由于某大学学生人数过多,助教不足,因此有必要对期中考试给每个学生的题目数量施加五道题的限制。
所有必须使用的问题必须来自大约 400 个预先批准的问题的测试库。
50% 的问题可以在期中使用。这项数据驱动研究的目标是找到应该从考试生成算法中排除的问题,以提供班级中最有意义的学生排名。
数据分析
动机
数据由 409,520 个观察值、12839 名学生和 391 个问题组成。这意味着最多可以从测试库中排除 195 个问题。在我开始任何数据分析之前,必须为分析准备数据。首先,我检查是否有任何学生没有正确回答或所有学生都正确回答的问题。如果所有学生都答错了一道题,说明题目太简单了。反之,如果所有学生都答对了一道题,则说明这道题太难了。无论哪种情况,这些问题都不会对中期结果造成任何差异。因此,我可以立即删除这些问题。
#检查是否有问题太容易 gros = databy(\['question_id'\]).mean() proect = groions\[\['correct'\]\].sores(by='correct') prot.head()
可下载资源

#检查是否有问题太难 prrect.tail()
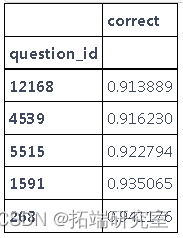
从第一个表格中,我们看到没有任何问题一个学生也没回答正确。但是,通过查看第二张表,我们看到每个人都正确回答了一个问题,因此我们从数据集中删除了该问题。
daa = da.loc\[dta\['qu_id'\] != 12665\]
在考虑使用机器学习或统计方法时,我最初的想法是找到回答中差异最大的问题,并将回答中相关性高的问题分组(即,正确回答问题 A 的学生也倾向于正确回答 B 题)。我意识到这种方法行不通,因为具有高方差的问题并不一定意味着它是创建有意义的学生等级的好问题(例如,它可能是每个人都猜测的难题)。此外,我还必须考虑每个学生的能力差异。这让我想到了潜在变量建模,其中潜在变量将是每个学生的能力和每个问题的难度,这就是我如何找到 IRT 模型的。

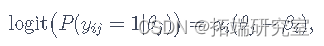
其中 θj是学生的能力,βi是问题的难度,αi是问题区分弱学生和强学生的程度。
并非每个学生都会回答数据集中的每个问题。这使得标准回归方法变得困难,但贝叶斯方法在这种情况下仍然可以很好地工作。我使用 pystan 在数据上拟合 2 参数 Rasch 模型,然后对 αi 参数进行后验。之后,我保留 196 个具有最大平均后验 α 值的问题。这些问题最能区分理解材料的学生和不理解材料的学生。不幸的是,我无法验证我对原始数据的分析,因为我不知道真实的参数值。但是,如果我使用已知参数模拟数据并使用这种贝叶斯 rasch 模型方法恢复这些参数,那么我可以自信地在真实给定数据上使用模型得出推论。
随时关注您喜欢的主题
模拟研究
对于模拟,测试库中将有 400 个问题,只有 500 名学生。学生回答的问题数量是一个随机正态变量,平均值为 100,标准差为 10。这是为了模拟在实际数据集中,每个学生回答的问题数量不同。判别参数 αj 取自均值为 0.5 且形状为 1 的对数正态分布,难度参数 βj 取自均值为 0 且标准差为 5 的正态分布,学生能力参数 θj 取自标准正态分布。结果变量(学生是否正确回答问题)是随机伯努利变量,成功概率为每个学生-问题对的 αi(θj-βi) 的逆对数。
nutions = 400 nuents = 500 #为400个试题生成区分度和难度参数 aphas = scipy.stvs(s=1, loc=0.5, size=num_questions) beas = scim.rvs(scale=5, size=num_questions) #为500名学生生成能力参数 theas = scinorm().rvs(ntudents) #挑选学生回答的问题;每个学生随机回答30个左右的问题 ag = 100 #回答的平均问题 sd = 10 qet = np.rint(scrm.rvs(loc=a, sce=sd, size=umdns)).asye(int) nu\_bs = np.sum(quton\_c_tdent) stdnm = np.reat(npange(1,np.sze(qsdt)+1), quets\_ac\_sdnt) qeoncumn = np.empty(numbs) rrecumn = np.empty(nm_os) prenix = 0 #追踪我们正在更新的索引 for i in rage(n_ses): nq = quunt\[i\] #学生i的问题数 quere = pre(nins, nq, relce=Flse) #随机选择每个学生回答的问题 s\_lm\[pn:pr\_dex + nq\] = qeed p = siypcs\[\] * (hta\[i\] - ets\[qioed\])) coom\[pre_ie:rnx + nq\] = cisnlrs(p) pesn\_idx = ren\_idx + nq qsnmn = (qti_lmn + 1).ayp(int) #pystan的索引从1开始 coc_umn = cotcon.atype(int)
在我们模拟数据并正确格式化以便 pystan 可以处理它之后,我们将数据传递到我们将用于真实数据的模型中。
int<lower=1> I; // # 问题 int<lower=1> J; // # 人数 int<lower=1> N; // # 观察值 int<lower=1, upper=I> i\[N\]; // n的问题 ctor<lower=0>\[I\] alp; // 项目i的鉴别力 beta; // 项目i的难度 apa ~ lognormal(0.5,1); bea ~ normal(0,10); tea ~ normal(0,1); y ~ brnollilogit(alha\[ii\] .* (tea\[jj\] - bta\[ii\]))。
从后验分布采样后,我检查参数的后验均值。如果模型在恢复参数方面做得很好,则参数的后验均值与实际参数值的散点图应以恒等线为中心。
我们希望得到后验抽样的平均值
sm = pystan(model_code=lrte) #pystan model
#index 9是实际后验参数值出现在数据帧中的地方 # meaahas = preaha.man()\[9:\].asaix() plt.figure() plt.scatter(alha, meanphas) #为beta绘制图表 lntrt = bamn() plt.figure() plt.scar(beas, men_eas) #为thetas绘制图表 linSart = hets.n() liend= thtas.max()
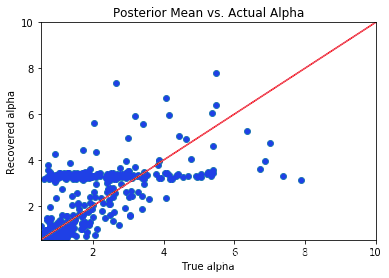

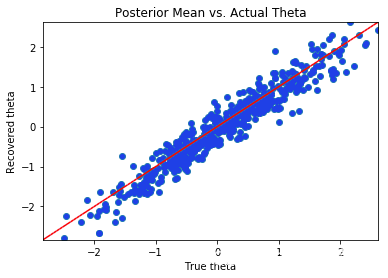
上面的 3 个散点图表明,虽然贝叶斯 2 参数 IRT 模型方法成功地恢复了学生的能力 θ,但它未能恢复 β 和 α 参数。对于 β 参数,当 β 介于 -5 和 5 之间时,预测 βs 的后验均值大致等于真实值。对于较大的 β 值,后验图似乎被放大了。我们最关心的参数集 α 参数的散点图似乎大致沿着恒等线下降,除了一个异常平坦的点,其中 αs 的后验均值略大于 3,而与真实值无关。虽然这种方法没有像我们希望的那样准确地推断出歧视参数,但它做得还不错。鉴于模型拟合选项的数量有限和时间限制,我们继续采用这种方法。由于实际数据集中每个问题的数据点更多,因此模型推理应该会有所改进。
模型拟合
接下来,我将贝叶斯模型应用于实际给定的数据集。首先,我检查每个学生看到了多少问题,以及每个问题有多少学生回答了问题。此外,如果一个问题没有被多次回答(< 50),那么很难推断出该问题的难度。在这些情况下,删除与这些学生和问题相关的观察可能是有意义的。
qutount = dta.grby(\['quesid'\]).sie() #得到回答每个问题的学生的数量 quess_50 = quescount\[quesnt < 50\] #获得少于50名学生的问题的ID
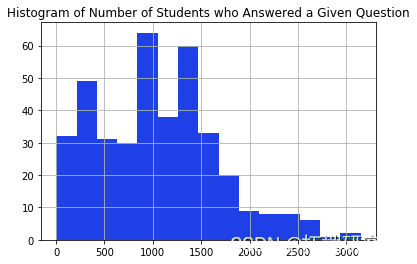
在我淘汰回答少于 20 个问题的学生之前,我会检查那些回答较少问题的学生是否比那些回答较多问题的学生弱。我可以通过比较 2 个不同人群正确回答的问题比例分布来粗略检查这一点。从下面的直方图中,直方图的形状似乎相同,因此我们可以继续过滤掉回答少于 20 个问题的学生。
useont = ata.goupy(\['usr_id'\]).size() usr20 = use\_cout\[erut\_cot >= 20\] #获得回答20个问题或以上的学生的id
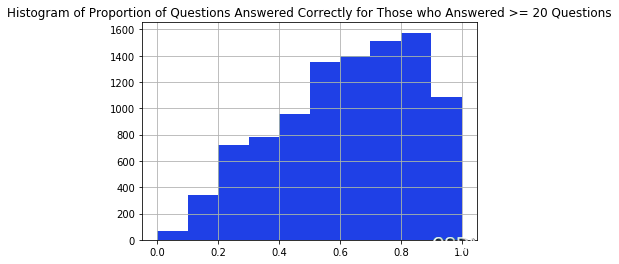
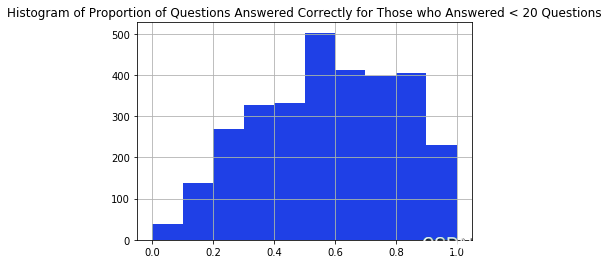
#过滤掉没有足够观察力的问题和用户 ata = da.oc\[data'urid'\].is(uer\_r\_20.ie)\] ata =datoc\[~dat\['qtion\_i'\].i(qesonles\_5)\]
过滤掉一些问题和学生后,我们剩下 378 个问题和 9785 个学生,总共 357,352 个观察值。接下来,我将问题的 ID 和学生的 ID 分别映射到集合,因为 pystan 需要这些标识符是从1开始的连续正整数。然后我们可以将数据传递到pystan中的模型中。
# 将问题的ID映射到1,2,...。 uni = np.uqu(daa\['qustonid'\]) newid1 = p.arng(1,en(niqq)+) qdit dict((unq\_q, ne\_id) dta\['\_id = daa.pply(lmbdaro: qict\[ow.qesion\_i\], xs=1) # 将学生ID映射到1,2,... uiqu = n.uiqe(dat\['use_d'\]) ne\_2 = np.ange1,len(uq\_)+1) dit = dit(zp(unq_, nw_i2)) aa\['uid'\] = daa.pp(lama ow: uit\[row.ser_\], xis=)
我们现在可以将数据传递到 pystan 以检索 αj 的后验图。
# 将数据格式化后传入pystan # 将模型与真实数据进行拟合 ralfi = s.salng(ata=rtdata, ite=100chais=4, sampe\_fil='Rel\_Draws, njs4, ctol='adpt\_dela' 0.75 'max\_tredeph' 15})
#得到196个具有最高歧视参数的问 alandi = (al_st)rsrt()\[:196\] + 1 #反向映射以获得问题的原始ID imp = v: kfor k,v in qict.tems(ices)
#找到问题库和问题清单之间的区别 qutino\_rop= \[q fo q in queston\_bak ifq not in qeonep pin(quesiono_dro)



上面显示了基于贝叶斯 2 参数 IRT 模型方法要丢弃的 195 个问题的 ID。由于这些问题在区分理解材料和不理解材料的学生方面做得最差,删除这些问题将使用测试生成算法提供最有意义的排名。
限制和未来的工作
虽然贝叶斯 2 参数 IRT 模型方法能够有效地推断学生的能力,但它几乎不能推断出问题的难度或区分值。此外,IRT 模型假设问题是可交换的,而实际上它们是连续相关的(例如,学生在回答更多问题时可能会感到疲劳)。违反这一假设可能会影响分析结果的有效性。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据
Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据 【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用
【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用

