在数据驱动的时代,数据科学家肩负着从海量数据中挖掘价值的重任。
本专题合集聚焦于租房市场数据的深度剖析,涵盖了北京短租房评价影响因素研究以及上海链家租房数据的探索。
北京短租房研究中,从 Airbnb 获取 2019 年 4 月 17 日北京地区公开数据,包括房源基础信息、时间表信息、评论信息以及行政区划数据。通过筛选变量,对离散型和连续型变量进行相关性检验,再进行特征转换,构建逻辑回归和决策树模型,并对模型优化。
在对北京短租房的研究里,研究人员从 Airbnb 平台获取了 2019 年 4 月 17 日北京地区的公开数据。这些数据包含了多个方面:
- 房源基础信息:例如房源的类型(公寓、别墅等)、房间数量、可容纳人数等,这些信息能让我们对房源的基本情况有一个初步了解。
- 时间表信息:可能是房源的可预订时间、入住和退房时间等,有助于分析房源的使用情况和租客的时间安排。
- 评论信息:租客对房源的评价内容,从中可以了解租客对房源的满意度、优缺点等。
- 行政区划数据:北京不同区域的划分信息,这有助于区分城区和郊区的房源情况。
结果显示,城区和郊区短租房评分影响因素差异显著,郊区租客重居住体验,城区租客重房源可靠性。
上海链家租房数据方面,利用 Python 从Lianjia.com.csv 文件获取租房信息,经过 ETL 数据预处理、探索性分析及数据可视化后,构建岭回归、Lasso 回归、Random forest 随机森林、XGBoost、Keras 神经网络、kmeans 聚类等模型预测房租。
视频
【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列预测
视频
Lasso回归、岭回归等正则化回归数学原理及R语言实例
视频
R语言机器学习高维数据应用:Lasso回归和交叉验证预测房屋市场租金价格
视频
逻辑回归Logistic模型原理和R语言分类预测冠心病风险实例
北京市短租房评价影响因素研究
短租房是指是将房屋短期出租给客人,它提供从一日起到几个月的租赁服务,集住宅、酒店、会所多功能于一体,具有“自用”和“投资”两大功效,是业主将自己住所的空余部分短期出租给他人的一种经营形式。
当前短租房交易主要活跃于一线城市和旅游城市,房源数、用户数、交易额都在连年持续增加,这使得短租房之间的竞争变得越发激烈。客户和网站对不同的房源会有不同的评分,如何探索并提供用户最想要的关键价值要素,在竞争中取得胜利从而获得更多利益就显得尤为关键。
解决方案
任务/目标
选取一系列房源信息与其评分信息,根据城郊空间特征对评分的影响因素进行差异性分析。
数据源准备
数据来自 Airbnb 于 2019 年 4 月 17 日公开的北京地区数据。数据均来源于 Airbnb 网站的公开信息,不包含任何个人隐私数据。
数据整合、填补缺失值
筛选变量
将所有变量分为两组:离散型和连续型,用不同的方法分别对此变量与是否为市区进行相关性检验。
离散型变量以“户主是否为超级户主”这一变量为例,得到的结果如下:
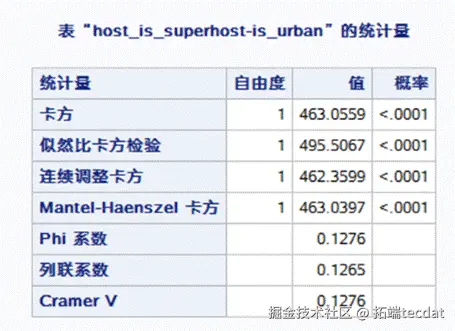
由于p<0.0001,因此“户主是否为超级户主”这一变量在市区和郊区存在差异。同理对其他离散型变量做检验,发现所有的变量均满足相关性。
对连续型变量同样做相关性检验,结果如下:
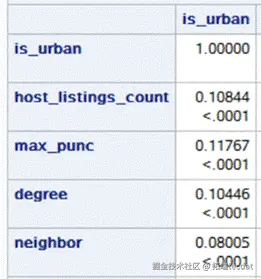
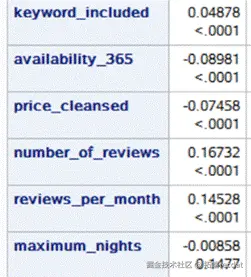
除“maximum_nights”之外其他变量均满足相关性。
特征转换
将卧室数目,浴室数目以及房东所有房源数按照不同数目人工分类为定性变量;将市郊区的房型分别用哑变量表示,房东回复时间,房间类型和房源位置是否精确,房东是否为超级房东也依次以哑变量替换
①房型进一步筛选分类:
城区:将除了’Apartment’,‘House’,‘Condominium’,‘Loft’,‘Serviced apartment’(五个城区中房源占比最大的五种房型的并集)以外的房源类型单独作为一类处理。
郊区同理。(‘Apartment’,‘House’,‘Condominium’,‘Loft’,‘Farm stay’)
②删除认为无关的自变量number_of_reviews reviews_per_month。
③响应变量:
Ⅰ将针对房源具体方面(如实描述/accuracy,干净卫生/cleanliness,入住顺利/checkin,沟通交流/communication,位置便利/ location,高性价比/value)的分数加和;由于每项满分十分,共6项,为了和总分review_scores_rating(满分100)量纲一致,乘上权重10/6作为新变量(对房源具体方面的评分)review_scores_specific

想了解更多关于模型定制、咨询辅导的信息?
Ⅱ将review_scores_rating和review_scores_specific加权求和形成响应变量scores,权重分别为0.3,0.7.
Ⅲ考虑到高分较多,我们人工设置scores大于97.5分的分数为1,小于97.5分的分数为0.(97.5的来历:取加权后的总分的五分位数作为分类变量的分界值)。
构造
以上说明了如何抽取相关特征,我们大致有如下训练样本(只列举部分特征)。
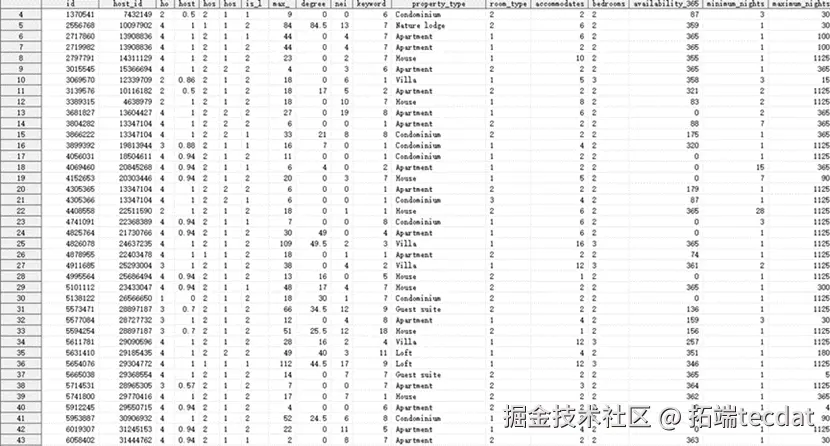
建模
logistic****回归是一种广义线性回归(generalized linear model),适用于因变量y只有两种可能取值的情况,也就是说,因变量的分布是伯努利分布(或二点分布),通常用1和0分别代表因变量的两种可能结果。
决策树是一种广泛应用的分类方法,它能从给出的训练样本中,提炼出树型的分类模型。树中的每个内部节点记录了使用哪个属性来进行分类,每个分支代表一个判断结果的输出,每个叶子节点则代表了最终分类后的结果。在本实验中将评分大于98.5的分数设置为1,将评分小于98.5的分数设置为0,将其作为目标变量score_kind,决策树模型的叶节点将显示目标变量score_kind的类别,根节点到每个叶子节点形成分类的路径规则。
模型优化
1.删除异常值:
在逻辑回归中输出各个残差统计量到res_out数据集,再筛选出Pearson残差绝对值大于2的观测,认为是异常值。共有793个,大约占比百分之二。
运用sql过程步删去这793个异常点,再进行逻辑回归。
2.上线之后的迭代,根据实际的A / B测试和业务人员的建议改进模型
逻辑回归ROC曲线:
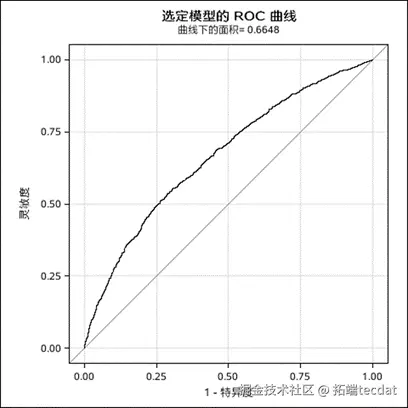

对城区数据通过决策树分类,有76.457%的准确率,对郊区数据通过决策树分类,有85.08%的准确率,说明决策树预测效果更好。
随时关注您喜欢的主题
在上面的分析结果中,我们不难看出,影响短租房评分的因素在北京城区和郊区之间存在着非常的差异。
在郊区,租客更加关注短租房的户型,房型以及房源所在的行政区。八达岭长城,司马台长城,密云水库等景点,尤其是以自然风光为主的景区,大量分布在京郊,密云县、顺义区和延庆县的房子更有可能成为优质房源可以佐证我们的推测,所以选择位于郊区的短租房的租客更多的是旅游导向的,更加关注居住的体验,所以独栋和小众房型,复式和酒店式公寓也都比普通居民楼公寓更加受欢迎。
python岭回归、Lasso、随机森林、XGBoost、Keras神经网络、kmeans聚类链家租房数据地理可视化分析|附数据代码
最近我们被客户要求撰写关于租房数据分析的研究报告。利用 python 爬取链家网公开的租房数据。对租房信息进行分析,主要对房租相关特征进行分析,并搭建模型用于预测房租。
利用上海链家网站租房的公开信息,着重对月租进行数据分析和挖掘。
上海租赁数据
此数据来自 Lianjia.csv文件包含名称,租赁类型,床的数量,价格,经度,纬度,阳台,押金,公寓,描述,旅游,交通,独立浴室,家具,新房源,大小,方向,堤坝,电梯,停车场和便利设施信息。
属性:
名称:列表名称
类型:转租或全部租赁
床: 卧室号码
价格
经度/纬度: 坐标
阳台,押金(是否有押金政策),公寓,描述,旅游可用性,靠近交通,独立浴室,家具
新房源:NO-0,YES-1
面积:平方米
朝向:朝向窗户,南1,东南2,东-3,北4,西南-5,西-6,西北-7,东北8,未知-0
级别: 房源层级, 地下室-0, 低层(1-15)-1, 中层(15-25)-2, 高层(>25)-3
停车场:无停车场-0,额外收费-1,免费停车-2
设施: 设施数量
import pandas as pd
import numpy as np
import geopandas
df = pd.read\_csv('liania\_sh.csv', sep =',', encoding='utf\_8\_sig', header=None)
df.head()可下载资源
视频
Lasso回归、岭回归等正则化回归数学原理及R语言实例
视频
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
视频
Boosting集成学习原理与R语言提升回归树BRT预测短鳍鳗分布生态学实例
视频
LSTM神经网络架构和原理及其在Python中的预测应用
数据预处理
ETL处理,清理数据帧。
df_clean.head()探索性分析 – 数据可视化
plt.figure(figsize=(8, 6))
sns.distplot(df_clean.price, bins=500, kde=True)
plt.xscale('log') # Log transform the price读取地理数据

随时关注您喜欢的主题
plt.figure(figsize=(12, 12))
sns.heatmap(df_clean.corr(), square=True, annot=True, fmt = '.2f', cmap = 'vla模型构建
尝试根据特征预测价格。
y = df\_clean.log\_price
X = df\_clean.iloc\[:, 1:\].drop(\['price', 'log\_price'\], axis=1)岭回归模型
ridge = Ridge()
alphas = \[0.0001, 0.001, 0.001, 0.01, 0.1, 0.5, 1, 2, 3, 5, 10\]Lasso回归
coef.sort_values(ascending=False).plot(kind = 'barh')Random forest随机森林
rf\_cv.fit(X\_train, y_train)XGBoost
xgb_model.loc\[30:,\['test-rmse-mean', 'train-rmse-mean'\]\].plot();xgb\_cv.fit(X\_train, y_train)Keras神经网络
model.add(Dense(1, kernel_initializer='normal'))
# Compile model
model.compile(loss='mean\_squared\_error', optimizer='Adam')
model.summary()kmeans聚类数据
kmeanModel = KMeans(n_clusters=k).fit(X)
kmeanModel.fit(X)
inertias.append(kmeanModel.inertia_)
plt.plot(K, inertias, 'bx-')gpd.plot(figsize=(12,10), alpha=0.3)
scatter\_map = plt.scatter(data=df\_clean, x='lon', y='lat', c='label', alpha=0.3, cmap='tab10', s=2)可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
关于分析师

Nan Hu
在此对 Nan Hu 对本文所作的贡献表示诚挚感谢,她在上海财经大学攻读应用统计专业硕士学位,专注于数据分析和统计建模领域。擅长 SQL、R 语言、Python 和 SAS 。
 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据
LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比 | 附代码数据



