
使用R和Python进行分析的主要好处之一是,它们充满活力的开源生态系统中总是有新的和免费提供的服务。
如今,越来越多的数据科学家能够同时在R,Python和其他平台上使用数据,这是因为供应商向R和Python引入了具有API的高性能产品,也许还有Java,Scala和Spark。
H2O包被称为“商业AI”,“使任何人都可以轻松地应用数学和预测分析来解决当今最具挑战性的业务问题。” H2O的与众不同之处在于其全面的,开源,跨平台,机器学习基础架构从头开始,以实现可扩展性和速度。
可下载资源
在本练习中,我部署了R的数据管理功能来构建模型数据集,然后“导入”到H2o结构中以运行模型。我可以轻松使用H2O功能。
广义上来说,有3种机器学习算法
1. 监督式学习(Supervised Learning)
工作机制:该算法由一个目标/结果变量(或因变量)组成,该变量由已知的一系列预测变量(自变量)计算而来。利用这一系列变量,我们生成一个将输入值映射到所需输出值的函数。该训练过程会持续进行,直到模型在训练数据上达到预期精确度。监督式学习的例子有:回归(Regression)、决策树(Decision Tree)、随机森林(Random Forest)、K最近邻(KNN)、逻辑回归(Logistic Regression)等等。
2. 非监督式学习(Unsupervised Learning)
工作机制:在该算法中,我们不预测或估计任何目标变量或结果变量。此算法用于不同组内的聚类分析,被广泛用于对不同群体的客户进行细分,从而进行特定的干预。非监督式学习的例子有:Apriori算法、K–均值算法。
3. 强化学习(Reinforcement Learning)
工作机制:该算法能够训练机器进行决策。其工作原理为:让机器处于一个能够通过反复试错来训练自己的环境中。机器从过去的经验中进行学习,并试图通过学习最合适的知识来作出精准的商业判断。强化学习的例子有:马尔可夫决策过程(Markov Decision Process)。
常见机器学习算法列表
下面是一些常用的机器学习算法。这些算法几乎可以应用于所有数据问题:
1. 线性回归(Linear Regression)
2. 逻辑回归(Logistic Regression)
3. 决策树(Decision Tree)
4. SVM
5. 朴素贝叶斯(Naive Bayes)
6. K最近邻(kNN)
7. K均值算法(K-Means)
8. 随机森林(Random Forest)
9. 降维算法(Dimensionality Reduction Algorithms)
10. 梯度提升算法(Gradient Boosting algorithms)
概述的任务序列从数据加载和训练/测试数据集构建开始。然后启动H2O服务器,依次按glm,带有三次样条的glm,梯度增强,随机森林和深度学习模型计算/绘制结果。提供了H2O数据集构建和模型训练的时间。
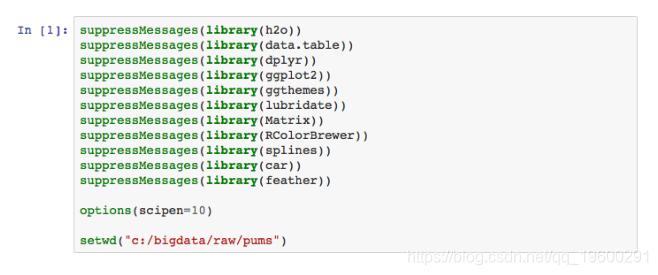
首先加载R库并设置工作目录。
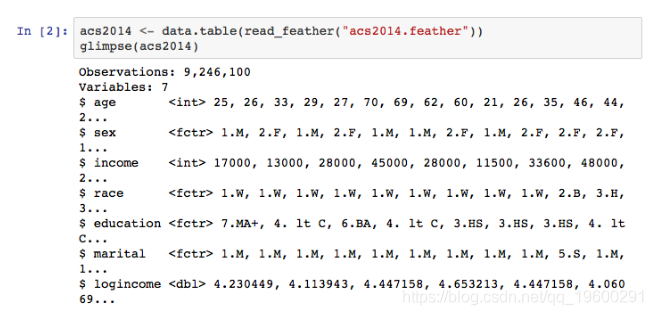
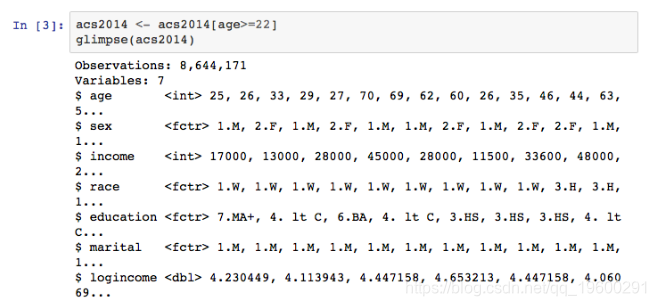
现在加载并子集用于建模练习的数据。 有8,644,171个案例和7个属性。
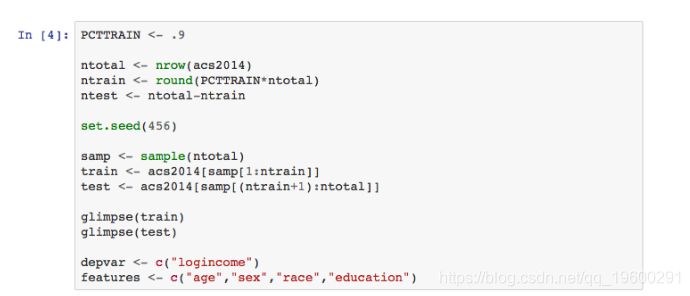
下一步是将Acs2014划分为R中的训练和测试数据表。对于我们的分析,因变量是logincome,而功能包括年龄,性别,种族和教育程度。

启动H2O服务器,分配16G RAM并使用所有8个内核。
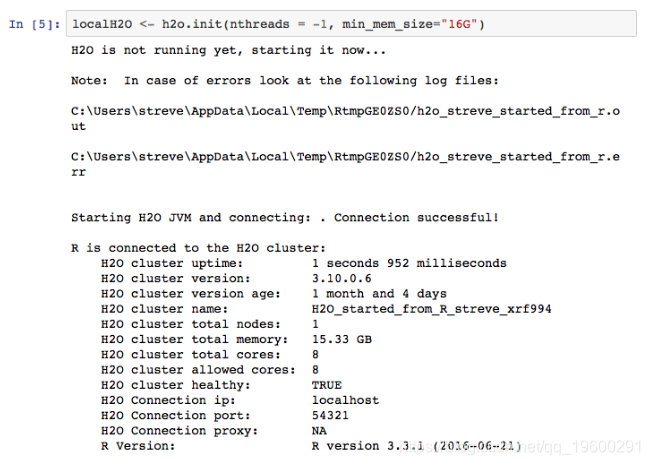

现在从R data.tables创建H2O数据结构。我们可以使用data.frames / data.tables进行数据处理,也可以直接使用H2O数据结构和功能。
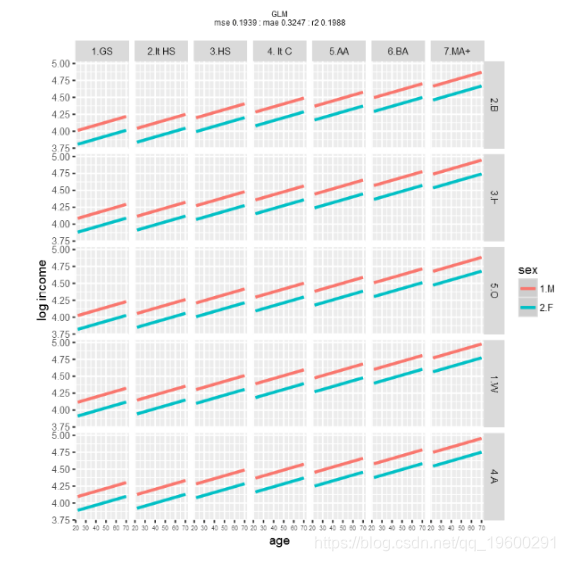
运行 线性模型(glm),并使用训练数据对登录年龄,性别,种族和教育程度进行回归。
随时关注您喜欢的主题
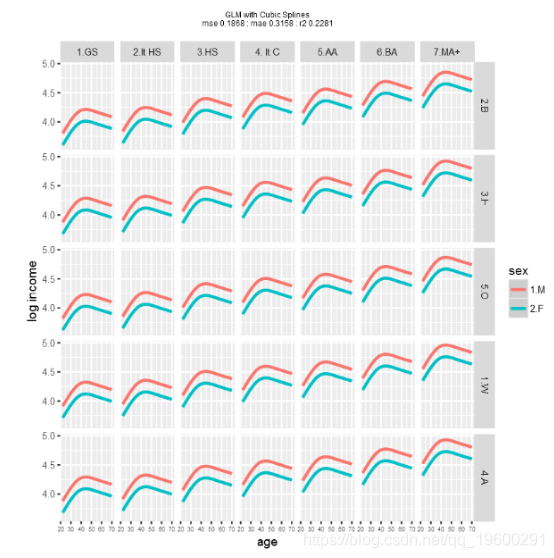
再次运行glm模型,这次使用年龄的三次样条来显示年龄和收入之间的曲线关系。


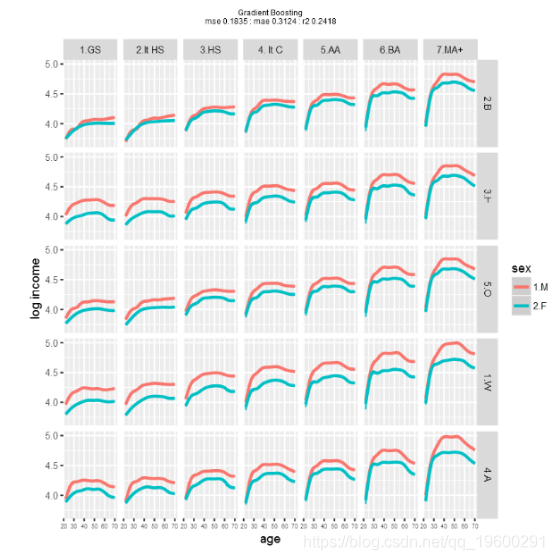
接下来,进行梯度增强,更多是非参数的,重采样的黑匣子模型。执行速度慢得多,反映出计算量很大。
现在让我们尝试随机森林。
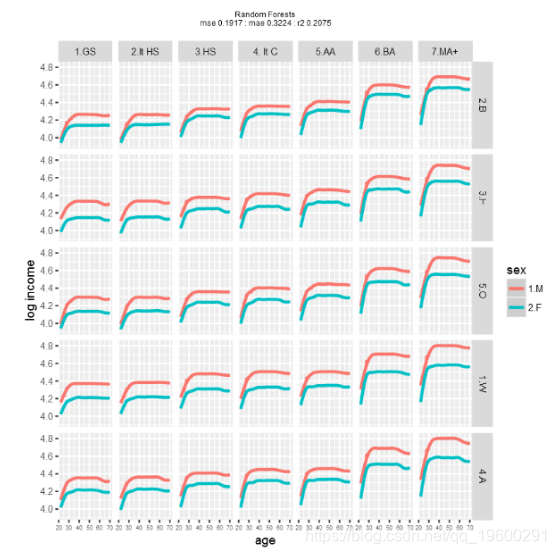
最后是深度学习。
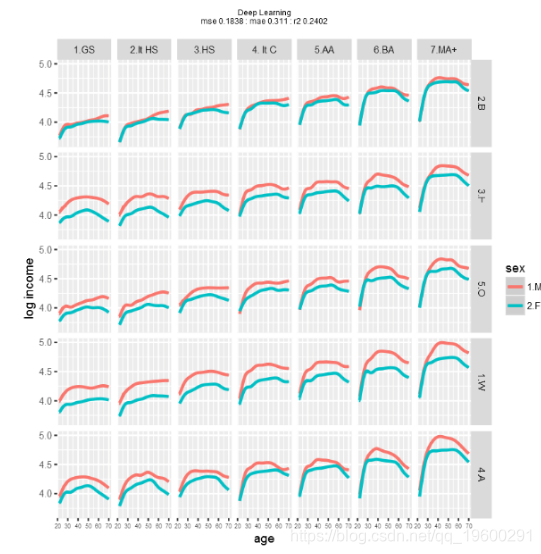
对模型性能的粗略检查表明,使用这些数据和模型,梯度提升可能会产生最佳结果。当然,不同的训练和测试数据集会产生不同的性能。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

