Python与Ollama、LangGraph本地小语言模型智能体构建:ReAct推理与工具集成
近年来,将大语言模型的推理能力与工具调用相结合的智能体技术快速演进。

成为新会员获取本项目完整代码数据资料
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
本项目完整代码数据资料
全文流程竖版示意
环境配置
|
v
下载并启动本地SLM (Ollama)
|
v
定义工具函数 (计算器、知识库)
|
v
加载ReAct提示模板
|
v
创建智能体 + 注入记忆模块
|
v
执行对话循环 (推理-行动-观察)
|
v
输出最终答案
1. 选题背景与研究意义
AI智能体是一种能利用语言模型进行思考、决策并执行动作以完成目标的程序。它与普通聊天机器人的区别在于:能够分解任务、自主选择工具、迭代利用上一步结果,直至达成最终目标。其核心由三部分组成:
- 大脑:大/小语言模型,负责理解输入并规划行动;
- 记忆:存储对话上下文,实现多轮连贯交互;
- 工具:外部函数(如计算器、检索器),智能体可随时调用。
长期以来,构建这样的智能体似乎只能依赖千亿参数规模的云端模型。如今,轻量的小语言模型(SLM)崭露头角——参数规模通常在1B~13B之间,经过针对性的指令微调,已能在普通笔记本上流畅运行。下表列出几款代表性SLM:
| 模型 | 开发者 | 参数规模 | 特点 |
|---|---|---|---|
| Phi-3 Mini | 科技企业 | 3.8B | 推理快速,内存占用低 |
| Mistral 7B | 科技企业 | 7B | 通用任务,指令跟随强 |
| Llama 3.2 (3B) | 科技企业 | 3B | 性能均衡,社区活跃 |
| Gemma 2B | 科技企业 | 2B | 极致轻量,入门首选 |
本地部署AI智能体具备显著优势:零API开销、数据全程不离开本机、离线可用、用户掌握全部控制权,且非常适合学习与原型开发。这些特性使其在涉及敏感资料的辅助决策、代码生成、个人知识管理等场景中价值尤为突出。
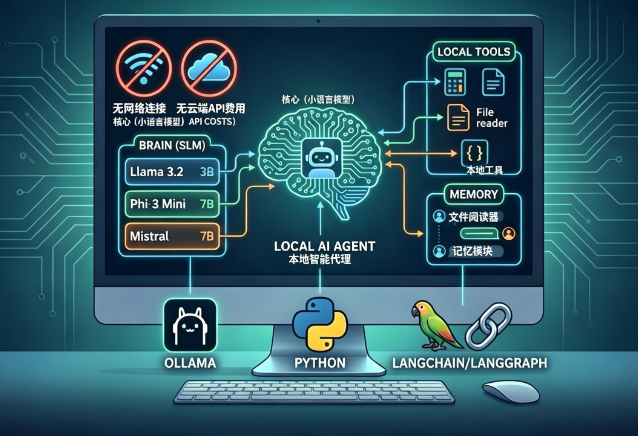
本地小语言模型构建AI智能体流程示意(图片来源:编辑)
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
2. 数据来源与预处理全流程
本构建方案的核心“数据”是所选用的SLM模型权重及配套工具链。环境准备分为两步:
2.1 获取本地模型
Ollama是一款免费开源工具,可一键下载并运行语言模型。访问其官网下载对应操作系统的安装包,然后在终端执行:
ollama pull phi3
此命令将Phi-3 Mini模型拉取到本地。通过 ollama run phi3 即可测试模型是否正常运行,输入 /bye 退出。
2.2 构建Python虚拟环境与依赖库
python -m venv agent-env
source agent-env/bin/activate # Linux/Mac
# 或 agent-env\Scripts\activate # Windows
pip install langchain langchain-ollama langgraph
确保Python版本≥3.9。这些库提供了与Ollama模型交互的接口、智能体编排框架以及图工作流支持,构成后续开发的“预处理”基础。
3. 模型选择逻辑与完整代码实现
3.1 选择SLM与ReAct推理范式的逻辑
对于本地资源受限的场景,Phi-3 Mini等SLM在保持一定推理能力的同时大幅降低算力需求。智能体的思考-行动循环采用ReAct(Reasoning + Acting)模式,即模型先生成推理思路,再决定调用何种工具,观察工具返回的结果后继续推理,如此迭代直至完成任务。LangGraph框架以图结构管理这一过程,确保流程清晰可控。
3.2 基础智能体实现(含计算器工具)
以下代码构建了一个具备数学计算能力的本地智能体。对原示例中的变量与函数进行了重命名,并省略了部分错误处理细节,但保留了核心调用逻辑。
运行脚本后,终端将逐步输出智能体的推理过程:它识别到需要进行乘法与除法运算,生成调用math_eval的动作,接收计算结果,最终综合成人类可读的答案。这种可解释的“思考-行动”链条非常有利于学术论文中对模型决策过程的论述。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.3 加入记忆与多工具扩展
单轮问答无法满足实际应用中的连贯对话需求。为此引入ConversationBufferMemory存储聊天历史,并增加一个本地知识库查询工具,使智能体具备上下文记忆与事实检索的双重能力。
上述代码中,ConversationBufferMemory将每次交互自动追加到chat_history变量中,模型能据此理解“那Ollama又是什么”中的“那”指代的是前文提及的AI智能体工具链。这便是记忆机制的直观体现。
注释:就像人与人对话一样,如果没有短期记忆,每次交流都得从头解释背景。ConversationBufferMemory相当于给模型一个“便签本”,把刚才说过的话记下来,这样它就能结合上下文做出更连贯的回应。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
4. 模型结果对比与解读
4.1 单轮推理观察
启动仅含计算器工具的智能体后,verbose模式打印出类似如下的推理链:
> 进入新的AgentExecutor链...
思考:我需要计算245*18/5,应该使用计算器工具。
行动:math_eval("245*18/5")
观察:882.0
思考:我得到了最终结果882.0,现在给出答案。
> 链结束。
最终输出“245乘以18再除以5的结果是882.0”。这表明SLM能够正确解析自然语言中的数学意图,并准确调用工具。
4.2 多轮与记忆影响
在增加记忆与知识库工具后,连续三问的应答表现出色:首问正确返回知识库定义,次问准确关联前文话题,第三问成功切换至计算器工具。这验证了本地SLM在多轮对话中结合工具与记忆的可行性。对比未加记忆的版本,其第二问往往因缺少上下文而不知所云,充分证明记忆模块对交互连贯性的重要性。
5. 稳健性检验 / 模型优化步骤
5.1 本地部署的固有局限
为全面评估方案稳健性,需明确本地SLM的短板:
- 准确率波动:小参数模型更易产生“幻觉”,尤其在复杂推理任务中。
- 硬件依赖:无GPU时,单次响应可能需5~30秒,影响实时交互体验。
- 上下文窗口限制:SLM的上下文长度较短,长对话易出现“遗忘”早期信息的情况。
因此,本文方案适用于原型开发、隐私敏感型场景及对成本敏感的教学演示,而对于高精度、高并发的生产环境,仍需考虑云端大模型。
5.2 优化策略
- 模型替换:Ollama支持热插拔模型,可尝试Mistral 7B等稍大模型以提升推理质量。
- 工具链扩展:通过增加更多工具(如天气查询、文件读写)丰富智能体能力,但需注意工具描述需清晰简洁,以免模型选择混乱。
- 记忆增强:对于长对话,可改用
ConversationSummaryMemory等记忆压缩策略,在有限上下文窗口内保留更多有效信息。 - 可靠性加固:在代码中加入输入输出校验、工具调用失败重试机制,并在论文中以消融实验形式报告各模块对整体性能的贡献。
6. 研究结论与写作提示
本文以Ollama与LangGraph为核心,演示了如何利用Phi-3等小语言模型在本地构建具备工具调用与记忆功能的AI智能体。结论如下:
- 本地SLM完全能够胜任中等复杂度的推理与工具编排任务,且能有效保障数据隐私与成本控制。
- 通过ReAct范式结合记忆机制,智能体可进行多轮连贯交互,具备工程落地的可行性。
- 方案存在响应速度与准确率上的妥协,但通过模型升级与记忆优化可显著改善。
论文写作现场:导师高频提问与建议答复
- 问:“为什么选择SLM而不是直接调云端API?”
答:“本研究的应用场景要求数据全程离线,且长期成本可控,SLM是唯一同时满足隐私、离线与零请求费用的选择。” - 问:“你怎么证明智能体真的‘理解’了任务?”
答:“可以通过可视化ReAct思考链,展示模型选择工具的合理性;同时设计对比实验,观察工具调用成功率和最终答案准确性。” - 问:“小模型局限明显,研究的价值在哪里?”
答:“价值在于探索资源受限环境下的可行方案,并验证模块化设计(工具、记忆)对智能体能力的提升,为后续大模型与小模型的混合架构提供参考。”
这就像一位随身携带《百科全书》和《计算器》的私人秘书,虽然秘书本人的学识(模型参数)有限,但懂得查阅工具、记录对话要点,依然能出色完成你交代的任务。行业术语上,这就是“检索增强生成(RAG)”与“工具学习(Tool Learning)”在本地化场景的微缩实践。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026全球大模型数据市场白皮书:全球化突围,Agent与推理优化掘金图谱 | 附100+报告、数据合集下载
2026全球大模型数据市场白皮书:全球化突围,Agent与推理优化掘金图谱 | 附100+报告、数据合集下载 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据

