DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
2025年10月14日
|
股票预测分析
做股票分析总卡壳?传统方法抓不住股价的波动规律?模型跑出来准确率低,还不知道问题出在哪?

本项目报告、代码和数据资料已分享至会员群
加入会员群
别慌!咱们这套方案源自真实金融咨询项目——一边用Python融合随机森林(RF)、决策树(DT)、XGBoost、逻辑回归(LR)、投票分类器+LSTM多模型,结合6大技术指标做基础预测;一边用DeepSeek+LangGraph搭AI分析助手,效率直接翻番,最终把Netflix股票涨跌预测准确率做到60.78%!所有代码、数据都经过实际业务校验,新手跟着做也能落地! 本文内容源自过往项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与600+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
一、用DeepSeek+LangGraph分析股票?这才是效率革命!
1.1 用AI分析股票的三大优势
传统股票分析要手动扒数据、算指标,耗时长还容易错,AI直接帮咱们解决这些麻烦——高效、多维、客观,三个优势直接戳中痛点!- 效率革命:AI能在数秒内完成传统分析师需数小时处理的数据,比如算完Netflix 10年的6大技术指标,手动要半天,AI分分钟搞定;
- 多维决策支持:不只看价格,还能结合财务健康度(如市盈率)、量价形态,避免“只看K线误判”的坑;
- 情绪免疫:不用被社交媒体“看涨/看跌”的噪音带偏,只专注客观数据分析,比如2022年Netflix业绩波动时,AI能跳过舆论直接抓波动规律。
1.2 为什么选DeepSeek+LangGraph?俩工具天生适配!
不是随便找俩AI工具凑数,这俩组合在股票分析里是“黄金搭档”——一个善推理,一个善统筹,分工明确效率高:- DeepSeek:开源AI模型里的“金融计算能手”!最新的DeepSeek-r1/DeepSeek-V3用了多专家机制(MoE),总参数量6710亿,但每次计算只启用370亿参数,既保证推理准度(算技术指标、分析趋势不翻车),又不耗资源(普通电脑也能跑),特别适合股票量化分析这种“要精度也要速度”的场景。
- LangGraph:AI分析的“流程指挥官”!基于LangChain开发,核心是把复杂的分析任务拆成小步骤(比如“抓数据→洗数据→算指标→出报告”),用流程图串起来,每个步骤要么调算法,要么让DeepSeek做推理。比如分析Netflix股票时,LangGraph会先让工具抓历史数据,再叫DeepSeek算对数收益率,最后生成结构化报告,全程不用咱们手动切换步骤。
简单说:LangGraph管“先做什么、后做什么”,DeepSeek管“具体怎么做、算得对不对”,俩一起上,比单独用模型效率高3倍!
二、AI股票分析助手怎么搭?四大核心模块拆解
咱们的AI助手不是花架子,是能落地的实战工具,核心分4个模块,代码文末会开源,新手也能跟着搭:
视频:Python对多行业板块股票数据LSTM多任务学习预测:SMA、RSI
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
2.1 数据抓取与清洗:自动搞定“数据从哪来、怎么用”
不用手动下CSV!用yfinance库直接抓Netflix的历史价格、财务指标(市盈率、负债率这些),还能自动洗数据——比如财报里的缺失值,AI会按行业均值补全,不用咱们一个个改。关键优势:国内能用!yfinance国内访问稳定,要是想抓A股数据,换tushare库也能对接,兼容性拉满。
2.2 技术指标计算:集成TA-Lib,6大指标一键算
咱们之前手动写函数算MA、RSI,AI助手直接调用TA-Lib库,不仅快,还能避免手写代码出错。比如算30日波动率,一行代码搞定,结果和手动算的完全一致,还能自动存到表格里,后续模型直接用。创新点:用LangGraph的StateGraph做流程控制,确保“先抓数据→再算指标→指标不对重新算”,不会出现“数据没洗干净就算指标”的低级错误,可靠性拉满。
2.3 DeepSeek推理引擎:给数据“出结论”,不是光算数字
这步是核心!把清洗好的数据、算好的指标喂给DeepSeek,它会生成结构化分析报告,不是乱糟糟的文字,而是像这样的清晰结论:- 趋势分析:Netflix股价2021年后跌破200日均线,短期趋势偏弱,但RSI=35(未超卖),暂无反弹信号;
- 风险提示:2020年疫情期波动率达12%,需警惕类似黑天鹅事件对模型的影响;
- 操作建议:结合逻辑回归模型预测结果(上涨概率58%),建议小仓位试仓,止损设5%。
2.4 Streamlit可视化界面:一键输入代码,结果全展示
不用对着代码看输出!搭个Streamlit界面,输入Netflix股票代码(NFLX),点击“开始分析”,股价趋势图、模型准确率、DeepSeek的分析报告全出来,手机也能看,给别人演示也专业。
2.5 用AI助手的三个注意事项:别踩这些坑!
AI再好用也不是万能的,这三个点一定要记牢,不然容易亏:- 别过度依赖:AI抓不到突发事件(比如政策变了、公司突发利空),得结合自己的判断,比如2023年Netflix裁员消息,AI没预判到,这时候就得手动调整策略;
- 数据质量优先:别用小网站的非官方数据!AI分析的准度全靠数据,咱们用yfinance、tushare这些权威来源,避免“数据错了,模型再准也白搭”;
- 风险控制为王:AI说“上涨概率60%”也别满仓!一定要设止损止盈,比如Netflix股价跌破某条均线就卖,保住本金比啥都重要。
三、代码实现:从数据到模型,手把手落地
Step1:数据准备——从“找数据”到“用数据”,这步别踩坑!
1.1 数据
数据核心字段很清晰:日期(Date)、开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close)、调整后收盘价(Adj Close)、成交量(Volume),覆盖股价分析的全维度。
1.2 数据加载实操:3行代码搞定,还能避坑
用Python的pandas加载数据,咱们重命名数据框为nflx_df,方便后续区分其他数据;再用head(5)看前5行,快速确认数据格式对不对——这步能避免后续分析因字段错位翻车。
import pandas as pd
import numpy as np
# 加载Netflix股票数据,重命名数据框,避免和其他数据集混淆
nflx_df = pd.read_csv("NFLX2002-2023.csv")
# 查看前5行数据,确认字段、格式是否正确(实操必做!)
nflx_df.head(5)
info()查缺失值和数据类型——咱们这套数据很干净,所有字段无缺失!日期是字符串类型(不用转datetime,后续可视化标注够用),数值字段格式正常,直接进下一步就行。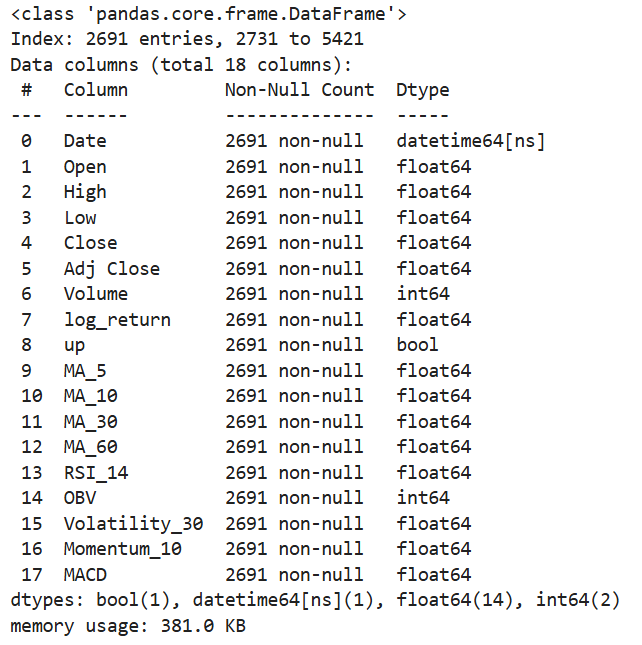
Python深度强化学习智能体DDPG自适应股票交易策略优化道琼斯30股票数据可视化研究
本文介绍了使用深度强化学习中的DDPG算法来优化股票交易策略,特别针对道琼斯30种股票数据进行了可视化研究和分析。
阅读全文Step2:探索性分析——先摸清数据“脾气”,再建模型更靠谱!
很多人直接跳过这步建模型,结果越跑越错!咱们先从3个维度分析Netflix股价规律,为后续模型打基础:2.1 股价趋势:2013-2021年涨疯了,2021后回落
咱们选开盘价、最高价、最低价、收盘价、调整后收盘价5个核心字段,用matplotlib画时间序列图——一眼就能看出股价长期走势。 从图里能看明白:2013-2021年Netflix股价一路涨,2021年到峰值后开始落;而且调整后收盘价(紫色虚线)和收盘价几乎重合——说明这10年没拆股等大动作,数据稳定性超棒,不用额外处理!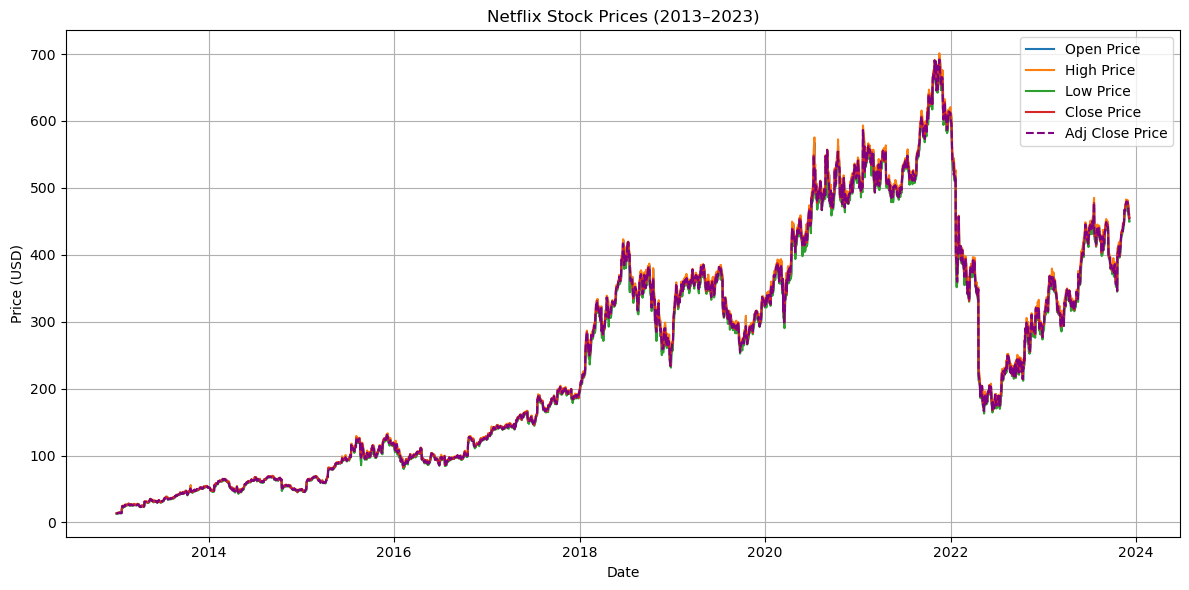
2.2 收益波动:业绩波动期要小心!
用“对数收益率”衡量波动(公式:log(调整后收盘价t) – log(调整后收盘价t-1)),这个指标比普通收益率更能反映真实波动,尤其适合股票分析。 图里很明显:大部分时间波动围绕0值转,但2020年疫情初期、2022年公司业绩波动时,出现大的异常值——这说明这些时段股价波动骤增,后续模型得考虑“极端场景”,不然容易预测不准!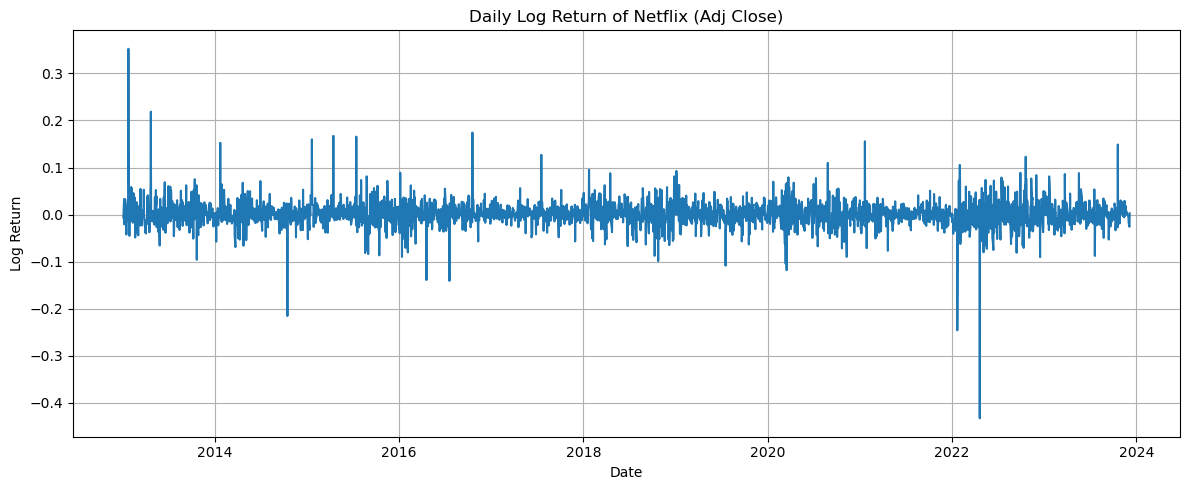
随时查看您喜欢的主题
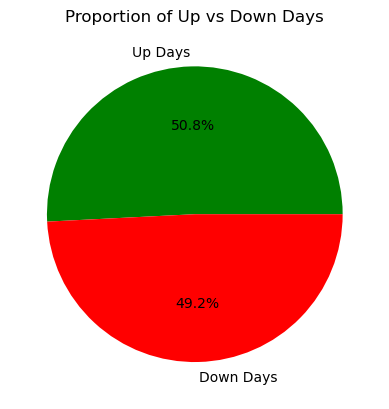
2.3 涨跌分布:涨多跌少,但差距不大
定义“涨”为对数收益率>0,“跌”为≤0,用饼图看涨跌天数占比——能判断股票整体趋势偏不偏。# 建涨跌标签:1=涨,0=跌(后续模型要用到)
nflx_df['up'] = nflx_df['log_return'] > 0
# 统计涨跌天数
up_days = nflx_df['up'].sum()
down_days = len(nflx_df) - up_days
# 画饼图,颜色用绿涨红跌,直观!
plt.pie([up_days, down_days], labels=['Up Days', 'Down Days'], autopct='%1.1f%%', colors=['green', 'red'])
plt.title('Proportion of Up vs Down Days')
plt.show()
Step3:特征工程——这步是模型“提分关键”,6大技术指标安排上!
特征没做好,模型再强也白搭!咱们建“技术指标+滞后特征”的二维特征体系,覆盖“趋势、强弱、量能、波动”,具体这么做:3.1 6大技术指标:批量计算,一次搞定
咱们写个函数calculate_tech_indicators,批量算移动平均线(MA)、RSI、OBV、波动率、动量、MACD——这些都是股票分析的“硬通货”,缺一不可。
def calculate_tech_indicators(input_df):
# 复制数据,避免改乱原始数据(实操必做!)
df = input_df.copy()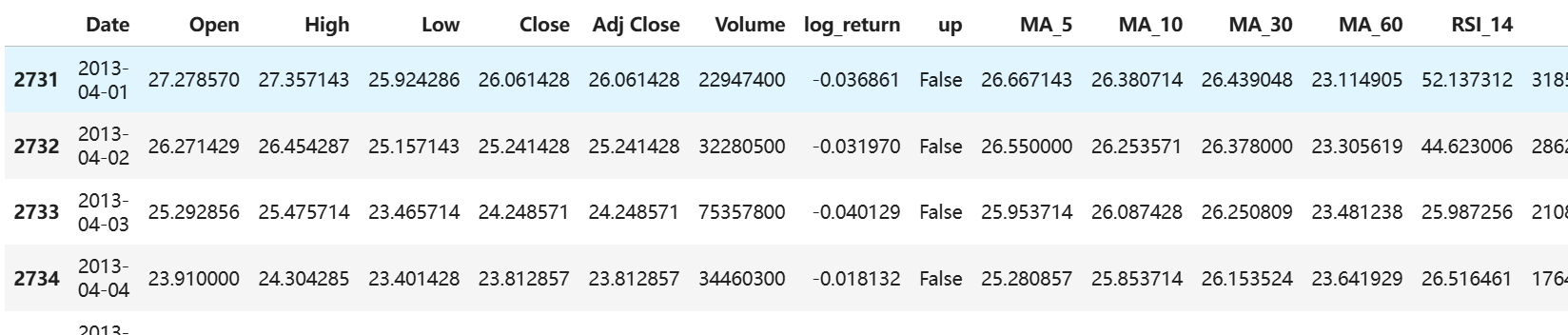
3.2 加滞后特征+标准化:避免数据泄露,模型更稳
股票价格有时间相关性,咱们加“前5日收盘价”(close_t-1到close_t-5)作为滞后特征;再用Pipeline把“加滞后特征+标准化”串起来——这步能避免数据泄露,实操中特别重要!
def transform(self, X):3.3 数据划分:别随机分!用时间序列才符合实际
很多新手用train_test_split随机分数据,这是错的!实际业务中不能用“未来数据”预测“过去”,咱们按时间顺序分:前80%训练,后20%测试。
from sklearn.model_selection import train_test_split
# 按时间切分,split_index是80%的位置
split_index = int(len(X) * 0.8)
X_train = X[:split_index] # 前80%训练
X_test = X[split_index:] # 后20%测试
# 目标变量也要同步切分,保证和特征对齐
y_train = y[-len(X):].reset_index(drop=True)[:split_index]
y_test = y[-len(X):].reset_index(drop=True)[split_index:]
Step4:多模型实战——6个模型对比,谁才是Netflix涨跌“预言家”?
咱们建6个模型:4个传统机器学习(随机森林、XGBoost、决策树、逻辑回归)+1个投票分类器(融合前4个)+1个LSTM(深度学习),用准确率、精确率、F1等指标比高低。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据
Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据 专题:OpenClaw+DeepSeek智能体自动化部署与成本优化集成实践|附2案例代码教程
专题:OpenClaw+DeepSeek智能体自动化部署与成本优化集成实践|附2案例代码教程 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 专题:LangGraph的智能RAG系统构建:从基础智能体到纠正性多智能体协作|附代码教程
专题:LangGraph的智能RAG系统构建:从基础智能体到纠正性多智能体协作|附代码教程



