本文展示了如何通过矩量的广义方法和广义经验似然来估计模型。
对这两种方法的理论方面进行了简要讨论,并通过经济学和金融学中的几个例子介绍了R语言。
自Hansen ( 1982 ) 以来,广义矩量法 (GMM) 已成为应用经济学和金融学许多领域的重要估计程序。
可下载资源
介绍了两步 GMM (2SGMM)。它可以看作是许多其他估计方法的概括,例如最小二乘法 (LS)、工具变量 (IV) 或最大似然法 (ML)。
因此,它不太可能被错误指定。LS 估计量的性质取决于回归量的外生性和残差的循环性,而 ML 的估计量取决于似然函数的选择。
GMM 更加灵活,因为它只需要一些关于矩条件的假设。例如,在宏观经济学中,它允许通过方程来估计结构模型方程。
介绍
在金融领域,股票收益等大多数数据的特点是重尾分布和偏态分布。因为它不对数据的分布施加任何限制,所以 GMM 在这个领域也是一个很好的选择。
广义矩量法
我们希望根据以下_q_ × 1 无条件矩条件向量从模型中估计参数向量_θ_ 0 ∈ R p :
E [ g ( θ 0 ,xi )] = 0 ,
其中_xi_是横截面数据、时间序列或两者的向量。为了使 GMM 从上述条件产生一致的估计,_θ_ 0 必须是_E_ [ g ( θ,xi )] = 0 的唯一解,并且是紧致空间的一个元素。还需要对_g_ ( θ,xi ) 的更高矩进行一些边界假设。_但是,它对xi_的分布没有施加任何条件,除了当它是时间序列向量时观察的依赖程度。
一些估计方法,如最小二乘法 (LS)、最大似然法 (ML) 或工具变量 (IV) 也可以被视为基于此类矩条件,这使其成为 GMM 的特殊情况。例如,以下线性模型:
Y = Xβ + u,
其中_Y_和_X_分别是_n_ × 1 和_n_ × k_矩阵,可以通过 LS 估计。估计_β ^是通过求解 min β k u k2 获得的,因此是以下一阶条件的解:

这是矩条件_E_ ( Xiui ( β )) = 0 的估计。
同样的模型可以通过 ML 估计,此时矩条件变为:
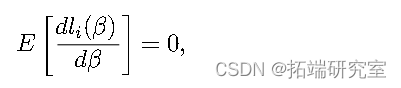
其中_li_ ( β ) 是_ui_的密度。在解释变量_X_存在内生性的情况下,即_E_ ( Xiui ) 6 = 0,通常使用 IV 方法。_它通过将X_替换为工具矩阵_H_来解决内生性问题,该矩阵需要与_X_相关且与_u_不相关。这些属性允许模型通过条件矩条件_E_ ( ui | Hi ) = 0 或其隐含的无条件矩条件_E_ ( uiHi_) = 0。一般来说,我们说_ui与信息集__Ii_正交,或者说_E ( ui | Ii ) = 0 在这种情况下,_Hi_是包含_Ii_的任何元素的函数的向量。因此,该模型可以通过求解来估计
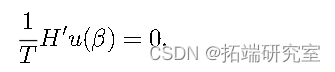
当没有对_u_的协方差矩阵进行假设时,IV 对应于 GMM。如果_E_ ( Xiui ) = 0 成立,则广义 LS 不假设_u_的协方差矩阵(边界矩阵除外)也是 GMM 方法。对于被视为 GMM 的 ML 过程,必须满足关于_u分布的假设。_如果不是,但_E_ ( dli ( θ 0) /dθ ) = 0 成立,因为它是具有非正态误差项的线性模型的情况,使用稳健协方差矩阵的伪 ML 可以看作是GMM 方法。
由于 GMM 仅依赖于矩条件,因此对于经济和金融中的许多模型来说,它是一种可靠的估计过程。
例如,一般均衡模型存在内生性问题,因为这些模型被错误指定并且它们仅代表经济的一部分。因此,具有正确时刻条件的 GMM 比 ML 更合适。在金融中,没有令人满意的参数分布来再现股票收益的特性。稳定分布族是一个很好的候选者,但只有属于该族的正态分布、柯西分布和 L´evy 分布的密度具有封闭形式的表达式。因此,在这种情况下,GMM 的无分布特性很有吸引力。
R 的 GMM
- 估计正态分布的参数 ———
当矩条件信息不足时,这也是 GMM 弱点的一个很好的例子。事实上,正态分布的均值和方差的 ML 估计更有效,因为似然比少数矩条件携带更多信息。
对于正态分布的两个参数 ( µ,σ ),我们有以下矩量条件向量:
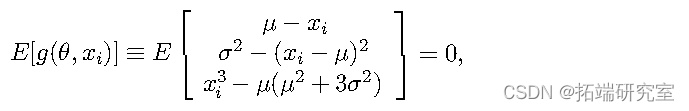
其中前两个可以通过 ( µ,σ ) 的定义直接获得,最后一个来自在 0 处评估的矩生成函数的三阶导数。

我们首先需要创建一个函数_g_ ( θ,x ),它返回一个_n_ × 3 矩阵:
f <- cbind(m1,m2,m3)
以下是¯ g ( θ ) 的梯度:
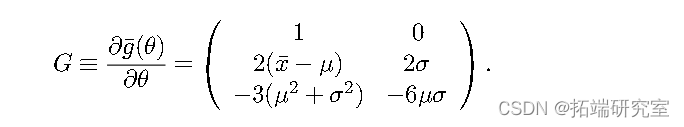
如果提供,它将用于计算_θ_ ^ 的协方差矩阵。
随时关注您喜欢的主题
首先我们生成正态分布的随机数:
> x1 <- rnorm(n, mean = 4, sd = 2)
然后我们使用起始值运行 gmm

summary 方法从估计中输出更多结果:
> summary(res)


“系数的初始值”部分显示了用于计算 2 步 GMM 中的加权矩阵或 CUE 或迭代中的固定带宽的第一步估计GMM。
提取过度识别限制的 J 检验:

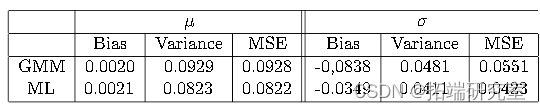
使用以下函数的小型模拟表明,基于上述矩条件,ML 生成的估计量均方误差小于 GMM。然而,不是 GMM 而是矩条件不是有效的,因为 ML 是 GMM,以似然导数作为矩条件。
for(i in 1:iter)
{
x1 <- rnom(n mean = 4, sd = 2)
tet1\[i,1\] <- mean(x1)
tet1\[i,2\] <- sqrt(varx1)*(n-1)/n)
tet2\[i,\] <- gm(g,x1,c(,0),graDg)$oefficiets
}
bias<- cind(rwMens(t(et)-(4,2)),owMans(t(tet2)-c4,2)))
dimnams(bias)<-ist(c("mu","sigma"),c("ML","GMM"))
在n = 50、_iter_ = 2000 并通过设置 set.seed可以重现以下结果:
我们想估计一个具有内生性问题的线性模型。
具有 iid 矩条件的线性ar 模型
xi_的任何函数都可以用作工具,因为它与_i_正交且与_Wi_相关。因此有无数种可能的工具。对于此示例, ( _xi,x 2 i ,x 3 i ) 将是选定的工具,并且样本大小设置为_n_ = 400:
> e <-rmvnorm(,sma=sig > x4 <- rnom(n) > w <- exp(-x4^2) + e\[,1\] > y <- .1*w + e\[,2\]
其中 rmvnorm 是一个多元正态分布随机生成器,它包含在 mvtnorm 包中(Genz、Bretz、Miwa、Mi、Leisch、Scheipl 和 Hothorn(2009 年))。对于线性模型,_g_参数是一个公式,用于指定 lm 的右侧和左侧:
> h <- cbind(x4, x4^2, x4^3) > g3 <- y~w
但是,在实际数据中,建议不要将此选项设置为“iid”,因为我们要使用 GMM 的原因之一是避免此类限制。最后,当模型是线性的时,不需要提供梯度,因为它已经包含在 gmm 中。第一个结果是:


默认情况下,计算 2SGMM。可以通过修改选项“类型”来选择其他方法。第二种可能性是 ITGMM:
type='iterative'
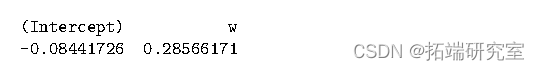
该过程迭代直到两次连续迭代的估计值之间的差异达到某个容差水平,由选项 crit(默认为 10-7)定义,或者如果迭代次数达到 itermax(默认为 100)。在后一种情况下,指示该过程未收敛。
第三种方法是 CUE。如您所见,来自 ITGMM 的估计值用作起始值。但是,仅当 g 是函数时才需要起始值。当 g 是一个公式时,默认的起始值是通过设置权重矩阵等于单位矩阵获得的。
type='cue')

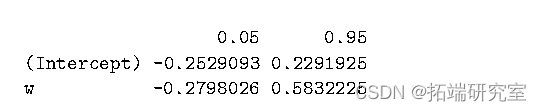
可以使用 confint 方法生成置信区间:
> confint(res3,level=.90)
拟合方法和残差方法也可用于线性模型。我们可以将 lm 的拟合值与 gmm 的拟合值进行比较,看看为什么这个模型不能被 LS 估计。
> plot(w,y)
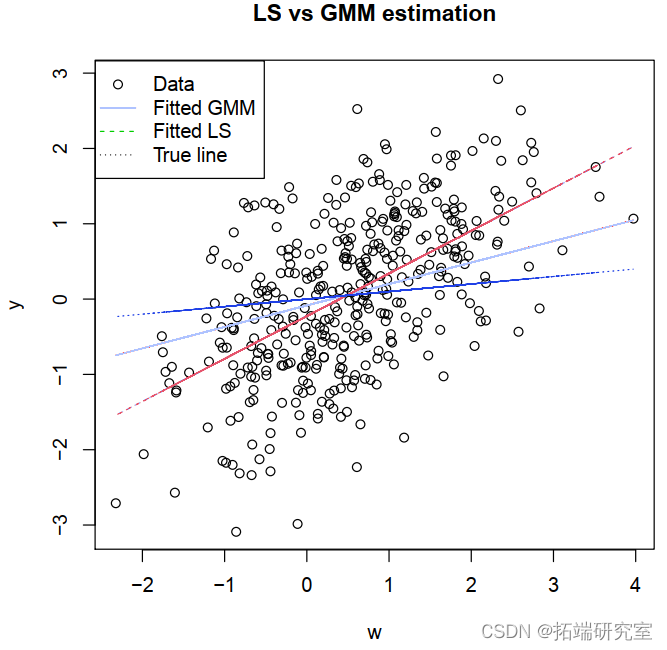
LS 似乎更适合模型。但是图形隐藏了内生性问题。_LS 高估了y_和_w_之间的关系,因为它没有考虑到一些相关性是由_yi_和_wi与误差项__i_正相关引起的。
估计ARMA 过程的 AR 系数
使用 ML 或非线性 LS 可以更好地估计 ARMA(p,q) 过程的自回归系数。但是在蒙特卡洛实验中,往往是通过 GMM 估计来研究它的性质。它给出了具有内生性问题的线性模型的一个很好的例子,其中矩条件是序列相关的并且可能是条件异方差的。与前面的示例相反,HAC 矩阵的选择成为一个重要问题。
对于这个例子,选择的工具是 ( Xt -3 ,Xt -4 ,Xt -5 ,Xt -6) 并且样本大小等于 400。ARMA(2,2) 过程由函数 arima.sim 生成:
> 5 <- arima.sim(n=t)) >

当矩条件基于时间序列时,最优矩阵是由等式(3)定义的HAC矩阵。文献中已经提出了该矩阵的几个估计量。给定一些正则条件,它们是渐近等价的。但是,它们对 GMM 估计器的有限样本属性的影响可能不同。
我们可以将结果与不同的内核选择进行比较:
> coef(res2)

kernel="Bartlett") > coef(res3)

kernel="Parzen") > coef(res4)
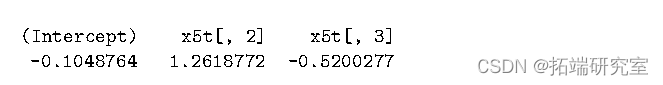
kernel="Tukey-Hanning") > coef(res5)

结果的相似性并不奇怪,因为权重矩阵应该只影响估计器的效率。我们可以使用 vcov 方法比较估计的标准差:



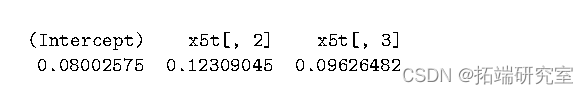
这表明,对于这个例子,巴特利特核生成的估计值具有最小的方差。但是,这并不意味着它更好。如果我们想比较它们,我们必须运行模拟并计算真实的方差。事实上,我们不知道哪一个产生了最准确的方差估计。
第二个选项用于带宽选择。
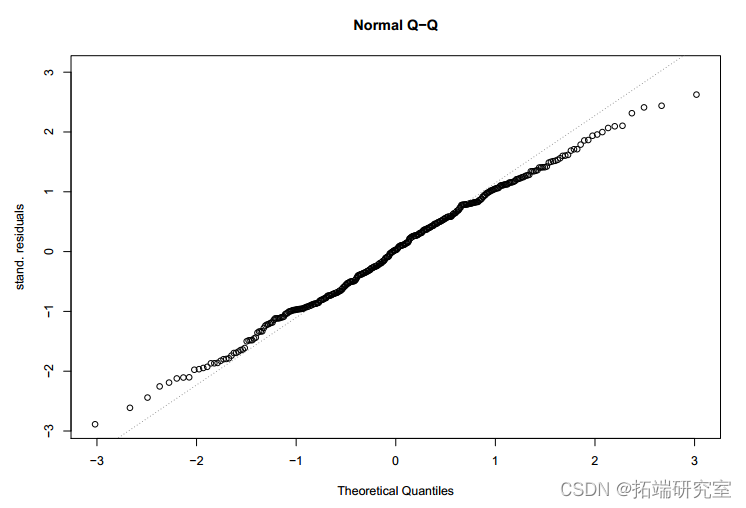
最后,可以对 gmm 对象应用 plot 方法来绘制残差的 QQ 图:
> plot(res,which=2)
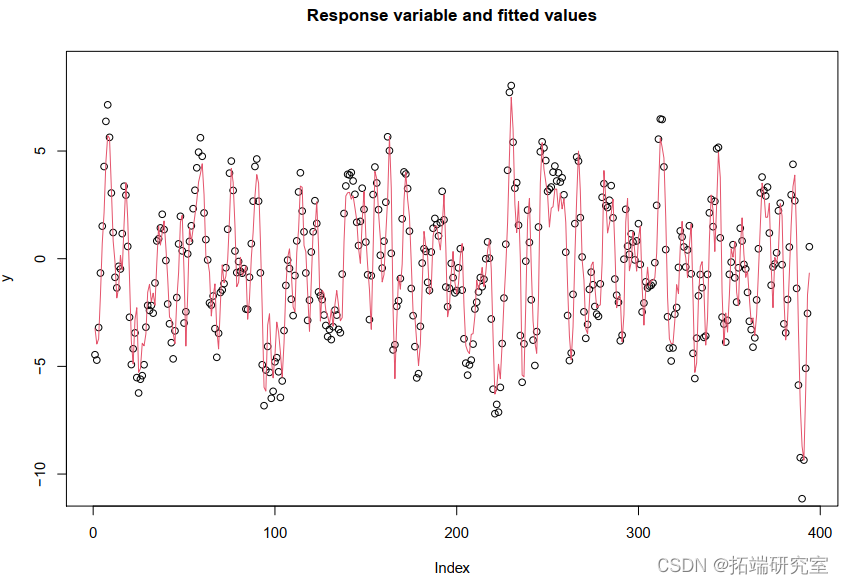
或用拟合值绘制观察结果:
估计方程组:CAPM
我们想测试资本资产定价模型 (CAPM) 的影响之一。
数据包中包含的数据是 1993 年 1 月至 2009 年 2 月 20 只选定股票的日收益率、无风险利率以及 Fama 和 French的三个因素。以下测试是使用 5 只股票的收益和 500的样本量进行的。
> z <- as.matrix(r-rf) > zm <- as.matrix(rm-rf) > coef(res)



其中使用渐近卡方,因为默认分布需要正态假设。可以使用系数的名称执行相同的测试:
测试 CAPM 的另一种方法是估计过度识别的受限模型 ( α = 0),并执行 J 检验。将 -1 添加到公式中会删除截距。在这种情况下,必须将一列 1 添加到工具矩阵中:
> specTest(res2)

证实了该理论的不被拒绝。
广义经验似然
GEL 是一个新的估计方法家族,与 GMM 一样,它是基于矩条件的。它遵循Owen ( 2001 ),他提出了经验似然估计的想法,旨在提高估计器的置信区域。我们在这里简要讨论该方法,而不涉及太多细节。
估计是基于
E ( g ( θ 0 ,xi )) = 0 ,
对于此示例,我们可以将选项 smooth 保留为其默认值,即 FALSE,因为_x_的 iid 属性。良好的起始值对 GEL 非常重要。最好的选择是样本均值和标准差。默认情况下,选项类型设置为 EL。
> summary(res_el)
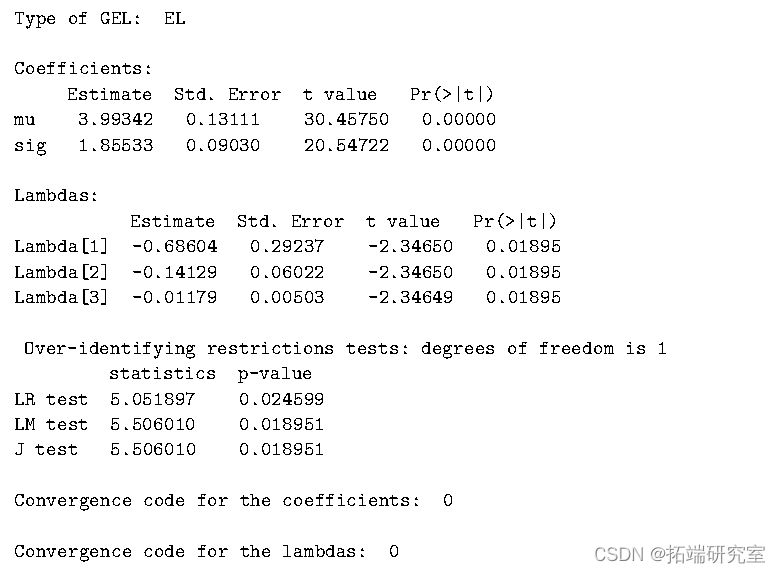
每个拉格朗日乘数代表矩条件隐含的约束的价格。summary 报告了两个收敛代码,一个用于_λ_ ,另一个用于_θ_。
ET 和 CUE 估计值可以如下获得:
type="ET") > coef(r_et)

g1,x1,tet0,type="CUE") > cef(esue)

第四种方法可用,称为指数倾斜经验似然 (ETEL),由Schennach ( 2007 ) 提出。但是,它不属于 GEL 估计器家族。它解决了错误指定模型的问题。在这样的模型中,随着样本量的增加,可能不存在任何_θ ^ 收敛到的伪值。_ETEL 使用 ET 的_ρ_ () 求解_λ_和 EL 的_ρ_ () 求解_θ_。Schennach ( 2007 ) 表明 ETEL 与 EL 具有相同的渐近特性,而不必对_ρ_ ( _v_) 求解_λ_时。
g1,x1,c(mu=1,sig=1),type="ETEL") > oef(re_el)

ETEL 类型目前是实验性的。虽然它应该更稳定,因为求解_λ_不需要任何限制,但是一旦我们在 EL 目标函数中替换_λ_ ( θ ) 来估计__θ_,我们仍然需要限制_λ 0 gt_以避免出现 NA。解决方案是使用 constrOptim获得_λ ( θ ),限制__为 λ 0 gt > 1,即使 ET ( ρ ( v ) = -exp( v )) 不需要它。然而,它对起始值很敏感。这就是为什么我们在上面使用不同的原因。
估计 ARMA 过程的 AR 系数
因为矩条件是弱相关的,我们需要设置选项smooth=TRUE。在进行估计程序之前,我们需要了解平滑核和 HAC 估计器之间的关系。因此,该模型将使用核截断来估计。选择具有单位矩阵的 GMM 估计作为起始值。
watrix="ident")$coef smoothTRUE,kernel="Truncated") > sumay(res)


计算了Smith提出的三个检验2004):
> specTest(res)

plot 产生更多图形。它显示了隐含的概率以及经验密度 (1 /T )。
> plot(res,which=4)
我们还可以选择 optfct=”nlminb” 或 constraint=TRUE 以对系数施加限制。前者设置系数的下限和上限,而后者使用算法 constrOptim 施加线性约束。在此示例中,我们希望 AR 系数的总和小于 1。constrOptim 施加约束_uiθ_ − ci ≥ 0。
因此,我们需要设置:
> ui=cbind(0,-1,-1) > ci <- -1
并重新运行估计
+ constraint=TRUE, ui=ui,ci=ci)
结果是相同的。
也可以使用选项更改优化器控制列表中的默认值LadaCntol(参见 ?nlminb 或 ?optim)。这里有些例子:
+ LambdaControl=list(trace=TRUE, parscale=rep(.1,5)))
结论
R提供了完整和灵活的算法来估计 GMM 和 GEL 模型。为了估计参数向量,用户可以根据是否需要不等式约束来选择他们喜欢的优化算法。对于GEL的拉格朗日乘子向量,可以通过基于牛顿法的迭代程序计算,提高了收敛速度,降低了估计程序的不稳定性。那些对研究这两种方法的数值特性感兴趣的人可以很容易地使用它。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程
llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别
Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别 Python、Amos汽车用户满意度数据分析:BERT情感分析、CatBoost、XGBoost、LightGBM、ACSI、GMM聚类、SHAP解释、MICE插补、PCA降维、熵权法
Python、Amos汽车用户满意度数据分析:BERT情感分析、CatBoost、XGBoost、LightGBM、ACSI、GMM聚类、SHAP解释、MICE插补、PCA降维、熵权法

