FF 模型通过回归除市场收益之外的几个变量的投资组合收益来扩展 CAPM。
从一般数据科学的角度来看,FF 将 CAPM 的简单线性回归(我们有一个自变量)扩展到多元线性回归(我们有许多自变量)。
我们要看的是FF三因素模型,它测试的是(1)市场收益(与CAPM相同),(2)公司规模(小与大)和(3)公司价值(账面市值比)的解释能力。
可下载资源
公司价值因素在FF中被标记为HML,代表高-低,指的是公司的账面与市场比率。
1、三因素模型的第一个不足,在于模型试图解释命题本身的哲学性,你做这东西到底是干什么?注意,Fama不是为了寻找CAPM阿尔法,而是要消灭CAPM阿尔法,他认为不应该有阿尔法的存在!为了解释证券收益率,要用更多的因素消除阿尔法。他不想数据挖掘,而是构造有金融学意义的解释,是用两个新增因素去解释其他所有无法用经典CAPM模型解释的截距项。其实什么是阿尔法?其实,阿尔法或许只是来自某种你不了解的贝塔而已,或者说,阿尔法和smart beta基本分不清楚;
2、那什么是公认的系统性风险?不止是三因素模型,包括2015年初fama和french加入CMA,RMW的五因素模型,或者加入更多风险指数的多因素模型,这统称为Macroeconomic factor model,也就是直接用公共风险因素解释证券收益率,把证券收益率分解为风险补偿和风险载荷的累积,这个风险因素本身就是统计模型,这不是金融模型,你当然可以找到更好的风险因素,但是对不起,因为是你,不是FAMA,这然并卵,who cares about it?
3、以BARRA为代表的Fundamental factor model,不直接构造风险指数,而是用每个股票的风险指标建立横截面模型估计风险指数,同样是在解释风险,不是在预测阿尔法;
当我们将投资组合的收益率与HML因子进行回归时,我们正在调查有多少收益是由于包括高账面市值比率的股票(有时被称为价值溢价,因为高账面市值的股票被称为价值股票)。
这篇文章的很大一部分内容涉及从FF网站导入数据,并对其进行整理,以用于我们的投资组合收益。我们将看到,处理数据在概念上很容易理解,但在实际操作中却很耗时。然而,对于任何拥有来自不同供应商的数据流并想创造性地使用它们的行业来说,将不同来源的数据混在一起是一项必要的技能。一旦数据被整理好,拟合模型就不费时间了。
今天,我们将使用我们通常的投资组合,其中包括:
+ SPY(标准普尔500基金)权重25%。 + EFA(一个非美国股票基金),权重25%。 + IJS(一个小盘股价值基金)权重20%。 + EEM (一只新兴市场基金)权重20%。 + AGG(一只债券基金)权重10%。
在计算该投资组合的 beta 之前,我们需要找到投资组合的月收益率。
mbls <- c("SPY","EFA", "IJS", "EEM","AGG")
pes <-
getSymbols
w <- c(0.25, 0.25, 0.20, 0.20, 0.10)
as\_t\_ng <-
res %>%
to.monthly %>%
tk_tbl %>%
gather %>%
group_by%>%
p_tuaeoly <-
ase\_un\_lng %>%
tq_portfolio
我们将处理投资组合收益的一个对象。
Fama French 因子的导入和整理
我们的首要任务是获取 FF 数据,幸运的是,FF 在互联网上提供了他们的因子数据。我们将记录导入和清理这些数据的每个步骤,在某种程度上可能有点过头了。现在让我们感到沮丧,但是当我们需要更新此模型或扩展到 5 因素案例时,可以节省时间。
看看 FF website. 数据被打包为 zip 文件,所以我们需要做的不仅仅是调用 read_csv()。让我们使用tempfile() 基础 R 中的 函数来创建一个名为 temp. 这是我们将放置压缩文件的地方。
temp <- tempfile()
R 创建了一个名为的临时文件 temp 。下载 3-factor zip。 我们想将它传递给 download.file() 并将结果存储在 temp.
首先,我们将把这个字符串分成三块:base、factor和format–这对今天的任务来说不是必须的,但是如果我们想建立一个Shiny应用程序让用户从FF网站上选择一个因子,或者我们只是想用一组不同的FF因子重新运行这个分析,它就会很方便。然后我们会把这些东西粘在一起,并把字符串保存为full_url。
be faor fmt furl <- glue
现在我们传递 full_url 给 download.file().
download.file
最后,我们可以在使用 函数read_csv() 解压缩数据后 读取 csv 文件 unz()。
Go\_3\_Fars <- read_csv head(Go\_3\_Fars )

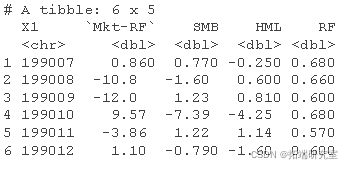
我们已经导入了数据集,但我们没有看到任何因素,只是一个带有奇怪格式日期的列。
发生这种情况时,_通常_ 可以通过跳过一定数量的包含元数据的行来修复它 。看看如果我们跳过 6 行。
Glo_as <- read_csv( skip = 6) head(Glo_as )


这就是我们所期待的,5个列:一个叫做X1的列,保存着奇怪的格式化日期,然后是Mkt-Rf,表示高于无风险利率的市场收益,SMB表示规模因子,HML表示价值因子,RF表示无风险利率。
然而,这些数据已经被转化为字符格式–看看每一列的类别。
map(Gob3s, class)

我们有两个选项可以将这些列强制转换为正确的格式。首先,我们可以在导入时这样做,通过cl_yps = cols 为每个数字列提供参数 。
随时关注您喜欢的主题
Gll3Ftrs <- read_csv(unz head(Gll3Ftrs )
这很好用,但它特定于具有这些特定列名的 FF 3 因子集。如果我们导入不同的 FF 因子集,我们将需要指定不同的列名。
作为一种替代方法,下面的代码块在导入后将列转换为数字,但更通用。它可以应用于其他 FF 因子集合。
为了做到这一点,我们将X1列重命名为date,然后将我们的列格式改为数字。vars()函数的操作与select()函数类似,我们可以通过在date前面加一个负号来告诉它对所有列进行操作,除了date列。
Gloa\_3\_Fars <- read_csv(unz %>% rename%>% mutate_at head(Gloa\_3\_Fars )

现在我们的因子有了数字数据,日期列有更好的标签,但格式错误。
我们可以使用该 lubridate 包将该日期字符串解析为更好的日期格式。我们将使用该 parse_date_time() 函数,并调用该 ymd() 函数以确保最终结果为日期格式。同样,在处理来自新来源的数据时,日期,事实上,任何列都可以有多种格式。
Gll\_3\_ts <- read_csv %>% rename %>% mutate_at%>% mutate head(Gll\_3\_ts )

日期格式看起来不错,这很重要,因为我们想要修剪 FF 日期与我们的投资组合日期匹配的因子数据。但是,请注意 FF 使用当月的第一天,而我们的投资组合收益使用的是当月的最后一天。这会将每月日期回滚到上个月的最后一天。我们 FF 数据中的第一个日期是“1990-07-01”。让我们回滚。
如果我们想将日期重置为月末,我们需要先添加一个,然后回滚。
Gol3Frs %>% select %>% mutate %>% head

Gob3Fars %>% select%>% mutate %>% head

我们还有其他方法可以解决这个问题–一开始,我们就可以将我们的投资组合收益率索引到indexAt = firstof。
最后,我们只想要与我们的投资组合数据一致的 FF 因子数据,因此我们 在投资组合返回对象中 按 日期first() 和 last()日期filter()。
Glb3Ftos <- read_csv(unz %>% rename%>% mutate_at %>% mutate) + months) %>% filte head(Glb3Ftos , 3)

tail(Glaos, 3)

我们用left\_join(…by = “date”)将这些数据对象合并起来。还将FF数据转换为十进制,并创建了一个名为R\_excess的新列,保存高于无风险利率的收益。
ff\_proio\_tns <- piruq\_ealaed\_ntly %>% left_join %>% mutate head(ff_poleus, 4)

我们现在有了一个包含我们的投资组合收益和 FF 因子的对象,并且可以从编码的角度进行我们练习中最简单的部分,也是我们的老板/同事/客户/投资者唯一关心的部分:建模和可视化.
现在我们有了格式不错的数据。CAPM 使用简单的线性回归,而 FF 使用具有许多自变量的多元回归。因此,我们的 3 因子 FF 方程为 lm(R_excess ~ MKT_RF + SMB + HML。
我们将在 CAPM 代码流中添加一项,即为我们的系数包括 95% 的置信区间。
ffdlrhd <- ffptoltus %>% do) %>% tidy(conf.level = .95) fdlyd %>% mutate_if %>% select

我们的模型对象现在包含一个 conf.high 和 conf.low 列来保存我们的置信区间最小值和最大值。
我们可以将这些结果通过管道传输到 ggplot() 并创建具有置信区间的系数散点图。我不想绘制截距,因此会将其从代码流中过滤掉。
我们用errorbar添加置信区间。
fdpynd %>% mutate_if%>% filter %>% ggplot+ geom_point + geom_errorbar + labs + theme_minimal + theme
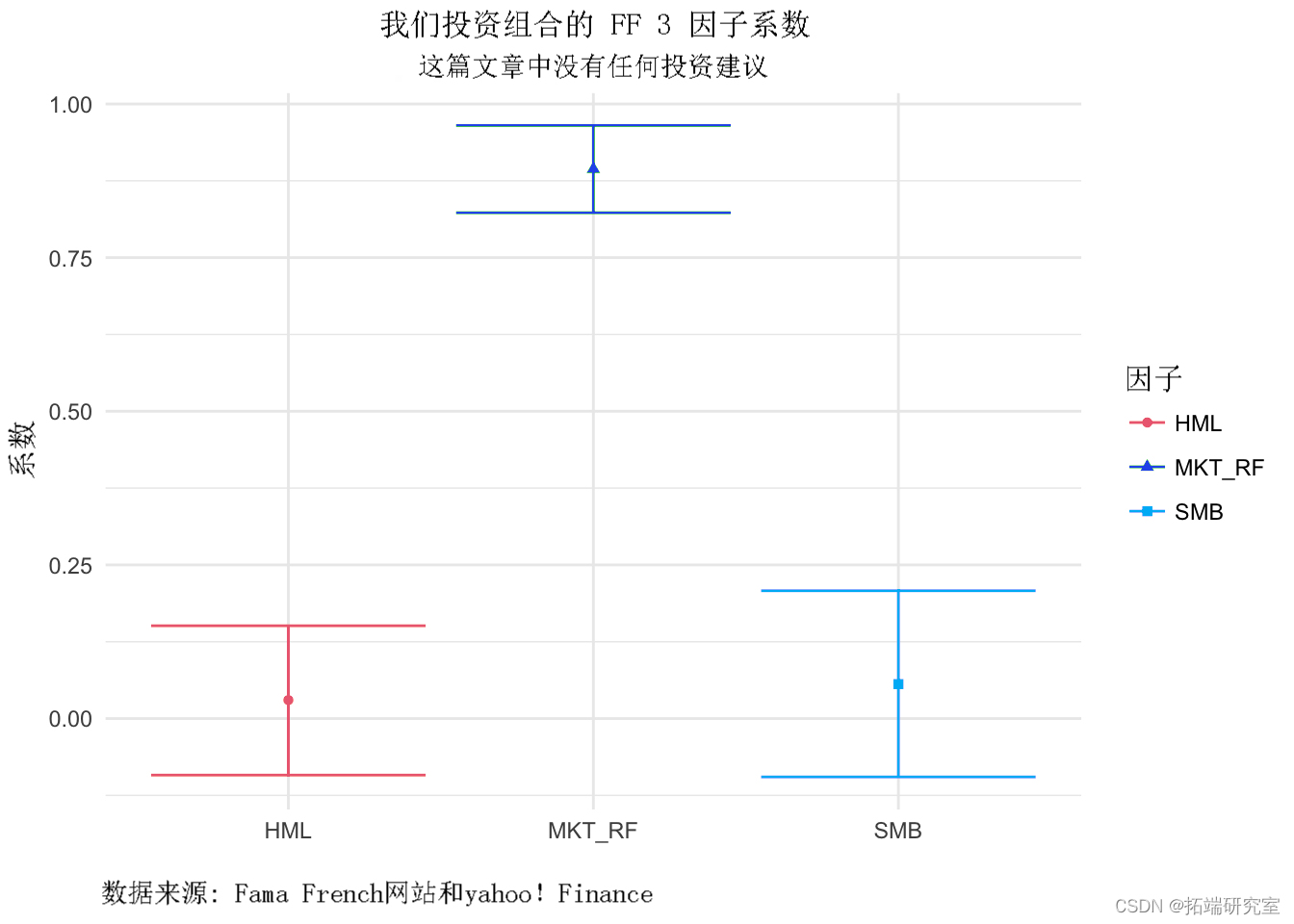
这里的结果是可以预测的,因为与 CAPM 一样,我们正在回归一个包含 3 个因素的市场的投资组合,其中一个是市场。因此,市场因素在该模型中占主导地位,而其他两个因素的置信区间为零。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据
OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据 llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程
llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python、SPSS单指数、FF三因子模型、决策树分析沪深300指数、申万风格指数、10年期国债收益率、300ETF期权波动率指数数据优化金融期货市场预测|附代码数据
Python、SPSS单指数、FF三因子模型、决策树分析沪深300指数、申万风格指数、10年期国债收益率、300ETF期权波动率指数数据优化金融期货市场预测|附代码数据



