本文介绍简化模型构建和评估过程。
caret包的train 函数可用于
可下载资源
- 使用重采样评估模型调整参数对性能的影响
- 在这些参数中选择“最佳”模型
- 从训练集估计模型性能
首先,必须选择特定的模型。
调整模型的第一步是选择一组要评估的参数。例如,如果拟合偏最小二乘 (PLS) 模型,则必须指定要评估的 PLS 组件的数量。
梯度提升算法Gradient Boosting Machine,属于模型集成方法中的boosting类方法。通常来说模型集成能够大大提高模型表现,减少单个模型预测的偏差和方差,因此深受数据分析人士的喜爱。
最基础的模型集成方法,即生成多个模型(也叫基础学习器base learner)后,取预测平均数(如线性回归)或以多数投票表决(如决策树等分类问题)为模型结果。为了训练出不同的模型,需要对训练集进行Bootstrap抽样,这种方法于1996年由Breiman提出,叫做bagging,是较为简单的模型集成法。而bagging与boosting的主要区别,即boosting算法中基础学习器的训练往往以上一个基础学习器的结果为基础,对上一个基础学习器有所改进。每一次训练也叫做一次迭代,对于boosting,模型集成是有先后训练顺序的基础学习器的加总,而bagging是彼此没有关系的基础学习器的加总。
boost也分为许多种类,如AdaBoost、Gradient Boost、XGBoost等,Gradient Boost顾名思义,与梯度脱不开关系,对梯度有了解或学过数值计算的人应当知道,负梯度方向是函数下降最快的方向。在有监督机器学习中,我们的目标是学得使得损失函数最小的模型,因此梯度下降算法的目标则是在每一轮迭代中,求得当前模型的损失函数的负梯度方向,乘以一定的步长(即学习速率),加到当前模型中形成此轮迭代产生的新模型,从而达到每一轮迭代后的模型,相比上轮模型,都可以使得损失函数更小的目的。
因此对于Gradient Boost Machine来说重要的变量有:迭代次数M、损失函数的形式ψ(y,f)和基础学习器的形式h(x,θ)。确定了以上变量后,Gradient Boost Machine的算法如下:
1、以常数初始化函数f0
2、从第1到第M次迭代:
3、计算负梯度函数gt(x)
4、训练新的基础学习器h(x, θt)
5、找到最佳步长ρt使得
一旦定义了模型和调整参数值,还应指定重采样的类型。目前, _k_折交叉验证(一次或重复)、留一法交叉验证和引导(简单估计或 632 规则)重采样方法可以被 train。重采样后,该过程会生成性能测量的配置文件,可用于指导用户选择应选择哪些调整参数值。默认情况下,该函数会自动选择与最佳值相关的调整参数,尽管可以使用不同的算法。
声纳数据例子
在这里,我们加载数据:
str(Snr\[, 1:10\])

将数据的分层随机样本创建为训练集和测试集:
iTraing <- creaDaaPatiion(Cls, p = .75, list = FALSE)
我们将使用这些数据说明此(和其他)页面上的功能。
基本参数调优
默认情况下,简单重采样用于上述算法中的第 3 行。还有其他的,如重复 _K_折交叉验证,留一法等。 指定重采样的类型:
fit <- trainCnol(## 10-fold CV meod = "rpaedcv", ## 重复10次 rpets = 10)
前两个参数 train 分别是预测变量和结果数据对象。第三个参数 , method指定模型的类型(请参阅 train Model List 或者 train Models By Tag)。为了说明,我们将通过 gbm 包。使用重复交叉验证拟合此模型的基本语法如下所示:
train( mehd = "gbm",


对于梯度提升机 (GBM) 模型,有三个主要调整参数:
- 迭代次数,即树,(
n.trees在gbm函数中调用) - 树的复杂度,称为
interaction.depth - 学习率:算法适应的速度,称为
shrinkage - 节点中开始分裂的最小训练集样本数 (
n.minobsinnode)
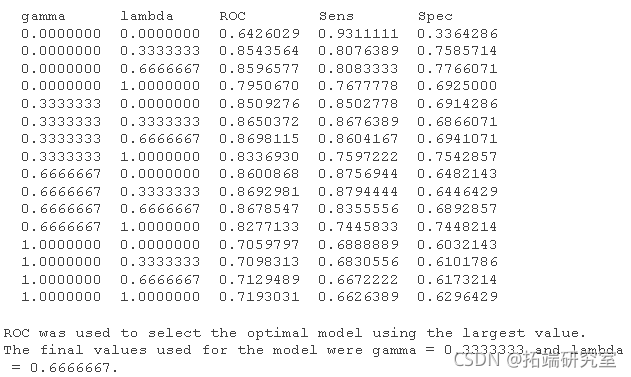
为该模型测试的默认值显示在前两列中(shrinkage 并且 n.minobsinnode 未显示,因为候选模型的网格集都对这些调整参数使用单个值)。标记为“ Accuracy”的列是交叉验证迭代的平均总体一致率。一致性标准偏差也是从交叉验证结果中计算出来的。“ Kappa”列是 Cohen 的(未加权的)Kappa 统计量在重采样结果中的平均值。 train 适用于特定模型。对于这些模型, train 可以自动创建一个调整参数的网格。默认情况下,如果 p 是调整参数的数量,则网格大小为 _3^p_。再举一个例子,正则化判别分析 (RDA) 模型有两个参数 (gamma 和 lambda),这两个参数都介于 0 和 1 之间。默认训练网格将在这个二维空间中产生九种组合。
train 下一节将介绍其中的其他功能 。
再现性注意事项
许多模型在估计参数的阶段使用随机数。此外,重采样索引是使用随机数选择的。有两种主要的方法来控制随机性以确保可重复的结果。
- 有两种方法可以确保在调用训练时使用相同的重样本。第一种是在调用训练前使用set.seed。第一次使用随机数是为了创建重采样信息。另外,如果你想使用数据的特定分割,可以使用trainControl函数的索引参数。
- 当模型在重采样中被创建时,种子也可以被设置。虽然在调用train之前设置种子可以保证使用相同的随机数,但在使用并行处理时不太可能是这种情况(取决于利用的是哪种技术)。为了设置模型拟合的种子,trainControl有一个额外的参数叫种子,可以使用。这个参数的值是一个作为种子的整数向量的列表。trainControl的帮助页面描述了这个选项的适当格式。
自定义调优过程
有几种方法可以自定义选择调整/复杂性参数和构建最终模型的过程。
预处理选项
如前所述,train 可以在模型拟合之前以各种方式对数据进行预处理。该功能 preProcess 是自动使用的。此函数可用于标准、插补(参见下文详细信息)、通过主成分分析或独立成分分析应用空间符号变换和特征提取。
为了指定应该进行什么预处理,该 train 函数有一个名为 的参数 preProcess。 preProcess 函数的附加选项 可以通过trainControl 函数传递 。
这些处理步骤将在使用predict.train, extractPrediction 或 生成的任何预测期间应用 extractProbs (请参阅本文档后面的详细信息)。预处理 不会 应用于直接使用object$finalModel 对象的预测 。
对于插补,目前实现了三种方法:
- _k -_最近邻采用具有缺失值的样本,并 在训练集中找到 _k 个_最接近的样本。该 预测器的_k 个_训练集值的平均值 用作原始数据的替代。在计算到训练集样本的距离时,计算中使用的预测变量是该样本没有缺失值且训练集中没有缺失值的预测变量。
- 另一种方法是使用训练集样本为每个预测因子拟合一个袋状树模型。这通常是一个相当准确的模型,可以处理缺失值。当一个样本的预测器需要估算时,其他预测器的值会通过袋装树进行反馈,并将预测值作为新值。这个模型会有很大的计算成本。
- 预测器训练集值的中位数可用于估计缺失数据。
如果训练集中存在缺失值,PCA 和 ICA 模型仅使用完整样本。
交替调谐网格
调谐参数网格可由用户指定。该参数 tuneGrid 可以采用包含每个调整参数列的数据框。列名应该与拟合函数的参数相同。对于前面提到的 RDA 示例,名称将是 gamma 和 lambda。 train 将在行中的每个值组合上调整模型。
对于提升树模型,我们可以固定学习率并评估三个以上的n.trees值。
expnd.grd( n.trees = (1:30)*50, ) Fit2



另一种选择是使用可能的调整参数组合的随机样本,即“随机搜索”。
要使用随机搜索,请使用search = "random" 调用中 的选项 trainControl。在这种情况下, tuneLength 参数定义了将被评估的参数组合的总数。
绘制重采样图像
该 plot 函数可用于检查性能估计与调整参数之间的关系。例如,函数的简单调用显示了第一个性能度量的结果:
tels.pr.st(cretTe())

随时关注您喜欢的主题
可以使用该metric 选项显示其他性能指标 :
trels.r.st(carthme()) plt(Fit2, meric = "Kap")
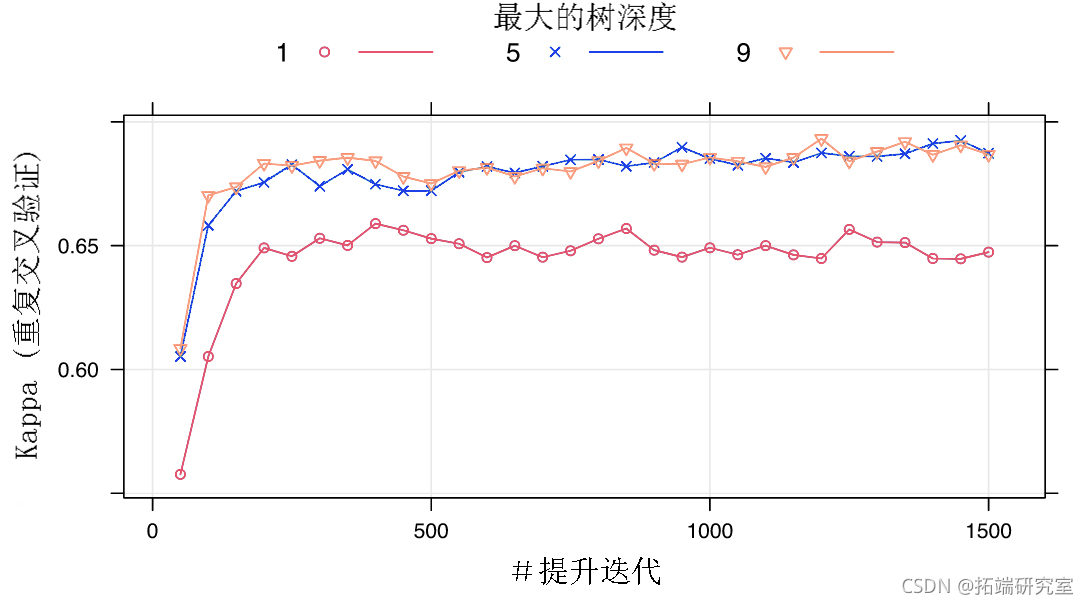
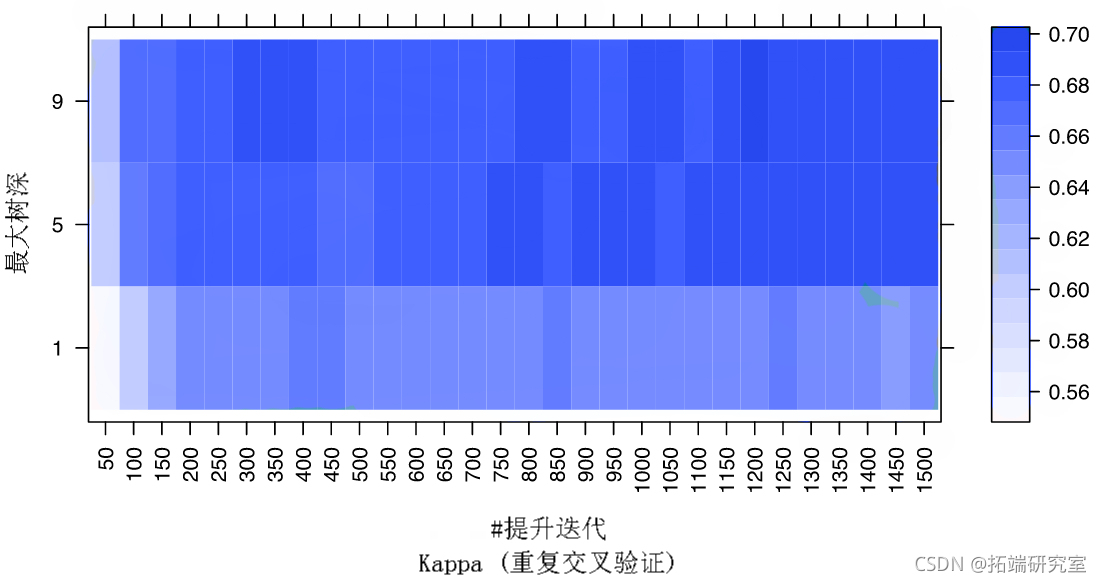
也可以使用其他类型的绘图。有关?plot.train 更多详细信息,请参阅 。下面的代码显示了结果的热图:
trlipt(crTme()) plt(Fit2))
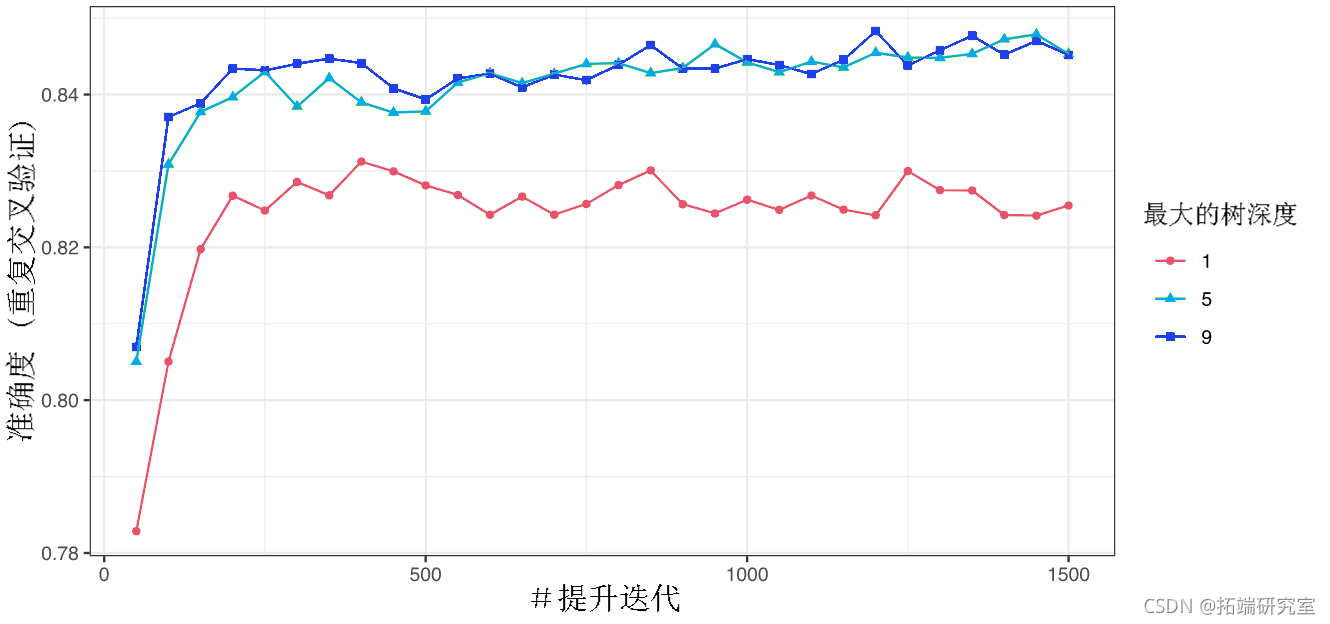
ggplot 还可以使用ggplot方法:
ggplot( Fit2)
还有一些绘图函数可以更详细地表示重新采样的估计值。有关?xyplot.train 更多详细信息,请参阅 。
从这些图中,可能需要一组不同的调谐参数。要更改最终值而无需再次启动整个过程, update.train 可用于重新拟合最终模型。看 ?update.train
trainControl 功能
该函数 trainControl 生成参数,进一步控制模型的创建方式,可能的值:
方法。重新取样的方法。"boot"、"cv"、"LOOCV"、"LGOCV"、"recomplatedcv"、"timeslice"、"none "和 "oob"。最后一个值,袋外估计值,只能由随机森林、袋装树、袋装地球、袋装灵活判别分析或条件树森林模型使用。GBM模型不包括在内。另外,对于留一法交叉验证,没有给出重采样性能指标的不确定性估计。number和repeats:number控制_K_折交叉验证中的折叠 次数或用于引导和离开组交叉验证的重采样迭代次数。repeats仅适用于重复的 _K_折交叉验证。假设method = "repeatedcv",number = 10和repeats = 3, 那么三个单独的 10 折交叉验证被用作重采样方案。verboseIter:输出训练日志。returnData: 将数据保存到名为trainingData。
替代性能指标
用户可以更改用于确定最佳设置的指标。默认情况下,为回归计算RMSE、 R 2 和平均绝对误差 (MAE),而为分类计算准确度和 Kappa。同样默认情况下,参数值是分别使用 RMSE 和精度选择的,分别用于回归和分类。该 函数的 metric 参数 train允许用户控制使用哪个最优标准。例如,在一类中样本百分比较低的问题中,使用 metric = "Kappa" 可以提高最终模型的质量。
如果这些参数都不令人满意,用户还可以计算自定义性能指标。
该 trainControl 函数有一个参数 summaryFunction ,用于指定计算性能的函数。该函数应具有以下参数:
- data是一个数据框或矩阵的参考,其列名为obs和pred,用于观察和预测结果值(用于回归的数字数据或用于分类的字符值)。目前,类的概率没有被传递给函数。data中的值是对单一调谐参数组合的保留预测值(及其相关参考值)。如果trainControl对象的classProbs参数被设置为 “true”,数据中就会出现包含类概率的额外列。这些列的名称与类的级别相同。另外,如果在调用训练时指定了权重,那么数据集中也会有一列叫做权重的数据。
lev是一个字符串,它具有从训练数据中提取的结果因子级别。对于回归,将 的值NULL传递到函数中。model是正在使用的模型的字符串(即传递给 的method参数 的值train)。
该函数的输出应该是具有非空名称的数字汇总指标的向量。默认情况下, train 根据预测类别评估分类模型。可选地,类概率也可用于衡量性能。要在重采样过程中获得预测的类概率,参数 classProbs in trainControl 必须设置为 TRUE。这将概率列合并到每个重采样生成的预测中(每个类有一列,列名是类名)。
如上一节所示,自定义函数可用于计算重采样的平均性能分数。计算 ROC 曲线下的灵敏度、特异性和面积:
head(toClamary)

要使用此标准重建提升树模型,我们可以使用以下代码查看调整参数与 ROC 曲线下面积之间的关系:
Fit3<- tran(C mtric = "ROC")


在这种情况下,与最佳调整参数相关的 ROC 曲线下的平均面积在 100 次重采样中为 0.922。
选择最终模型
自定义调整过程的另一种方法是修改用于选择“最佳”参数值的算法,给定性能数字。默认情况下,该 train 函数选择具有最大性能值(或最小,对于回归模型中的均方误差)的模型。可以使用其他选择模型的方案。 Breiman et al (1984)“) 为简单的基于树的模型建议了“一个标准错误规则”。在这种情况下,识别出具有最佳性能值的模型,并使用重采样来估计性能的标准误差。使用的最终模型是(经验上的)最佳模型的一个标准误差范围内的最简单模型。对于简单的树,这是有道理的,因为随着这些模型越来越针对训练数据,它们将开始过度拟合。
train 允许用户指定用于选择最终模型的替代规则。该参数 selectionFunction 可用于提供一个函数来通过算法确定最终模型。包中现有三个函数: best 是选择最大/最小值, oneSE 尝试捕捉精神 Breiman et al (1984)“) 并 tolerance 在最佳值的某个百分比容差范围内选择最不复杂的模型。
可以使用用户定义的函数,只要它们具有以下参数:
x是一个包含调整参数及其相关性能指标的数据框。每行对应一个不同的调整参数组合。metric指示哪些性能度量应该被优化的字符串(这在直接从传递metric的自变量train。maximize是一个单一的逻辑值,指示性能指标的较大值是否更好(这也直接从调用传递到train)。
该函数应输出一个整数,指示x 选择了哪一行 。
举个例子,如果我们根据整体精度选择之前的 boosted 树模型,我们会选择:n.trees = 1450,interaction.depth = 5,shrinkage = 0.1,n.minobsinnode = 20。该图相当紧凑,准确度值从 0.863 到 0.922 不等。一个不太复杂的模型(例如更少、更浅的树)也可能产生可接受的准确性。
容差函数可用于基于 ( x – x best)/ x bestx 100(百分比差异)找到不太复杂的模型。例如,要根据 2% 的性能损失选择参数值:
tolrae(rslts, merc = "ROC", tol = 2, mxiie = TRUE)

resul\[whTwc,1:6\]

这表明我们可以得到一个不太复杂的模型,其 ROC 曲线下的面积为 0.914(与“选择最佳”值 0.922 相比)。
这些函数的主要问题与从最简单到复杂的模型排序有关。在某些情况下,这很容易(例如简单的树、偏最小二乘法),但在这种模型的情况下,模型的排序是主观的。例如,使用 100 次迭代且树深度为 2 的提升树模型是否比使用 50 次迭代且深度为 8 的模型更复杂?该包做出了一些选择。在提升树的情况下,该包假设增加迭代次数比增加树深度更快地增加复杂性,因此模型按迭代次数排序,然后按深度排序。
提取预测和类别概率
如前所述,由训练函数产生的对象在finalModel子对象中包含 “优化 “的模型。可以像往常一样从这些对象中进行预测。在某些情况下,比如pls或gbm对象,可能需要指定来自优化后拟合的额外参数。在这些情况下,训练对象使用参数优化的结果来预测新的样本。例如,如果使用predict.gbm创建预测,用户必须直接指定树的数量(没有默认)。另外,对于二元分类,该函数的预测采取的是其中一个类的概率形式,所以需要额外的步骤将其转换为因子向量。predict.train自动处理这些细节(以及其他模型)。
此外,R 中模型预测的标准语法很少。例如,为了获得类概率,许多 predict 方法都有一个称为参数的参数 type ,用于指定是否应该生成类或概率。不同的包使用不同的值 type,例如 "prob", "posterior", "response", "probability" 或 "raw"。在其他情况下,使用完全不同的语法。
对于predict.train,类型选项被标准化为 “class “和 “prob”。比如说。
prdit(it3, nwta = hadetn))

prdit(Ft3, ewata = hed(ttig), tye = "pob")

探索和比较重采样分布
模型内
例如,以下语句创建一个密度图:
tlisaret(crtTe()) deiplt(Ft3, pch = "|")

请注意,如果您有兴趣绘制多个调整参数的重采样结果,resamples = "all" 则应在控制对象中使用该选项 。
模型间
表征模型之间的差异(使用产生的 train, sbf 或 rfe通过它们的重新采样分布)。
首先,支持向量机模型拟合声纳数据。使用preProc 参数对数据进行标准化 。请注意,相同的随机数种子设置在与用于提升树模型的种子相同的模型之前。
set.sed(25)
Ft <- tran(
preProc = c("center", "scale"),
metric = "ROC")

此外,还拟合了正则化判别分析模型。
Fit <- tn( method = "rda")

鉴于这些模型,我们能否对它们的性能差异做出统计陈述?为此,我们首先使用 收集重采样结果 。
rsa <- resamples()

summary
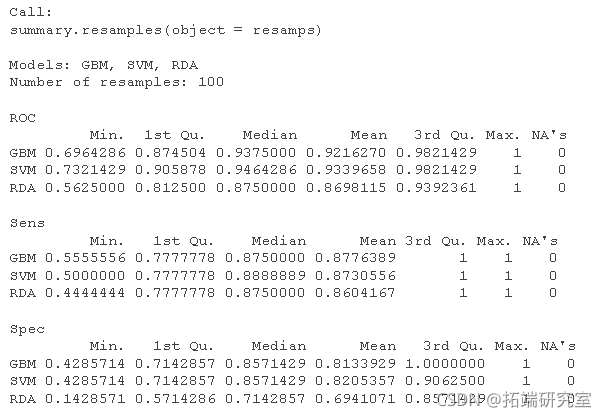
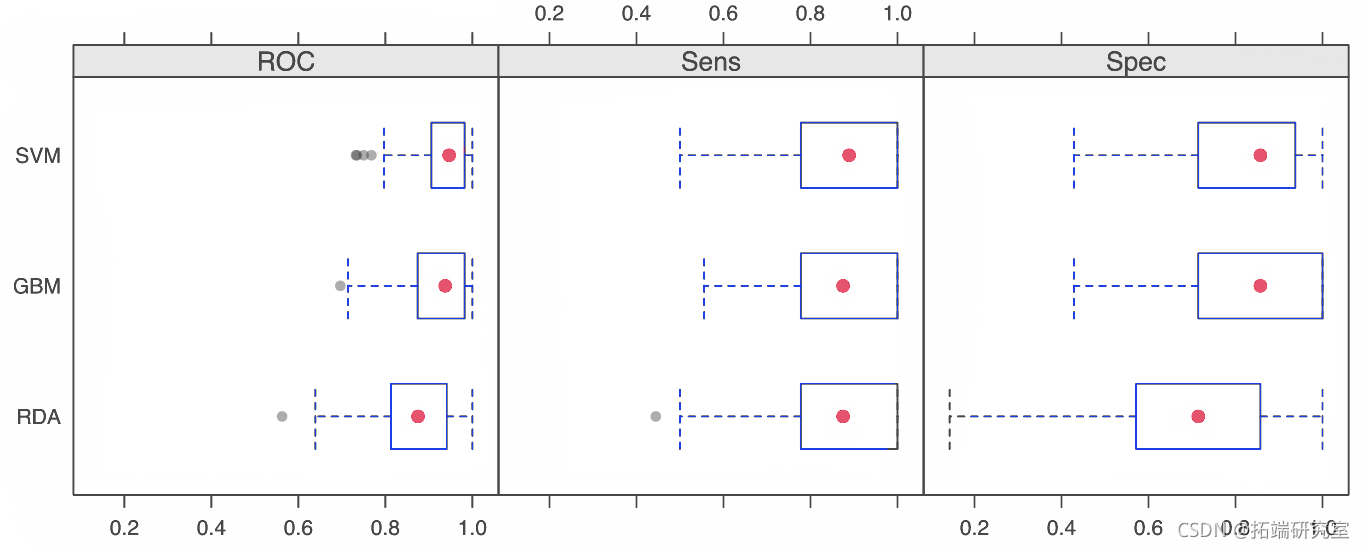
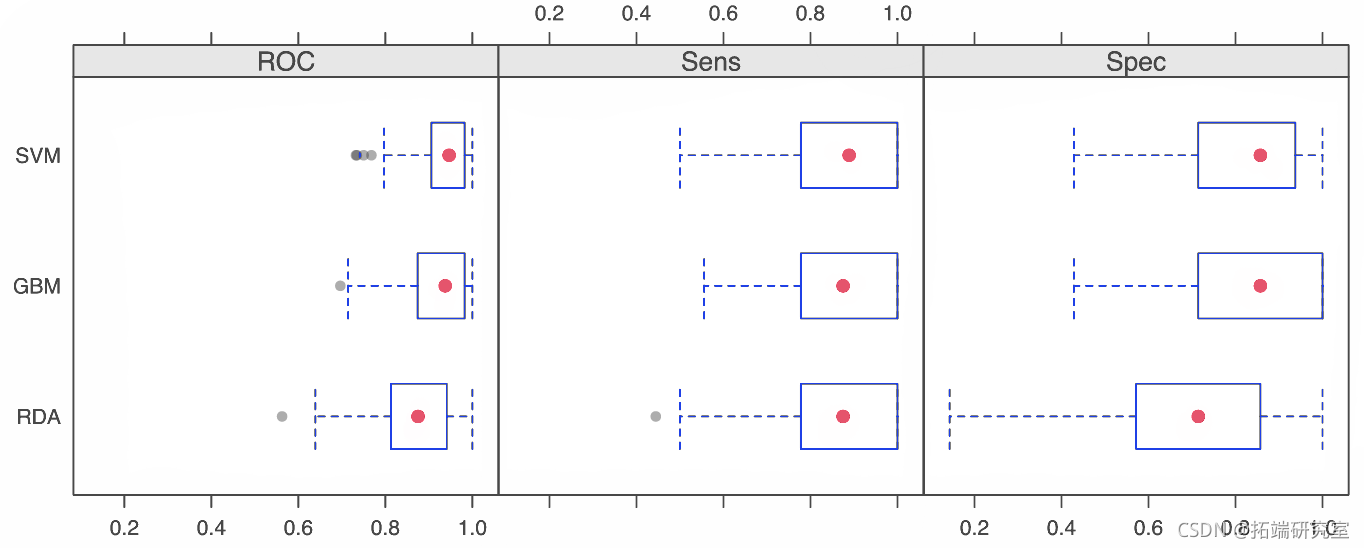
有几种点阵图方法可用于可视化重采样分布:密度图、盒须图、散点图矩阵和汇总统计的散点图。例如:
the <- elia.get( ptsyol$col = rb(.2, ., .2, .4) plot(resamp, layot = c(3, 1))
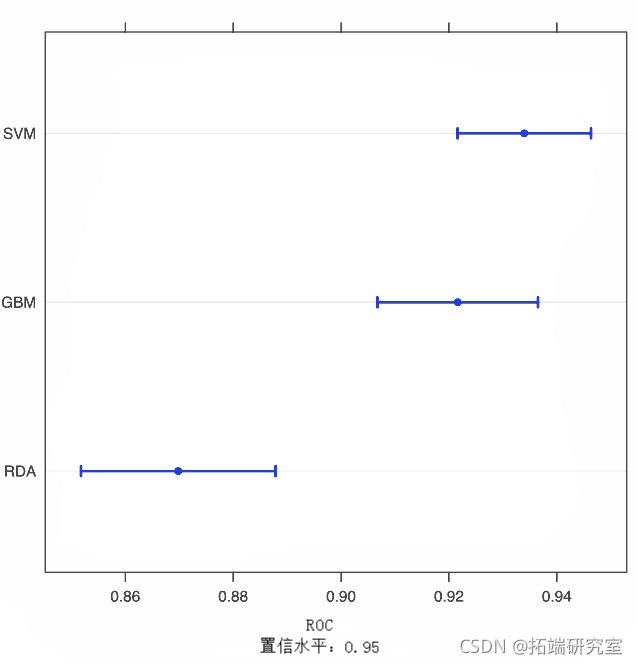
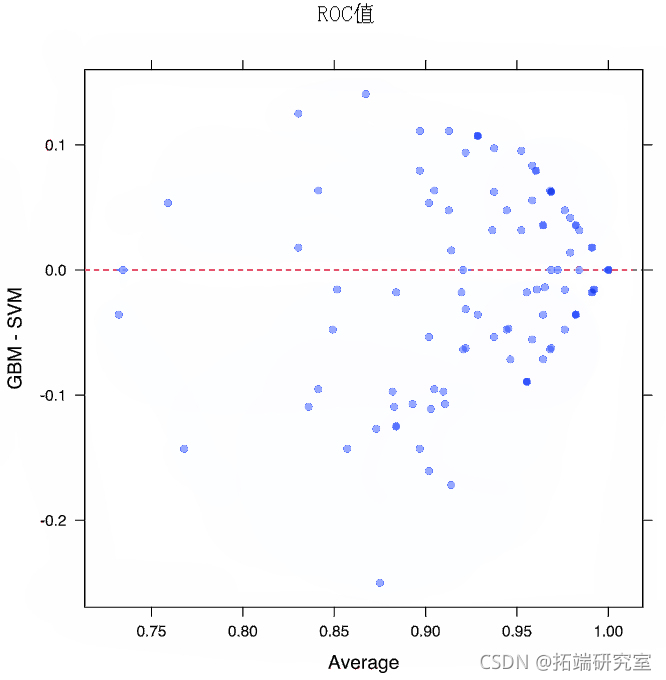
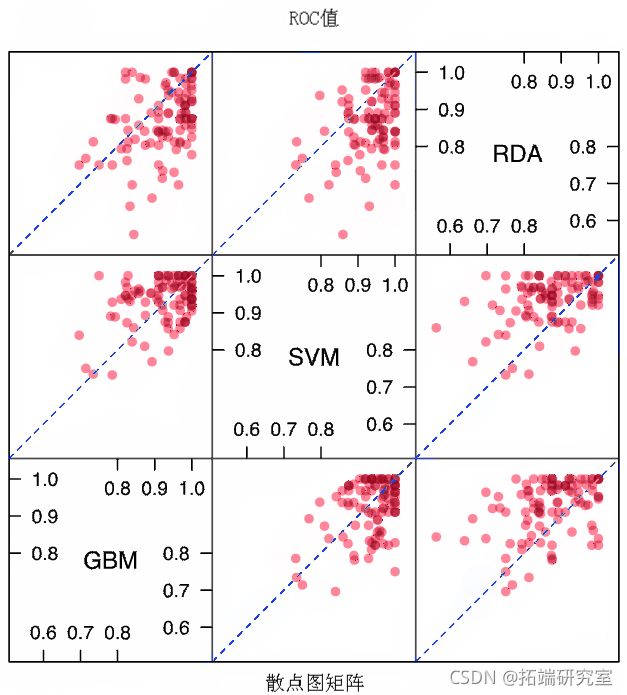
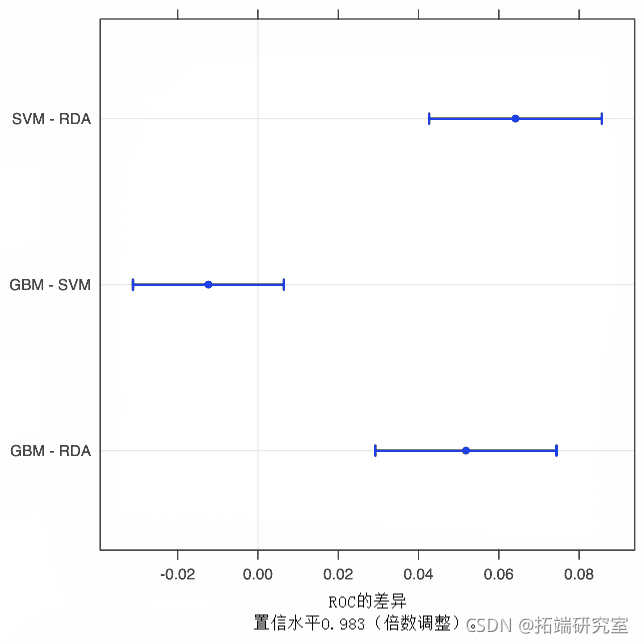
由于模型是在相同版本的训练数据上拟合的,对模型之间的差异进行推断是有意义的。通过这种方式,我们减少了可能存在的样本内相关性。我们可以计算差异,然后使用一个简单的t检验来评估模型之间没有差异的无效假设。
diValu

summary

plot(diVls, lyu = c(3, 1))
plot(fVue)
没有参数调整的拟合模型
在模型调整值已知的情况下, train 可用于将模型拟合到整个训练集,无需任何重采样或参数调整。可以使用 using method = "none" 选项 trainControl 。例如:
tronol(mtd = "none", csPrs = TRUE) Fit4

请注意 plot.train, resamples, confusionMatrix.train 和其他几个函数不适用于此对象,但其他函数 predict.train 将:
prdct(Fit4, newdata )
prdit(Fit4, newdata , tpe = "prb")

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码
Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码 Python用XGBoost、梯度提升树、Lasso与极端随机树ETR功率变换器磁芯损耗建模及SLSQP优化 | 附数据代码
Python用XGBoost、梯度提升树、Lasso与极端随机树ETR功率变换器磁芯损耗建模及SLSQP优化 | 附数据代码 Claude Code跨IDE集成与工作流优化:VS Code与Cursor双环境对比分析及AI编程助手决策框架构建 | 附教程文档
Claude Code跨IDE集成与工作流优化:VS Code与Cursor双环境对比分析及AI编程助手决策框架构建 | 附教程文档 多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码
多模态与推理模型高效压缩:自适应感知、KV缓存优化与Token容量扩展方法研究及Python复现|附数据代码

