Python、BMA-Stacking融合LightGBM、GBDT、KNN多模型电商交易欺诈风险预警研究
电子商务的蓬勃发展为全球经济注入活力,但也滋生了日益复杂的线上欺诈行为。

成为新会员获取本项目完整报告、代码和数据资料
本文的核心在于提出一种基于贝叶斯模型平均与 Stacking 集成学习的模型。它并非简单堆砌算法,而是巧妙地利用 BMA 对异构基模型的预测进行概率加权,再通过 Stacking 的元学习器进行优化组合。这种设计旨在解决传统方法在面对极度不平衡数据时,对少数类(欺诈交易)捕捉能力不足的问题。我们将完整呈现从数据清洗、多粒度特征工程到模型构建与评估的全流程,最终结果表明,该框架在召回率等关键指标上实现了显著提升,为电商平台构建实时、精准的风控体系提供了可靠的技术方案。
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
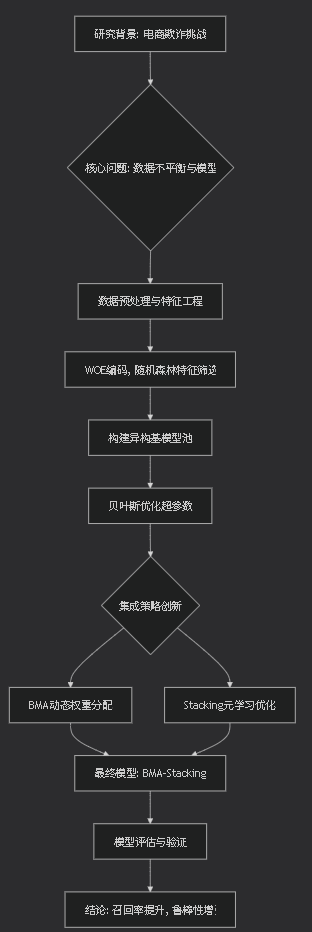
文章脉络流程图
项目文件目录截图



摘要
研究背景
电子商务欺诈指在线上交易中,不法分子通过技术手段或虚假信息,以非法牟利为目的进行的欺骗行为。数据显示,2023 年全球电商欺诈损失高达 480 亿美元,较 2020 年增长 127%。新兴市场因支付体系尚不完善,欺诈率是成熟市场的近两倍。欺诈手段也已从传统盗刷演变为利用 AI 生成虚假身份、篡改设备指纹等新型模式。此类行为导致商家年均损失 5.2%的营收,且每 1 美元欺诈损失需耗费 3.4 美元进行后续处理。因此,构建高效、精准的欺诈风险预警机制,成为业界与学界共同关注的焦点。
导师答辩高频提问:为什么选择电商欺诈检测作为研究对象?
标准答案:电商欺诈具有典型的数据不平衡、模式快速演变和高实时性要求等特征,是检验机器学习模型鲁棒性与适应性的理想场景。解决该问题不仅有巨大的商业价值,其方法论也能推广至金融风控、异常检测等其他领域。
按照欺诈手段、主体及风险场景,可将电商欺诈行为分类整理,常见手段如下表所示。
表 1 电子商务欺诈的分类与常见手段
| 分类依据 | 类别 | 常见手段 |
|---|---|---|
| 按欺诈手段分类 | 账户盗用 | 凭证猜测、撞库、钓鱼获取账户 |
| 信息伪装欺诈 | 假冒伪劣商品、仿冒平台界面 | |
| 规则滥用欺诈 | 批量注册账号、恶意退单、套取优惠 | |
| 按欺诈主体分类 | 消费者欺诈 | 虚假退货、恶意索赔 |
| 商家欺诈 | 刷单炒信、销售假冒商品 | |
| 第三方攻击者欺诈 | 数据泄露、信用卡盗刷 | |
| 按风险场景分类 | 账户安全风险 | 用户密码泄露、账户接管(ATO) |
| 支付安全风险 | 信用卡盗刷、支付接口漏洞 | |
| 交易生态风险 | 刷单、虚假评价 |
本项目完整报告、代码和数据资料
现有技术局限与研究机遇
当前主流的欺诈检测依赖规则引擎和机器学习模型。规则引擎缺乏动态适应能力,难以应对快速迭代的欺诈模式;传统机器学习模型在处理高维稀疏特征和非线性关系时存在局限;深度学习的”黑箱”特性与高计算成本阻碍了其在实际业务中的落地。欺诈检测场景普遍存在三个核心问题:一是类别极度不平衡,正常交易占比远超 99%;二是特征时效性强,欺诈模式平均每 3 个月就会发生显著演变;三是可解释性需求,相关法规要求模型决策需满足透明性与可审计性。
概念解析:类别不平衡
想象你在一个巨大的图书馆里寻找几本被撕掉封面的违禁书。如果挨个检查,99%以上的书都是正常的,你很可能会漏掉那几本,甚至会因为疲劳而误判。这个场景就是”类别不平衡”。模型在处理这类问题时,很容易学会”偷懒”,把所有样本都预测为多数类(正常书),从而获得很高的总体准确率,但这毫无意义。我们真正关心的是如何大海捞针,找到那极少数有问题的样本。
贝叶斯模型平均与 Stacking 技术的结合为解决此问题提供了新思路:BMA 通过概率加权整合多模型预测,量化不确定性;Stacking 利用元学习优化模型组合策略。二者的协同作用有望突破传统集成方法的性能瓶颈。
研究框架
本研究旨在构建一个高性能的电商欺诈风险预警模型,通过数据预处理、特征工程和模型融合技术,提升对欺诈交易的检测能力,重点关注召回率等关键指标。研究采用某公开平台提供的电商交易数据集,结合监督学习算法与贝叶斯优化调参,并引入贝叶斯模型平均来分配基模型权重,以提升模型的鲁棒性。
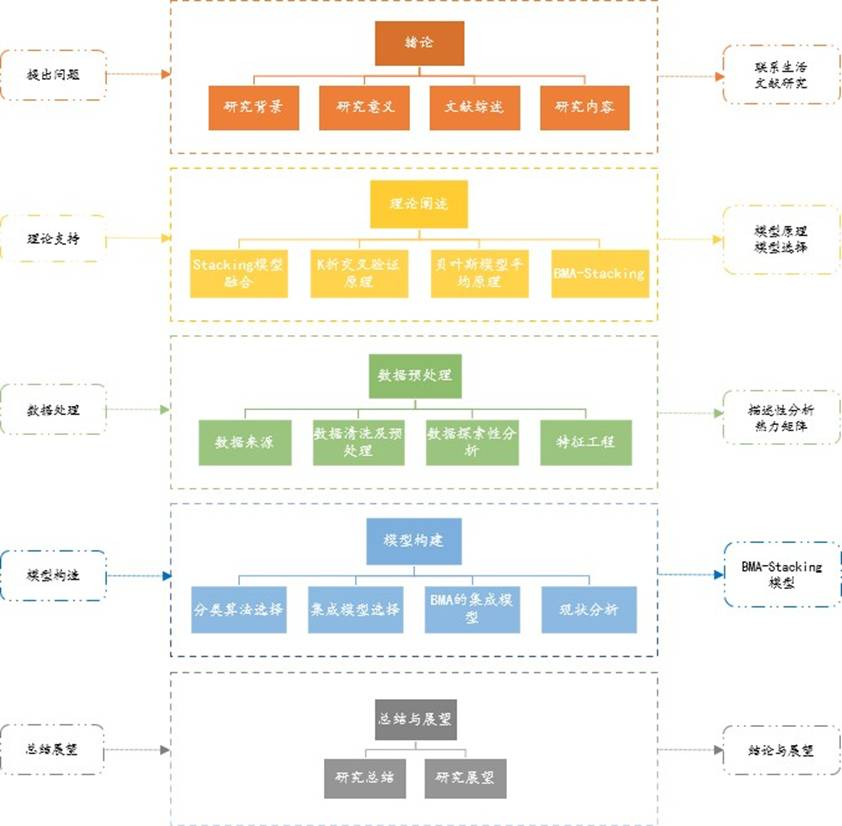
图 1 文章总体流程图
研究方法概述
不平衡数据处理
实证分析中常出现数据不平衡现象。在数据层面,小样本下常用 SMOTE 方法,通过插值生成新的合成样本;大样本下常用 TomekLinks 方法,通过识别并剔除边界样本进行欠采样。本研究采用的 SMOTE-ENN 混合采样,是先过采样扩充少数类,再欠采样清除重叠和噪声样本,以改善类别分布。在算法层面,则通过调整分类器参数(如 SVM 的惩罚系数)、使用集成学习(如 Boosting)或代价敏感学习来处理。
Stacking 模型融合
Stacking 是一种分层集成技术,它先用多个基学习器进行预测,再将所有预测结果合并作为新特征,输入到第二层的元学习器中进行最终预测,其架构如下图所示。
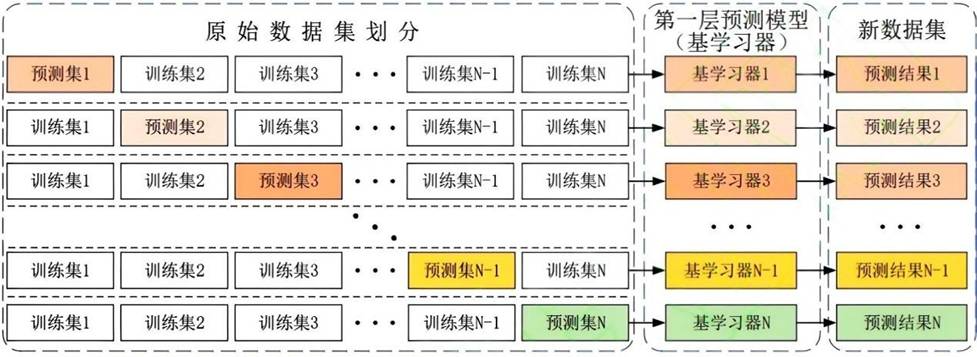
图 2 Stacking 模型架构
第一层基学习器的多样性至关重要。本研究建立了包含树算法、支持向量机、近邻算法、神经网络和回归类等 5 类算法的基学习器库,以保证观测数据方式的差异性。在本电商欺诈预警场景中,具体选择了决策树、逻辑回归、LightGBM、GBDT 以及 KNN 作为基分类器。
表 2 基学习器库
| 类别 | 算法 | 作用 |
|---|---|---|
| 基于树算法 | RF, GBDT, XGBoost, LightGBM, Catboost | 基学习器 |
| 支持向量机 | SVM | 基学习器 |
| 近邻算法 | KNN | 基学习器 |
| 神经网络 | ELM, LSTM | 基学习器 |
| 回归类 | 岭回归, Lasso 回归, LR | 基学习器/元学习器 |
K 折交叉验证
K 折交叉验证是评估模型泛化性能的常用方法。它将原始数据集平均分成 K 份,每次用其中 1 份作为测试集,剩余 K-1 份作为训练集,迭代训练 K 次后取平均值作为最终性能估计。当 K=5 时,分层示意图如下。
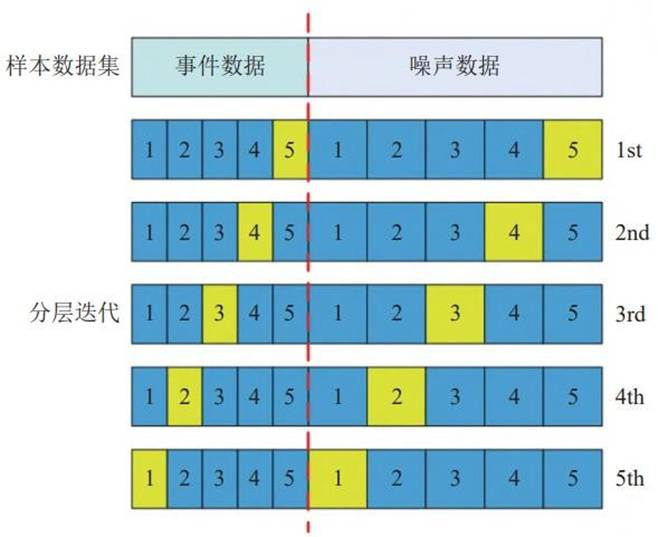
图 3 K 折交叉验证分层示意图(k=5)
BMA-Stacking 模型建模
贝叶斯模型平均是一种通过后验概率为不同模型分配权重的统计方法,能有效处理模型的不确定性。在融合 BMA 的 Stacking 流程中,首先训练多个基分类器;然后,BMA 算法根据各基分类器在训练集上的预测表现计算其后验概率,并以此为权重对预测结果进行加权平均,生成高质量的元训练集;最后,用元训练集训练元学习器,得到最终预测。
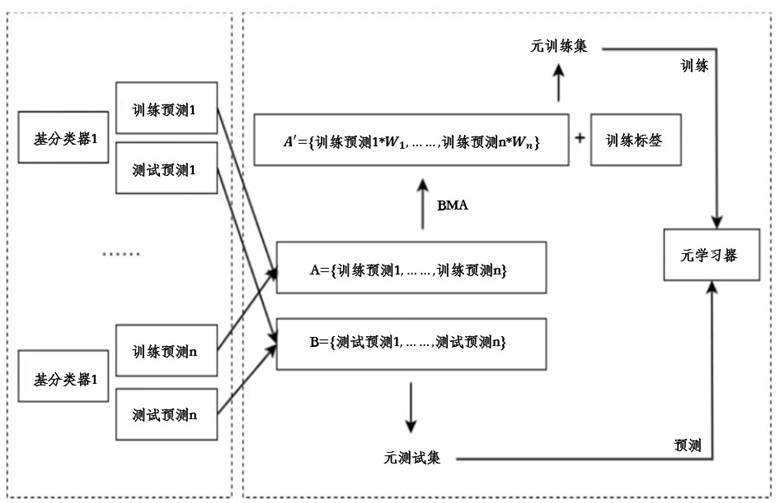
图 4 融入 BMA 的 Stacking 预测流程
核心概念精讲:贝叶斯模型平均与 Stacking
- 类比:这就像一个医院的多学科会诊。多个不同领域的专家(异构基模型)先各自独立诊断,给出他们的初步意见。但每位专家的判断都有不确定性,如何综合?BMA 就像根据每位专家过去诊断的准确率(后验概率)来决定他们意见的权重。最后,一位资深主任医师(元学习器)综合这些加权后的意见,做出最终决策。
- 术语对应:
- 多学科会诊 = Stacking 集成架构
- 专家意见权重 = 贝叶斯模型平均的后验概率
- 主任医师最终决策 = 元学习器的预测输出
模型评价指标
为保证模型的准确性和鲁棒性,本研究采用准确率、精确率、召回率和 F1 值四个指标进行客观量化评估。
数据预处理及特征工程
数据来源与清洗
本研究采用某公开平台提供的电商交易数据集,包含 23634 个样本,16 个原始特征。数据清洗环节,首先将交易日期特征转换为 datetime 格式,并从中衍生出”交易天数”、”交易星期”和”交易月份”三个新特征,随后删除原始日期变量。接着对”年龄”特征进行处理:将小于 9 岁的值替换为平均年龄,负值取绝对值。最后,新增一个”地址匹配”特征,用以标记收货地址与账单地址是否一致。清洗后的特征及其含义如下表所示。
表 3 电商交易数据集的基本特征
| 编号 | 特征 | 特征含义 | 特征类型 |
|---|---|---|---|
| 1 | amount | 交易金额 | 数值型 |
| 2 | method | 支付方式 | 分类型 |
| 3 | category | 产品类别 | 分类型 |
| 4 | quantity | 购买的产品数量 | 数值型 |
| 5 | age | 客户年龄 | 数值型 |
| 6 | device_type | 设备类型 | 分类型 |
| 7 | transaction_day | 日期中的天数 | 数值型 |
| 8 | transaction_dow | 交易发生的星期几 | 数值型 |
| 9 | transaction_month | 交易发生的月份 | 数值型 |
| 10 | address_match | 收货地址和账单地址是否一致(0,1) | 分类型 |
| 11 | account_age_days | 账户年龄 | 数值型 |
| 12 | transaction_hour | 具体小时数 | 数值型 |
| 13 | is_fraudulent | 是否欺诈(0,1) | 分类型 |
数据探索性分析
目标变量分布
如下图所示,正常交易占比高达 94.83%,而欺诈交易仅占 5.17%。这种极度不平衡的数据分布,是模型训练中必须解决的首要问题。
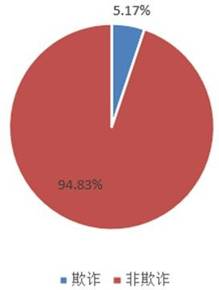
图 5 欺诈数据占比图
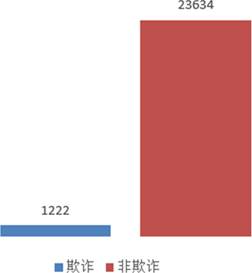
图 6 欺诈数据分布图
客户年龄与欺诈交易的关系
分析客户年龄分布可知,线上交易的主要群体集中在 30 至 50 岁。相应地,该年龄段的欺诈交易量也相对较高,是风控审核的重点人群。
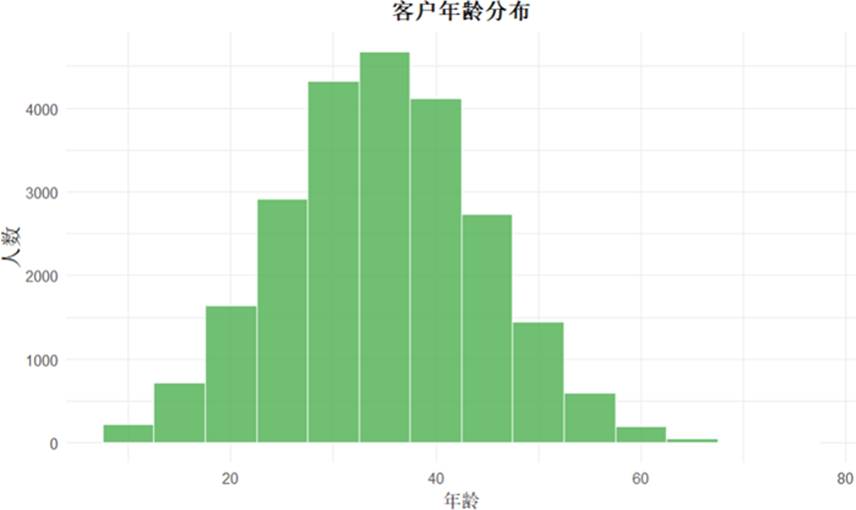
图 7 客户年龄分布图
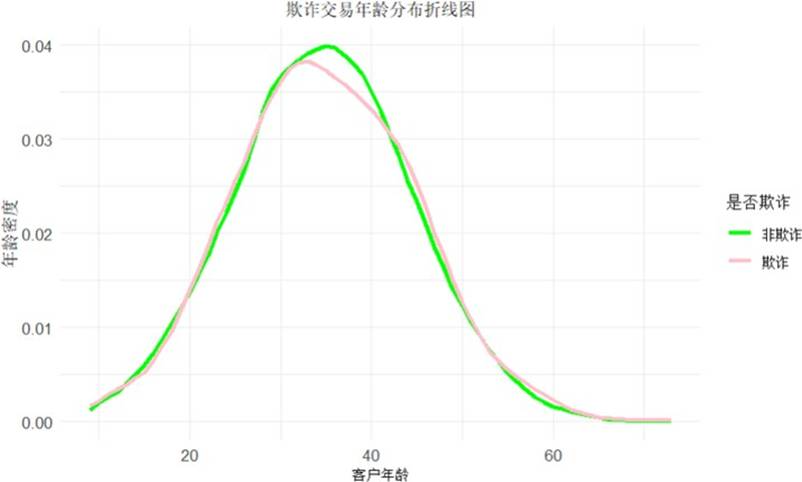
图 8 不同年龄是否欺诈分布图
商品类别与欺诈交易的关系
商品类别涵盖服饰、电子产品、日用品等五大类。分析发现,在服饰、日用品等日常消费领域,欺诈交易的比例相对更高,表明这些是欺诈高发领域,消费者和平台需给予更多关注。
图 9 商品类别图
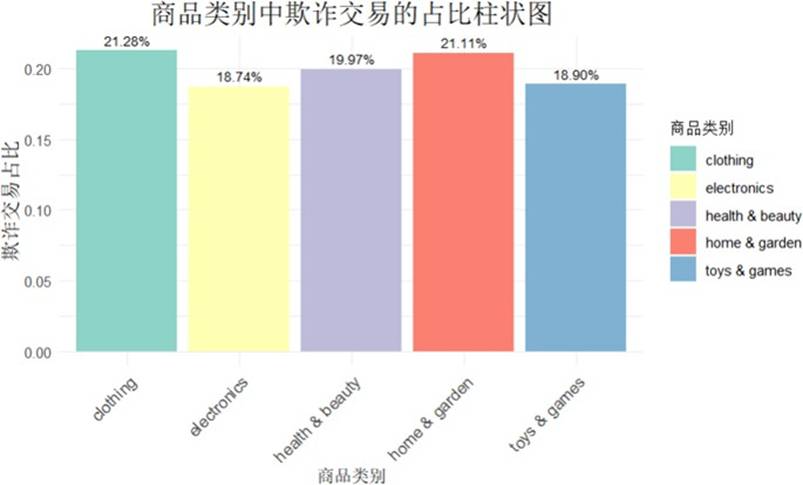
图 10 商品类别中欺诈交易的占比柱状图
欺诈交易与交易时间的关系
从时间维度分析,欺诈交易的发生频率呈现明显规律。以天为单位,凌晨后是欺诈高发期。以周为单位,欺诈交易波动显著,周四达到峰值,周二最低。以季度为单位,欺诈交易频率波动较大,尤其在第四季度出现急剧下滑。
导师答辩高频提问:为什么要做如此细致的探索性数据分析?
标准答案:探索性数据分析不仅是描述现状,更是为后续特征工程提供业务直觉和先验知识。例如,发现凌晨是欺诈高发时段,我们就可以构建transaction_hour特征;发现特定商品类别欺诈率高,就可以通过 WOE 编码将该信息量化为数值特征。脱离业务理解的特征工程是盲目的。
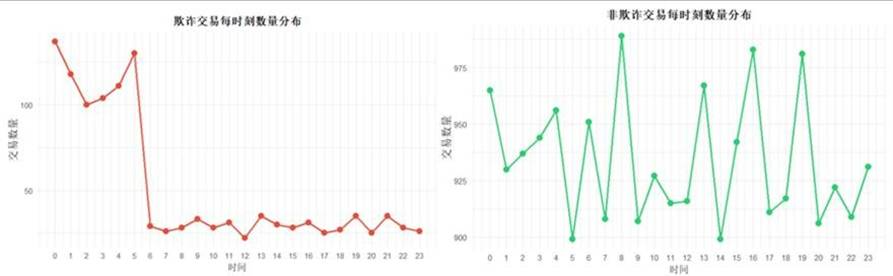
图 11 欺诈交易总数时间分布图
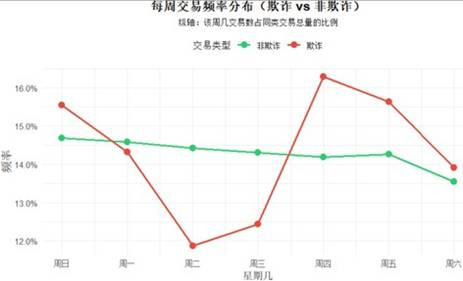
图 12 是否欺诈每周频率分布图
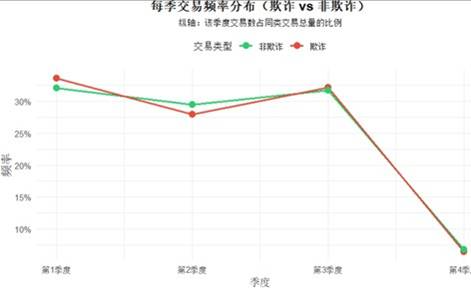
图 13 是否欺诈每季频率分布图
特征工程
特征编码
我们采用 WOE 编码处理分类变量,其核心思想是通过比较每个类别中正负样本的分布,来衡量该类别对目标变量的预测能力。本文将 address_match 等二分类变量进行独热编码,将 method、category、device_used 等多分类变量进行 WOE 编码。
表 4 特征编码的数据结果部分展示
| 数据 | is_fraudulent | address_match | method_woe | category_woe | device_woe |
|---|---|---|---|---|---|
| 1 | 0 | 1 | -0.017124 | 0.073216 | 0.009462 |
| 2 | 0 | 1 | 0.018225 | -0.071605 | 0.047497 |
| 3 | 0 | 0 | 0.080818 | 0.060085 | 0.362172 |
| 4 | 0 | 1 | 0.018225 | 0.103614 | -0.054327 |
相关矩阵分析
通过绘制特征间皮尔逊相关系数的热力图,可以直观地发现,交易金额、账户年龄和交易时间是与欺诈行为相关性较强的几个特征。
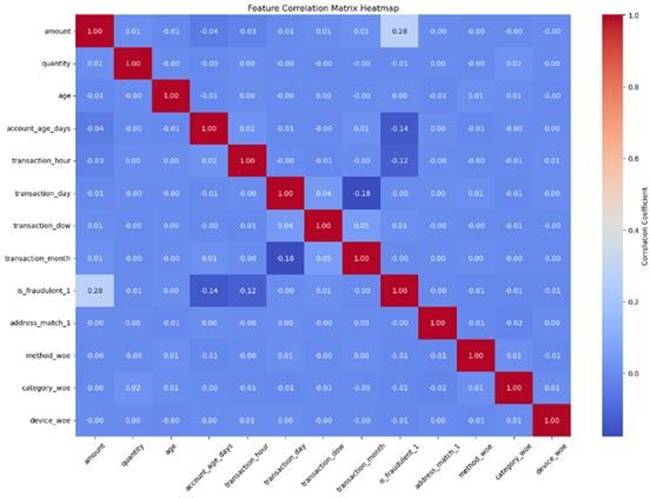
图 14 相关性热力图
随机森林特征重要性排序
为量化各特征对模型的贡献并降低过拟合风险,本研究采用随机森林进行特征重要性排序。其核心是计算每个特征在所有决策树节点上带来的基尼不纯度平均减少量。分析结果显示,各变量重要性不一,但均对模型有一定贡献。结合相关矩阵分析,我们最终保留了除目标变量外的所有特征用于建模。
概念解析:基尼不纯度
想象你有一筐水果,混合着苹果和橘子,很”不纯”。你随机拿出一个,猜它是苹果还是橘子,猜错的可能性很大。如果你按颜色把它分成两筐,每筐里的水果种类变得单一了,那么这个筐的”不纯度”就降低了。决策树就是不断寻找最佳的特征作为”分裂”的依据,让分出的子节点”不纯度”尽可能低。一个特征使”不纯度”降低得越多,它对分类的贡献就越大,重要性也就越高。
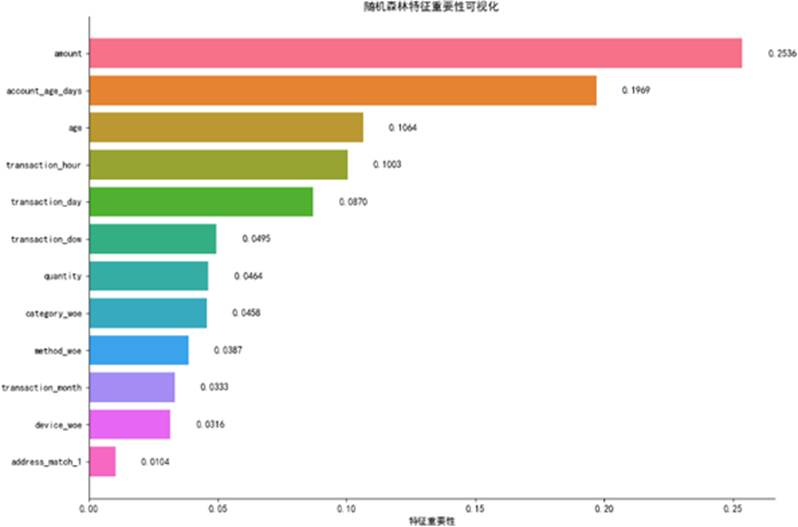
图 15 随机森林特征重要性排序
电商欺诈风险预警模型实证分析
分类算法选择与超参数优化
本研究聚焦于监督学习与模型融合技术。通过系统比较,筛选出决策树、逻辑回归、LightGBM、GBDT 以及 KNN 五种预测性能良好的基分类器。针对这些模型,我们采用贝叶斯优化算法寻找最优超参数组合。相比传统的网格搜索,贝叶斯优化通过构建目标函数的概率代理模型,能以更少的迭代次数找到更优解。
概念解析:贝叶斯优化
这就像在一个漆黑的山谷中寻找最低点。网格搜索是带着探照灯地毯式扫描,效率很低;而贝叶斯优化则是基于每一次探索获得的地形信息,智能地推测下一个最有可能是最低点的位置,从而快速逼近谷底。
表 5 模型最终参数设置
| 分类算法 | 参数值 |
|---|---|
| Adaboost | learning_rate=1.0, n_estimators=153 |
| LR | C=3.8 |
| 决策树 | criterion=entropy, max_depth=6, splitter=best |
| KNN | n_neighbors=5, weights=distance, metric=euclidean |
| GBDT | learning_rate=0.3, max_depth=17, n_estimators=140 |
| LightGBM | learning_rate=0.2, max_depth=17, n_estimators=84, num_leaves=43 |
各模型的 ROC 曲线及 AUC 值如下图所示。其中,AdaBoost 的 AUC 值达到 0.926,表现最为突出。但 AUC 对于极端不平衡数据的模型区分能力有限,因此还需结合更多指标综合评估。
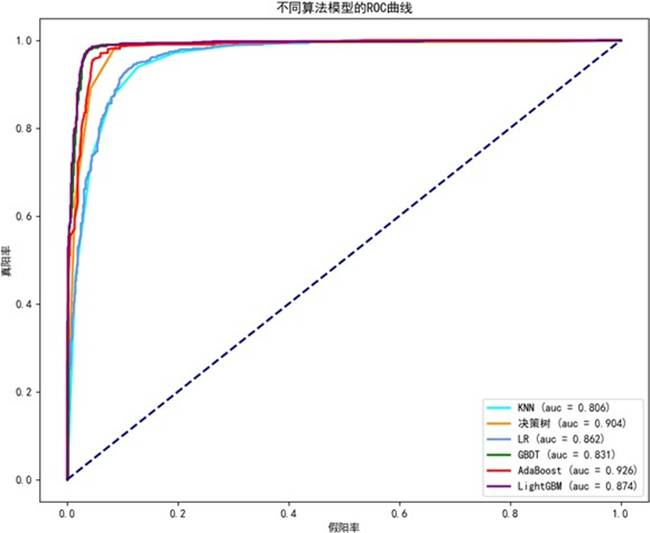
图 16 各模型的 ROC 曲线图
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
下表给出了各单一模型的详细性能评估。可以看到,召回率最高的是 LightGBM(69.72%),准确率最高的是 Adaboost,精确率最高的是决策树。但整体而言,所有单一模型的召回率都处于较低水平,表明其对欺诈交易的捕捉能力有限。
表 6 分类算法的性能评估表
| 模型 | 准确率 | 精确率 | 召回率 | F1 分数 |
|---|---|---|---|---|
| Adaboost | 0.9425 | 0.7632 | 0.6481 | 0.7006 |
| LR | 0.9110 | 0.6380 | 0.5315 | 0.5806 |
| 决策树 | 0.9413 | 0.7936 | 0.6284 | 0.7018 |
| KNN | 0.8036 | 0.7904 | 0.4693 | 0.5889 |
| GBDT | 0.9307 | 0.7858 | 0.5930 | 0.6759 |
| LightGBM | 0.9219 | 0.7793 | 0.6972 | 0.7359 |
集成模型选择与验证
为进一步提升性能,我们引入 Stacking 集成方法。下表对比了不同基模型组合下的 Stacking 模型效果。在未处理数据不平衡的情况下,以”KNN + GBDT”为基学习器、”LightGBM”为元学习器的组合表现最优,召回率达到 75.22%,F1分数达到 0.8093。这验证了异构模型集成的有效性,但数据不平衡问题仍是瓶颈。
表 7 不同集成模型的结果
| 集成方式 | 准确率 | 精确率 | 召回率 | F1 分数 |
|---|---|---|---|---|
| LR、GBDT+LGB | 0.9337 | 0.8408 | 0.724 | 0.7779 |
| 决策树、LR+LGB | 0.9407 | 0.8273 | 0.744 | 0.7835 |
| KNN、LGB+LR | 0.9435 | 0.8516 | 0.7098 | 0.7739 |
| 决策树、GBDT+LR | 0.9261 | 0.8592 | 0.7246 | 0.7859 |
| LGB、KNN+GBDT | 0.9482 | 0.8757 | 0.7316 | 0.7967 |
| KNN、GBDT+LGB | 0.9518 | 0.8762 | 0.7522 | 0.8093 |
融合BMA的集成模型结果分析
本节引入 SMOTE-ENN 混合采样处理数据不平衡,并将贝叶斯模型平均融入 Stacking 框架。下图展示了 BMA 方法对 KNN、GBDT 和 LightGBM 三个基模型分配的后验权重。可见,GBDT 和 LightGBM 获得了更高的权重,而 KNN 的权重较低,这种基于概率的动态权重分配是 BMA 的核心优势。
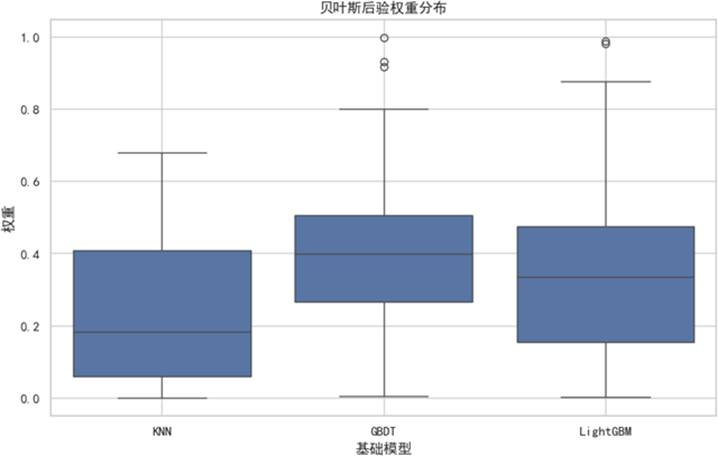
图 17 贝叶斯后验权重分布图
为全面验证,我们设置了对比实验,测试在不同采样方式下,未融合 BMA 与融合 BMA 的集成模型性能。
表 8 不同采样方式下的集成模型结果
| 集成模型 | 采样方式 | 准确率 | 精确率 | 召回率 | F1 分数 |
|---|---|---|---|---|---|
| 未融合 BMA 的集成模型 | Nearmiss | 0.9146 | 0.7276 | 0.5091 | 0.5976 |
| SMOTE | 0.9183 | 0.7991 | 0.7133 | 0.7539 | |
| SMOTE-ENN | 0.9279 | 0.8045 | 0.7784 | 0.7912 | |
| 融合BMA 的集成模型 | Nearmiss | 0.9273 | 0.7687 | 0.5454 | 0.6368 |
| SMOTE | 0.9461 | 0.8235 | 0.7309 | 0.7744 | |
| SMOTE-ENN | 0.9355 | 0.8518 | 0.8098 | 0.8302 |
结果清晰地表明:
- 采样方法的影响:SMOTE 和 SMOTE-ENN 在所有指标上均优于 NearMiss,而 SMOTE-ENN 在召回率提升上尤为显著。
- BMA 的增益:引入 BMA 动态加权后,模型的整体性能得到进一步提升。尤其是在 SMOTE-ENN 采样下,融合 BMA 的模型在召回率和 F1 分数上分别达到了 80.98% 和 83.02%,在所有方案中表现最佳。
导师答辩高频提问:BMA-Stacking模型与普通Stacking模型的本质区别在哪里?
标准答案:本质区别在于元模型训练数据的生成方式。普通Stacking直接将基模型的原始预测概率拼接后输入元模型;而BMA-Stacking则根据各基模型的后验概率对原始预测进行加权平均,相当于利用贝叶斯框架对不确定性进行了量化与平滑,然后才输入元模型。这使得元模型能在一个信噪比更高的特征空间中进行学习,尤其在处理不平衡数据时更为鲁棒。
总结与展望
研究总结
本研究围绕电商欺诈风险预警,提出了一种基于 BMA-Stacking 的集成学习模型,旨在弥补传统方法在动态适应性、特征融合与模型鲁棒性上的不足。BMA 通过概率加权,量化了各基模型的贡献,减少了单一模型的不确定性;Stacking 则通过元学习机制,有效融合了异构模型的优势。二者的协同显著提升了对高维稀疏特征和非线性关系的捕捉能力。
在特征工程环节,我们提出了多粒度特征衍生与优化策略,结合 WOE 编码、随机森林特征重要性排序,筛选出关键特征。在模型构建中,采用贝叶斯优化进行超参数调优,并利用 SMOTE-ENN 混合采样技术缓解数据不平衡。实证结果验证了模型的有效性:BMA-Stacking 模型在召回率和 F1 分数上显著优于传统集成方法,最高分别达到 80.98% 和 83.02%。
研究展望
未来研究可在以下方面深化:一是引入社交网络、设备指纹、用户行为序列等多源异构数据,构建跨模态特征融合框架,提升模型对复杂欺诈模式的泛化能力。二是探索对抗训练与鲁棒性增强技术,以应对日益增长的对抗样本攻击。三是结合流式计算与增量学习技术,设计轻量化在线学习框架,实现模型的毫秒级动态更新,满足实时风控需求。最终,推动建立跨平台的电商欺诈预警技术标准与共享数据库,构建全行业联防联控体系。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
在实证分析中,我们进一步发现BMA-Stacking模型在SMOTE-ENN采样方式下,不仅召回率达到了80.98%的优异水平,精确率也保持在85.18%的高位,F1分数更是达到了83.02%,充分证明了该融合框架在实际风控场景中的巨大潜力。这一成果为电商平台提供了从数据预处理、特征工程到模型部署的完整解决方案。
总体而言,本研究提出的BMA-Stacking集成学习框架,通过将贝叶斯模型平均的概率加权机制与Stacking的元学习优化策略相结合,成功解决了传统欺诈检测方法在极端类别不平衡场景下的核心痛点。在SMOTE-ENN混合采样的配合下,模型对欺诈交易的识别能力得到了质的飞跃,为电商平台构建实时、精准、可解释的风控体系提供了坚实的技术基础。
从更广阔的视角来看,本研究的方法论不仅适用于电商欺诈检测,还可推广至金融风控、医疗诊断、工业异常检测等众多面临类别不平衡挑战的领域。BMA-Stacking框架所展现的灵活性与鲁棒性,使其成为处理复杂现实世界数据问题的有力工具。随着数据采集技术的不断进步和计算资源的日益丰富,这一融合框架有望在未来发挥更大的价值。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据

