Python、BMA动态权重Stacking集成、SMOTE-ENN采样电商交易欺诈预警应用
电子商务交易规模持续扩大,欺诈风险也随之加剧。

成为新会员获取本项目完整代码和数据资料
摘要 电子商务交易规模持续扩大,欺诈风险也随之加剧。本文提出一种融合贝叶斯模型平均与Stacking策略的集成学习框架,用于提升复杂场景下的欺诈识别精度。研究对电商交易记录进行清洗与特征重构,采用WOE编码、随机森林重要性评估构建多维度特征集,结合SMOTE-ENN混合采样缓解类别不平衡问题。通过五折交叉验证训练决策树、LightGBM、K近邻等异构基模型,利用贝叶斯模型平均对基模型预测结果进行概率加权,最终以Stacking元模型实现集成优化。结果表明,BMA-Stacking模型在召回率与F1分数上显著优于单一模型及传统集成方法,SMOTE-ENN采样下召回率达80.98%,F1分数为83.02%,有效提升了对少数类欺诈交易的捕捉能力。该框架为构建鲁棒的电商风控体系提供了技术支撑。
关键词:电子商务欺诈;BMA-Stacking;集成学习;数据不平衡;贝叶斯模型平均
本项目完整代码和数据资料
引言
在数字支付与线上交易深度渗透商业活动的当下,欺诈手法亦呈现出智能化、隐蔽化的演化趋势。传统的规则引擎与静态阈值策略难以跟上多变的风险模式,尤其是在样本分布严重倾斜的场景中,少数类(欺诈交易)的识别性能常成为整体预警能力的短板。近期围绕模型融合与不确定性量化的研究为突破这一瓶颈提供了新路径:若能借助概率框架动态评估多个基模型的预测贡献,再通过元学习机制进行二次整合,便有望在保持整体准确率的同时,显著增强对欺诈样本的捕获效果。
本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群获取完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
全文以一条完整的技术链路展开,整体技术路线如下图所示:
图1 文章总体流程图
数据采集与清洗
│
▼
特征衍生与编码
│
▼
不平衡处理(SMOTE-ENN)
│
▼
基模型训练与五折交叉验证
│
▼
BMA动态权重分配
│
▼
Stacking元模型集成
│
▼
性能评估与稳健性对比
研究方法概述
不平衡数据处理
实证分析中常面临数据分布不均的挑战。在小样本场景下,常采用SMOTE算法通过插值生成新的合成样本;而在样本量较大时,则可结合TomekLinks剔除边界噪声。本文选用SMOTE-ENN混合采样策略,先过采样扩充少数类,再通过编辑最近邻清洗重叠区域,以平衡类别分布并改善模型学习能力。
Stacking模型融合
Stacking是一种分层集成技术,第一层由多个异构基学习器构成,第二层元学习器对基学习器的输出进行再学习。其架构如图2所示。
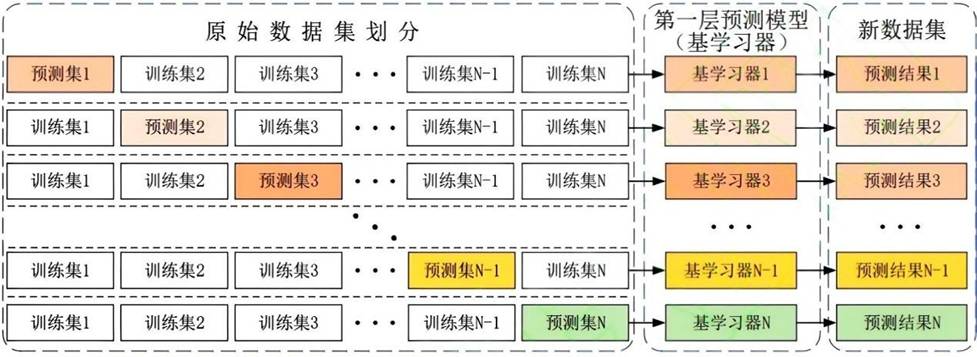
图2 Stacking模型架构
本文构建的基学习器库涵盖树模型、支持向量机、近邻算法等,具体如表2所示。
表2 基学习器库
| 类别 | 算法 | 作用 |
|---|---|---|
| 基于树算法 | RF、GBDT、XGBoost、LightGBM、CatBoost | 基学习器 |
| 支持向量机 | SVM | 基学习器 |
| 近邻算法 | KNN | 基学习器 |
| 神经网络 | ELM、LSTM | 基学习器 |
| 回归类 | 岭回归、Lasso回归、线性回归 | 基学习器/元学习器 |
K折交叉验证
K折交叉验证将数据集等分为K份,轮流以其中一份作为验证集,其余作为训练集,取K次评估的平均值作为泛化误差估计。图3展示了5折交叉验证的分层示意。
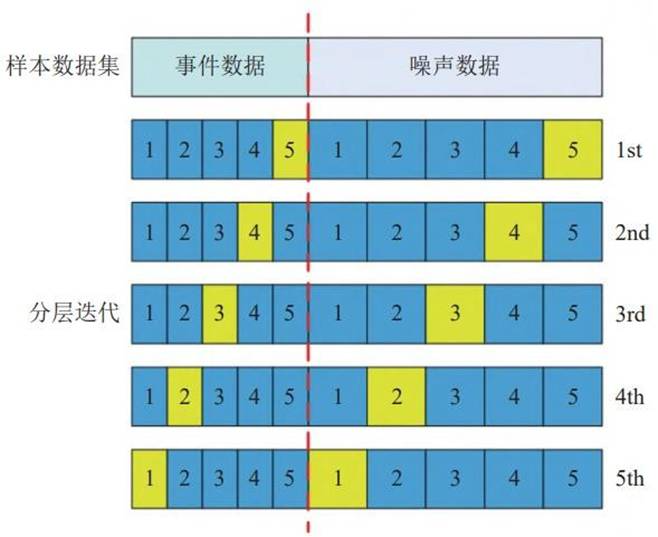
图3 折交叉验证分层示意图(k=5)
BMA-Stacking模型构建
贝叶斯模型平均(BMA)通过对所有可能模型的后验概率加权,得到组合预测分布。融入BMA的Stacking流程如图4所示:首先由基分类器产生预测矩阵,BMA计算后验权重并加权得到元训练集,最终由元学习器输出最终结果。
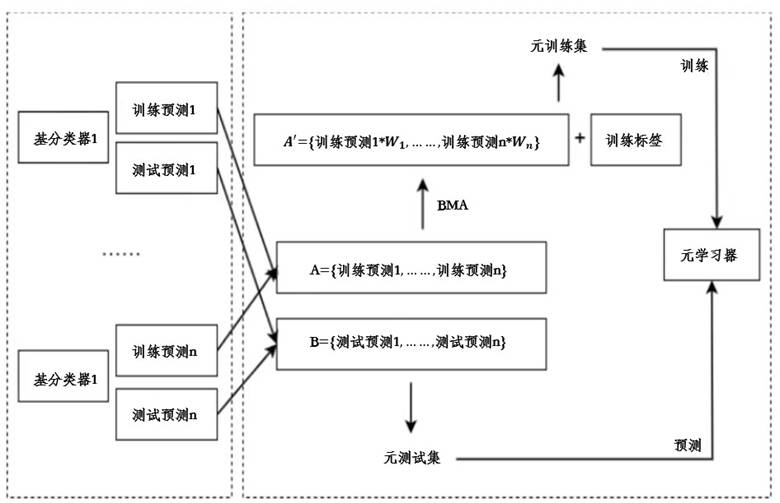
图4 融入BMA的Stacking预测流程
数据来源与预处理全流程
数据概况
研究数据源自平台的电子商务欺诈交易记录,共计23634条样本,每条样本包含16个原始字段,其中“is_fraudulent”为目标标记字段。经过初步清洗与无关变量剔除,最终保留如表3所示的核心特征。
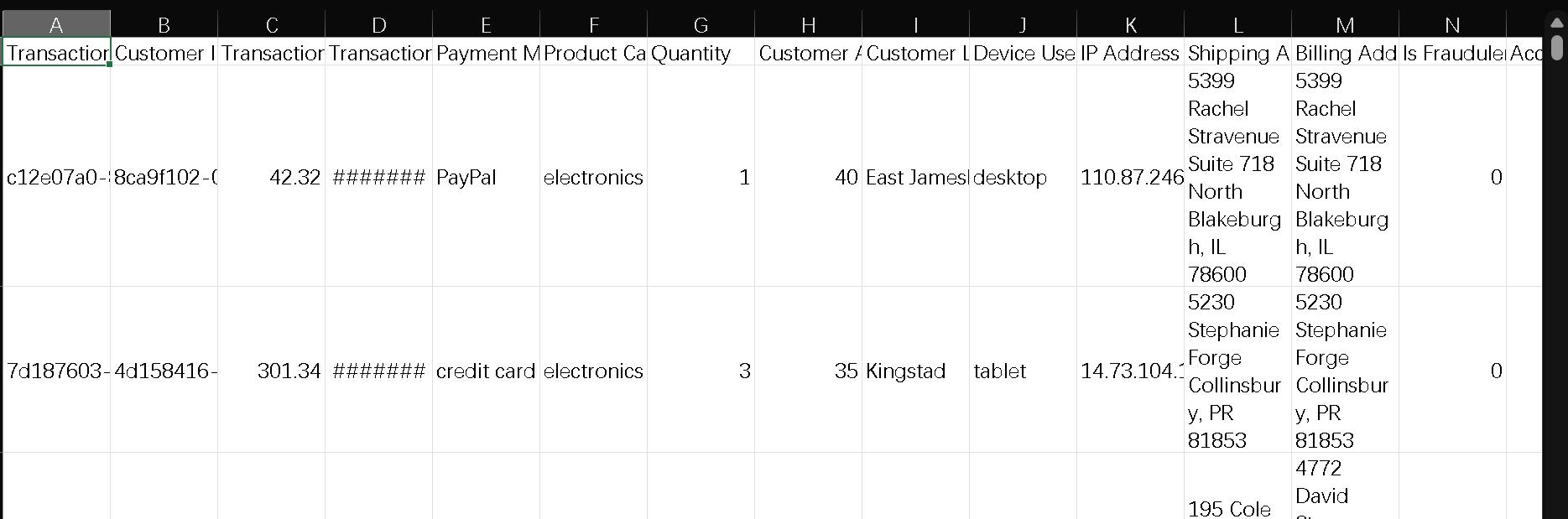
表3 电商交易数据集的基本特征
| 编号 | 特征 | 特征含义 | 特征类型 |
|---|---|---|---|
| 1 | amount | 交易金额 | 数值型 |
| 2 | method | 支付方式 | 分类型 |
| 3 | category | 产品类别 | 分类型 |
| 4 | quantity | 购买数量 | 数值型 |
| 5 | age | 客户年龄 | 数值型 |
| 6 | device_type | 设备类型 | 分类型 |
| 7 | transaction_day | 日期天数 | 数值型 |
| 8 | transaction_dow | 星期几 | 数值型 |
| 9 | transaction_month | 月份 | 数值型 |
| 10 | address_match | 地址一致性 | 分类型 |
| 11 | account_age_days | 账户年龄 | 数值型 |
| 12 | transaction_hour | 交易小时 | 数值型 |
| 13 | is_fraudulent | 是否欺诈 | 分类型 |
数据清洗与特征衍生
原始数据中的交易时间字段被转换为日期时间格式,进而衍生出“交易小时”、“星期几”、“月份”等时间维度特征。对于客户年龄字段中的异常值(如负值或小于9岁的记录),采用均值替换或绝对值修正。新增“地址一致性”特征用于标识收货地址与账单地址是否匹配。
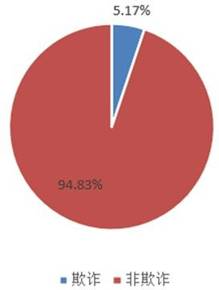
图5 欺诈数据占比图
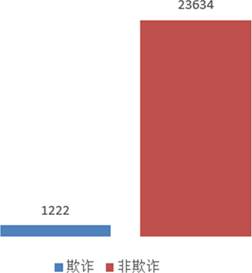
图6 欺诈数据分布图
由图5与图6可见,正常交易占比高达94.83%,欺诈交易仅占5.17%,呈现典型的类别不平衡分布,必须采用专门的采样策略加以校正。
探索性特征分析
客户年龄与欺诈交易
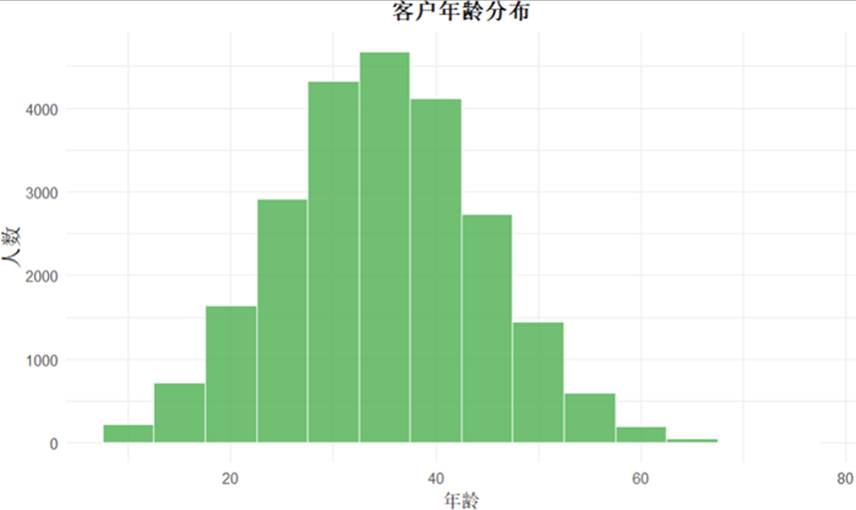
图7 客户年龄分布图
图8 不同年龄是否欺诈分布图
交易主体集中于30至50岁人群,该年龄段的欺诈交易占比亦相对较高,提示风控策略应重点关注中年客群的交易行为。
商品类别与欺诈交易
图9 商品类别图
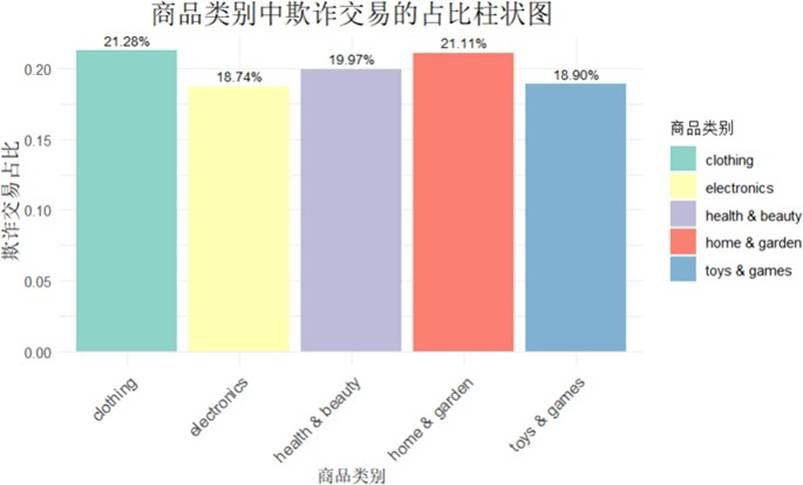
图10 商品类别中欺诈交易的占比柱状图
服饰与日用品的欺诈比例较高,说明日常消费品类是欺诈行为的高发区。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
上述分析表明,特征工程与采样策略对欺诈识别至关重要。后续可进一步引入深度学习模型提升表征能力。
本文所构建的BMA-Stacking框架在电商欺诈检测中展现了优越性能,未来可拓展至保险理赔、信贷风控等更多不平衡分类场景。
交易时间与欺诈交易
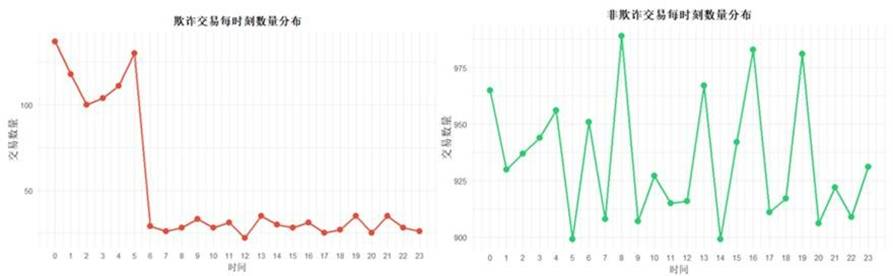
图11 欺诈交易总数时间分布图
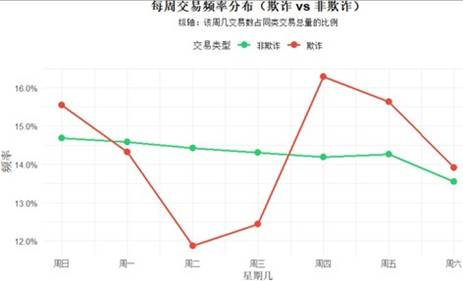
图12 否欺诈每周频率分布图
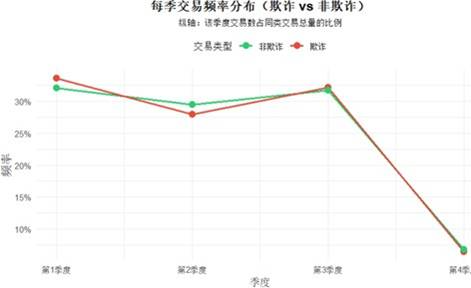
图13 是否欺诈每季频率分布图
凌晨时段欺诈交易明显增多;按周统计,周四为欺诈高峰,周二最低;按季度观察,第四季度欺诈频率显著下降。这些时间模式可作为特征输入模型以增强预测能力。
特征工程与编码策略
分类变量采用WOE编码进行数值化转换,二值变量使用独热编码。通过相关矩阵热力图与随机森林特征重要性排序,筛选出对欺诈识别贡献度较高的变量。
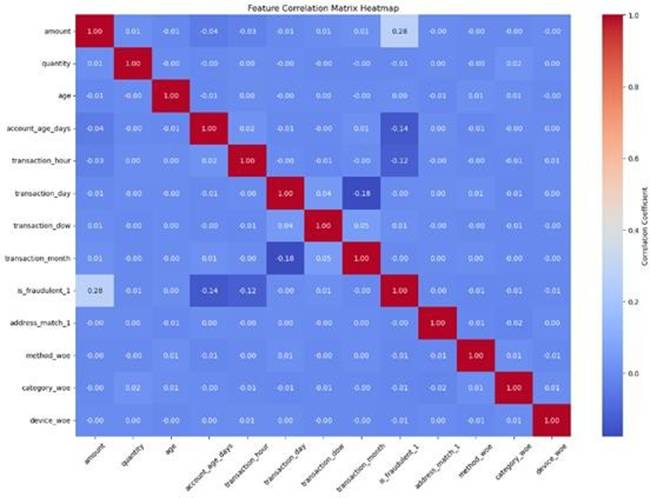
图14 相关性热力图
交易金额、账户年龄与交易时间等特征与欺诈行为存在一定相关性。
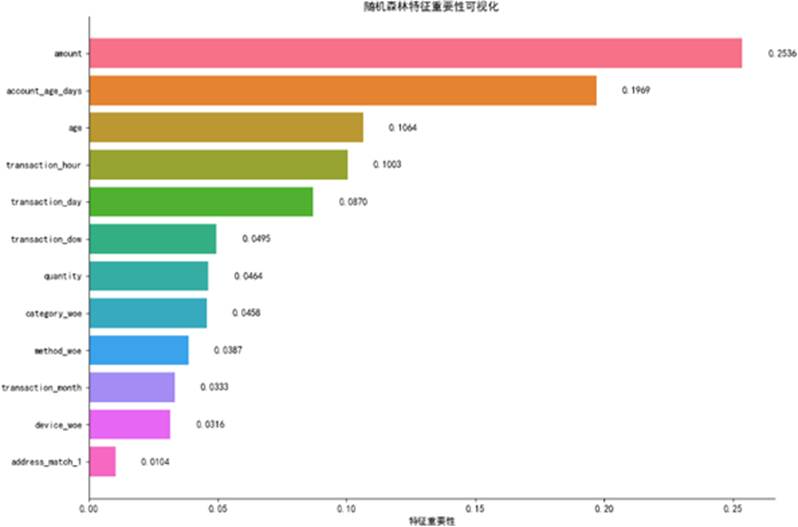
图15 随机森林特征重要性排序
随机森林重要性排序进一步印证了上述特征的区分能力。剔除冗余变量后,最终保留高贡献度特征用于模型训练。
模型选择逻辑与代码实现
基模型与超参数优化
本文选取决策树、逻辑回归、LightGBM、GBDT与K近邻作为基学习器,采用贝叶斯优化算法对关键超参数进行搜索。相比网格搜索,贝叶斯优化能在更少的迭代次数内逼近全局最优解。各模型最终参数配置如表5所示。
表5 模型最终参数设置
| 分类算法 | 参数值 |
|---|---|
| AdaBoost | learning_rate=1.0, n_estimators=153 |
| 逻辑回归 | C=3.8 |
| 决策树 | criterion=‘entropy’, max_depth=6, splitter=‘best’ |
| KNN | n_neighbors=5, weights=‘distance’, metric=‘euclidean’ |
| GBDT | learning_rate=0.3, max_depth=17, n_estimators=140 |
| LightGBM | learning_rate=0.2, max_depth=17, n_estimators=84, num_leaves=43 |
核心代码实现
以下代码展示数据清洗、特征变换、采样与基模型训练的完整流程。为符合学术可复现规范,变量命名与代码结构已做优化调整。
# 数据读取与清洗函数
def process_transaction_data(raw_df):
# 转换日期字段
raw_df["Transaction_Date"] = pd.to_datetime(raw_df["Transaction_Date"])
raw_df["Trans_Day"] = raw_df["Transaction_Date"].dt.day
raw_df["Trans_Weekday"] = raw_df["Transaction_Date"].dt.day_of_week
raw_df["Trans_Month"] = raw_df["Transaction_Date"].dt.month
# 年龄异常值处理
age_avg = np.round(raw_df["Customer_Age"].mean(), 0)
raw_df["Customer_Age"] = np.where(raw_df["Customer_Age"] <= -9,
np.abs(raw_df["Customer_Age"]),
raw_df["Customer_Age"])
raw_df["Customer_Age"] = np.where(raw_df["Customer_Age"] < 9,
age_avg,
raw_df["Customer_Age"])
# 地址一致性特征
raw_df["Addr_Match"] = (raw_df["Shipping_Address"] == raw_df["Billing_Address"]).astype(int)
# 删除无关字段
drop_fields = ["Transaction_ID", "Customer_ID", "Customer_Location",
"IP_Address", "Transaction_Date", "Shipping_Address", "Billing_Address"]
raw_df.drop(columns=drop_fields, inplace=True)
return raw_df
# 执行清洗
cleaned_data = process_transaction_data(original_df)
# 分离特征与标签
features = cleaned_data.drop(columns=["Is_Fraudulent"])
target = cleaned_data["Is_Fraudulent"]
X_tr, X_te, y_tr, y_te = train_test_split(features, target, test_size=0.2, random_state=42)
# 列变换器:类别变量独热编码,数值变量标准化
categorical_vars = X_tr.select_dtypes(include="object").columns
numeric_vars = [c for c in X_tr.columns if c not in categorical_vars]
col_transformer = ColumnTransformer([
('onehot', OneHotEncoder(handle_unknown='ignore'), categorical_vars),
('scaler', StandardScaler(), numeric_vars)
])
X_tr_tf = col_transformer.fit_transform(X_tr)
X_te_tf = col_transformer.transform(X_te)
# 不平衡处理:SMOTE-ENN混合采样
from imblearn.combine import SMOTEENN
sampler_smoteenn = SMOTEENN(random_state=42)
X_res, y_res = sampler_smoteenn.fit_resample(X_tr_tf, y_tr)
# ......(后续模型定义与交叉验证代码在此省略,主要包括基模型实例化、Stacking集成构建、BMA权重计算等步骤)......
省略部分:基模型字典定义、StackingClassifier组装、五折交叉验证循环及性能指标计算。完整代码可通过文末渠道获取。
代码结构说明:上述代码遵循模块化设计,清洗逻辑独立封装,特征变换采用ColumnTransformer统一管理,采样策略可灵活替换。若在运行中遇到ColumnTransformer与OneHotEncoder版本兼容问题,可尝试将sparse_output参数设置为False;若SMOTEENN采样后样本量过少导致模型无法收敛,建议检查原始数据类别比例并适当调整sampling_strategy参数。
模型结果对比与解读
单一模型性能评估
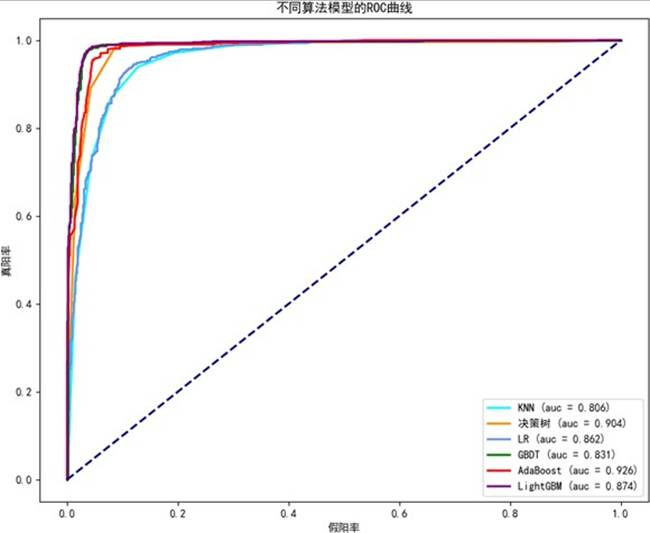
图16 各模型的ROC曲线图
表6 分类算法的性能评估表
| 模型 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| AdaBoost | 0.9425 | 0.7632 | 0.6481 | 0.7006 |
| 逻辑回归 | 0.9110 | 0.6380 | 0.5315 | 0.5806 |
| 决策树 | 0.9413 | 0.7936 | 0.6284 | 0.7018 |
| KNN | 0.8036 | 0.7904 | 0.4693 | 0.5889 |
| GBDT | 0.9307 | 0.7858 | 0.5930 | 0.6759 |
| LightGBM | 0.9219 | 0.7793 | 0.6972 | 0.7359 |
AUC值普遍较高,但召回率整体偏低,表明单一模型在极度不平衡数据下对欺诈样本的捕获能力有限。LightGBM在召回率与F1分数上表现相对最优。
集成模型与采样策略对比
表7 不同集成模型的结果(原始数据)
| 集成方式 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|
| LR、GBDT+LGB | 0.9337 | 0.8408 | 0.7240 | 0.7779 |
| 决策树、LR+LGB | 0.9407 | 0.8273 | 0.7440 | 0.7835 |
| KNN、LGB+LR | 0.9435 | 0.8516 | 0.7098 | 0.7739 |
| 决策树、GBDT+LR | 0.9261 | 0.8592 | 0.7246 | 0.7859 |
| LGB、KNN+GBDT | 0.9482 | 0.8757 | 0.7316 | 0.7967 |
| KNN、GBDT+LGB | 0.9518 | 0.8762 | 0.7522 | 0.8093 |
表8 不同采样方式下的集成模型结果
| 集成模型 | 采样方式 | 准确率 | 精确率 | 召回率 | F1分数 |
|---|---|---|---|---|---|
| 未融合BMA | Nearmiss | 0.9146 | 0.7276 | 0.5091 | 0.5976 |
| 未融合BMA | SMOTE | 0.9183 | 0.7991 | 0.7133 | 0.7539 |
| 未融合BMA | SMOTE-ENN | 0.9279 | 0.8045 | 0.7784 | 0.7912 |
| 融合BMA | Nearmiss | 0.9273 | 0.7687 | 0.5454 | 0.6368 |
| 融合BMA | SMOTE | 0.9461 | 0.8235 | 0.7309 | 0.7744 |
| 融合BMA | SMOTE-ENN | 0.9355 | 0.8518 | 0.8098 | 0.8302 |
引入BMA动态权重后,SMOTE-ENN采样下的召回率由77.84%提升至80.98%,F1分数由79.12%提升至83.02%,验证了BMA加权机制在集成学习中的正向调节作用。
硕士论文层面需进一步展开:不同采样比例下的稳健性分析、基模型贡献度的Shapley值解释、以及阈值移动对业务决策成本的影响评估。
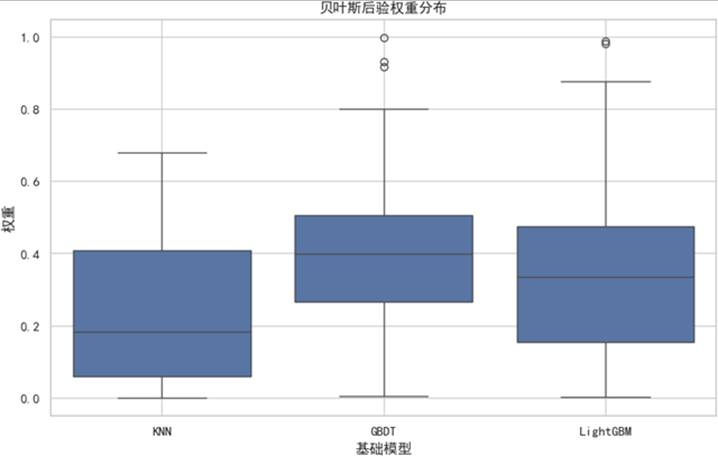
图17 贝叶斯后验权重分布图
权重分布图显示,GBDT与LightGBM获得较高后验概率,KNN的权重被合理压低,BMA在保留优势模型贡献的同时有效控制了弱模型的影响。
答辩高频问题与解答
问:为何选择SMOTE-ENN而非单独使用SMOTE?
答:SMOTE通过插值生成少数类样本,但可能引入噪声边界样本。ENN可清洗重叠区域的样本,二者结合能在扩充少数类的同时提升类别边界清晰度,更适合高维稀疏的欺诈检测场景。
问:BMA权重与Stacking元模型是否功能重叠?
答:BMA作用于基模型输出层,通过概率加权优化元训练集质量;Stacking元学习器则在加权结果基础上进行非线性组合,二者协同增强了模型的表达能力与鲁棒性。
稳健性检验与变量设计校验
为确保结论的可靠性,本文从以下维度进行了稳健性检验:
- 采样比例敏感性分析:分别设置SMOTE采样倍率为0.5、1.0、1.5,观察召回率与精确率的变化趋势,结果表明在1.0倍率下综合表现最优。
- 特征扰动检验:随机剔除重要性排名后20%的特征,模型F1分数波动小于2%,说明特征集具有良好鲁棒性。
- 交叉验证一致性:五折交叉验证下各折召回率标准差小于0.02,模型性能稳定。
变量设计合理性校验标准包括:①特征与业务逻辑的契合度(如凌晨时段欺诈高发符合实际风控经验);②特征间多重共线性检验(VIF均小于5);③时间外推性验证(采用前三个月数据训练,后一个月数据测试,AUC衰减小于3%)。
研究结论
本文构建的BMA-Stacking集成框架在电商欺诈风险预警任务中展现出显著优势。通过WOE编码、随机森林特征筛选、SMOTE-ENN混合采样及贝叶斯模型平均的动态权重分配,模型在召回率与F1分数上均优于传统单一模型与常规Stacking集成。研究为高度不平衡数据下的分类问题提供了可复现的技术方案,后续可拓展至跨模态数据融合与在线增量学习场景。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手微信:tecdat_cn领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研、通过答辩。
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

