线性模型是统计学的基础,但它的意义远不止用尺子在几个点上画一条线。
我认为以分布为中心的观点使 generalised linear models (GLM) 也更容易理解。
可下载资源
这就是这篇文章的目的。
广义线性模型,其实没想象中那么吓人,但是大多数文章中的解释都太过公式化,初学者很难从这些抽象的数学推导中去总结宏观的思维过程。
相较与标准线性模型,广义线性模型有两个推广:
响应变量 Y 在标准线性模型中服从于参数为的正态分布(μY,δ2),推广到广义线性模型中,响应变量 Y 服从于指数分布族中的一种分布即可,相关参数根据具体分布而定。(这个指数分布族的坑就很深,手头上没有相关项目我还没有打算花时间去填,只要记住几个常用的指数分布目前也就够用了,比如二项分布、泊松分布等)
线性含义的推广。在标准线性模型中,线性指的是,响应变量 Y 所服从的正态分布的参数 μY 是线性的,即 μY =a + bx 当然这个线性可以从 x 这个角度做其他推广,多元、非线性之类)。而在广义线性模型中,线性推广至,响应变量 Y 所服从的一个分布(指数分布族)的参数θ它的函数 f(θ)是线性的,即(同样可以从 f(θ)= a + bx 这个角度做其他推广,这里的 f(θ) 我们称为联结函数)。
我将使用冰淇淋销售统计数据来说明不同的模型,从传统的线性最小二乘回归开始,到线性模型、对数变换线性模型,然后是广义线性模型,即泊松(log ) GLM 和二项式(逻辑)GLM。
数据
这是我将使用的示例数据集。它显示了在不同温度下销售的冰淇淋单位。正如预期的那样,更多的冰淇淋在更高的温度下出售。
basicPlot()
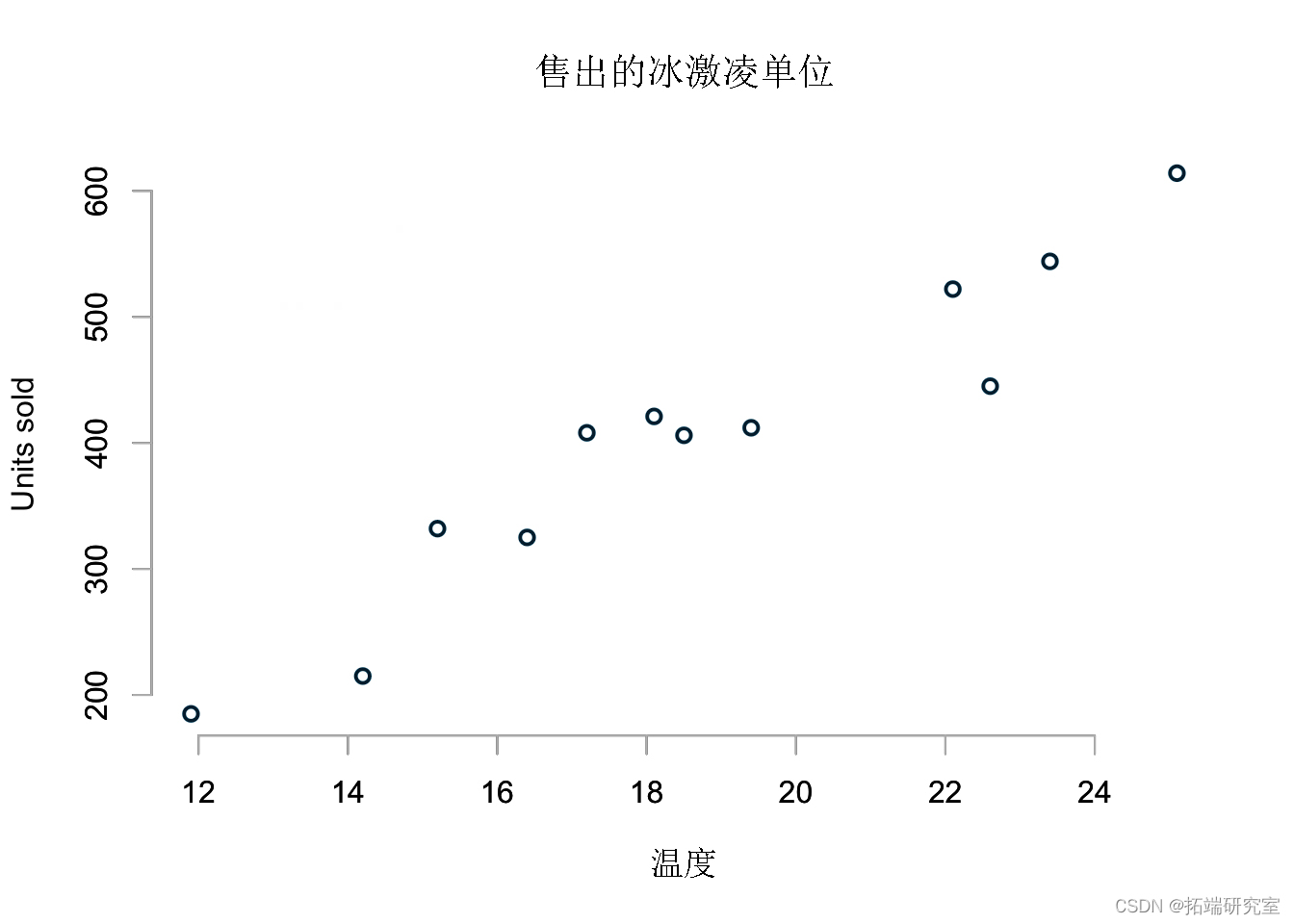
挑战
我想创建一个模型来预测在任何温度下销售的单位,即使在可用数据范围之外。
我特别感兴趣的是,当室外结冰时,我的模型在更极端的情况下会如何表现,比如温度下降到 0ºC 并且预测一个非常炎热的夏日在 35ºC。
线性最小二乘
我的第一种方法是用尺子在这些点上画一条直线,这样可以最大限度地减少点和线之间的平均距离。这基本上是一条线性最小二乘回归线:
lqd <- lsfit abline
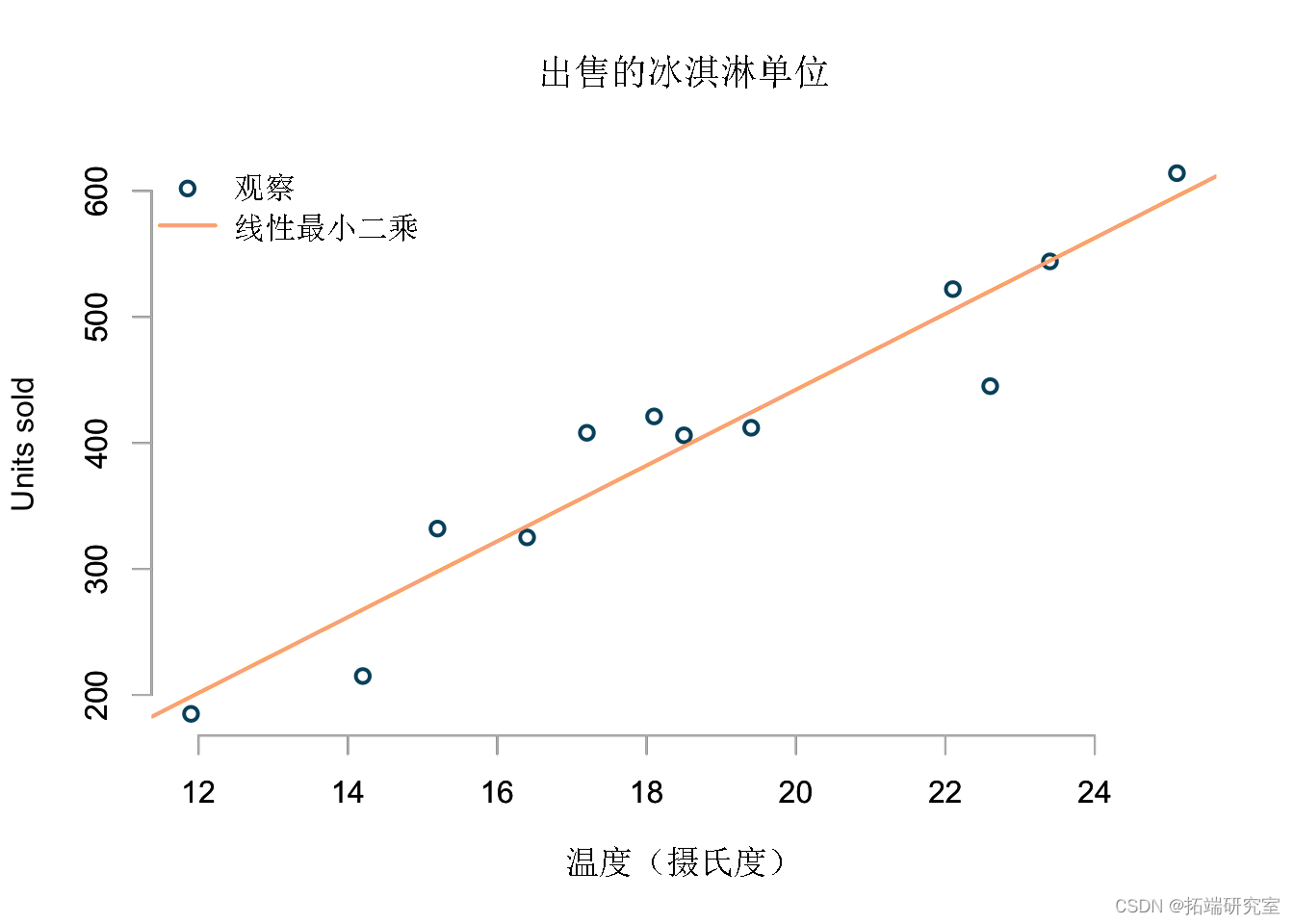
这很容易,而且看起来并非不合理。
线性回归
我相信观测值 yi 是从具有平均 μi 的正态(又名高斯)分布中得出的,这取决于温度 xi 和所有温度下的恒定方差 σ2。
在另一天,在相同温度下,我可能售出了不同数量的冰淇淋,但在相同温度下的许多天里,售出的冰淇淋的平均单位将趋向于 μi。

因此,使用以分布为中心的符号,我的模型如下所示:
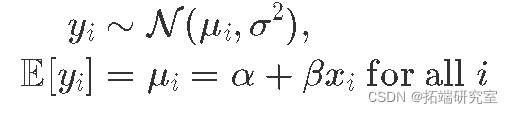
或者,残差,即观察值和预测值之间的差异,遵循均值为 0 且方差为 σ2 的高斯分布:
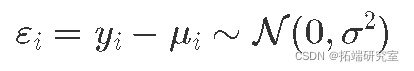
此外,方程
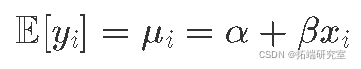
我认为 yi 的期望值与基础分布的参数 μi 相同,而方差是恒定的。
随时关注您喜欢的主题
以经典误差术语约定编写的相同模型如下所示:
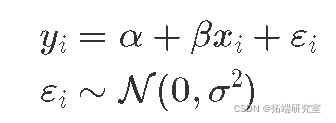
我认为以概率分布为中心的约定更清楚地表明我的观察只是分布的一种实现。此外,它强调分布的参数是线性建模的。
为了在 R 中明确建模,我使用 glm 函数,将响应分布指定为高斯分布,并将从分布的预期值到其参数的链接函数指定为恒等式。
这就是 GLM 全部内容。

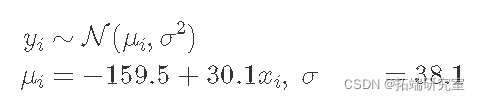
尽管线性模型在观察到的温度范围内看起来不错,但在 0ºC 时没有多大意义。
截距为 -159,这意味着客户在冰冻天平均买 159 个单位的冰淇淋。
对数变换的线性回归
我可以先转换数据。理想情况下,我想确保转换后的数据只有正值。在这些情况下,我想到的第一个转换是对数。
因此,让我们以对数尺度对冰淇淋销售进行建模。因此,我的模型更改为:

这个模型意味着我相信销售额服从对数正态分布,yi∼logN(μi,σ2),这意味着我认为较高的销售数字比较低的销售数字更有可能,因为对数正态分布是右偏的。
尽管模型在对数尺度上仍然是线性的,但我必须记住将预测转换回原始尺度(记住 E[log(yi)]≠log(E[yi])):
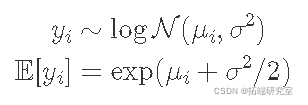
display(logn.mod)

Plot() lines legend

该图看起来比之前的线性模型好一点,它预测我在 0ºC 时平均会卖出 82 个冰淇淋:
虽然这个模型更有意义,但似乎高估了在越来越低的温度下销售。
exp(coef(lo.i.d)\[1\])

此外,这个模型和之前的线性模型还有另一个问题。
假设的模型分布生成实数,但我的销售统计数据是单位,因此总是整数。尽管售出的平均单位数量可能是实数,但从模型分布中抽取的任何数据都应该是整数。
泊松回归
计数数据的经典方法是泊松分布。
泊松分布只有一个参数,这里是 μi,这也是它的期望值。μi 的链接函数是对数,这意味着我必须将指数函数应用于线性模型才能恢复到原始比例。这是我的模型:
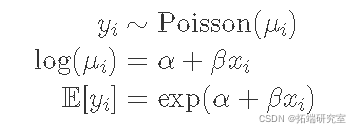
再说一遍,虽然我观察到的期望值是实数,但泊松分布只会产生整数,与实际销售额相符。
pos.md <- glm display(poi.od)

Plot() lines
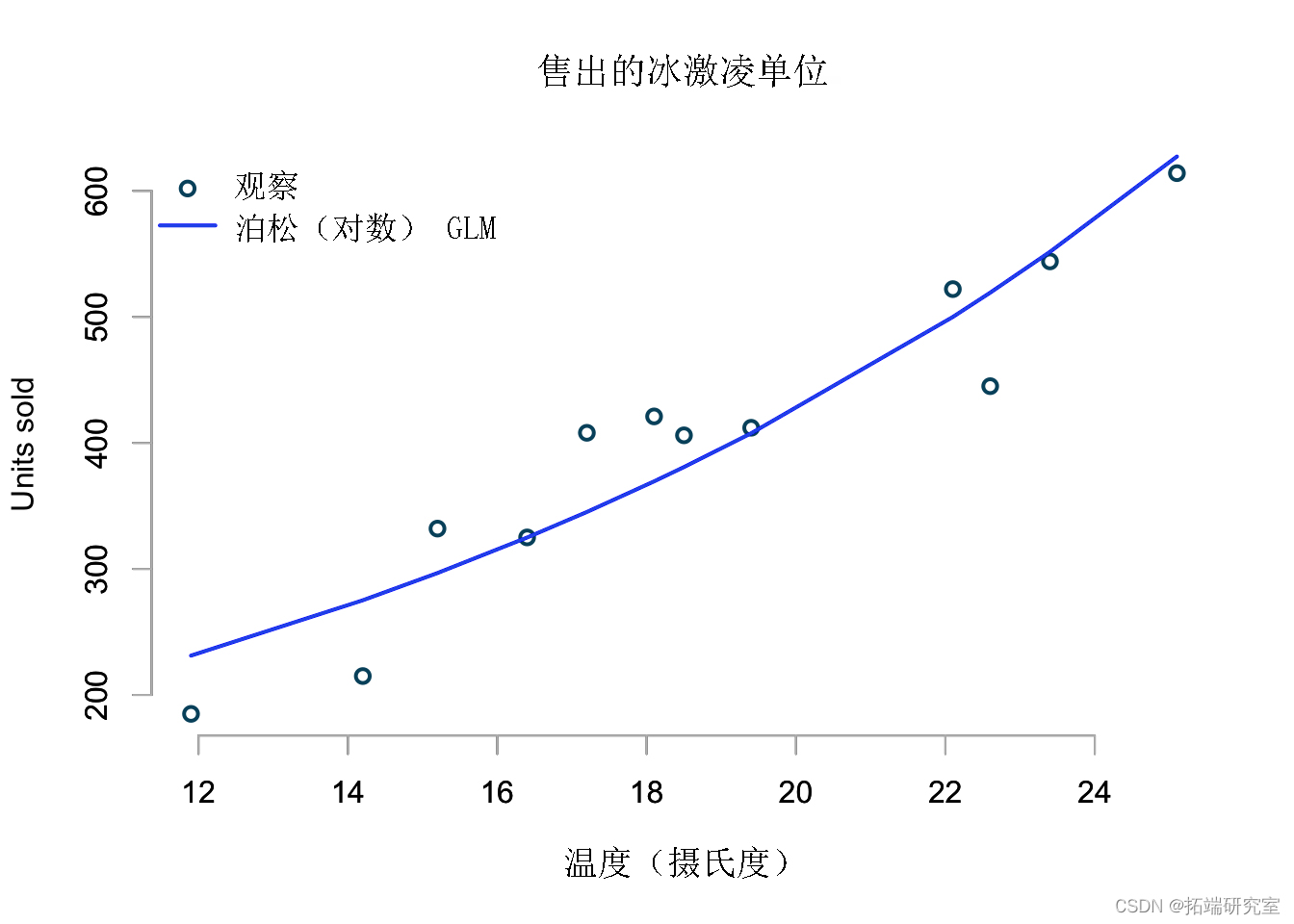
这看起来很不错。系数的解释现在应该很清楚了。
从系数中我可以看出,0ºC 时,我预计会卖出 exp(4.45)=94 冰淇淋,而温度每升高 1 度,预计销量会增加 exp(0.076)−1=7.9% .
到现在为止还挺好。我的模型符合我的观察。此外,它不会预测负销售额,如果我使用上述模型给出的平均值从泊松分布进行模拟,我将始终只得到整数。
但是,我的模型还会预测,如果温度达到 32 摄氏度,我应该会卖出 1000 多个冰淇淋:
predict(pmod, newdata)

二项式回归
好的,让我这样思考这个问题:我有 800 个潜在销售量,我想了解在给定温度下销售的比例。
这表明成功销售数量为 800 次的二项式分布。二项式分布的关键参数是成功概率,即有人购买我的冰淇淋的概率作为温度的函数。
因此,我需要一条将销售统计数据映射到 0 到 100% 之间的概率的 S 形曲线。
一个典型的选择是逻辑函数:
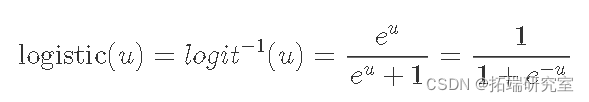
有了这个,我的模型可以描述为:
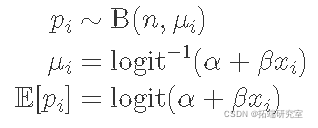
mize <- 1000 icectunity <- marksize - icenits display(b.glm)

binred <- predict(biglm, type="response")*marsize basicPlot
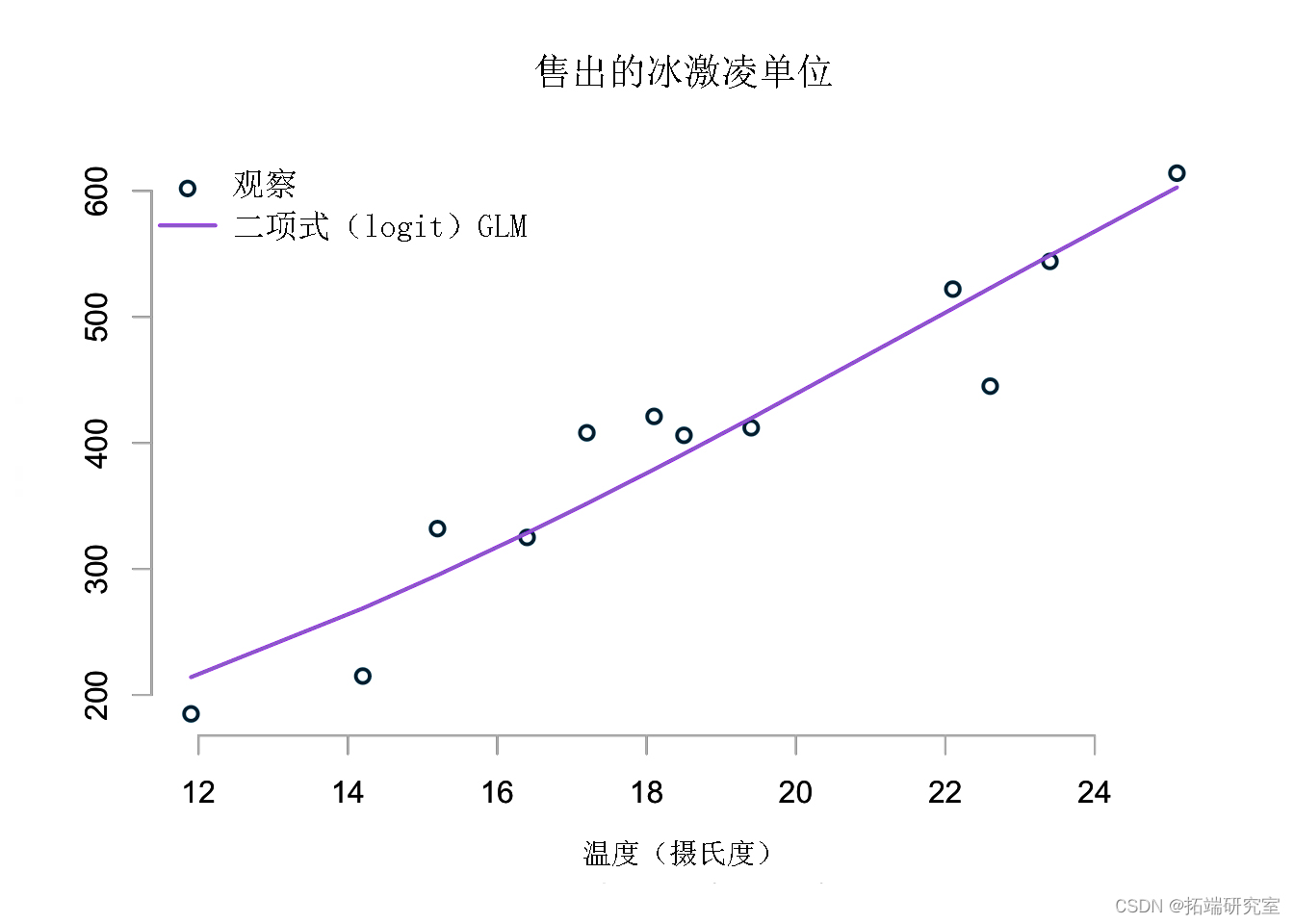
随着温度越来越高,该模型将预测销售将达到市场饱和,而迄今为止所有其他模型都将预测越来越高的销售。
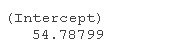
我可以使用逻辑函数的倒数来预测 0ºC 和 35ºC 时的销售额:
# 0摄氏度下的销售 plogis(coef(biglm)\[1\])*market.size
# 在35摄氏度下销售 plogis(coef(bnm)\[1\] + coef(bglm)\[2\]\*35)\*maksie
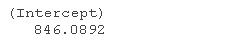
概括
让我们将所有模型放在一张图中,温度范围为 0 到 35ºC。
p.lm <- predict po.lm <- exp + 0.5 * sumary(loim)$dispersion) p.pis <- preict(poiso daaframe(tp=tm, type="response") p.bn <- predict(biglm, datafrme(emptem), type="espns")*arke.ze baPlot
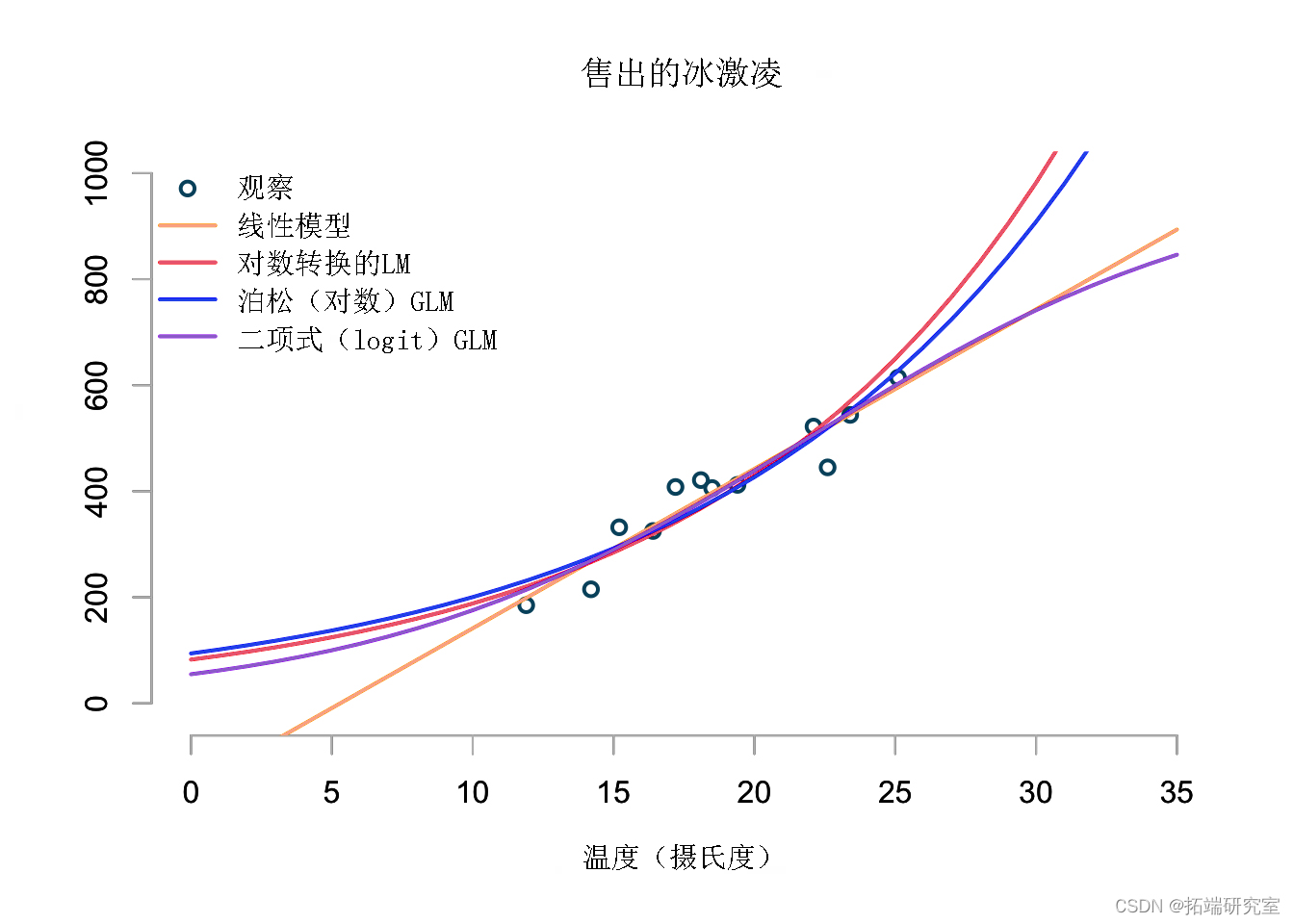
该图表显示了我的四个模型在 0ºC 到 35ºC 的温度范围内的预测。尽管线性模型在 10ºC 到 30ºC 之间看起来还可以,但它清楚地表明了它的局限性。对数变换的线性模型和泊松模型似乎给出了类似的预测,但将预测随着温度的升高,销售额将不断加速增长。我不相信这是有道理的,因为即使是最喜欢冰淇淋的人也只能在非常炎热的一天吃这么多冰淇淋。这就是为什么我会使用二项式模型来预测我的冰淇淋销量。
模拟
使用以分布为中心的视图来描述我的模型自然会导致模拟。如果模型很好,那么我应该无法从模拟中识别出真实数据。
在我所有的模型中,线性结构都是
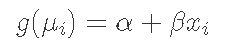
或以矩阵表示法
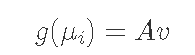
其中 Ai,⋅=[1,xi] 和 v=[α,β],其中 A 是模型矩阵,v 是系数向量。
话虽如此,让我们模拟原始数据中测量的温度的每个分布的数据,并与实际销售单位进行比较。
n <- nrow(icre) A <- modl.(uits ~ temp, data=cam) set.seed(1234) (rad.nal <- rnorm(n, mean A %*% cof(li.od), sd = sqrt(sumary(liod)$esion)))

(ranlans <- rlnorm(n, mnog = A %*% coef(.od), sdlog = sqrt(summary(loiod)$isin)))

(nd.ps <- rpois(n, labd = exp(A %*% coef(piod))))

(ra<- rbinom(n, size = meze, prob = plogis(A %*% coef(b.m))))

bacPlot cols <- adscor(c points(iceram$tmp, pch=19, col=cols\[1\])
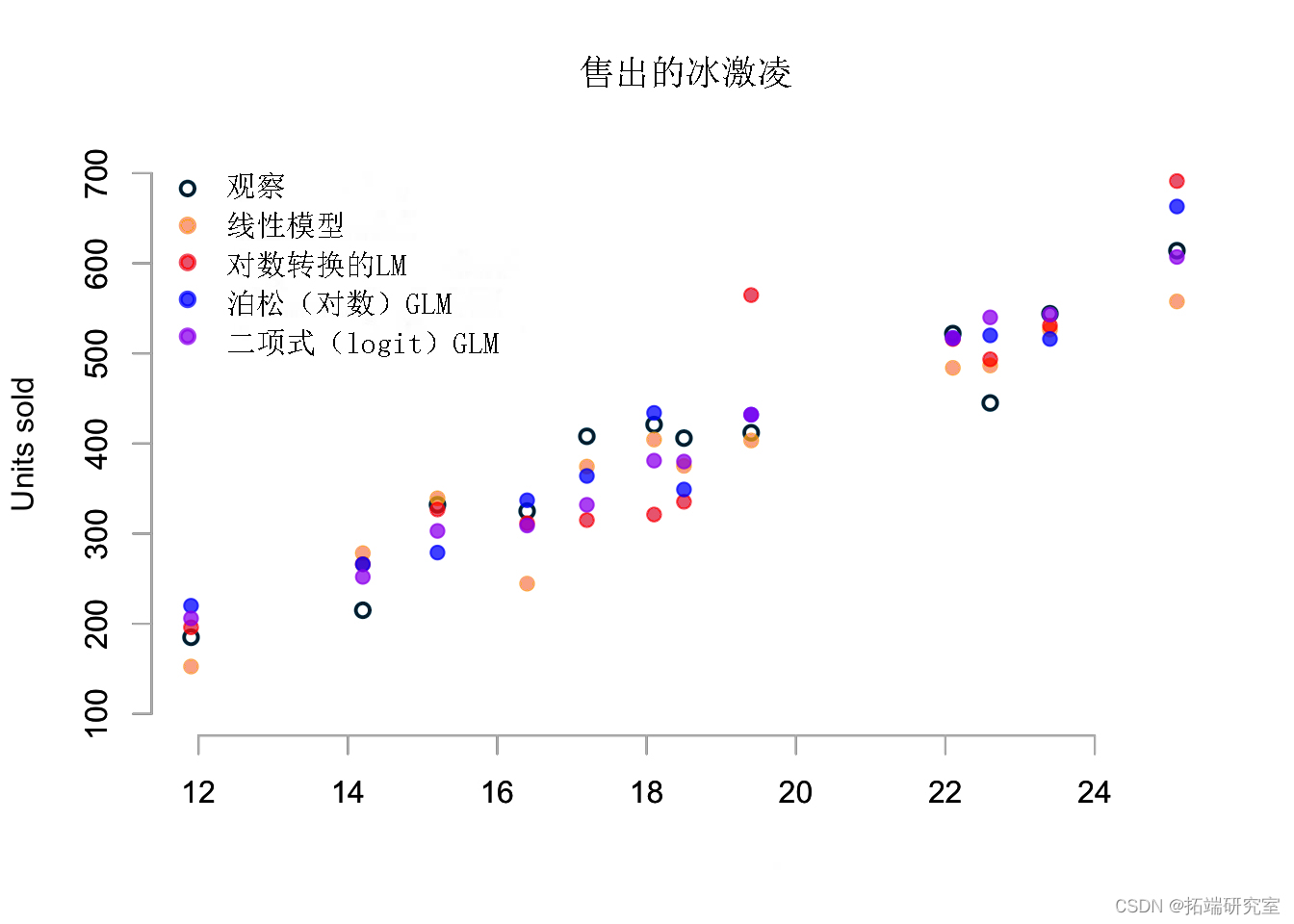
该图表仅显示每个模型的一个模拟,但显示了一些有趣的方面。我不仅看到泊松和二项式模型生成整数,而高斯和对数变换的高斯预测实数,我注意到红点处对数正态分布的偏度为 19.4ºC。
此外,线性模型预测高于和低于平均值的可能性相同,在 16.4ºC 时,预测似乎有点低 – 可能是结果。
此外,对数转换和泊松模型在 25.1ºC 时的高销售额预测也不意外。
同样,二项式模型的模拟似乎是最现实的。
结论
我希望这篇文章能说明广义线性模型背后的直觉。
将模型拟合到数据需要的不仅仅是应用算法。特别值得思考的是:
- 期望值的范围:它们是有界的还是范围从 -∞ 到 ∞?
- 观察类型:我期望实数、整数还是比例?
- 如何将分布参数与观测值联系起来
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究 Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化
Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化 Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证
Python农业气象预测:优化决策树、SHAP模型可解释性、滑动窗口时序分析及交叉验证 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
