
最近我们被客户要求撰写关于Copula 的研究报告。copula是将多变量分布函数与其边缘分布函数耦合的函数,通常称为边缘。
Copula是建模和模拟相关随机变量的绝佳工具。Copula的主要吸引力在于,通过使用它们,你可以分别对相关结构和边缘(即每个随机变量的分布)进行建模。
copulas如何工作
首先,让我们了解copula的工作方式。
可下载资源
作者

set.seed(100)
m < - 3
n < - 2000
z < - mvrnorm(n,mu = rep(0,m),Sigma = sigma,empirical = T)
假定我们的组合中有两个可违约的资产a,b,我们想对其违约时间进行模拟。我们假定风险资产a和b的违约时间服从Gamma和Beta分布:
如果我们分别对 或者
进行模拟很简单,分别从各自的分布抽样就可以了。但事实上,两种资产之间违约与否很可能存在相关性。分别抽样他们两个之间肯定是不相关的。与此同时,求Gamma和Beta分布的联合密度函数也是非常难求的。
因此我们就引入Coplua函数来假定这两个分布之间的联系。比如高斯Copula。
当然这种关系都是你假定的,并不一定是真的。比如,你也可以用阿基米德Copula来刻画。2008年次贷危机也是因为业界都是只用单纯的高斯Copula来刻画联系低估了风险造成的。
当我们假定了他们之间的联系之后,我们就可以模拟两种风险资产存在相关性的违约时间了。
具体方法为:
1)先从一个二维高斯分布产生随机产生(x1 , x2)两个变量,x1,x2是存在相关性的。相关性通过设定二维正态分布的协方差矩阵来确定。
2)根据多维正态分布的性质,x1, x2的边缘分布都是一维正态分布。将生成的x1, x2带入一维正态分布得到对应的概率u1, u2。需要注意的是u1, u2此时也是存在关系的。
3)根据风险资产a、b违约时间各自的CDF逆函数就可以产生相关联的违约时间了:
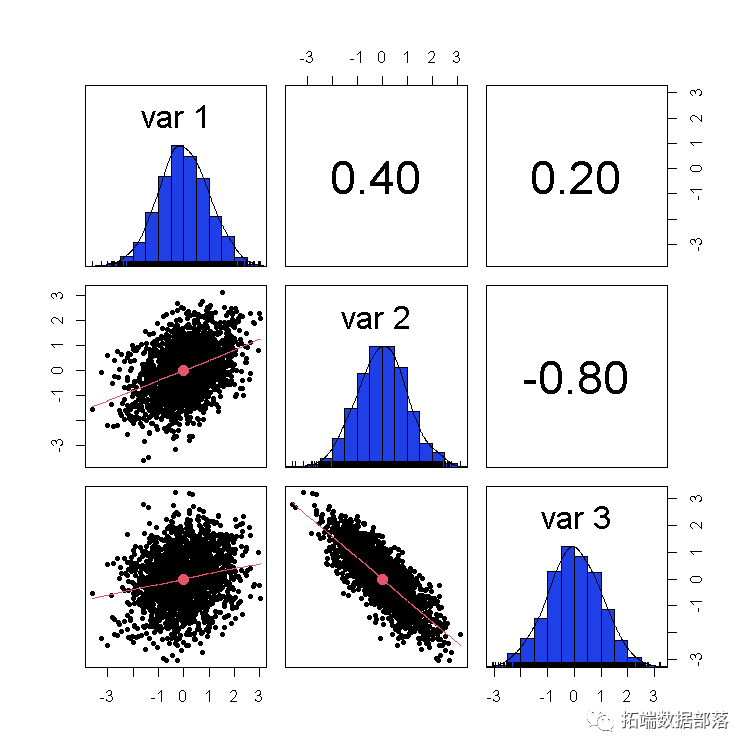
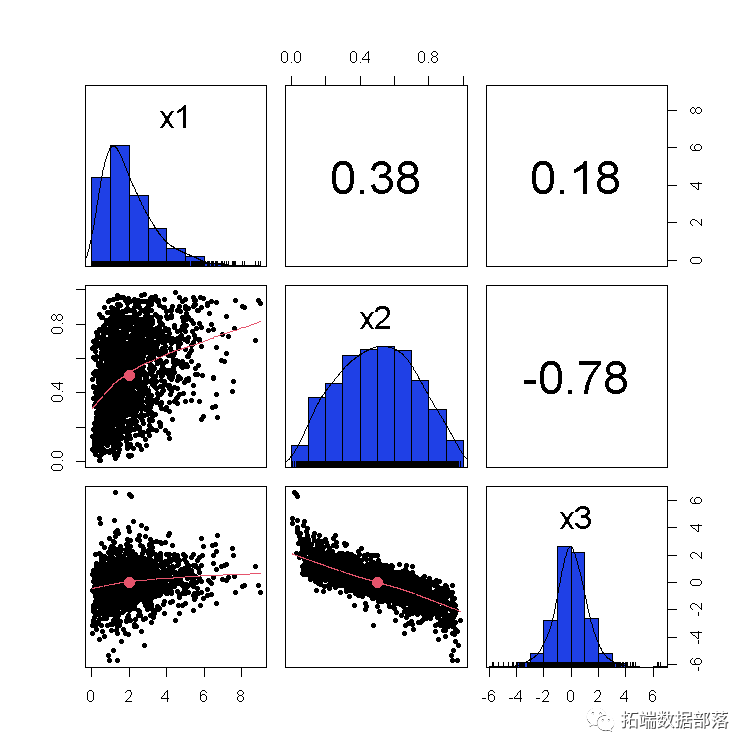
我们使用cor()和散点图矩阵检查样本相关性。
pairs.panels(Z)
[,1] [,2] [,3]
[1,] 1.0000000 0.3812244 0.1937548
[2,] 0.3812244 1.0000000 -0.7890814
[3,] 0.1937548 -0.7890814 1.0000000
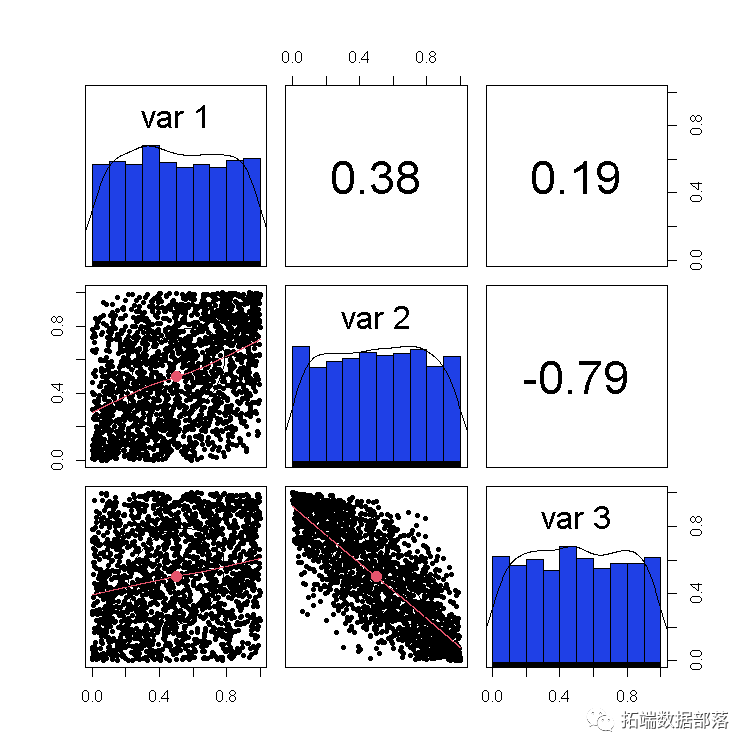
pairs.panels(U)
这是包含新随机变量的散点图矩阵u。
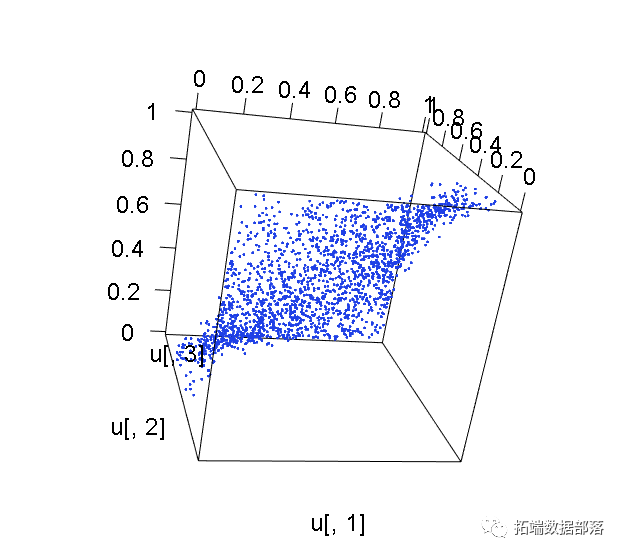
我们可以绘制矢量的3D图表示u。
现在,作为最后一步,我们只需要选择边缘并应用它。我选择了边缘为Gamma,Beta和Student,并使用下面指定的参数。
x1 < - qgamma(u [,1],shape = 2,scale = 1)
x2 < - qbeta(u [,2],2,2)
x3 < - qt(u [,3],df = 5)
下面是我们模拟数据的3D图。
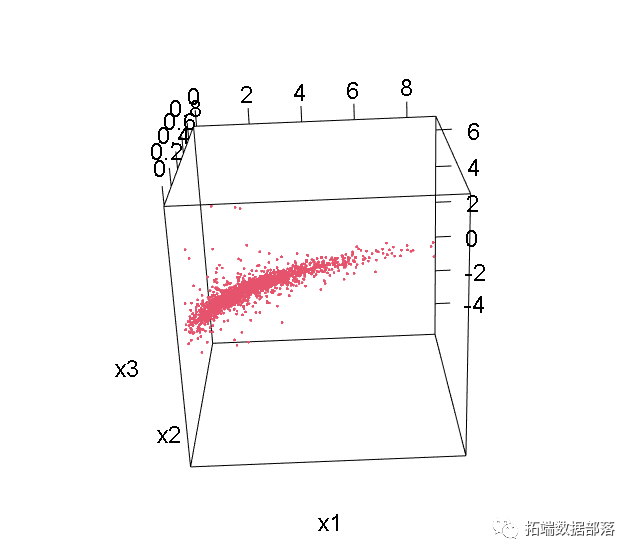
df < - cbind(x1,x2,x3)
pairs.panels(DF)
x1 x2 x3
x1 1.0000000 0.3812244 0.1937548
x2 0.3812244 1.0000000 -0.7890814
x3 0.1937548 -0.7890814 1.0000000
这是随机变量的散点图矩阵:
使用copula
让我们使用copula复制上面的过程。
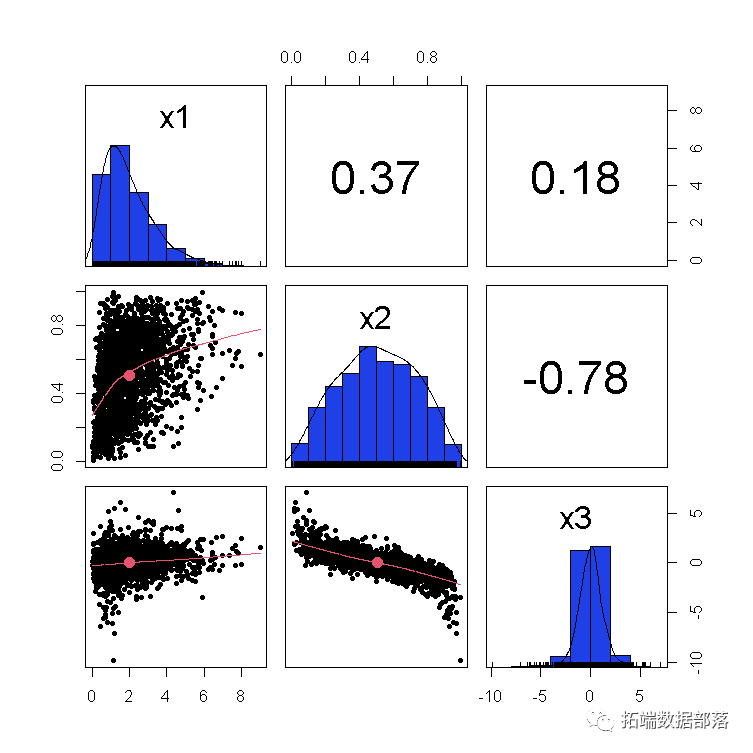
现在我们已经通过copula(普通copula)指定了相依结构并设置了边缘,mvdc()函数生成了所需的分布。然后我们可以使用rmvdc()函数生成随机样本。
set.seed(100)
myCop < - (param = c(0.4,0.2,-0.8),dim = 3,dispstr =“un”)
myMvd < - (copula = myCop,margin = c(“gamma”,“beta”,“t”)
)
现在我们已经通过copula(普通copula)指定了相依结构并设置了边缘,mvdc()函数生成了所需的分布。然后我们可以使用该rmvdc()函数生成随机样本。
colnames(Z2)< - c(“x1”,“x2”,“x3”)
pairs.panels(Z2)
模拟数据当然非常接近之前的数据,显示在下面的散点图矩阵中:
应用示例
现在为现实世界的例子。我们将拟合两个股票 ,并尝试使用copula模拟 。
让我们在R中加载 :
cree < - read.csv('cree_r.csv',header = F)$ V2
yahoo < - read.csv('yahoo_r.csv',header = F)$ V2
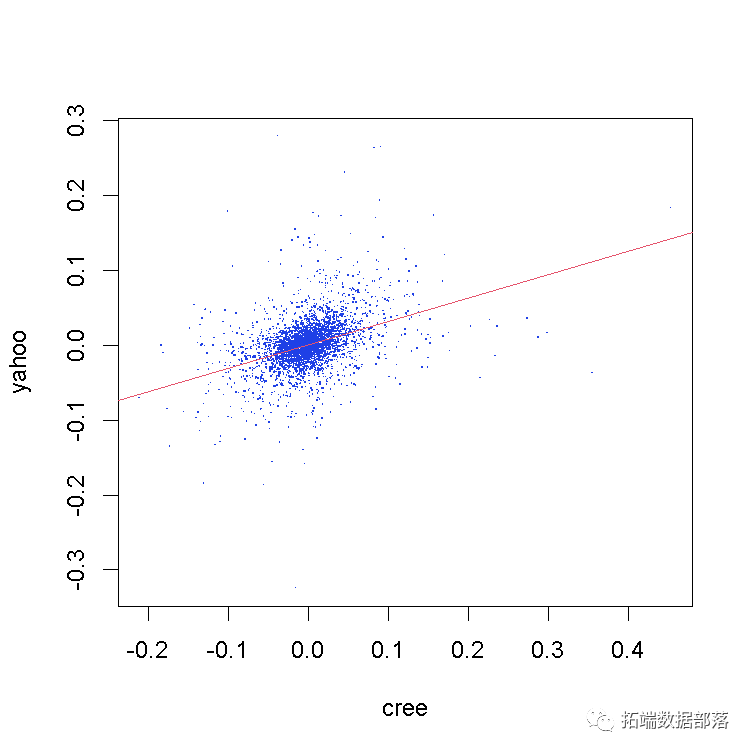
在直接进入copula拟合过程之前,让我们检查两个股票收益之间的相关性并绘制回归线:
我们可以看到 正相关 :
在上面的第一个例子中,我选择了一个正态的copula模型,但是,当将这些模型应用于实际数据时,应该仔细考虑哪些更适合数据。例如,许多copula更适合建模非对称相关,其他强调尾部相关性等等。我对股票回报的猜测是,t-copula应该没问题,但是猜测肯定是不够的。本质上, 允许我们通过函数使用BIC和AIC执行copula选择 :
pobs(as.matrix(cbind(cree,yahoo)))[,1]
selectedCopula
$ PAR
[1] 0.4356302
$ PAR2
[1] 3.844534
拟合算法确实选择了t-copula并为我们估计了参数。
让我们尝试拟合建议的模型,并检查参数拟合。
t.cop
set.seed(500)
m < - pobs(as.matrix(cbind(cree,yahoo)))
COEF(FIT)
rho.1 df
0.43563 3.84453
我们来看看我们刚估计的copula的密度
rho < - coef(fit)[1]
df < - coef(fit)[2]
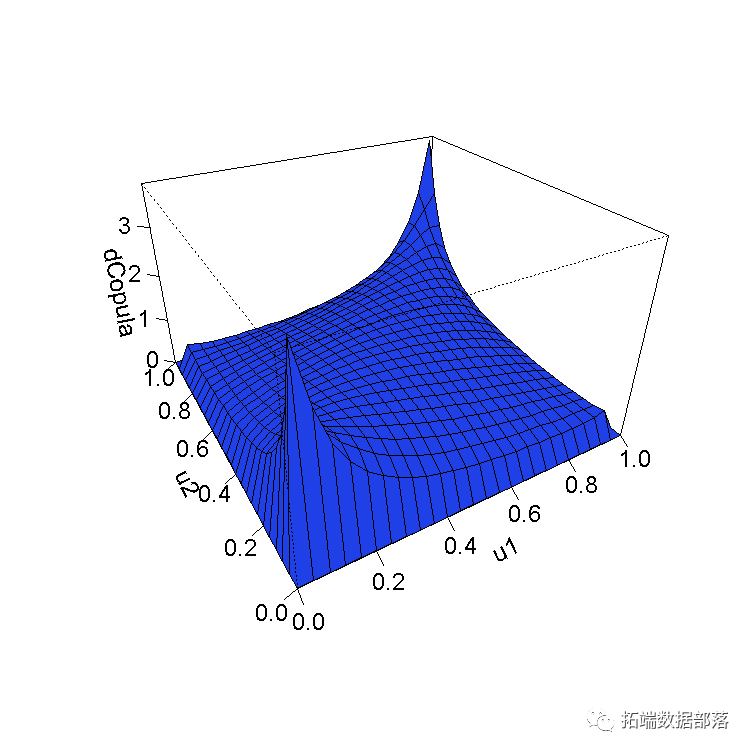
现在我们只需要建立Copula并从中抽取3965个随机样本。
rCopula(3965,tCopula( = 2, ,df = df))
[,1] [,2]
[1,] 1.0000000 0.3972454
[2,] 0.3972454 1.0000000
这是包含的样本的图:
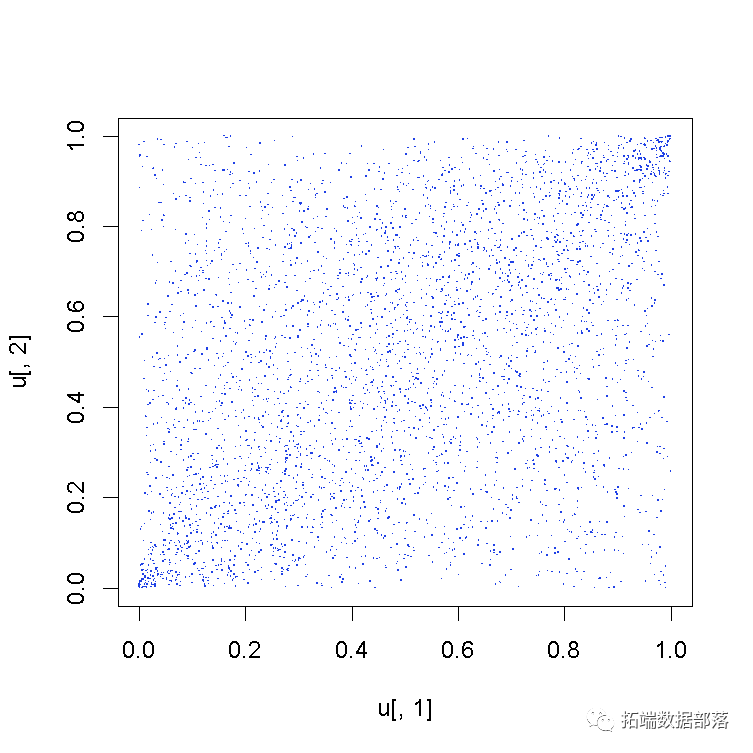
t-copula通常适用于在极值(分布的尾部)中存在高度相关性的现象。
现在我们面临困难:对边缘进行建模。为简单起见,我们将假设正态分布 。因此,我们估计边缘的参数。
两个直方图显示如下
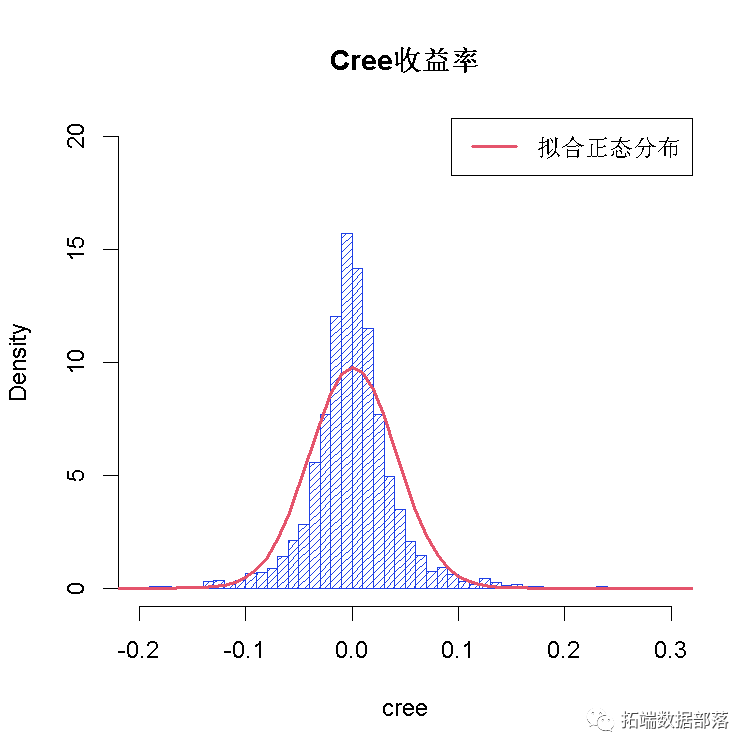
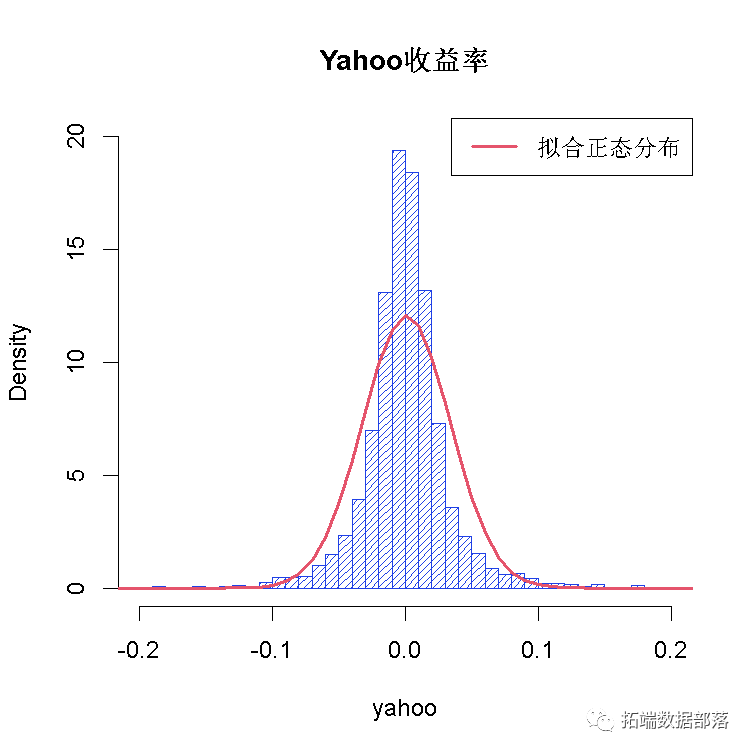
现在我们在函数中应用copula,从生成的多变量分布中获取模拟观测值。最后,我们将模拟结果与原始数据进行比较。
这是在假设正态分布边缘和相依结构的t-copula的情况下数据的最终散点图:
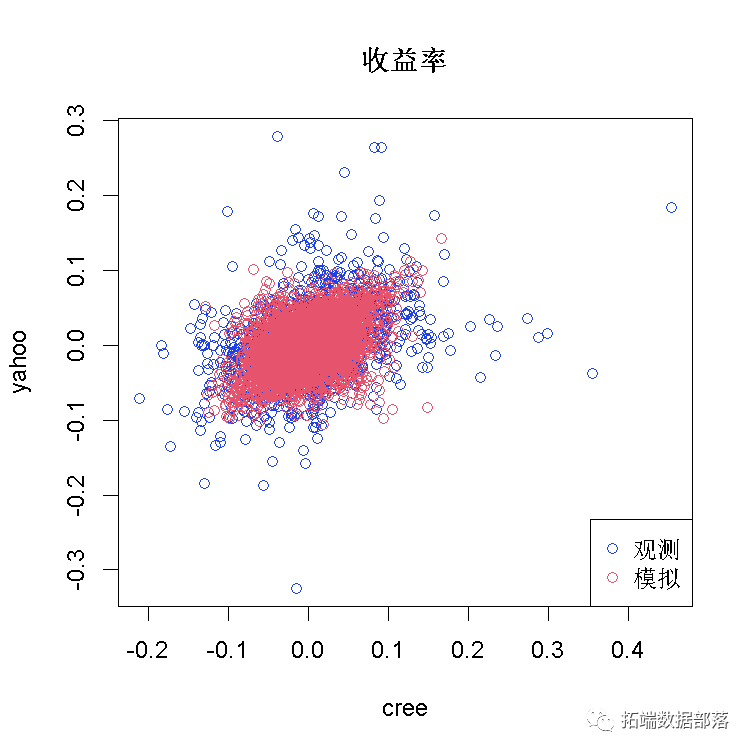
正如您所看到的,t-copula导致结果接近实际观察结果 。
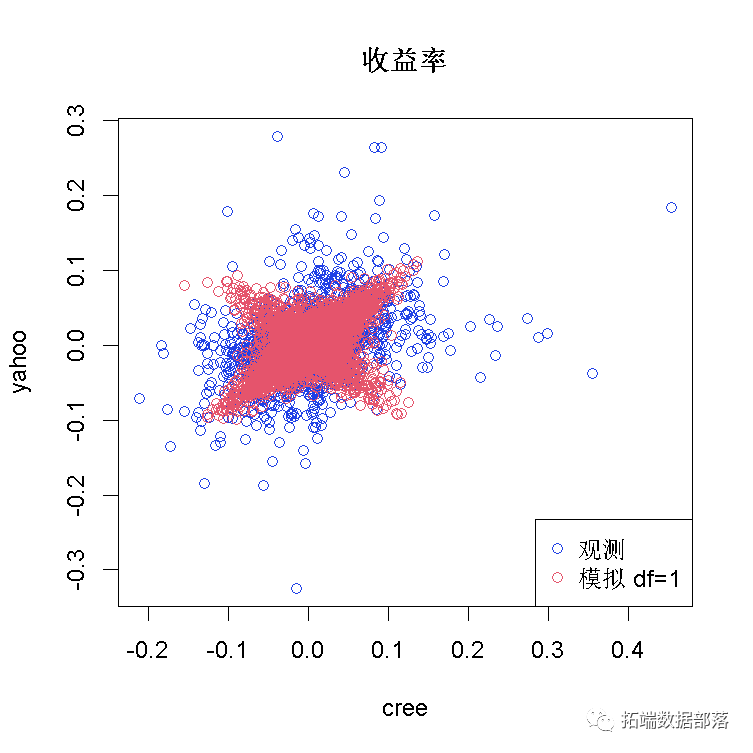
让我们尝试df=1和df=8:
显然,该参数df对于确定分布的形状非常重要。随着df增加,t-copula倾向于高斯copula。
 python中Copula在多元联合分布建模可视化2实例合集|附数据代码
python中Copula在多元联合分布建模可视化2实例合集|附数据代码 R语言Copula对债券时间序列数据的流动性风险进行度量
R语言Copula对债券时间序列数据的流动性风险进行度量 【视频】因子分析简介及R语言应用实例:对地区经济研究分析重庆市经济指标
【视频】因子分析简介及R语言应用实例:对地区经济研究分析重庆市经济指标 R语言宏观经济学:IS-LM曲线可视化货币市场均衡
R语言宏观经济学:IS-LM曲线可视化货币市场均衡


