这是一种拟合稀疏广义加性模型(GAM)的新方法。
RGAM具有计算可扩展性,并且适用于连续、二进制、计数和生存数据。
让我们生成一些数据:
set.seed(1) n <- 100; p <- 12 mu = rowSums(x[, 1:3]) + f4 + f5 + f6可下载资源
我们使用最基本的rgam来拟合模型:
fit <- rgam
下面,我们使用不同的init_nz值拟合模型:
RGAM算法第2步的自由度超参数可以通过df选项进行设置,默认值为4。以下是使用不同超参数拟合RGAM模型的示例:
gamma = 0.6, df = 8
函数rgam()为一系列lambda值拟合RGAM模型,并返回一个rgam对象。
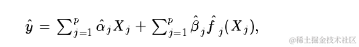

getf()函数是一个方便的函数,可以给出由一个输入变量引起的预测组成部分。也就是说,如果RGAM给出预测结果
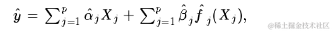
例如,下面的代码给出了第20个lambda值时响应由变量5引起的组成部分:
f5 <- get
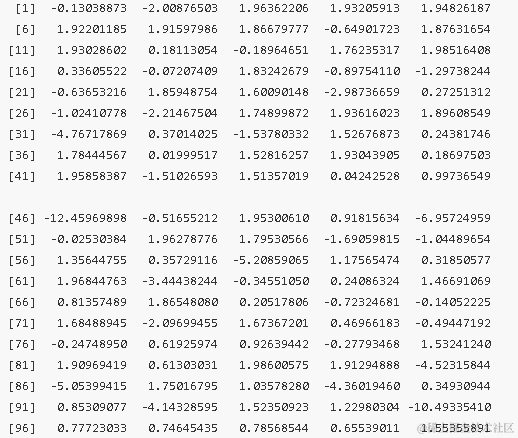
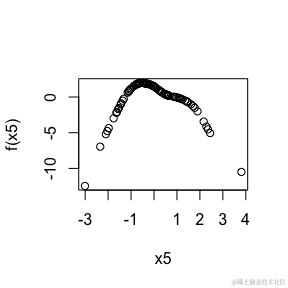
我们可以使用以下代码制作一个图表,展示变量5对响应的影响:
plot
图表和摘要
让我们再次拟合基本的rgam模型:
fit <- rga

默认情况下,plot()给出了最后一个 fit 中的 lambda键的拟合函数,并仅给出前4个特征的图表:
plot(fit
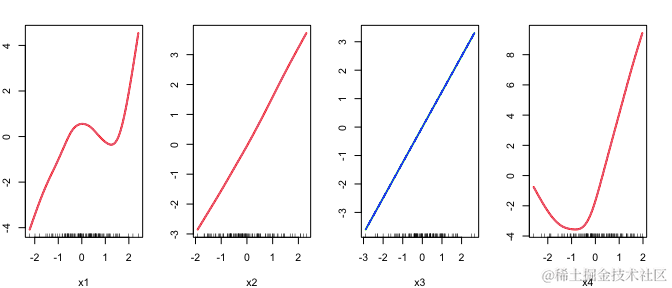
用户可以使用 index 和 which 选项指定 lambda 值的索引和要显示的特征图:
plot(fit, x, in
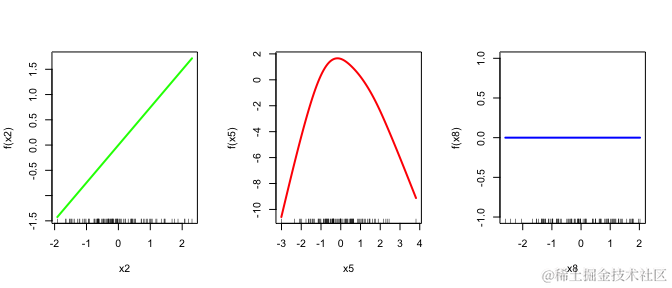
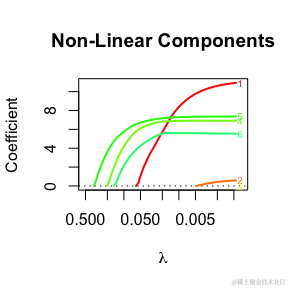
线性函数以绿色呈现,非线性函数以红色呈现,而零函数以蓝色呈现。
有 summary 方法,允许用户查看线性和非线性特征的系数概况。在每个图表上(一个用于线性特征,一个用于非线性特征),x轴是从大到小的 ��xi 值,y轴是特征的系数。
summary
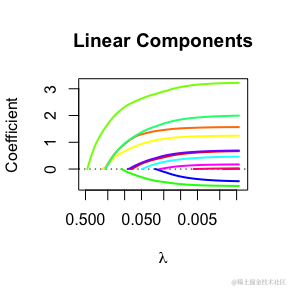

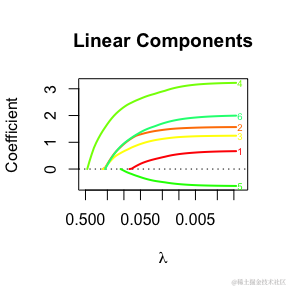
默认情况下,系数概况将针对所有变量进行绘制。
summary(fit
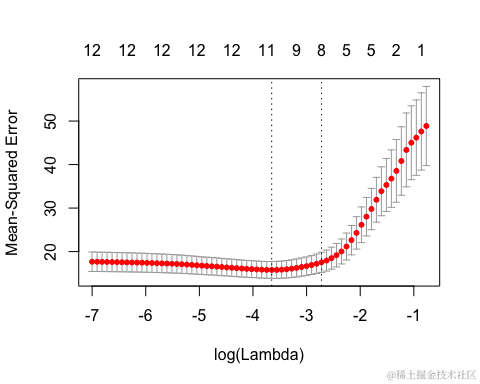
cvft <- cv.r
我们可以通过指定 foldid 参数来实现,其中 foldid 是一个长度为 n 的向量。
gamma = 0.6, foldid = foldid, verbose = FALSE)
cv.rgam() 调用会返回一个 cv.rgam 对象。
plot
可以从拟合的 cv.rgam 对象中进行预测。
predict(cvf s = lambda.1se

predict(cvfn")

其他类型的RGAM模型
在上述例子中,变量y是一个定量变量(即取值沿实数数轴)。因此,使用默认的rgam()的family = "gaussian"是合适的。然而,RGAM算法非常灵活,可以在y不是定量变量时使用。
二元数据的逻辑回归
在这种情况下,响应变量y应该是一个只包含0和1的数字向量。在进行预测时,请注意,默认情况下,predict()仅返回线性预测值,即
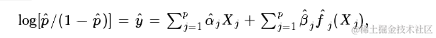
要获取预测的概率,用户必须在predict()调用中传递type = "response"。
# 拟合二元模型
bin_y <-binomial", init_nz = c(), gamma = 0.9,
verbose = FALSE)
# 第10个模型的前5个观察值的线性预测值
predict(bi1
# 第10个模型的前5个观察值的预测概率
predict(

计数数据的泊松回归
对于泊松回归,响应变量y应该是一个计数数据向量。虽然rgam()不要求每个元素都是整数,但如果任何元素为负,则会报错。
与逻辑回归类似,默认情况下,predict()仅返回线性预测值,即
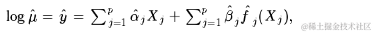
要获取预测速率,用户必须在predict()调用中传递type = "response"。
对于泊松数据,通常允许用户传入偏移,这是一个与观测数相同长度的向量。rgam()也允许用户这样做:
# 生成数据
set.seed(5)
offset <- rnoroffset, verbose = FALSE)
请注意,如果将offset提供给rgam(),则在进行预测时必须还提供一个偏移向量给predict():
# 第20个lambda值的速率预测
predict(poifit,ponse")[,20]

可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据

