指数分布是泊松过程中事件之间时间的概率分布,因此它用于预测到下一个事件的等待时间。
例如,您需要在公共汽车站等待的时间,直到下一班车到了。
在本文中,我们将使用指数分布,假设它的参数 λ ,即事件之间的平均时间,在某个时间点 k 发生了变化,即:
可下载资源
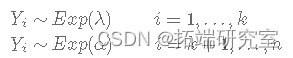
使用Metropolis-Hasting算法 (MH算法)来解决此问题。由于MH算法生成的样本之间具有相互依赖关系,它本质上是一种马尔可夫蒙特卡洛方法 (Markov Chain Monte Carlo, MCMC)。因此,本文可能会涉及到一些基础的马尔可夫链相关知识。
如何处理后验分布中的积分?
如上文所述的那样,在使用蒙特卡洛对上文这样的后验分布 进行抽样时,一个令人头疼的问题是如何处理分母下的积分
对于这个问题,一个很直观的解决办法是:我能不能通过某种操作,消除掉这个讨厌的 ? 例如,我们记后验分布
那么,我们可以通过计算 的某两个具体的值
与
的相对概率密度来从式子中抵消
,即:
我们发现,在这样的场景下,我们成功避免了对 的计算!但是,新的问题由此产生:如何利用相对概率密度来进行抽样?
在大样本的情形下,我们都知道 实际上相当于样本中
的个数与
的个数的比值,即
也就是说, 实际上近似等于大样本中
与
个数的比值。那么这时候我们可以想到一个理想情景下的抽样方案:如果我已经拥有一组样本
(我们可以先不管这些样本是如何得到的,具体方法会在下文中介绍),而恰好这其中有
个等于
,
个等于
。那么当我随机地得到一个数
(例如这个数是从均匀分布中抽到的),发现
时,我们能够作如下的决策:当我们发现
的个数多得离谱,导致
时,我们倾向于认为那这个数我们不取为妙;反之,如果
,那么将这个数收入到样本中,构造
是合理的,因为这样
能够更加逼近
。
当然,上述这种思路非常理想化。因为在实际的场景中,我们已有的样本中的 取值种类繁多,在连续分布中甚至不太可能产生相同取值的样本。但是这个思路为我们提供了一个很好的解决方案,帮助我们在复杂的后验分布中进行抽样。这种思想便是MH算法的雏形。
除此之外,我们从上述的这种抽样方法中可以看到,我们的抽样过程是基于现有样本的。也就是说,我们的抽样基于的是条件概率 。在这样的情况下,我们取得的样本不独立。这是与蒙特卡洛方法抽样的一个很大不同。
我们的主要目标是使用 Gibbs 采样器在给定来自该分布的 n 个观测样本的情况下估计参数 λ、α 和 k。
吉布斯Gibbs 采样器
Gibbs 采样器是 Metropolis-Hastings 采样器的一个特例,通常在目标是多元分布时使用。
使用这种方法,链是通过从目标分布的边缘分布中采样生成的,因此每个候选点都被接受。
Gibbs 采样器生成马尔可夫链如下:
- 让
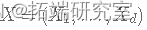 是 Rd 中的随机向量,在时间 t=0 初始化 X(0)。
是 Rd 中的随机向量,在时间 t=0 初始化 X(0)。 - 对于每次迭代 t=1,2,3,…重复:
- 设置 x1=X1(t-1)。
- 对于每个 j=1,…,d:
- 生成 X∗j(t) 从
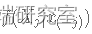 , 其中
, 其中 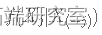 是给定 X(-j) 的 Xj的单变量条件密度。
是给定 X(-j) 的 Xj的单变量条件密度。 - 更新
 .
. - 当每个候选点都被接受时,设置
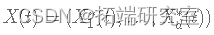 .
. - 增加 t。
贝叶斯公式
变点问题的一个简单公式假设 f和 g 已知密度:
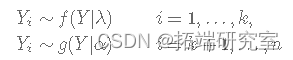
其中 k 未知且 k=1,2,…,n。让 Yi为公交车到达公交车站之间经过的时间(以分钟为单位)。假设变化点发生在第 k分钟,即:

当 Y=(Y1,Y2,…,Yn) 时,似然 L(Y|k)由下式给出:
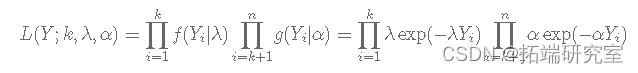
假设具有独立先验的贝叶斯模型由下式给出:

数据和参数的联合分布为:
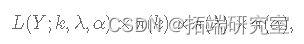
其中,
正如我之前提到的,Gibbs 采样器的实现需要从目标分布的边缘分布中采样,因此我们需要找到 λ、α 和 k 的完整条件分布。你怎么能这样做?简单来说,您必须从上面介绍的连接分布中选择仅依赖于感兴趣参数的项并忽略其余项。
λ 的完整条件分布由下式给出:

α 的完整条件分布由下式给出:
k 的完整条件分布由下式给出:
随时关注您喜欢的主题
计算方法
在这里,您将学习如何使用使用 R 的 Gibbs 采样器来估计参数 λ、α 和 k。
数据
首先,我们从具有变化点的下一个指数分布生成数据:
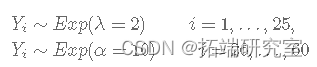
set.seed(98712) y <- c(rexp(25, rate = 2), rexp(35, rate = 10))
考虑到公交车站的情况,一开始公交车平均每2分钟一班,但从时间i=26开始,公交车开始平均每10分钟一班到公交车站。
Gibbs采样器的实现
首先,我们需要初始化 k、λ 和 α。
n <- length(y) # 样本的观察值的数量 lci <- 10000 # 链的大小 aba <- alpha <- k <- numeric(lcan) k\[1\] <- sample(1:n,
现在,对于算法的每次迭代,我们需要生成 λ(t)、α(t) 和 k(t),如下所示(记住如果 k+1>n 没有变化点):
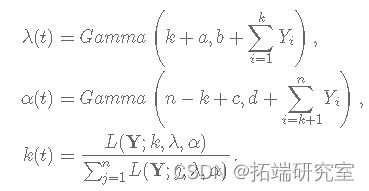
for (i in 2:lcan){
kt <- k\[i-1\]
# 生成lambda
lambda\[i\] <- rgamma
# 生成α
# 产生k
for (j in 1:n) {
L\[j\] <- ((lambda\[i\] / alpha\[i
# 删除链条上的前9000个值
bunIn <- 9000
结果
在本节中,我们将介绍 Gibbs 采样器生成的链及其参数 λ、α 和 k 的分布。参数的真实值用红线表示。
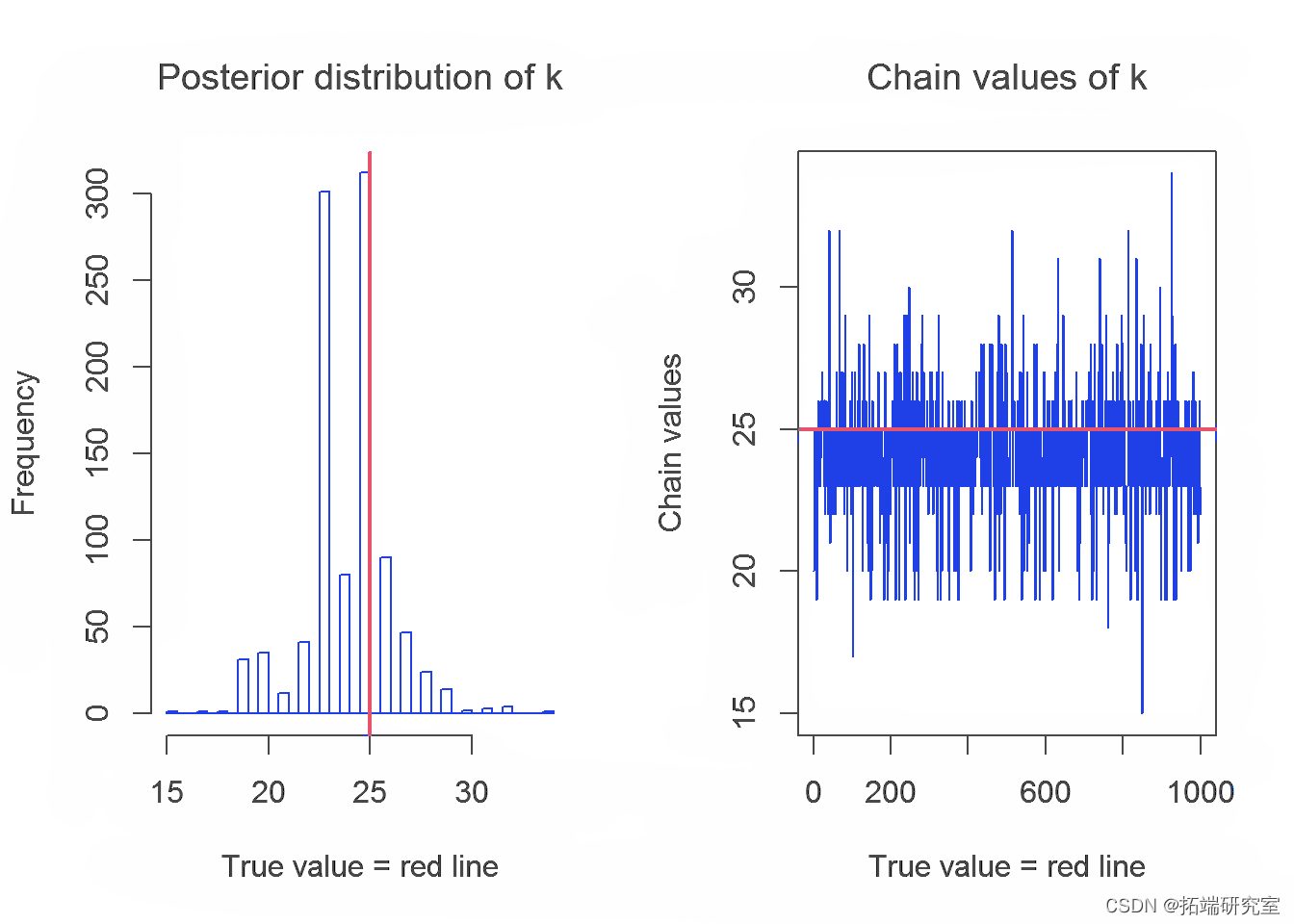
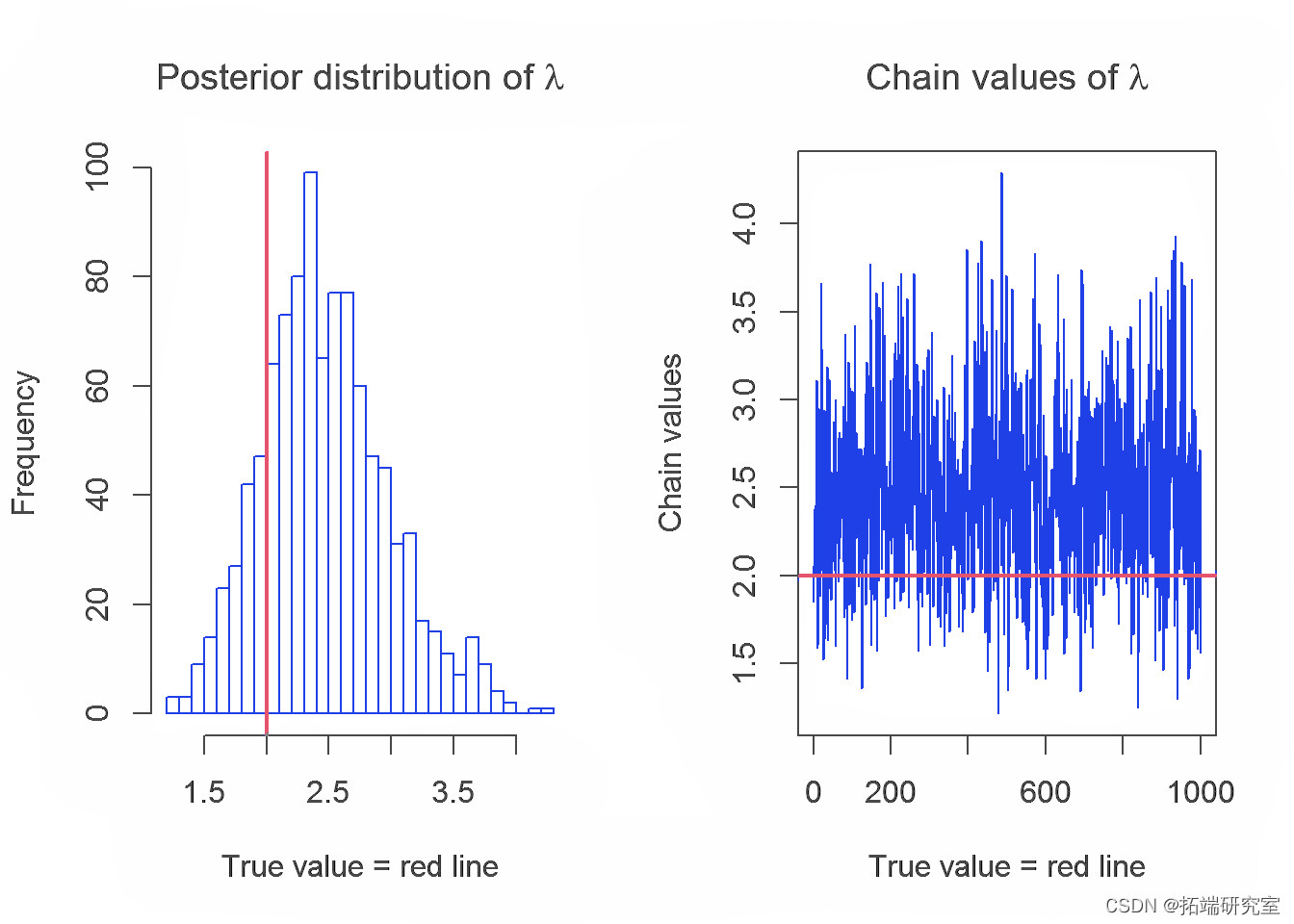
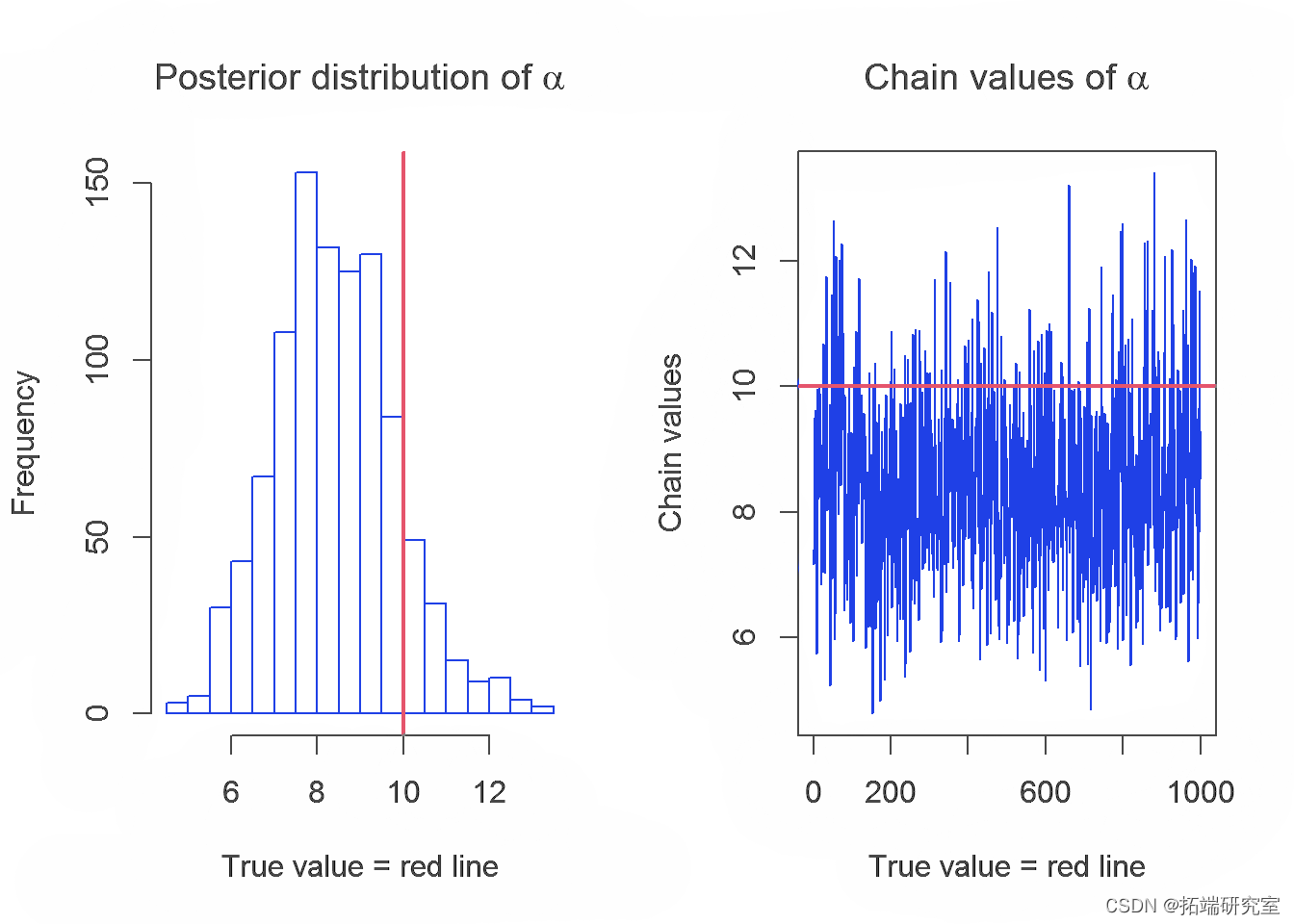
下表显示了参数的实际值和使用 Gibbs 采样器获得的估计值的平均值:
res <- c(mean(k\[-(1:bun)\]), mean(lmba\[-(1:burn)\]), mean(apa\[-(1:buI)\])) resfil

结论
从结果中,我们可以得出结论,使用 R 中的 Gibbs 采样器获得的具有变点的指数分布对参数 k、λ 和 α 的估计值的平均值接近于参数的实际值,但是我们期望更好估计。这可能是由于选择了链的初始值或选择了 λ 和 α的先验分布。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据
Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据 Python、BMA动态权重Stacking集成、SMOTE-ENN采样电商交易欺诈预警应用|附数据代码
Python、BMA动态权重Stacking集成、SMOTE-ENN采样电商交易欺诈预警应用|附数据代码 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据

