本文考虑一下基于核方法进行分类预测。注意,在这里,我们不使用标准逻辑回归,它是参数模型。
用于函数估计的非参数方法大致上有三种:核方法、局部多项式方法、样条方法。
非参的函数估计的优点在于稳健,对模型没有什么特定的假设,只是认为函数光滑,避免了模型选择带来的风险。
可下载资源
非参数方法
但是,表达式复杂,难以解释,计算量大是非参的一个很大的毛病。所以说使用非参有风险,选择需谨慎。
非参的想法很简单:函数在观测到的点取观测值的概率较大,用x附近的值通过加权平均的办法估计函数f(x)的值。
拉里·瓦瑟曼(Larry Wasserman)将参数模型定义为一组分布,“可以通过有限数量的参数对其进行参数化”。(第87页)相比之下,非参数模型是不能通过有限数量的参数进行参数化的一组分布。
因此,根据该定义,标准逻辑回归是参数模型。逻辑回归模型是参数化的,因为它具有一组有限的参数。具体地,参数是回归系数。这些通常对应于每个预测变量加一个常数。Logistic回归是广义线性模型的一种特殊形式。具体来说,它涉及使用logit链接功能对二项分布的数据进行建模。
有趣的是,可以执行非参数逻辑回归(例如,Hastie,1983)。这可能涉及使用样条曲线或某种形式的非参数平滑来对预测变量的效果进行建模。
参考文献
-
Wasserman,L.(2004年)。所有统计信息:统计推断的简要课程。施普林格出版社。
核方法
当加权的权重是某一函数的核,这种方法就是核方法,常见的有Nadaraya-Watson核估计与Gasser-Muller核估计方法,也就是很多教材里谈到的NW核估计与GM核估计,这里我们还是不谈核的选择,将一切的核估计都默认用Gauss核处理。
NW核估计形式为:
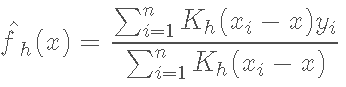
GM核估计形式为:
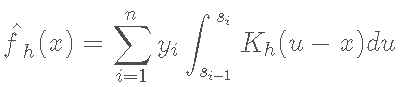

式中![]()
数据
使用心脏病数据,预测急诊病人的心肌梗死,包含变量:
- 心脏指数
- 心搏量指数
- 舒张压
- 肺动脉压
- 心室压力
- 肺阻力
- 是否存活
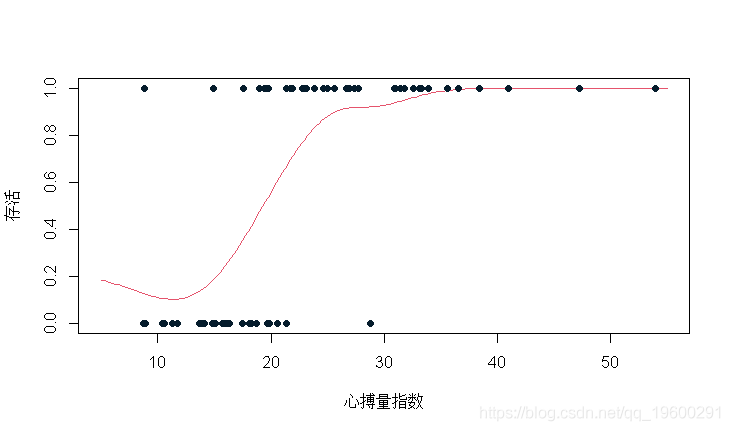
既然我们知道核估计是什么,我们假设k是N(0,1)分布的密度。在x点,使用带宽h,我们得到以下代码
dnorm(( 心搏量指数-x)/bw, mean=0,sd=1)
weighted.mean( 存活,w)}
plot(u,v,ylim=0:1,
当然,我们可以改变带宽。
Vectorize( mean_x(x,2))(u)
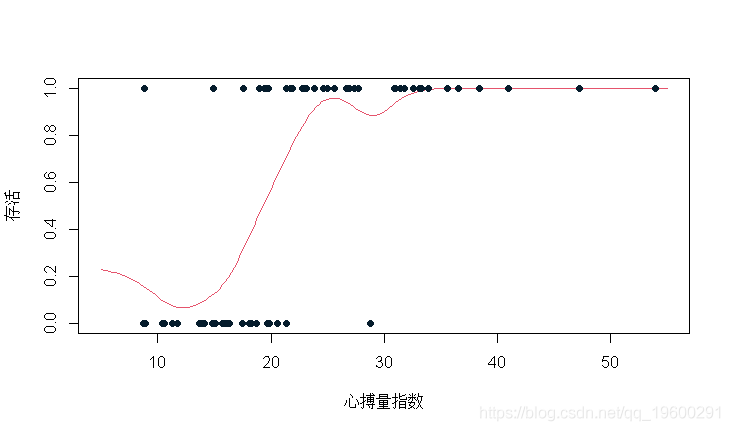
我们观察到:带宽越小,我们得到的方差越大,偏差越小。“越大的方差”在这里意味着越大的可变性(因为邻域越小,计算平均值的点就越少,估计值也就越不稳定),以及“偏差越小”,即期望值应该在x点计算,所以邻域越小越好。
使用光滑函数
用R函数来计算这个核回归。
smooth( 心搏量指数, 存活, ban = 2*exp(1) 
我们可以复制之前的估计。然而,输出不是一个函数,而是两个向量序列。此外,正如我们所看到的,带宽与我们以前使用的带宽并不完全相同。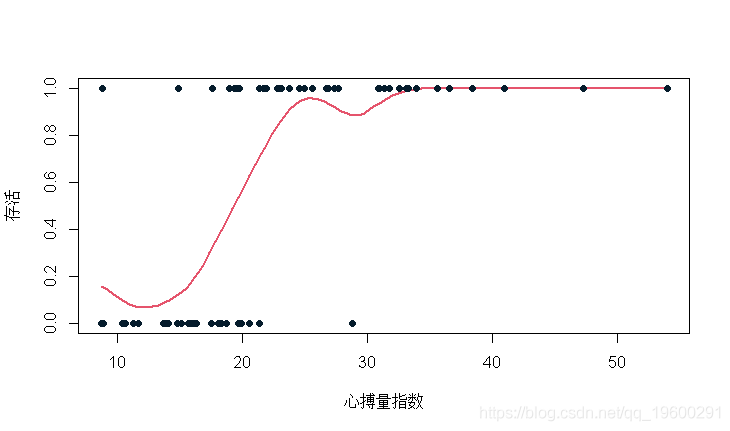
smooth(心搏量指数,存活,"normal",bandwidth = bk)
optim(bk,f)$par}
x=seq(1,10,by=.1)
plot(x,y)
abline(0,exp(-1),col="red")
随时关注您喜欢的主题
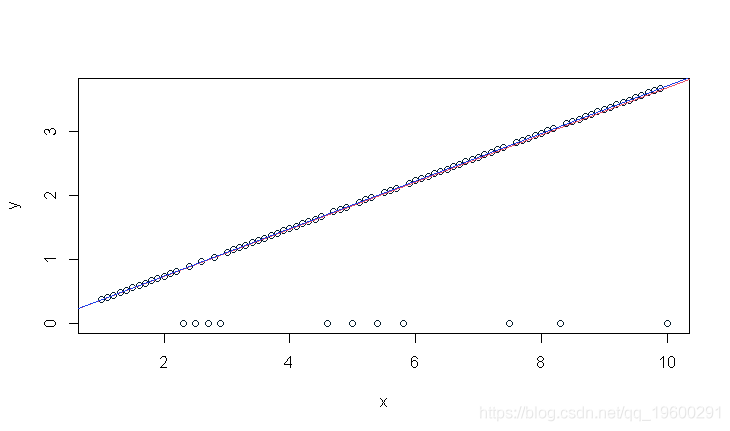
斜率为0.37,实际上是e^{-1}。
高维应用
现在考虑我们的双变量数据集,并考虑一些单变量(高斯)核的乘积
w = dnorm((df$x1-x)/bw1, mean=0,sd=1)*
dnorm((df$x2-y)/bw2, mean=0,sd=1)
w.mean(df$y=="1",w)
contour(u,u,v,levels = .5,add=TRUE)
我们得到以下预测
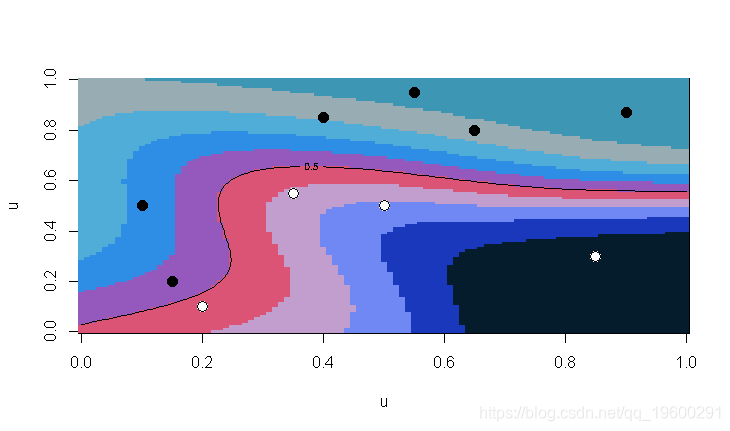
在这里,不同的颜色是概率。
K-NN(k近邻算法)
另一种方法是考虑一个邻域,它不是用到点的距离来定义的,而是用我们得到的n观测值来定义k邻域(也就是k近邻算法)。
接下来,我们自己编写函数来实现K-NN(k近邻算法):
困难的是我们需要一个有效的距离。
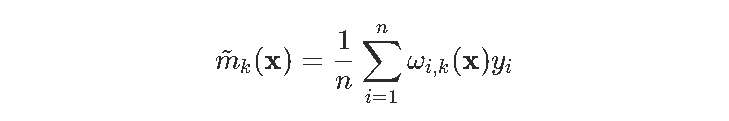
如果每个分量的单位都非常不同,那么使用欧几里德距离将毫无意义。所以,我们考虑马氏距离
我们也可以计算出最近邻居中黑点的比例。它实际上可以被解释为是黑色的概率,
mahalanobis = function(x,y,Sinv){as.numeric(x-y)%*%Sinv%*%t(x-y)}
mahalanobis(my[i,1:7],my[j,1:7])
这里我们有一个函数来寻找k最近的邻居观察样本。然后可以做两件事来得到一个预测。我们的目标是预测一个类,所以我们可以考虑使用一个多数规则:对yi的预测与大多数邻居样本的预测是一样的。
for(i in 1:length(Y)) Y[i] = sort( 存活[k_closest(i,k)])[(k+1)/2]
for(i in 1:length(Y)) Y[i] = mean( 存活[k_closest(i,k)])
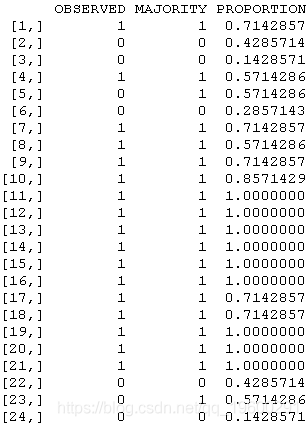
我们可以在数据集上看到观察结果,基于多数原则的预测,以及死亡样本在7个最近的邻居中的比例
k_ma(7),PROPORTION=k_mean(7))
这里,我们得到了一个位于 x 的观测点的预测,但实际上,可以寻找任何 x的最近邻k。回到我们的单变量例子(得到一个图表),我们有
w = rank(abs(心搏量指数-x),method ="random")
mean(存活[which(<=9)])}
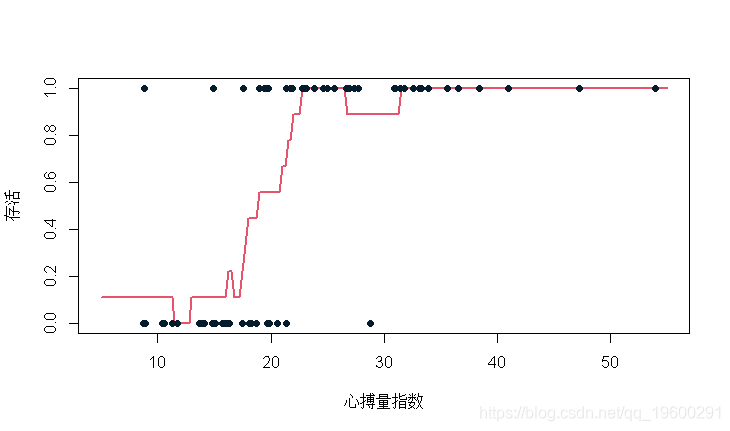
不是很平滑,但我们的点也不是很多。
如果我们在二维数据集上使用这种方法,我们就会得到以下的结果。
k = 6
dist = function(j) mahalanobis(c(x,y))
vect = Vectorize( dist)(1:nrow(df))
idx = which(rank(vect<=k)
contour(u,u,v,levels = .5,add=TRUE)
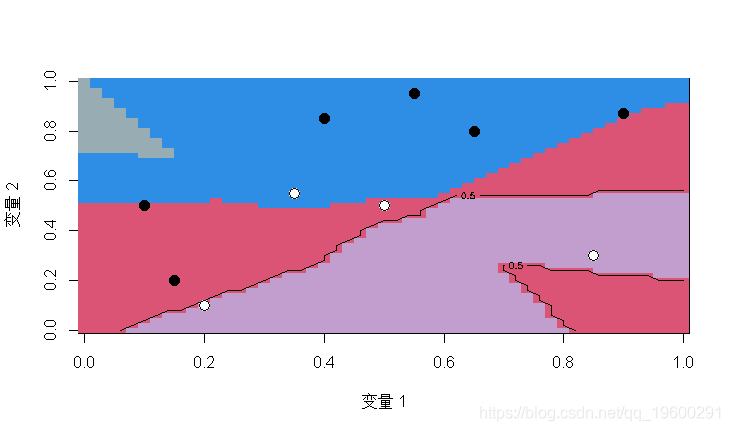
这就是局部推理的思想,用kernel对 x的邻域进行推理,或者用k-NN近邻。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据

