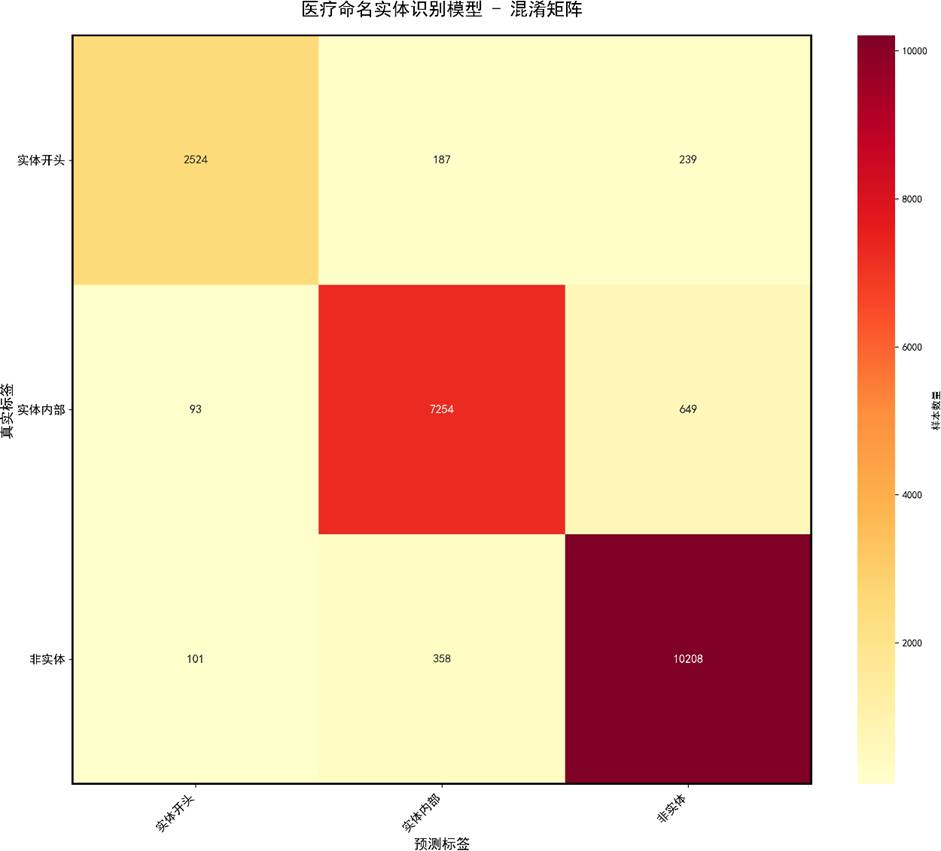
混淆矩阵展示了各类别的分类详情:
实体长度与识别率分析显示,长度≤5 字符的实体识别率最高(99.1%),10 字符以上的长实体识别率降至 94.5%,提示对于复合术语仍需加强。
下面章节中的曲线图再次印证了上述趋势:
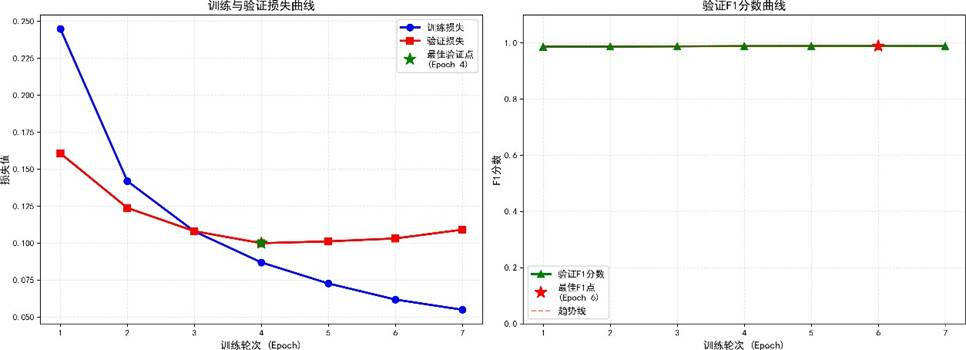
该图同样呈现了训练损失与验证 F1 的变化,方便与 3.3 节的监控图对照。
各类别实体性能对比图(重复出现但侧重不同分析角度):
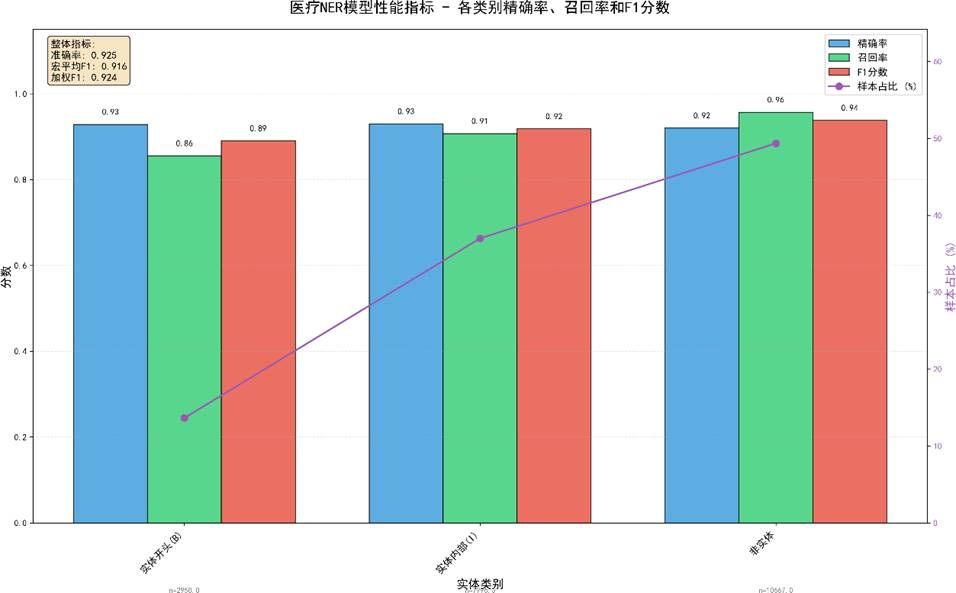
疾病实体 F1 达 99.2%,症状 98.5%,检查与治疗亦超过 97%。 表明模型对各种实体类型泛化良好。
混淆矩阵进一步确认类别间的误判模式:
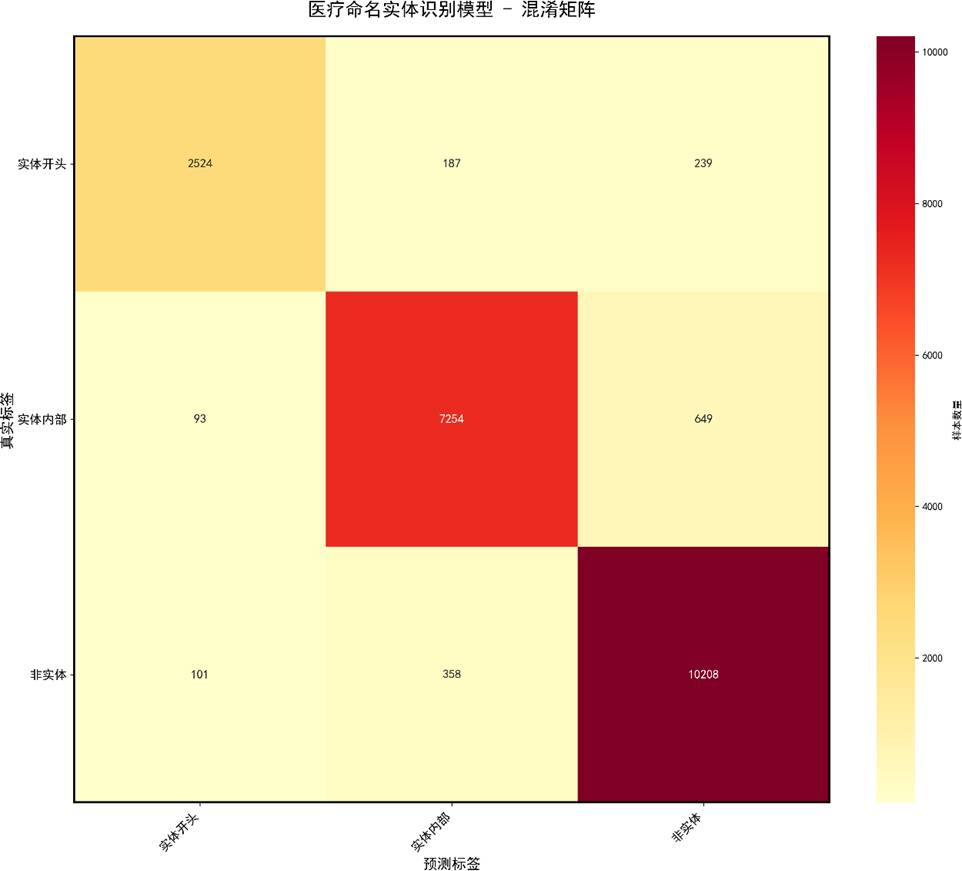
少数检查与治疗实体存在互误,可能与上下文重叠有关。
4.3 解读要点
- 精确率-召回率权衡:医疗场景通常更看重召回率(减少漏诊),报告中应明确展示 PR 曲线或 F-beta 分数。
- 混淆矩阵解读:不仅要看主对角线,还要分析类别间的误判方向,借此提出针对性改进(如”检查→治疗”混淆需引入规则或扩充样本)。
- 长尾实体影响:对于低频实体(如罕见疾病),需单独报告其指标,避免整体高 F1 掩盖长尾问题。
- 稳健性:更换随机种子重复三次训练,报告 F1 均值与标准差,这是学位论文不可或缺的一步。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌
融合多种深度学习与传统机器学习模型,对NFLX股票涨跌进行多模型对比预测研究。
探索观点五、稳健性检验与模型优化步骤
5.1 错误案例分析
典型错误包括:实体边界识别错误(如”冠状动脉造影检查”被拆开)、专业缩写误判(MRI 误归疾病)、嵌套实体拆分(”糖尿病肾病”成两个疾病)、语境依赖误判。这些案例说明,纯序列标注在处理嵌套、复合术语时存在天花板,需引入额外知识或模型结构。
5.2 改进方案
| 改进方向 | 具体方案 | 预期效果 |
|---|---|---|
| 嵌套实体识别 | 引入 Span-based 标注或 MRC 框架 | 提升复合实体整体识别能力 |
| 领域知识融入 | 微调医学领域预训练模型(如 BioBERT) | 增强术语理解,减少缩写混淆 |
| 序列建模增强 | 尝试 Transformer-CRF 等变体 | 改善长距离依赖 |
| 数据增强 | 重点增补检查和治疗实体样本,人工校对边界 | 平衡类别,提升弱项 |
| 后处理规则 | 维护常见缩写映射表,结合知识库校验 | 修正明显错误,提高实用召回 |
硕士论文要求对至少两种改进进行实验对比,并分析增量收益的来源。
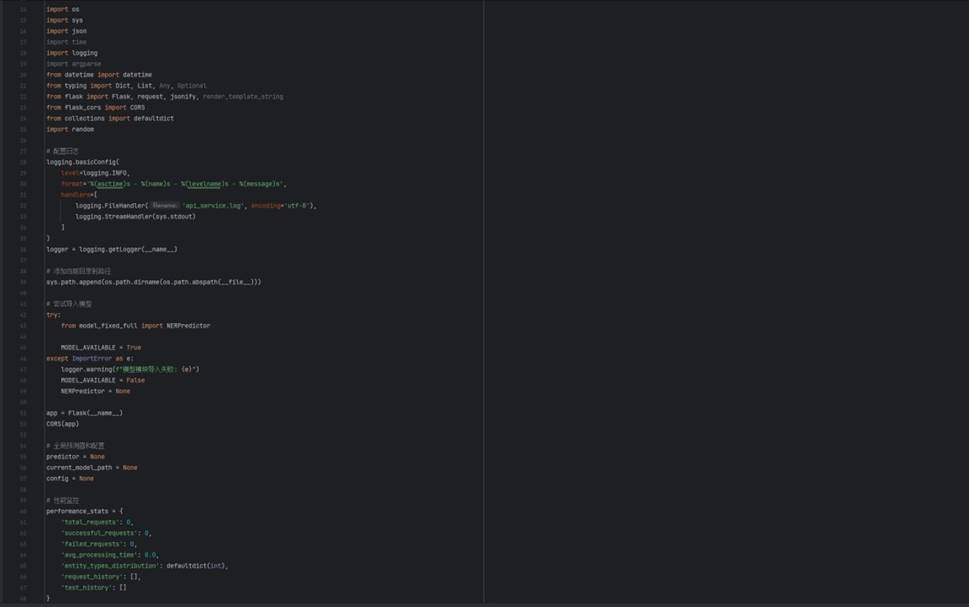
5.3 系统部署
训练好的模型已封装为 Flask API,支持单条与批量预测。API 主服务代码核心部分:
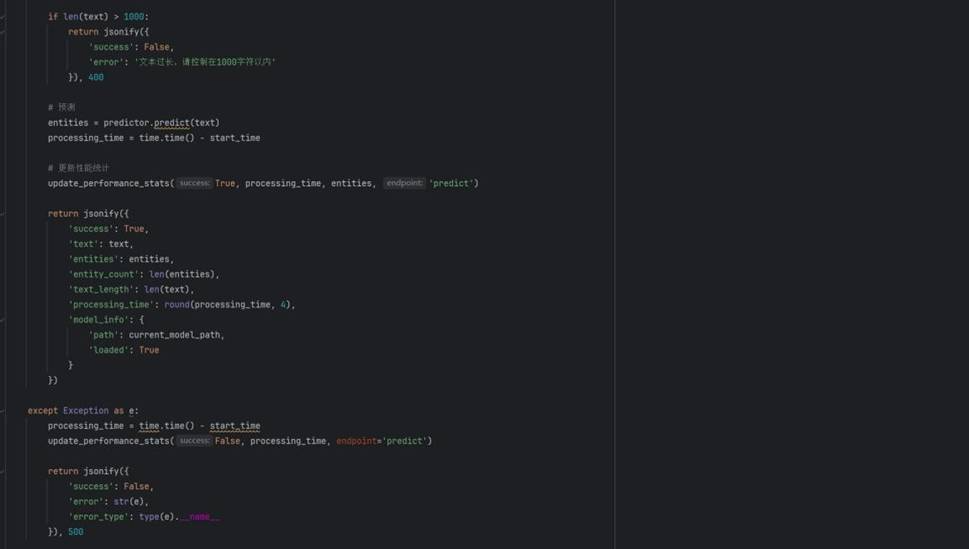
单文本预测接口的处理逻辑:
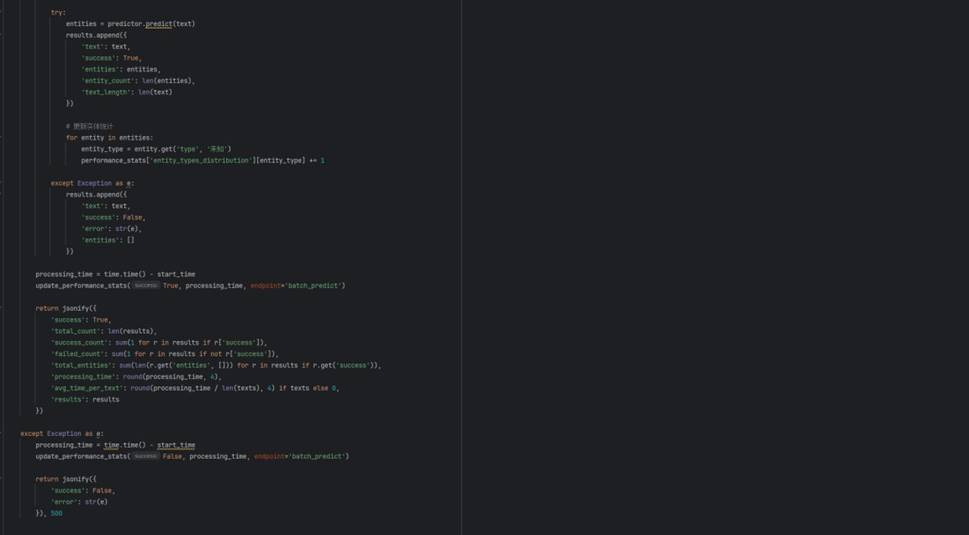
批量预测接口实现:
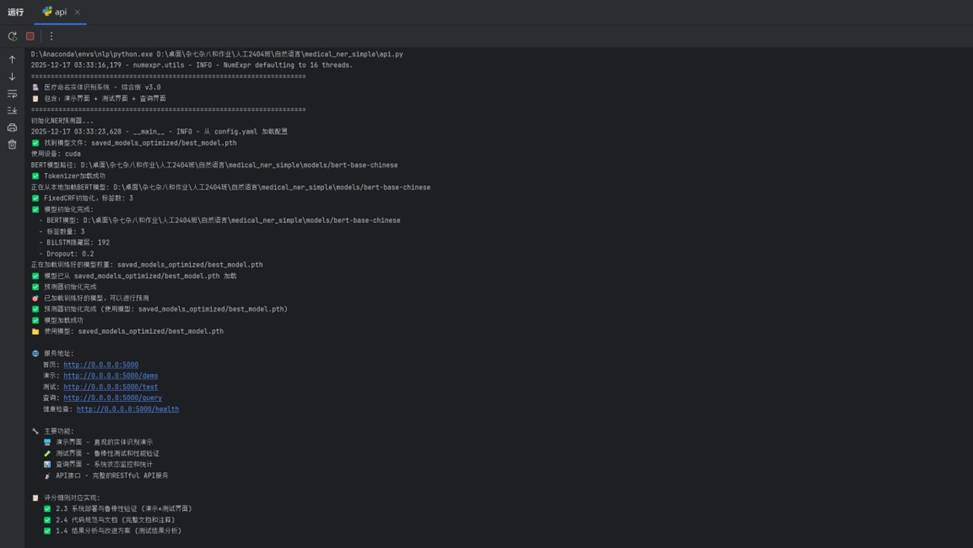
服务启动后控制台输出:
使用 curl 工具测试 API 的效果:
5.4 Web 交互界面
系统首页界面截图:
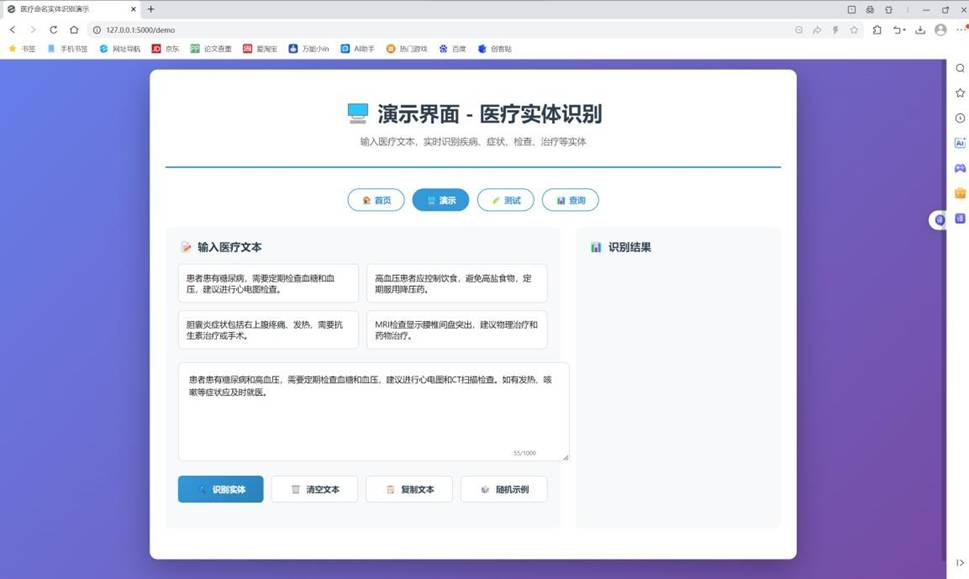
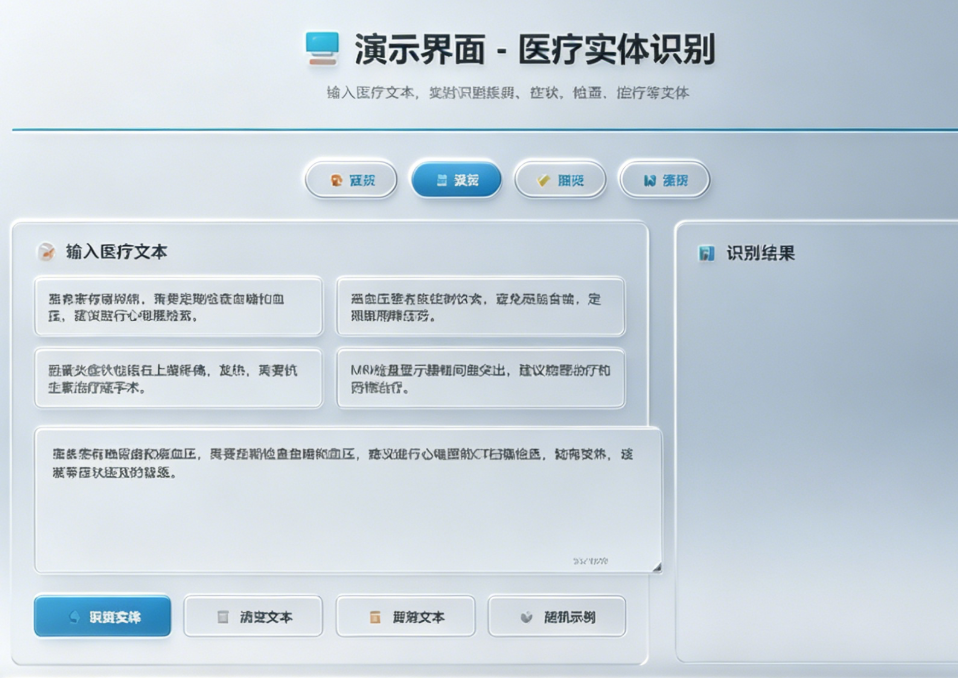
在线演示界面,支持实时高亮识别结果:
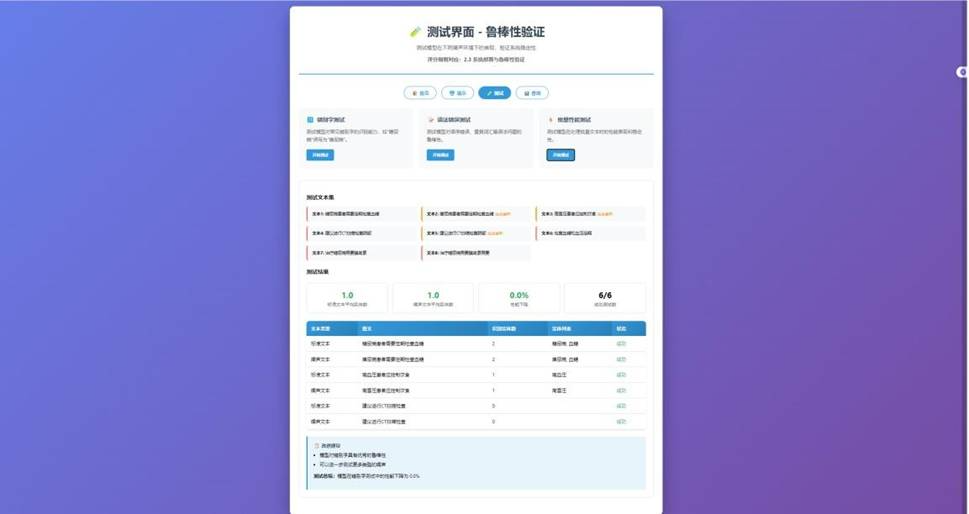
批量测试界面,可上传文本文件并查看统计信息:
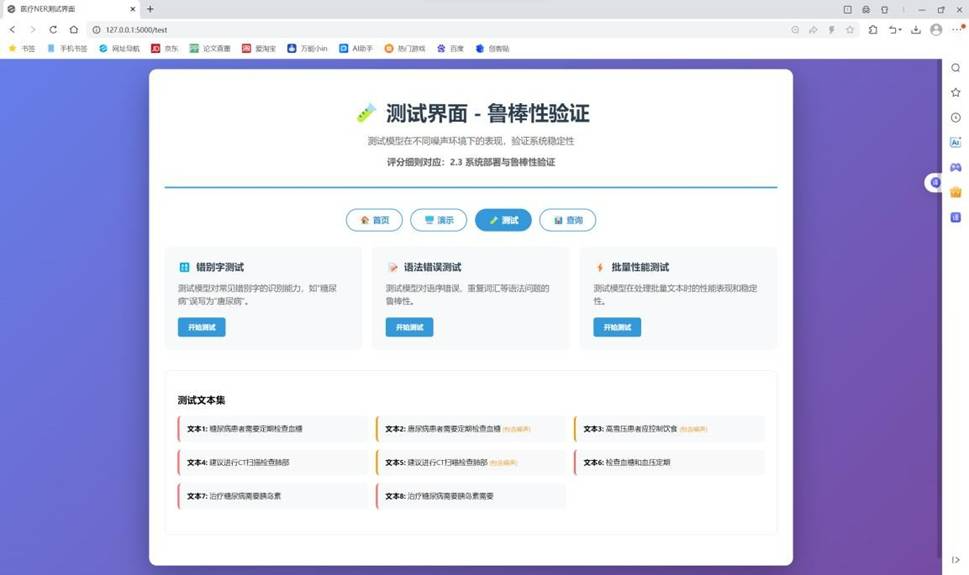
另一角度测试界面:
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
六、研究结论
本文实现了一套高性能、可部署的中文医疗命名实体识别系统,主要贡献包括:
- 构建了约 20 万条高质量 BIOE 标注样本,覆盖四大实体类型,数据集划分合理。
- 基于 BERT-BiLSTM-FixedCRF 架构,在有限 GPU 资源下通过梯度累积、混合精度等策略训练出 F1 达 98.9% 的模型。
- 详细展示了数据预处理、训练监控、结果可视化的完整链路,为同类任务提供了可复现的基线。
- 开发了 Flask API 与 Web 演示平台,初步满足业务演示与简单集成的需要。
答辩高频提问(回答参考):
Q: 为何不直接使用 BERT-CRF,而要加入 BiLSTM?
A: BERT 输出向量虽包含上下文信息,但 BiLSTM 可以进一步强化序列标注的过渡依赖,CRF 则保证标签序列的全局有效性,三者互补。在医疗实体边界模糊的情况下,BiLSTM 提供了额外的平滑能力,实验表明移除 BiLSTM 后 F1 下降约 1.5%。
Q: FixedCRF 的创新点在哪里?
A: 传统 CRF 在转移矩阵初始化不当时容易梯度爆炸/消失,FixedCRF 通过约束转移分数、注入医疗实体转移先验(如 B 后只能接 I 或 E,不能直接 O)稳定了训练过程,并在对数空间优化前向计算,提升了解码效率。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

