模型表现差异很大的可能原因是什么?换句话说,为什么在别人评估我们的模型时会失去稳定性?
在本文中,我们将探讨可能的原因。我们还将研究交叉验证的概念以及执行它的一些常用方法。
目录
- 为什么模型会失去稳定性?
- 什么是交叉验证?
- 交叉验证的几种常用方法
- 验证集方法
- 留一法交叉验证(LOOCV)
- k折交叉验证
- 分层k折交叉验证
- 对抗验证
- 时间序列的交叉验证
- 自定义交叉验证技术
- 如何测量模型的偏差方差?
可下载资源
为什么模型会失去稳定性?
让我们使用下面的快照来说明各种模型的拟合情况,以了解这一点:
对抗验证(Adversarial Validation),并不是一种评估模型效果的方法,而是一种用来确认训练集和测试集的分布是否变化的方法。
它的本质是构造一个分类模型,来预测样本是训练集或测试集的概率。
如果这个模型的效果不错(通常来说AUC在0.7以上),那么可以说明我们的训练集和测试集存在较大的差异。
仍然以「预测人们在超市的消费习惯」为例。因为训练集主要是18岁-25岁的年轻人,测试集主要是70岁以上的老人,那么通过「年龄」,我们就能够很好的区分出训练集和测试集。
具体步骤:
-
定义y:样本是train还是test。
-
将 Train 和 Test 合成一个数据集
-
构造一个模型,拟合新定义的y
-
观察模型效果:如果模型的AUC超过0.7,说明了 Train 和 Test 的分布存在较大的差异

在这里,我们试图找到数量和价格之间的关系。为此,我们采取了以下步骤:
- 我们使用线性方程式建立了关系,并为其显示曲线图。从训练数据点来看,第一幅图有很高的误差。在这种情况下,我们的模型无法捕获数据的潜在趋势
- 在第二个图中,我们刚刚发现了价格和数量之间的正确关系,即较低的训练误差
- 在第三个图中,我们发现训练误差几乎为零的关系。这是因为通过考虑数据点中的每个偏差(包括噪声)来建立关系,即模型过于敏感并且捕获仅在当前数据集中存在的随机模式。这是“过度拟合”的一个例子。

数据科学竞赛的一种常见做法是迭代各种模型以找到性能更好的模型。为了找到正确的答案,我们使用验证技术。
什么是交叉验证?
在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方和。
以下是交叉验证中涉及的步骤:
- 保留 样本数据集
- 使用数据集的其余部分训练模型
- 使用测试(验证)集的备用样本。帮助您评估模型性能的有效性。
交叉验证的几种常用方法
有多种方法可用于执行交叉验证。我已经在本节中讨论了其中一些。
验证集方法
在这种方法中,我们将数据集的50%保留用于验证,其余50%用于模型训练。但是,这种方法的主要缺点是,由于我们仅在50%的数据集上训练模型,因此很可能会错过一些有关数据的信息,导致更高的偏差。
Python代码:
train, validation = train_test_split(data, test_size=0.50, random_state = 5)R代码:
set.seed(101) # 设置种子,以便将来可以复制相同的样本
#现在从数据的总共“ n”行中选择50%的数据作为样本
sample <- sample.int(n = nrow(data), size = floor(.50*nrow(data)), replace = F)留一法交叉验证(LOOCV)
在这种方法中,我们仅从可用数据集中保留一个数据点,并在其余数据上训练模型。该过程针对每个数据点进行迭代。这有其优点和缺点。让我们看看它们:
- 我们利用所有数据点,因此偏差会很低
- 我们将交叉验证过程重复n次(其中n是数据点数),这会导致执行时间更长
- 由于我们针对一个数据点进行测试,因此这种方法导致测试模型有效性的较大差异。因此,我们的估计会受到数据点的影响。如果数据点是异常值,则可能导致更大的变化
R代码:
for(i in 1:nrow(x)){
training = x[-i,]
model = #... 训练模型
score[[i]] = rmse(pred, validation[[label]]) # 得分/误差
return(unlist(score)) # 返回一个向量LOOCV指出了一个数据点。同样,您可以忽略p个训练示例,以使每次迭代的验证集大小为p。这称为LPOCV(留出P交叉验证)

k折交叉验证
通过以上两种验证方法,我们了解到:
- 我们应该在很大一部分数据集上训练模型。否则,我们将无法读取和识别数据中的潜在趋势。最终将导致更高的偏差
- 我们还需要一个良好比例的测试数据点。如上所述,测试模型的有效性时,较少的数据点数量会导致误差
- 我们应该多次重复训练和测试过程。应该更改训练并测试数据集分布。这有助于正确验证模型有效性
我们是否有一种方法可以满足所有这三个要求?
随时关注您喜欢的主题
该方法称为“ k倍交叉验证”。以下是它的步骤:
- 随机将整个数据集拆分为k个“部分”
- 对于数据集中的每k折部分,在数据的k – 1折上建立模型。然后,测试模型以检查k 折的有效性
- 记录每个预测上看到的误差
- 重复此过程,直到每个k折都用作测试集
- 您记录的k个误差的平均值称为交叉验证误差,它将用作模型的性能指标
以下是k = 10时k倍验证的可视化。
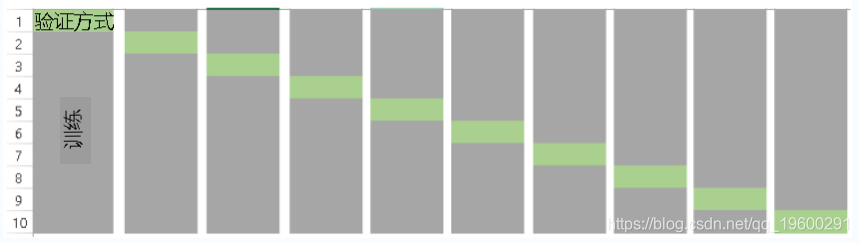
现在,最常见的问题之一是:“如何选择正确的k值?”。
k的 值越低, 偏差越大。另一方面,较高的K值偏差较小,但可能会出现较大的可变性。准确地说,LOOCV等效于n倍交叉验证,其中n是训练的数量。
Python代码:
kf = RepeatedKFold(n_splits=5, n_repeats=10, random_state=None) R代码:
# 定义训练集进行k折交叉验证
trainControl(method="cv", number=10)
# 拟合朴素贝叶斯模型
train(Species~., data=iris, trControl=train_control, method="nb")
# 总结结果4.分层k折交叉验证
分层是重新排列数据的过程,以确保每个折都能很好地代表整体。例如,在二进制分类问题中,每个类别包含50%的数据,最好安排数据,在每一折中每个类别包含大约一半的实例。
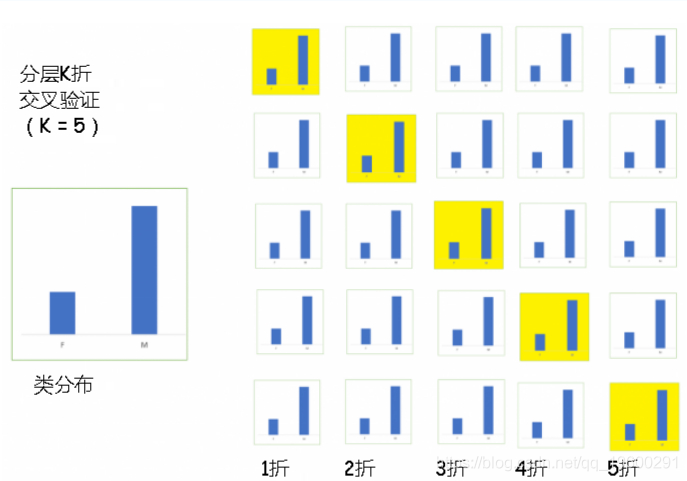
话虽如此,如果训练集不能充分代表整个数据,那么使用分层k折可能不是最好的方法。在这种情况下,应使用带有重复的简单 k倍交叉验证。
当同时处理偏差和方差时,这通常是更好的方法。
用于分层k折交叉验证的Python代码段:
# X是特征集,y是因变量
for train_index, test_index in skf.split(X,y):
print("Train:", train_index, "Validation:", val_index)
R代码:
#折是根据因变量创建的
folds <- createFolds(factor(data$target), k = 10, list = FALSE)在重复的交叉验证中,交叉验证过程将重复 n 次,从而产生 原始样本的n个随机分区。将 n个 结果再次平均(或以其他方式组合)以产生单个估计。
用于重复k折交叉验证的Python代码:
# X是特征集,y是因变量
print("Train:", train_index, "Validation:", val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]5.对抗性验证
在处理真实数据集时,通常会遇到测试集和训练集非常不同的情况。结果,内部交叉验证技术可能给出的分数甚至不及测试分数。在这种情况下,对抗性验证提供了一种解决方案。
总体思路是根据特征分布检查训练和测试之间的相似程度。如果情况并非如此,我们可以怀疑它们是完全不同的。可以通过组合训练和测试集,分配0/1标签(0-训练,1-test)并评估二进制分类任务来量化这种判断。
让我们了解一下,如何通过以下步骤完成此操作:
- 从训练集中删除因变量
train.drop(['target'], axis = 1, inplace = True)- 创建一个新的因变量,该变量对于训练集中的每一行是1,对于测试集中的每一行是0
train['is_train'] = 1
test['is_train'] = 0- 结合训练和测试数据集
pd.concat([train, test], axis = 0)- 使用上面新创建的因变量,拟合分类模型并预测要进入测试集中的每一行的概率
# Xgboost 参数
clf = xgb.XGBClassifier(**xgb_params, seed = 10)- 使用步骤4中计算出的概率对训练集进行排序,并选择前n%个样本/行作为验证组(n%是要保留在验证组中的训练集的分数)
new_df = new_df.sort_values(by = 'probs', ascending=False) # 30% 验证集val_set_ids 将从训练集中获取ID,这些ID将构成最类似于测试集的验证集。对于训练和测试集非常不同的情况,这可以使验证策略更可靠。
但是,使用这种类型的验证技术时必须小心。一旦测试集的分布发生变化,验证集可能就不再是评估模型的良好子集。
6.时间序列的交叉验证
随机分割时间序列数据集不起作用,因为数据的时间部分将被弄乱。对于时间序列预测问题,我们以以下方式执行交叉验证。
- 时间序列交叉验证的折叠以正向连接方式创建
- 假设我们有一个时间序列,用于在n 年内消费者对产品的年度需求 。验证被创建为:
fold 1: training [1], test [2]
fold 2: training [1 2], test [3]
fold 3: training [1 2 3], test [4]
fold 4: training [1 2 3 4], test [5]
fold 5: training [1 2 3 4 5], test [6]
.
.
.
fold n: training [1 2 3 ….. n-1], test [n]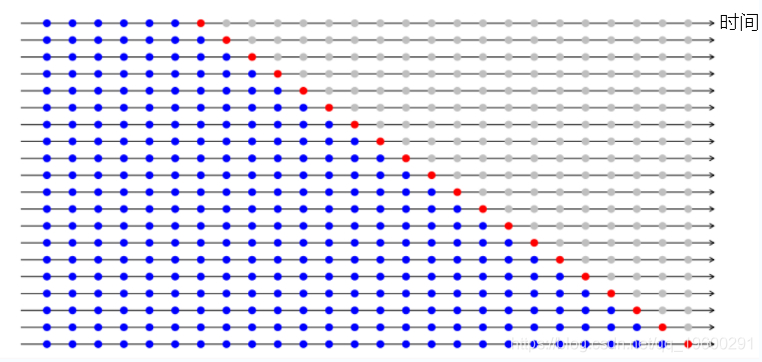
我们逐步选择新的训练和测试集。我们从一个训练集开始,该训练集具有最小拟合模型所需的观测值。逐步地,我们每次折叠都会更改训练和测试集。在大多数情况下,第一步预测可能并不十分重要。在这种情况下,可以将预测原点移动来使用多步误差。例如,在回归问题中,以下代码可用于执行交叉验证。
Python代码:
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
TRAIN: [0] TEST: [1]
TRAIN: [0 1] TEST: [2]
TRAIN: [0 1 2] TEST: [3]R代码:
tsCV(ts, Arima(x, order=c(2,0,0), h=1) # arima模型交叉验证
sqrt(mean(e^2, na.rm=TRUE)) # RMSEh = 1表示我们仅对提前1步的预测采用误差。
(h = 4)下图描述了4步提前误差。如果要评估模型来进行多步预测,可以使用此方法。
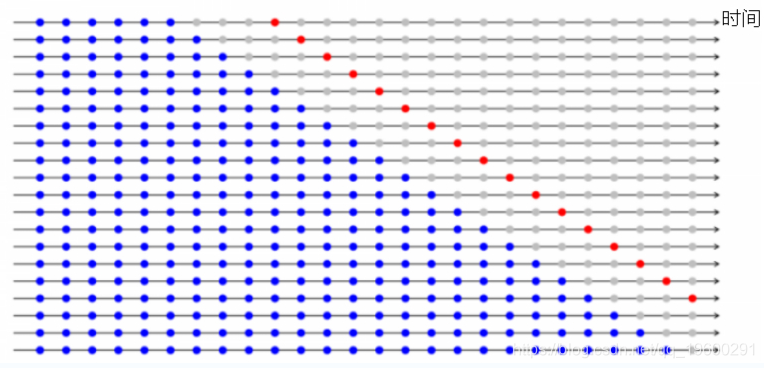
7.自定义交叉验证技术
如果没有一种方法可以最有效地解决各种问题。则可以创建基于函数或函数组合的自定义交叉验证技术。
如何测量模型的偏差方差?
经过k倍交叉验证后,我们将获得 k个 不同的模型估计误差(e1,e2…..ek)。在理想情况下,这些误差值应总计为零。为了得到模型的偏差,我们获取所有误差的平均值。降低平均值,使模型更好。
同样,为了计算模型方差,我们将所有误差作为标准差。标准偏差值低表明我们的模型在不同的训练数据子集下变化不大。
我们应该集中精力在偏差和方差之间取得平衡。可以通过减小方差并在一定程度上控制偏差来实现。这将获得更好的预测模型。这种权衡通常也会导致建立不太复杂的预测模型。
尾注
在本文中,我们讨论了过度拟合和诸如交叉验证之类的方法,来避免过度拟合。我们还研究了不同的交叉验证方法,例如验证集方法,LOOCV,k折交叉验证,分层k折等,然后介绍了每种方法在Python中的实现以及在Iris数据集上执行的R实现。
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

