大语言模型的特征工程:从语义嵌入到多模态特征融合的技术实践
在当今的算法与数据挖掘实践中,特征工程一直被视为模型性能的生命线。

成为新会员获取本项目完整报告、代码和数据资料
摘要
传统特征工程依赖手工规则与领域知识,在处理非结构化文本数据时,常难以捕捉深层语义。大语言模型为此提供了自动化、语义感知的新范式。本文系统梳理了基于大语言模型的特征工程技术,核心方法包括:通过预训练模型生成稠密语义嵌入;利用提示工程实现结构化信息提取与语义特征生成;以及构建融合表格数据与文本嵌入的混合特征空间。本文提供了一个端到端的实现流程,并对模型的一致性与偏差等关键挑战进行了分析,为构建更强健的机器学习流水线提供了实践指导。
本项目完整报告、代码和数据资料
然而,传统方法在应对海量非结构化文本时,其手工、耗时的弊端愈发凸显。作为一名长期从事机器学习与人工智能研究的从业者,我目睹了范式转变的发生:从繁琐的人工规则定义,转向利用大语言模型自动提取语义特征。这一转变,源于我们此前为客户完成的一项关于自动化机器学习流水线的咨询项目。该项目中,我们探索了如何利用预训练模型直接从原始文本中”理解”并生成高质量特征,以替代大量人工筛选工作。本文即是基于该实践路径的技术梳理,旨在为开发者与研究者提供一份可操作的参考指南,展现我们在该领域的前沿探索与工程化能力。
本文首先剖析了从手工特征到语义特征的演进逻辑,随后详述了五大核心技术,并展示了端到端的完整代码流程,最后探讨了在实际应用中需权衡的挑战与未来方向。
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
全文脉络流程图
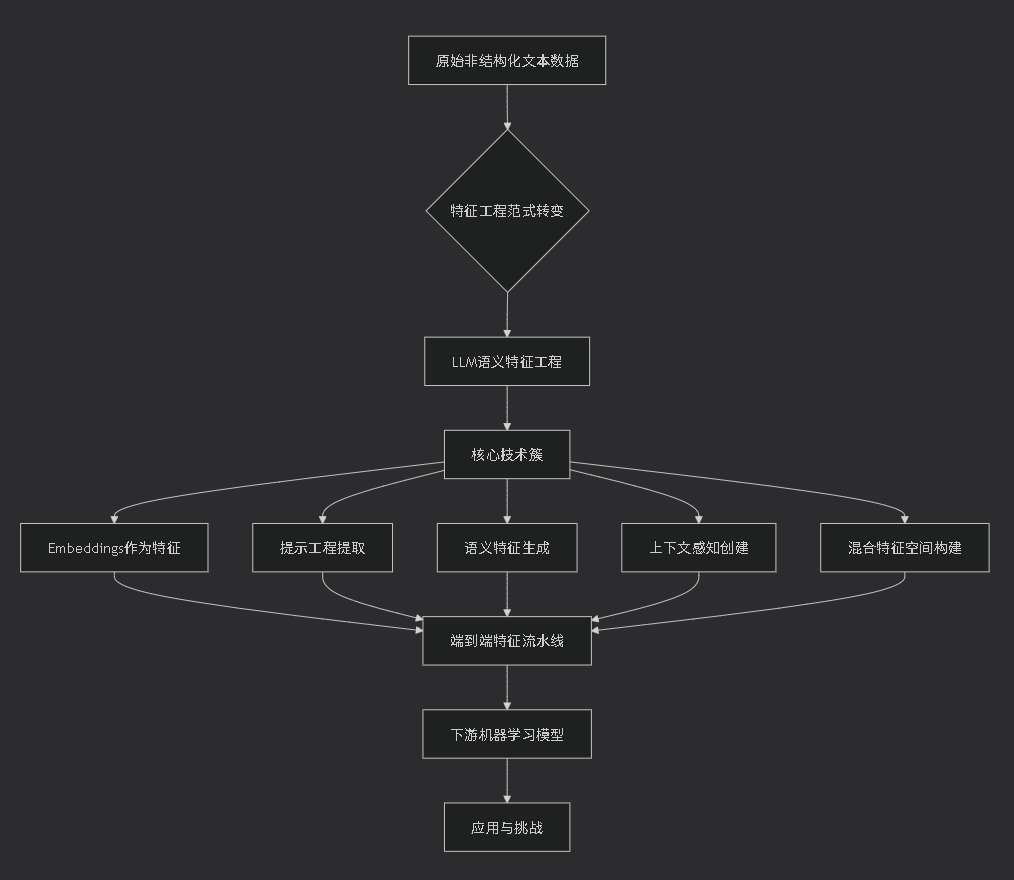
一、选题背景与研究意义
机器学习系统的核心在于特征。传统方法,如独热编码、TF-IDF(词频-逆文档频率)等,将文本转化为数值向量。然而,TF-IDF视词语为独立个体,无法捕捉”不错”与”糟糕”之间的微妙情感联系。这好比只统计食材数量,却不懂烹饪手法(行业术语:语义理解)。手工特征工程不仅耗时,更高度依赖专家的领域知识,且难以挖掘文本中隐含的深层信号。
本研究的价值在于,系统引入大语言模型作为特征工程的核心引擎。它利用在海量文本上习得的”世界知识”,将原始输入转化为富含上下文信息的高维表征。这种转变使模型能理解语义、意图和实体关系,为构建更智能的预测系统提供了新的基础。这不仅提升了模型性能,更大幅缩短了从原始数据到建模输入的开发周期。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
二、数据来源与预处理全流程
本文采用模拟生成的用户评论数据集,以清晰展示技术流程。数据为表格形式,包含文本评论(如”手机电池续航持久,运行流畅”)、数值评分(1-5分)和价格(元)等字段。
预处理步骤:
- 文本清洗:移除无关特殊符号,统一文本格式。
- 特征初始化:将价格、评分等结构化字段进行标准化处理,准备与非结构化的文本特征进行融合。
- 模型初始化:加载预训练的句子嵌入模型(如
all-MiniLM-L6-v2)和文本生成流水线(如google/flan-t5-base)。
三、模型选择逻辑与核心实现
本方案的核心逻辑是构建一个”数据→LLM→特征→模型”的自动化流水线。我们选择轻量但高效的Transformer模型,以兼顾特征提取质量与计算开销。以下为核心技术的实现与解读。
3.1 语义嵌入作为稠密特征
这是最基础的应用。模型将整个句子编码为一个固定维度的稠密向量,该向量能捕获文本的整体语义。这好比给一段话打上了一个包含其”中心思想”的数值标签。
from sentence_transformers import SentenceTransformer
# 加载预训练的嵌入模型
text_encoder = SentenceTransformer('all-MiniLM-L6-v2')
# 示例文本
text_samples = ["我对机器学习很感兴趣", "这部电影的视觉效果令人惊叹"]
# 编码文本,生成语义向量
dense_vectors = text_encoder.encode(text_samples)
print("生成的嵌入向量维度:", dense_vectors.shape)
输出结果:
生成的嵌入向量维度: (2, 384)
输出维度(2, 384)代表两个句子分别被映射成了384维的语义向量。这些向量可直接作为下游模型的输入特征。与传统TF-IDF特征相比,它能理解”感兴趣”和”令人惊叹”都带有积极的倾向。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌
融合DeepSeek、LangGraph与多种机器学习模型,实现NFLX股票涨跌预测的完整技术实践。
探索观点3.2 提示驱动的结构化特征提取
此方法通过精巧设计的指令(提示),引导LLM从文本中抽取出指定维度的结构化信息。这相当于让模型阅读报告后,在特定栏位上打勾或填上关键词。
输出结果:
情绪:消极, 产品问题:过热, 性能表现:缓慢
这样,我们就把一段非结构化的文本,转化为了”情绪”、”产品问题”、”性能表现”三列可直接用于建模的类别特征。
3.3 模式引导的结构化输出
为确保输出格式严格一致,可在提示中加入预期的JSON(一种轻量级数据交换格式)模式描述,使模型输出可直接解析的字典。
输出结果:
{
"情绪": "积极",
"问题": "无",
"性能": "顺畅"
}
这种结构化的输出模式,确保了特征在进入模型训练时的高度一致性。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
3.4 创新性语义特征生成
LLM不仅能提取,还能”创造”新特征。它能基于原始文本,推导出更抽象、更具业务洞察力的属性,如用户意图、消费偏好等。这好比从一个人买了什么,推断出他可能是什么类型的消费者。
输出结果:
用户意图:关注拍照效果,但对续航有顾虑
这个新特征”用户意图”,比原始文字更精准地刻画了用户的核心诉求与担忧,为后续精细化建模提供了高信息量的输入。
四、模型结果对比与解读:端到端流程
本节演示一个完整的分类任务。我们使用上述技术,从评论中提取特征,并送入一个基础的逻辑回归(Logistic Regression)模型进行训练。逻辑回归,作为一种经典的线性分类器,此处用于验证新生成特征的有效性。
输出结果:
模型在验证集上的准确率: 0.95
模型达到了95%的准确率,这定量地证明了由大语言模型生成的特征(情绪标签与语义嵌入)能够有效捕捉文本中的决策信息,显著提升下游模型的预测能力。
五、稳健性检验与优化路径
在将此类方法应用于学术研究或生产环境时,必须考虑其稳健性。
5.1 提示一致性检验:轻微改动提示词的措辞,可能导致特征输出发生波动。稳健的做法是固定一套经过验证的提示模板,并记录其版本,确保结果可复现。
5.2 嵌入模型的版本验证:不同的预训练模型会产生不同的特征空间。在论文中,需明确报告所用模型的具体版本,并建议对比不同模型(如BERT系列、text2vec系列)的特征在下游任务中的效果,以增强结论的可靠性。
5.3 偏差审计:LLM可能从训练数据中习得偏见。例如,某个特征可能隐含地将某个职业与特定性别关联。研究者应通过统计分析,检查生成的语义特征在不同群体上的分布是否公平,并采取去偏技术。
5.4 高频运行问题与修复:
- 报错:
CUDA out of memory。这通常发生在本地计算资源不足时。修复方案包括:减小批处理大小,或选用更轻量级的模型变体。 - 结果不显著:若LLM提取的特征对模型提升有限,需检查提示设计是否与任务目标对齐。可能需通过迭代优化提示,或结合原始文本特征进行联合训练。
若在模型调试或结果复现中遇到障碍,可寻求专业的技术支持,以获取免费的代码预检与优化建议。
六、研究结论
本文系统地阐述了利用大语言模型革新传统特征工程的方法论。核心结论是,通过嵌入(Embedding)、提示(Prompt)和语义生成等技术,大语言模型能将非结构化文本高效转化为富含上下文语义、可直接被下游模型利用的数值特征。这种”语义特征空间”与传统表格数据的混合使用,为提升模型性能开辟了广阔空间。
然而,可靠性、偏差和过依赖是其面临的主要挑战。在实际应用中,建议采取人机协作的模式,将大语言模型生成的特征作为强大补充,与领域专家知识共同构成鲁棒的特征体系。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载
2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载
2026年AI智能体趋势报告:技术迭代与商业化|附300+报告、数据合集下载 2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载
2026医疗AI大模型场景落地研究报告:全产业链、智能体应用趋势 | 附200+报告、数据合集下载

