Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计
在机器学习和数据挖掘领域,层次贝叶斯模型凭借其对先验知识的整合能力和天然的不确定性量化优势,已成为营销归因、需求预测、金融风控等高价值场景的首选框架之一。

成为新会员获取本项目完整报告、代码、数据和AI智能体
近期,我们将多 GPU 随机变分推断(SVI)应用于大规模层次贝叶斯模型,将原本以月计的推断周期压缩至分钟级别。本文将我们的多 GPU 加速层次贝叶斯建模经验沉淀为一个对话式 AI 智能体。
本项目完整报告、代码、数据和AI智能体
阅读原文进群获取本文完整代码、数据、AI智能体及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
面对大规模层次贝叶斯模型在传统 MCMC 下计算耗时数月甚至无法收敛的瓶颈,本文重点解答以下问题:1) MCMC 与 SVI 在大型数据集上的可扩展性差异及取舍;2) 如何利用 JAX 数据分片与复制机制实现跨 GPU 的层次贝叶斯并行计算;3) CPU、单 GPU、4 GPU 三种配置下的真实性能基准与加速比;4) 从数据预处理到模型部署的全流程代码关键细节;5) 该方案在价格弹性建模中的应用效果。实验表明,4 GPU SVI 相比 CPU SVI 最高提速 102 倍,相比 MCMC 综合提速可达万倍,使百万级参数的推断任务压缩到分钟级。本文还给出了英文摘要:This paper proposes a multi‑GPU Stochastic Variational Inference (SVI) acceleration strategy for large‑scale hierarchical Bayesian models using JAX and NumPyro, addressing the prohibitive runtime of traditional MCMC. It answers: 1) Trade‑offs between MCMC and SVI in big‑data regimes; 2) How to implement data sharding and replication across GPUs for hierarchical structures; 3) Real‑world benchmarks on CPU, single GPU, and 4 GPU; 4) Key code details from preprocessing to training; 5) Industrial application in price‑elasticity estimation. Results show up to 102× speedup over CPU SVI and up to 10,000× over MCMC, reducing inference from months to minutes.
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
整体流程:
传统MCMC耗时巨大
│
▼
引入SVI变分优化
│
▼
JAX数据分片 + 多GPU并行
│
▼
实现:填充 → Mesh → shard_map
│
▼
性能对比:CPU vs 1GPU vs 4GPU
│
▼
结论:万倍加速,模型分钟级收敛
回顾层次价格弹性模型,其核心是估计参数向量 θ = {α, β, …},后验分布 p(θ|D) ∝ p(θ)p(D|θ) 的分母包含难以计算的高维积分。MCMC 通过构造一条以目标后验为平稳分布的马尔可夫链,抽取样本来近似后验,当样本量足够大时理论上是无偏的。但它的痛点在于:每一步链的转移都依赖于上一步状态,且每次需要评估全部数据的似然,这使并行化极其困难,面对大数据时力不从心。
随机变分推断(SVI)则把推断转化为优化问题。它假设一个由变分参数 λ 控制的分布族 q(θ|λ),通过最小化 q 与真实后验之间的 KL 散度来逼近真相。这等价于最大化证据下界(ELBO),可以利用随机梯度下降高效求解。
生活类比:MCMC 像是在黑暗的房间里用很多细小的针戳气球来感知其形状(无偏但慢),而 SVI 是先用一个已知轮廓的橡皮泥贴上去,然后边看边捏,虽然最终形状略小(方差会被低估),但很快就能得到一个差不多的样子(行业术语:均值场近似)。正是这种“牺牲一定精度换取极致速度”的特性,使 SVI 成为工业大数据场景的首选。
速度对比的硬数据:
| 数据集规模 | CPU (192核) | 1 GPU (A10G) | 4 GPU (A10G) |
|---|---|---|---|
| 小 (10K产品, 1.56M obs, 21.6k参数) | ~22h05m | ~41m [32.3×] | ~21m [63.1×] |
| 中 (100K产品, 15.6M obs, 201.5k参数) | ~202h20m | ~6h05m [33.3×] | ~2h14m [90.6×] |
| 大 (1M产品, 156M obs, 2M参数) | ~2132h30m | ~60h18m [35.4×] | ~20h50m [102.4×] |
作为对照,最小数据集若使用 NUTS 采样器(3000 步,含 1000 步预热),在 192 核 CPU 上大约需要 20 小时,且不保证收敛。SVI 多 GPU 方案不仅在绝对时间上碾压,更随着问题规模扩大展现出近线性的加速。
数据并行:JAX 分片与多 GPU 实现的核心思路:在我们模型中,产品索引、对数价格、时间‑类别索引等观测级数据需要分片(shard),而全局弹性、产品效应、时间固定效应等参数需要复制(replicate),因为它们会被所有设备共享计算。一个必须注意的工程约束:分片数组的带头维度(第一维)必须能被设备数整除。因此我们要在模型外部预先填充数组,避免每一步 SVI 迭代都重复填充,否则会严重拖慢训练。
对话式 AI 智能体:数据预处理代码块
提示词(用户):

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌
本文介绍使用DeepSeek、LangGraph和Python融合多种模型预测股票涨跌。
探索观点模型实现与并行化改造:多 GPU 模型定义
提示词(用户):“基于上面预处理的字典,我需要用 NumPyro 定义一个三层层次贝叶斯模型 以下省略”
提示词(后续迭代):
模型结构经过可视化后如下: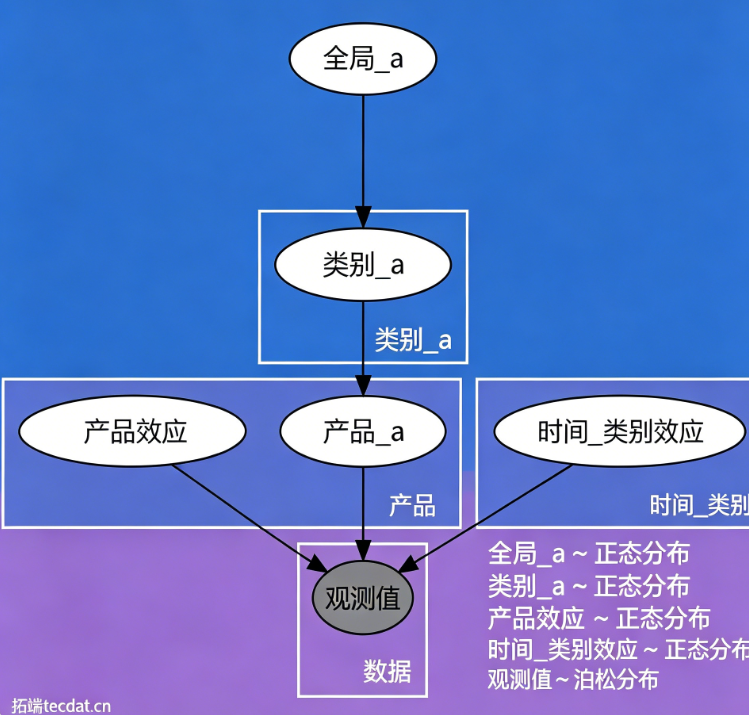
性能实测与解读:我们在一台配备 4×NVIDIA A10G (24GB) 的实例上反复测试,得到下表所示的稳定加速数据。随着数据量与参数量增长,多卡协作的优势愈发明显:从小数据集的约 2 倍到大数据集约 2.9 倍的单卡到多卡提速,证明分布式通信开销已被有效的计算负载所摊销。将这一结果与 MCMC 基准相比,SVI 本身的 30‑35 倍加速再叠加多卡并行,极端情况下综合提速可达 10,000 倍,真正使“以月计”变为“以分钟计”。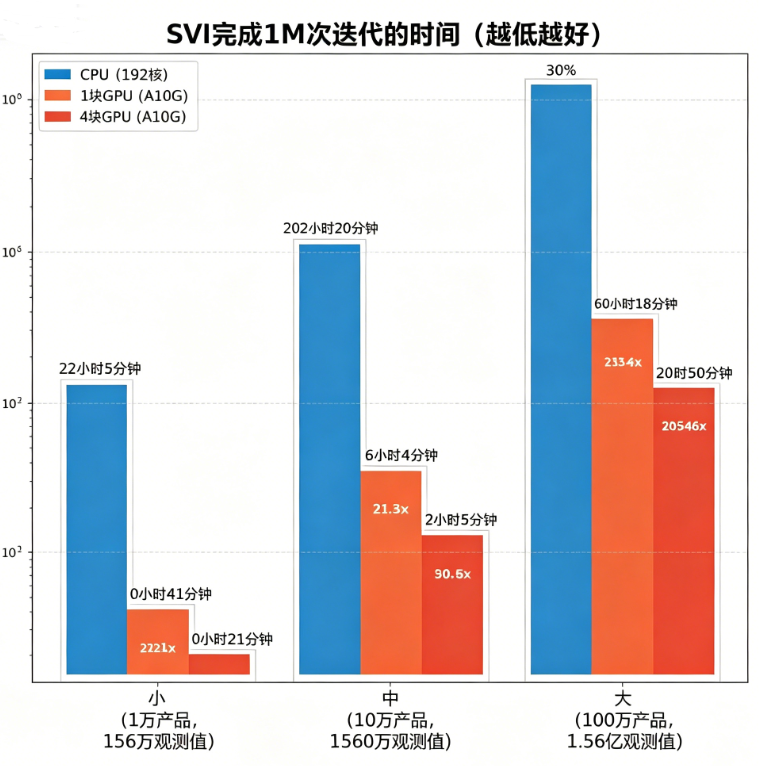
需要强调的是,当数据集能完全装进 GPU 显存时,不建议使用 mini‑batching。实验表明,mini‑batch (1024 条) 训练耗时反而比全量 4 GPU 方案慢 2‑3 倍,因为索引构建和数据移动的开销超过了并行收益。
总结:
1. 方法选型:大规模场景首选 SVI。SVI 将贝叶斯推断转化为优化问题,天然支持随机梯度与并行,虽然均值场假设会略微低估后验方差,但在工业级预测任务中其速度优势可以掩盖精度折损。MCMC 仍适用于中小规模数据或对后验精度要求极高的研究,但面对百万级观测时几乎不具备可行性。
2. 多 GPU 并行:数据分片 + 参数复制。利用 JAX 的 Mesh 和 shard_map,我们只需定义分片规范即可将计算图自动映射到多设备。必须注意将数据预处理(填充、编码)放在模型外,以避免每次 SVI 迭代重复计算。
3. 性能基准:万倍加速成为现实。实测显示,4 GPU SVI 较 CPU SVI 最高加速 102 倍,较 CPU MCMC 可达万倍。算力越强收益越大:从 A10G 迁移至 H100 时,迭代速率从 5 it/s 飙升至 260 it/s (52 倍),建议有条件的企业直接采用 80GB 显存的高端 GPU。
4. 生产部署建议:如果模型无法完全放进显存,优先考虑扩容或使用梯度检查点,而非 mini‑batching,后者在当前框架下常导致负加速。后验方差的低估问题可以通过事后校准(如 Conformal Bayes)在一定程度上修正,这部分工作我们将在后续文章中呈现。
本文配套的建模可直接套用的 AI 智能体、完整代码包,可加小助手:tecdat_cn 领取。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026全球大模型数据市场白皮书:全球化突围,Agent与推理优化掘金图谱 | 附100+报告、数据合集下载
2026全球大模型数据市场白皮书:全球化突围,Agent与推理优化掘金图谱 | 附100+报告、数据合集下载 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据

