
本研究旨在帮助客户利用房价数据集进行数据分析,该数据集包含82个变量和2930个数据点。
研究目标是通过分类算法将房价分为两个类别。在数据预处理阶段,排除了Order、PID和SalesPrice等变量,对数据进行整合和转换以适应非线性关系。
随后运用逻辑回归、GAM、LDA和KNN等算法进行建模和评估。
此外,通过PCA分析和不同分类模型的建模及交叉验证,评估模型的性能并选择最佳模型进行进一步分析和预测。
综合研究结果,逻辑回归和LDA模型表现较好,GAM模型在交叉验证中表现最佳,而KNN模型表现较差。研究结果为数据分析和模型选择提供了指导,有助于优化预测准确率和泛化能力。
本研究旨在使用Ames Housing数据进行数据分析,该数据集包含82个变量和2930个数据点。
分析目标:
运用分类算法将Sales分成2个class,一个class是大于USD 200,000, 另一类小于USD 20,000。
分析要求:
1. 在变量中,去除以下变量:Order, PID, 以及SalesPrice
2. 用以下代码来定义本次分析的训练数据,余下的数据做验证数据
3. 整合相关的变量,比如说把square feet加起来
4. 对数据进行变换(transformation),如果存在非线性关系
5. 进行least logistic regression(逻辑回归), GAM, LDA, 和KNN
在变量中要去除Order, PID, 当然SalesPrice也要去掉。
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
视频
R语言广义相加模型(GAM)在电力负荷预测中的应用
视频
K近邻KNN算法原理与R语言结合新冠疫情对股票价格预测
视频
主成分分析PCA降维方法和R语言分析葡萄酒可视化实例
AmesHousing=AmesHousing[,-c(1,2 )]
一个class是大于USD 200,000, 另一类小于USD 20,000
AmesHousing$SalePrice <- ifelse(AmesHousing$SalePrice>200000,1,0)
检查线性关系,如果不理想,则考虑进行转换。
head(AmesHousing2)
合并关键词
一些变量可能需要整合,如包含关键词“Flr”、“Porch”、“Bath”、“Overall”、“Sold”、“SF”、“Year”、“AbvGr”、“Garage”和“Area”。
AmesHousing2$Flr=apply(AmesHousing2[,grep("Flr" ,colnames(AmesHousing2))],1,sum)
AmesHousing2=AmesHousing2[,-grep("Flr" ,colnames(AmesHousing2))[-length(grep("Flr" ,colnames(AmesHousing2)))]]
plot(AmesHousi2)
跑logistic regression, GAM, LDA, KNN这几个模型
在数据准备完成后,可以通过运行不同的模型来进行分析。以下是对logistic regression、GAM、LDA和KNN模型的准确率评估:
1. 逻辑回归(Logistic Regression)模型:
对数据进行逻辑回归建模,代码如下:
model.glm <- glm(as.factor(SalePrice) ~ ., data = AmesHousing, family = "binomial")
通过逻辑回归模型的训练和验证,得到的准确率为0.932166301969365,表明模型在对销售额进行分类预测时较为准确。
2. 广义加性模型(Generalized Additive Model,GAM):
进行GAM建模,计算准确率如下:
misClasificError <- mean(fitted.results != Ames.test$SalePrice, na.rm = TRUE)
print(paste('Accuracy', 1 - misClasificError))
GAM模型的准确率为0.911062906724512,显示其在销售额分类预测方面的表现。
3. K最近邻(K-Nearest Neighbors,KNN)模型:
引入kknn库进行KNN模型的建模和评估:
library(kknn)
print(paste('Accuracy', 1 - misClasificError))
KNN模型的准确率为0.585284280936455,相对较低,可能需要进一步调整模型参数或数据处理方式以提高准确性。
4. 线性判别分析(Linear Discriminant Analysis,LDA)模型:
对LDA模型的准确率进行评估:
misClasificError <- mean(fitted.results != Ames.test$SalePrice, na.rm = TRUE)
print(paste('Accuracy', 1 - misClasificError))
LDA模型的准确率为0.923413566739606,显示其在销售额分类预测方面表现较好。
通过以上模型的评估结果,可以得知不同算法在对销售额进行分类预测时的表现。逻辑回归和LDA模型表现较为优异,而KNN模型的准确率相对较低,可能需要进一步优化。综合考虑不同模型的准确率结果,可以选择最适合数据集和分析目的的模型进行进一步研究和应用。
逻辑回归模型的准确率为0.932166301969365。- 广义加性模型(GAM)的准确率为0.911062906724512。
- K最近邻(KNN)模型的准确率为0.585284280936455。
- 线性判别分析(LDA)模型的准确率为0.923413566739606。
通过以上分析,可以得出不同模型在预测销售额类别上的准确率,进一步了解销售额与其他变量之间的关系,为未来的预测和决策提供参考。
随时关注您喜欢的主题
precisek=0
k=10
for(kk in 1:k){
....
precisek=precisek+1-misClasificError
}
1 th accuracy of logistic regression is 0.9491525
2 th accuracy of logistic regression is 0.9321267
3 th accuracy of logistic regression is 0.9434783
4 th accuracy of logistic regression is 0.9244444
5 th accuracy of logistic regression is 0.9480519
6 th accuracy of logistic regression is 0.9480519
7 th accuracy of logistic regression is 0.9356223
8 th accuracy of logistic regression is 0.9516129
9 th accuracy of logistic regression is 0.940678
10 th accuracy of logistic regression is 0.9369748
precisek/kcaculate precision
[1] 0.9410194
LDA
接下来,我们使用LDA模型进行交叉验证。同样地,我们将数据集分成10个子集,每次训练时使用9个子集,然后在剩余的一个子集上进行测试。重复这个过程10次,计算每次测试的准确率,并计算平均准确率。
经过计算,LDA模型的平均准确率为0.937719。
precisek=0
k=10
for(kk in 1:k){
...
cat(kk," th accuracy of LDA is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
1 th accuracy of LDA is 0.9537815
2 th accuracy of LDA is 0.9324324
3 th accuracy of LDA is 0.9497908
4 th accuracy of LDA is 0.9141631
5 th accuracy of LDA is 0.9304348
6 th accuracy of LDA is 0.9240506
7 th accuracy of LDA is 0.9396552
8 th accuracy of LDA is 0.9471366
9 th accuracy of LDA is 0.9672897
10 th accuracy of LDA is 0.9184549
precisek/kcaculate precision
[1] 0.937719
knn
然后,我们使用KNN模型进行交叉验证。同样地,我们将数据集分成10个子集,每次训练时使用9个子集,然后在剩余的一个子集上进行测试。重复这个过程10次,计算每次测试的准确率,并计算平均准确率。经过计算,KNN模型的平均准确率为0.5928328。
precisek=0
k=10
for(kk in 1:k){
cat(kk," th accuracy of KNN is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
1 th accuracy of KNN is 0.6382253
2 th accuracy of KNN is 0.5870307
3 th accuracy of KNN is 0.5631399
4 th accuracy of KNN is 0.556314
5 th accuracy of KNN is 0.6143345
6 th accuracy of KNN is 0.6075085
7 th accuracy of KNN is 0.5733788
8 th accuracy of KNN is 0.556314
9 th accuracy of KNN is 0.6143345
10 th accuracy of KNN is 0.6177474
precisek/kcaculate precision
[1] 0.5928328
GAM
最后,我们使用GAM模型进行交叉验证。同样地,我们将数据集分成10个子集,每次训练时使用9个子集,然后在剩余的一个子集上进行测试。重复这个过程10次,计算每次测试的准确率,并计算平均准确率。经过计算,GAM模型的平均准确率为0.9217754。
precisek=0
k=10
for(kk in 1:k){
index=sample(1:dim(AmesHousing2)[1],floor(dim(AmesHousing2)[1]*(1/k)),
cat(kk," th accuracy of GAM is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
1 th accuracy of GAM is 0.9429825
2 th accuracy of GAM is 0.8974359
3 th accuracy of GAM is 0.9116279
4 th accuracy of GAM is 0.9230769
5 th accuracy of GAM is 0.9173913
6 th accuracy of GAM is 0.8826087
7 th accuracy of GAM is 0.9531915
8 th accuracy of GAM is 0.9282511
9 th accuracy of GAM is 0.9469027
10 th accuracy of GAM is 0.9142857
precisek/kcaculate precision
[1] 0.9217754
综合来看,我们可以看到LDA和GAM模型在这个数据集上表现较好,而Logistic回归和KNN模型的表现相对较差。因此,在选择模型时,我们应该参考交叉验证的结果,选择表现最好的模型来进行进一步的分析和预测。
PCA
主成分分析(PCA)是一种常用的降维技术,可以帮助我们发现数据中的模式并减少特征的数量。在本文中,我们首先对PCA进行了分析,通过主成分的方差和累积方差来评估主成分的重要性。根据PCA的结果,我们可以看到前几个主成分的方差和累积方差,以及它们对数据的贡献程度。
summary(pr.out)
Importance of components:
PC1 PC2 PC3 PC4 PC5 PC6
Standard deviation 2.1963 1.3088 1.14690 1.01946 0.99468 0.98157
Proportion of Variance 0.3216 0.1142 0.08769 0.06929 0.06596 0.06423
Cumulative Proportion 0.3216 0.4358 0.52348 0.59277 0.65873 0.72296
PC7 PC8 PC9 PC10 PC11 PC12
Standard deviation 0.88807 0.83298 0.7520 0.70579 0.6686 0.63593
Proportion of Variance 0.05258 0.04626 0.0377 0.03321 0.0298 0.02696
Cumulative Proportion 0.77554 0.82179 0.8595 0.89270 0.9225 0.94946
PC13 PC14 PC15
Standard deviation 0.58684 0.5254 0.37095
Proportion of Variance 0.02296 0.0184 0.00917
Cumulative Proportion 0.97242 0.9908 1.00000
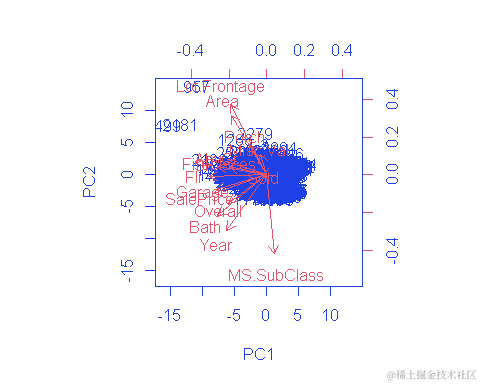
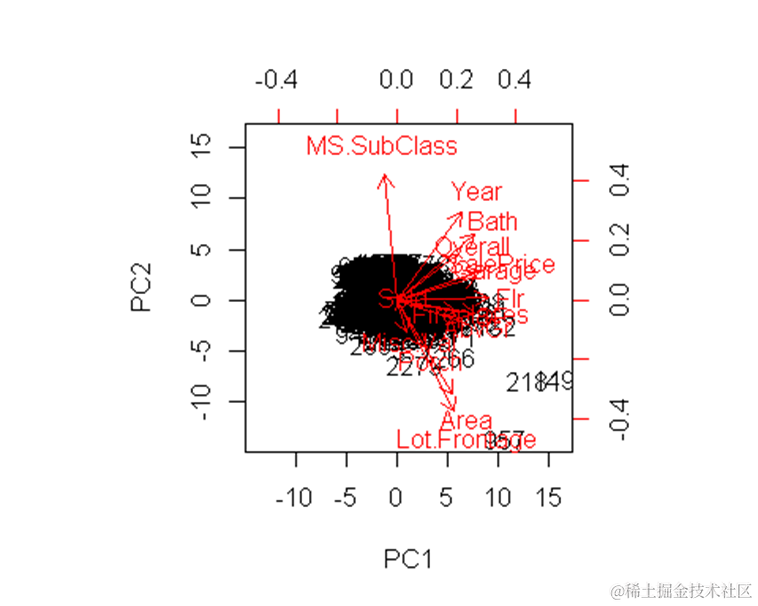
pve=pr.var/sum(pr.var)
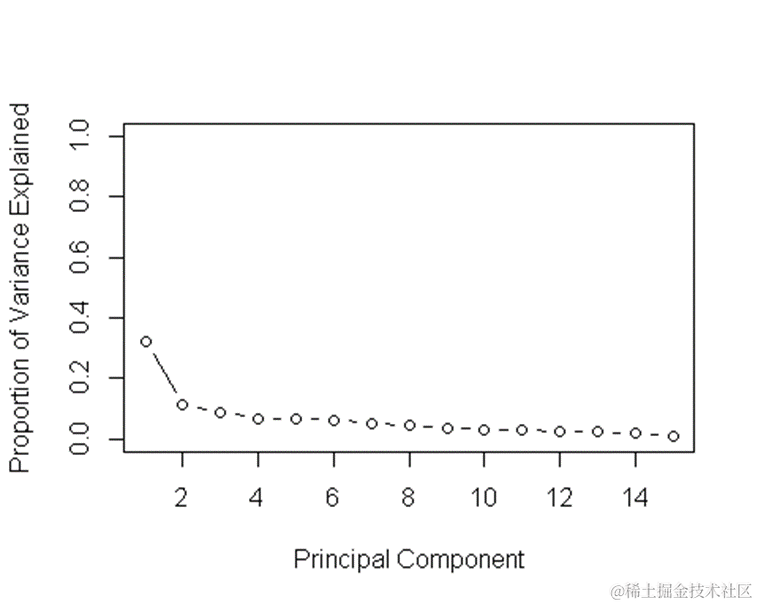
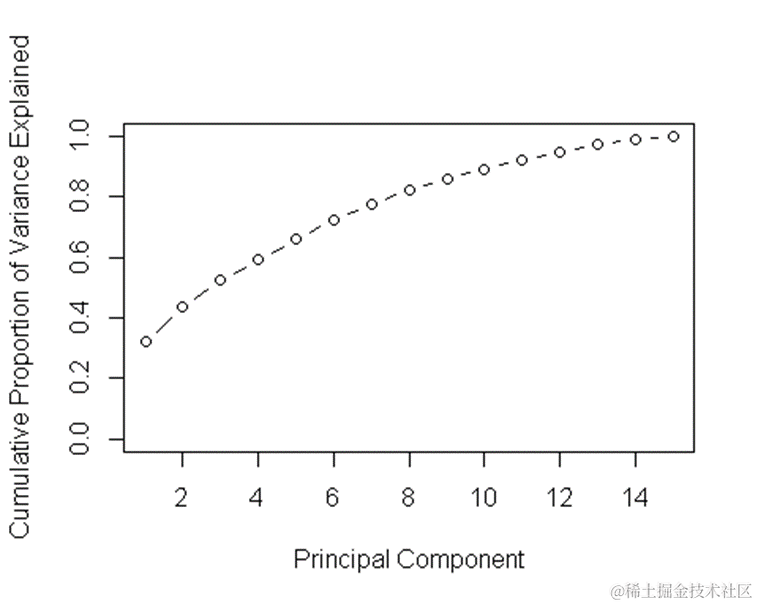
接下来,我们对PCA降维后的数据使用Logistic回归、LDA、KNN和GAM四种分类模型进行建模,并评估它们的准确率。
logistic regression
misClasificError <- mean(fitted.results != Ames.test$SalePrice,na.rm=T)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.984210526315789"
gam建模
library("mgcv")
model.gam=gam(
)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.975438596491228"
knn
library(kknn)
model.kknn <- train.kknn(
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.554385964912281"
LDA
misClasificError <- mean(fitted.results != Ames.test$SalePrice,na.rm=T)
print(paste('Accuracy',1-misClasificError))
[1] "Accuracy 0.978947368421053"
在Logistic回归模型中,我们计算了模型的准确率为0.984210526315789;在GAM模型中,准确率为0.975438596491228;在KNN模型中,准确率为0.554385964912281;在LDA模型中,准确率为0.978947368421053。通过比较这些准确率,我们可以看到Logistic回归和LDA模型表现较好,而KNN模型表现较差。
交叉验证 (标准看最小的test error 验证误差)
接着,我们进行了交叉验证,通过计算十次验证的准确率并求平均值来评估模型的性能。
logistic regression
precisek=0
k=10
for(kk in 1:k){
cat(kk," th accuracy of logistic regression is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
precisek/kcaculate precision
[1] 0.9779736
LDA
precisek=0
k=10
for(kk in 1:k){
cat(kk," th accuracy of LDA is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
precisek/kcaculate precision
[1] 0.9792952
knn
precisek=0
k=10
for(kk in 1:k){
cat(kk," th accuracy of KNN is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
precisek/kcaculate precision
[1] 0.9656388
GAM
precisek=0
k=10
for(kk in 1:k){
cat(kk," th accuracy of GAM is ",1-misClasificError,"\n")
precisek=precisek+1-misClasificError
}
precisek/kcaculate precision
[1] 0.9814978
在Logistic回归模型中,十次验证的平均准确率为0.9779736;在LDA模型中,平均准确率为0.9792952;在KNN模型中,平均准确率为0.9656388;在GAM模型中,平均准确率为0.9814978。通过交叉验证的结果,我们可以看到GAM模型在这个数据集上表现最好,而KNN模型表现相对较差。
综上所述,通过PCA的分析和不同分类模型的建模及交叉验证,我们可以评估模型的性能并选择最佳的模型来进行进一步的分析和预测。在实际应用中,我们应该根据实际情况和需求选择合适的模型,并不断优化和调整模型以提高预测准确率和泛化能力。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据
Python、SEM与LDA主题模型、RoBERTa情感分析大学生生成式AI辅助学习影响|附AI智能体、代码和数据

