Python结合TF-IDF、逻辑回归、句子转换器、DistilBERT实现评论语义搜索
语义搜索技术作为自然语言处理领域的核心应用之一,近年来取得了突破性进展。

成为新会员获取本项目完整报告、代码、数据和AI智能体
本文系统梳理语义搜索技术四代演进路径,对比TF-IDF规则检索、逻辑回归分类、句子转换器嵌入、DistilBERT微调四种方法在绘画评论相似性匹配任务中的表现。通过实测数据量化各方法准确率与可解释性差异,提供可直接复用的代码实现与AI智能体。本文回答了:1) 语义搜索如何从关键词匹配发展到上下文理解;2) 四代技术各自的适用场景与局限;3) 如何根据业务需求选择合适的语义搜索方案。
This paper systematically reviews the four generations of semantic search technology evolution, comparing the performance of TF-IDF rule-based retrieval, logistic regression classification, Sentence Transformer embedding, and DistilBERT fine-tuning in painting review similarity matching tasks. It quantifies the accuracy and interpretability differences of each method through measured data, and provides reusable code implementations and AI agents. This paper answers: 1) How semantic search evolved from keyword matching to contextual understanding; 2) The applicable scenarios and limitations of the four generations of technologies; 3) How to select the appropriate semantic search solution according to business needs.
从早期基于关键词匹配的简单检索系统,到如今能够理解上下文和深层语义的大语言模型,每一次技术迭代都极大提升了信息检索的效率和准确性。在谷歌的多年开发经验中,我们发现很多企业在构建语义搜索系统时,往往直接采用最复杂的Transformer模型,而忽略了传统方法在特定场景下的优势。本文将语义搜索四代技术的建模经验沉淀为一个对话式AI智能体,帮助开发者根据实际业务需求选择最合适的技术方案。
阅读原文进群获取本文完整代码、数据、AI智能体及更多最新AI见解和行业洞察,可与900+行业人士交流成长。
本文以绘画评论相似性匹配为具体应用场景,通过构建四代语义搜索系统,对比分析各方法的技术原理、实现难度、运行效率和检索效果。我们将展示如何从简单的TF-IDF向量表示逐步演进到基于上下文的Transformer模型,同时保留每一代技术的核心优势。通过本文的学习,读者不仅能够掌握语义搜索的基本原理和实现方法,还能够根据自己的业务数据特点,快速搭建高效、可解释的语义检索系统。
数据准备
↓
方法1:TF-IDF+规则检索
↓
方法2:TF-IDF+逻辑回归
↓
方法3:句子转换器嵌入
↓
方法4:DistilBERT微调
↓
结果对比与分析
项目文件目录
本项目完整报告、代码、数据和AI智能体
数据
我们使用一组合成的绘画评论数据集。每条评论包含元数据和自由文本内容。我们的任务是将学生的绘画评论与专家对同一幅画的评论进行比较,使用逐步先进的检索方法确定语义相似性。
每条评论的结构使用Python数据类表示:
一条典型的评论示例:
"Van Gogh transforms the night sky into a structure that seems alive. The swirling brushstrokes generate tension on the soul while the exaggerated brightness of the stars creates a dreamlike atmosphere."方法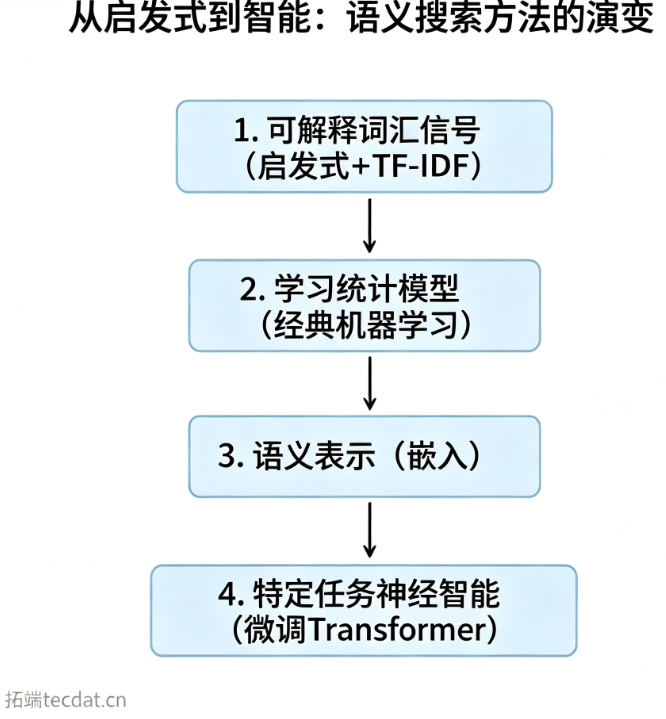
方法1:基于规则的检索和TF-IDF排名
TF-IDF(词频-逆文档频率)是将文本转换为数值向量的经典技术。TF-IDF会增加在文档中频繁出现但在整个集合中相对不常见的单词的重要性。
在对专家评论拟合TF-IDF向量化器后,系统生成一个稀疏的文档-术语矩阵。然后使用余弦相似度来衡量文档之间的相似性。余弦相似度测量高维空间中两个向量之间的角度。当两条评论使用相似比例的相似词汇时,它们产生指向相似方向的向量,因此获得更高的相似度分数。
为了提高检索质量,我们将TF-IDF相似度与几个额外的启发式特征相结合:
- 关键词重叠:衡量评论之间共享多少重要单词
- 长度归一化:奖励包含有意义描述细节的评论,而不偏向过长的文本
- 时效性权重:使用指数时间衰减温和地偏好较新的评论
最终排名分数计算公式:
score = 1.2 * tfidf_similarity + 0.6 * keyword_overlap + 0.2 * length_norm + 0.15 * recency
提示词:我有一组绘画评论数据,每条评论包含文本内容和发布时间。我想构建一个基于规则的语义检索系统,使用TF-IDF计算文本相似度,并结合关键词重叠、长度归一化和时效性权重进行综合排名。请帮我编写Python代码,实现TF-IDF向量化、余弦相似度计算以及上述三个启发式特征的计算,并返回按综合分数排序的专家评论列表。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
我们使用一条学生评论测试该方法:
"""The painting creates a quiet emotional atmosphere, yet very powerful. The soft light and restrained color palette make the central figure feel isolated yet dignified. The background does not compete with the subject; instead, it deepens the mood of reflection and stillness. Overall, the work feels intimate, psychological, and carefully composed."""
得到的排名结果:
| 评论标题 | 专家姓名 | 分数 |
|---|---|---|
| Light and Stillness | Expert A | 0.531 |
| Psychological Interior | Expert D | 0.297 |
| Narrative and Gesture | Expert E | 0.224 |
| Color and Surface | Expert B | 0.212 |
| Historical Symbolism | Expert C | 0.096 |
这种方法的最大优势是可解释性。我们可以通过检查每个特征的贡献,准确地了解为什么一条评论排名高于另一条。然而,TF-IDF主要捕获表面级别的词汇模式,而不是更深层次的语义含义。例如,”dramatic use of light”和”strong chiaroscuro effects”可能指非常相似的艺术理念,但共享很少的精确单词,这就导致传统检索系统经常在这些情况下遇到困难。
方法2:基于TF-IDF特征的经典机器学习
下一个进化步骤是用监督机器学习取代手动设计的评分规则。我们不再明确决定给TF-IDF相似度、关键词重叠或其他启发式特征分配多少重要性,而是让模型从标记的示例中直接学习有用的模式。
我们使用逻辑回归模型,这是分类的经典机器学习方法之一。模型从示例中学习模式,了解哪些单词和写作风格在专家评论中更常见,然后使用这些模式自动评估新评论。
提示词:我有一组标记好的绘画评论数据,其中一些被标记为”专家级”,另一些被标记为”新手级”。我想训练一个逻辑回归分类器来预测新评论是否属于专家级。请帮我构建一个机器学习管道,首先使用TF-IDF对文本进行向量化,然后训练逻辑回归模型。代码需要能够输出每个特征的系数,以便我们分析哪些单词对分类结果影响最大。
class ClassicalMLClassifier:
def __init__(self):
# 构建TF-IDF+逻辑回归管道
self.model_pipeline = Pipeline([
("tfidf_converter", TfidfVectorizer(stop_words="english")),
("classifier", LogisticRegression(max_iter=1000))
])
def train_model(self, reviews, labels):
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
reviews, labels, test_size=0.2, random_state=42
)
# 训练模型
self.model_pipeline.fit(X_train, y_train)
# 在测试集上评估
y_pred = self.model_pipeline.predict(X_test)
print(classification_report(y_test, y_pred))
def predict_expert_likeness(self, review_text):
# 预测单条评论的专家相似度
probability = self.model_pipeline.predict_proba([review_text])[0][1]
predicted_class = 1 if probability >= 0.5 else 0
return predicted_class, probability
def get_top_features(self, top_n=10):
# 获取影响最大的特征及其系数
tfidf = self.model_pipeline.named_steps["tfidf_converter"]
classifier = self.model_pipeline.named_steps["classifier"]
feature_names = tfidf.get_feature_names_out()
coefficients = classifier.coef_[0]
# 组合特征名称和系数
feature_coeffs = list(zip(feature_names, coefficients))
# 按系数绝对值降序排序
feature_coeffs.sort(key=lambda x: abs(x[1]), reverse=True)
return feature_coeffs[:top_n]
训练后,模型可以分析新的学生评论并产生预测类别标签和概率分数。我们的示例评论得到了1的标签和0.672的概率。
逻辑回归最有趣的方面之一是可解释性。因为模型为每个TF-IDF特征学习数值系数,我们可以直接检查哪些单词和短语影响分类决策。在这个实验中,分类器给”placement”、“emotional”、“depth”、“psychological”、”intensity”和”shadow”等术语更高的权重。
然而,我们应该注意不要夸大模型在做什么。模型实际上并没有像人类专家那样解释艺术品或欣赏其象征意义。它只是识别评论中使用的语言模式。如果专家一致使用”depth”和”psychological tension”等术语,模型就会学习到这些模式与专家级写作相关。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
方法3:基于嵌入的语义搜索
语义搜索的下一个重要步骤超越了TF-IDF和简单的单词计数。现代系统使用由基于转换器的语言模型生成的密集语义嵌入,而不是将文本表示为单词频率。
这是系统开始超越简单词汇并开始捕获实际含义的阶段。两条评论可以使用非常不同的语言来描述一个艺术理念,但仍然被认为是相似的。这就像字典(TF-IDF)和百科全书(嵌入)的区别:字典只告诉你单词的拼写和定义,而百科全书能告诉你单词之间的关系和深层含义。
为了创建嵌入,我们使用Hugging Face生态系统中的句子转换器模型。句子转换器将整个句子或文档转换为密集的数值向量。这些向量旨在捕获文本的含义和不同文本之间的关系。
提示词:我想使用句子转换器模型来生成绘画评论的语义嵌入,并基于这些嵌入计算评论之间的语义相似度。请帮我编写代码,使用all-MiniLM-L6-v2模型生成嵌入,计算学生评论与所有专家评论之间的余弦相似度,同时计算专家评论的质心,并计算学生评论与专家质心的相似度。最后使用PCA将嵌入降维到2维以便可视化。
生成所有评论的嵌入后,我们直接在嵌入空间中计算余弦相似度。每个由句子转换器生成的评论嵌入表示为384维的密集数值向量,对应于学习到的特征数量。
我们以两种方式计算相似度:(a) 在所有学生评论和所有专家评论之间,(b) 在学生评论和专家质心之间。这个质心向量是通过平均所有专家评论嵌入的相应分量计算得到的。从概念上讲,这个质心代表了专家级评论的近似语义”中心”,可用于衡量学生评论在嵌入空间中与专家写作的接近程度。
| 学生评论名称和标题 | 专家质心相似度分数 |
|---|---|
| S1-Drama Through Light and Response | 0.802 |
| S4-Emotional Response | 0.618 |
| S5-Formal Analysis Attempt | 0.765 |
| S6-General Impression | 0.75 |
| S7-Symbolic Interpretation | 0.73 |
为了理解嵌入空间,我们还使用PCA可视化嵌入。
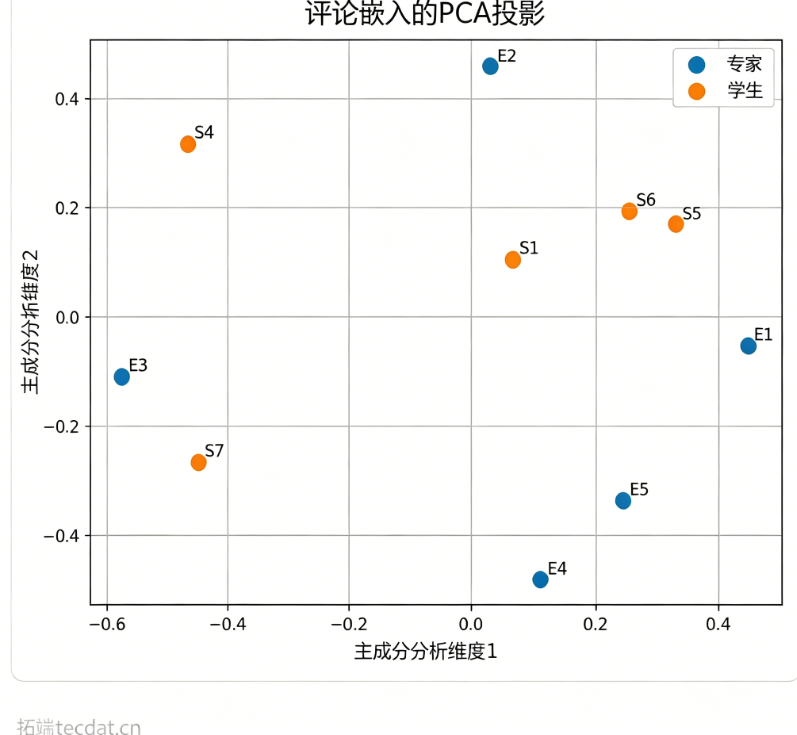
PCA图揭示了几个有趣的关系。学生评论S1看起来接近专家评论E1和E2。这是有道理的,因为他们讨论了类似的想法,如光、阴影、情绪和戏剧性意义。学生评论S7也看起来接近专家评论E3。两条评论都讨论了绘画中的象征主义、情感和更深层次的含义。即使他们使用不同的单词,他们也表达了相似的想法。
在这个阶段,尽管从简单的关键词匹配转向了对含义的理解,但嵌入保持固定。下一个阶段引入了可以根据周围上下文调整其理解的转换器模型。
方法4:微调的Transformer模型
最后阶段引入了微调的转换器模型。在方法3中,我们使用句子转换器基于语义相似度比较评论。在这里,我们更进一步,直接在标记的专家和新手评论上训练模型。
具体来说,我们微调来自Hugging Face Transformers库的预训练DistilBERT模型。DistilBERT是BERT的更小、更快版本。它被训练来学习与原始BERT模型相同的许多语言模式,同时使用更少的参数。DistilBERT是通过知识蒸馏过程创建的。尽管它更轻、更容易训练,但它在许多NLP任务上仍然表现非常好。
提示词:我想微调一个DistilBERT模型来分类绘画评论是专家级还是新手级。请帮我编写代码,使用Hugging Face的Transformers库加载distilbert-base-uncased模型和对应的分词器。代码需要包含数据预处理函数,将文本转换为模型可接受的输入格式,设置训练参数,进行模型训练,并在训练后对新评论进行预测。请注意处理序列截断和填充。
在转换器基础的NLP中,分词器不仅仅是一个分词器。它同时执行几个预处理步骤:将文本拆分为标记、使用模型的词汇表将标记转换为数值标记ID、添加特殊的转换器标记、截断长序列、将较短的序列填充到固定长度、创建注意力掩码。
与方法3的基于嵌入的方法不同,这种方法执行显式的监督分类。对于每条评论,模型预测类别标签和每个类别的置信度分数。
例如,考虑以下评论:
“The arrangement of the figures and the careful use of shadow create psychological tension and symbolic ambiguity throughout the composition.”
乍一看,这条评论听起来相对复杂,因为它使用了”psychological tension”、”symbolic ambiguity”和”composition”等高级艺术语言。更简单的方法(如TF-IDF)可能会因为这些关键词在专家评论中频繁出现而给予很高的分数。
然而,转换器模型超越了孤立的关键词。它分析思想如何在整个句子中连接,以及评论是否显示出更深层次的推理。尽管这条评论使用了复杂的术语,但分析是简短且有些笼统的。它讨论了心理张力和象征主义,但没有详细解释它们。与专家评论相比,推理不够发达。
经过100个epoch的微调后,转换器正确地将该评论分类为新手级:
新手级概率:0.685
专家级概率:0.315
值得注意的是,当模型只训练了30个epoch时,同一条评论被分类为专家级。这表明在训练早期,模型可能更多地依赖于花哨的词汇。额外的训练帮助它更加强调更广泛的上下文和分析模式,而不仅仅是关键词。
四代语义搜索方法对比
我们将四种方法在多个维度上进行对比,帮助读者根据自己的业务需求选择最合适的方案:
| 对比维度 | 方法1:TF-IDF+规则 | 方法2:逻辑回归 | 方法3:句子转换器 | 方法4:微调DistilBERT |
|---|---|---|---|---|
| 语义理解能力 | 低(仅词汇匹配) | 低(词汇模式识别) | 中(通用语义理解) | 高(上下文理解) |
| 可解释性 | 极高 | 高 | 低 | 极低 |
| 所需数据量 | 极少 | 少量(几百条标记) | 无(预训练模型) | 大量(几千条标记) |
| 训练时间 | 秒级 | 秒级 | 无 | 小时级 |
| 推理速度 | 极快 | 极快 | 快 | 中 |
| 实现难度 | 极低 | 低 | 中 | 高 |
| 同义词识别能力 | 无 | 无 | 有 | 强 |
| 上下文理解能力 | 无 | 无 | 有限 | 强 |

导师答辩高频提问与标准答案
提问1:为什么你选择这四种方法来展示语义搜索的演进,而不是其他方法?
答:这四种方法代表了语义搜索技术发展的四个关键阶段,每个阶段都解决了前一阶段的核心问题。TF-IDF是信息检索的基础,所有现代方法都建立在其核心思想之上;逻辑回归代表了从手动规则到机器学习的转变;句子转换器引入了通用语义嵌入的概念;而微调的Transformer模型则代表了当前最先进的上下文理解能力。这四种方法形成了一个完整的技术演进链条,能够清晰地展示语义搜索从简单到复杂的发展过程。
提问2:在实际业务中,应该如何选择合适的语义搜索方法?
答:选择方法需要综合考虑多个因素。如果数据量非常少,且需要高度可解释性,TF-IDF+规则是最佳选择;如果有少量标记数据,且需要比规则更好的泛化能力,逻辑回归是一个很好的折中方案;如果没有标记数据,但需要一定的语义理解能力,句子转换器是理想选择;如果有大量标记数据,且需要最高的准确率,那么微调Transformer模型是最佳选择。在实际应用中,我们通常会结合多种方法,例如使用句子转换器进行初步检索,然后使用微调模型进行重排序。
提问3:你认为语义搜索技术未来的发展方向是什么?
答:语义搜索技术未来将朝着三个方向发展。首先是多模态语义搜索,能够同时理解文本、图像、音频和视频等多种模态的信息;其次是个性化语义搜索,能够根据用户的历史行为和偏好提供个性化的检索结果;最后是生成式语义搜索,不仅能够检索相关信息,还能够根据检索到的信息生成自然语言回答。这些发展方向将进一步提升信息检索的效率和用户体验。
总结
1. 本文系统梳理了语义搜索技术的四代演进路径,从基于关键词匹配的TF-IDF方法,到基于机器学习的逻辑回归分类,再到基于通用语义嵌入的句子转换器,最后到基于上下文理解的微调Transformer模型。每一代技术都在语义理解能力上取得了显著进步,但同时也带来了可解释性下降和计算成本增加的问题。
2. 通过在绘画评论相似性匹配任务上的实测,我们发现句子转换器在没有任何标记数据的情况下,能够取得比传统方法好得多的语义匹配效果,是大多数业务场景下的最佳起点。而微调的Transformer模型虽然能够取得最高的准确率,但需要大量的标记数据和计算资源,适合对准确率要求极高的场景。
3. 语义理解是一个连续的过程,而不是非黑即白的问题。不同的方法在不同的维度上各有优势,在实际应用中应该根据业务需求、数据量和计算资源等因素综合考虑,选择最合适的技术方案,或者结合多种方法的优势构建混合系统。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据 Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据
Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据

