在多变量波动率预测中,我们有时会看到对少数主成分驱动的协方差矩阵建模,而不是完整的股票。
使用这种因子波动率模型的优势是很多的。
首先,你不需要对每个股票单独建模,你可以处理流动性相当弱的股票。第二,因子波动率模型在计算成本低。第三,与指数加权模型相比,持久性参数(通常表示为
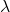
)不必在所有股票上都是一样的。
可下载资源
你可以为每个因子指定一个不同的过程,这样协方差矩阵过程就会有更丰富的动态变化。
但这里没有免费的午餐,代价是信息的损失。它是将协方差矩阵中的信息浓缩为少数几个因子的代价。
这意味着因子波动率模型最适合于实际显示因子结构的数据。因子波动率模型并不是具有弱的截面依赖性的数据的最佳选择。在因子化的过程中会丢失太多的信息。
这篇文章,我们让主成分遵循 GARCH 过程。代数相当简单。
(1) ![]()
(2) ![]()
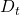 是一个对角矩阵,维数为选定的因子数。将此矩阵设置为对角线意味着主成分之间的协方差为零(所有非对角线元素都为零)。因此它们是正交的。当然,通过构造,主成分只是无条件正交的,但我们添加了约束\假设它们在每个时间点也是正交的。这确保
是一个对角矩阵,维数为选定的因子数。将此矩阵设置为对角线意味着主成分之间的协方差为零(所有非对角线元素都为零)。因此它们是正交的。当然,通过构造,主成分只是无条件正交的,但我们添加了约束\假设它们在每个时间点也是正交的。这确保 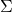 是一个有效的协方差矩阵。
是一个有效的协方差矩阵。
的对角线 填充了因子的方差。这里我们使用阈值-GARCH 模型。
让我们实践。我们使用股票数据。前两个追踪短期和长期的债券收益,后两个追踪股票指数。每日收益矩阵 ret。
下面的代码分为两部分。首先,我们基于单个因子的阈值 GARCH 模型构建了我们自己的双因子正交 GARCH 模型。有几种不同的方法来估计参数(非线性最小二乘法、最大似然法和矩量法)。
#--------------
# 第一部分,自己的双因子正交 GARCH 模型
#--------------------
library(rugarch) # 单变量GARCH模型
# 我使用1000个观察的初始窗口,每增加一个时间点就重新估计模型的参数
wd <- 1000 #初始窗口
k <- 2 #因素的数量
Uvofit <- matrix # 用一个矩阵来保存三种资产的波动率
for(i in wd:T){
pc1 <- promp # 主成分分解
for (j in 1:k){ # 对于每个因素,这里有相同的Garch过程(但可以是不同的)。
gjel = ugarchfit
}
# 不使用内置的 prcomp 函数获得 w。
w <- matrix(eivales, nrow = l, ncol = k, byrow = F) * (eigos)
# 存储每个时间点上的协方差矩阵。
for(i in 1:TT){
# 这是Gamma D_t gamma'。
otch\[i,,\] <- w %*% as.matrix) %*% t(w)
}
# 第二部分。使用广义正交GARCH(GO-GARCH)模型
#--------------
garchestby = "mm"
summary
# 让我们从这个模型中获得协方差
mH <- array
for(i in 1:TT){
yH\[i,,\] <- faf@H\[\[i\]\] 。
}
# 绘制这两张图。因为我们用1000作为初始窗口,所以只画最近的观察值
# 改变k来表示最近的观测值。
k <- TT - wd
teme <- tail(time,k) # 定义时间
# 用来绘制相关图的函数
plot(teime
abline
lines(tetime
# 让我们来看看所产生的相关关系。

随时关注您喜欢的主题
我们看到的是对应于 6 个相关序列(SPY 与 TLT、SPY 与 QQQ 等)。我们自己的估计模型和使用包构建的模型之间几乎没有区别。但我们自己的只使用了 2 个因子,一个差分 GARCH 模型,估计的是窗口而不是整个样本,以及不同的估计方法。我怀疑真实的相关性是否像底部面板中估计的那样稳定。
* 我们在这里混合了代数、概率和几何的术语。正交是一个来自几何学的术语,它是指两个向量之间的角度。如果它们是垂直的,就被称为正交。
代数上,如果它们的内积会发生这种情况
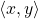
为零。在概率上,回到协方差矩阵,COV(x,y)=E(XY)-E(X)E(Y),但因为因子的平均值为零。COV(x,y)=E(XY)。所以E(XY)=0意味着因子是正交的。本质上,正交性意味着线性独立。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据
Python与CatBoost的顾客婚姻状态预测填补及特征类型策略分析 | 附代码数据



