T-distributed Stochastic Neighbor Embedding (T-SNE) 是一种可视化高维数据的工具。
T-SNE 基于随机邻域嵌入,是一种非线性降维技术,用于在二维或三维空间中可视化数据。
Python API 提供 T-SNE 方法可视化数据。在本教程中,我们将简要了解如何在 Python 中使用 TSNE 拟合和可视化数据。教程涵盖:
- 鸢尾花数据集TSNE拟合与可视化
- MNIST 数据集 TSNE 拟合和可视化
可下载资源
我们将从加载所需的库和函数开始。
import seaborn as sns import pandas as pd
1、TSNE的基本概念
2、例1 鸢尾花数据集降维
3、例2 MINISET数据集降维
1、TSNE的基本概念
t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,是由 Laurens van der Maaten 等在08年提出来。此外,t-SNE 是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,进行可视化。该算法可以将对于较大相似度的点,t分布在低维空间中的距离需要稍小一点;而对于低相似度的点,t分布在低维空间中的距离需要更远。
t-SNE的梯度更新有两大优势:
-
对于不相似的点,用一个较小的距离会产生较大的梯度来让这些点排斥开来。
-
这种排斥又不会无限大(梯度中分母),避免不相似的点距离太远。
主要不足有四个:
-
主要用于可视化,很难用于其他目的。比如测试集合降维,因为他没有显式的预估部分,不能在测试集合直接降维;比如降维到10维,因为t分布偏重长尾,1个自由度的t分布很难保存好局部特征,可能需要设置成更高的自由度。
-
t-SNE倾向于保存局部特征,对于本征维数(intrinsic dimensionality)本身就很高的数据集,是不可能完整的映射到2-3维的空间
-
t-SNE没有唯一最优解,且没有预估部分。如果想要做预估,可以考虑降维之后,再构建一个回归方程之类的模型去做。但是要注意,t-sne中距离本身是没有意义,都是概率分布问题。
-
训练太慢。有很多基于树的算法在t-sne上做一些改进
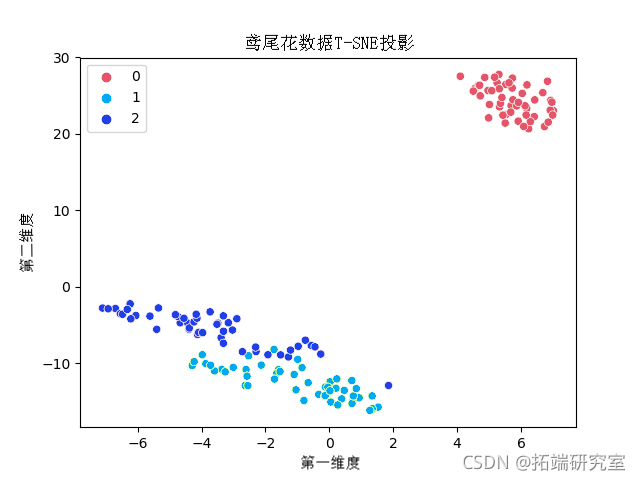
鸢尾花数据集TSNE拟合与可视化
加载 Iris 数据集后,我们将获取数据集的数据和标签部分。
x = iris.data y = iris.target
然后,我们将使用 TSNE 类定义模型,这里的 n_components 参数定义了目标维度的数量。’verbose=1′ 显示日志数据,因此我们可以检查它。
TSNE( verbose=1)
接下来,我们将在图中可视化结果。我们将在数据框中收集输出组件数据,然后使用“seaborn”库的 scatterplot() 绘制数据。在散点图的调色板中,我们设置 3,因为标签数据中有 3 种类型的类别。
df = p.Dtame()
df\["\] = y
df\["cm"\] =z\[:,0\]
df\[cop"\] = z\[,\]
plot(hue=dfytlst()
patte=ns.cor_ptt("hls", 3),
dat=df)
MNIST 数据集 TSNE 拟合和可视化
接下来,我们将把同样的方法应用于更大的数据集。MNIST手写数字数据集非常合适,我们可以使用Keras API的MNIST数据。我们只提取数据集的训练部分,因为这里用TSNE来测试数据就足够了。TSNE需要太多的时间来处理,因此,我将只使用3000行。
x_train= xtrin\[:3000\] y_rin = ytrin\[:3000\] print(x_train.shape)
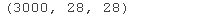
MNIST 是一个三维数据,我们将其变形为二维数据。
print(xtishpe) x\_nit = rshap(\_rin, \[xran.shap\[0\],xtrn.shap\[1\]*xrin.shap\[2\]) print(x_mit.shape)
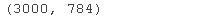
在这里,我们有 784 个特征数据。现在,我们将使用 TSNE 将其投影到二维中,并在图中将其可视化。
z = tsne.fit(x_mnist) df\["comp1"\] = z\[:,0\] df\["comp2"\] = z\[:,1\] plot(huedf.tit(), ata=f)
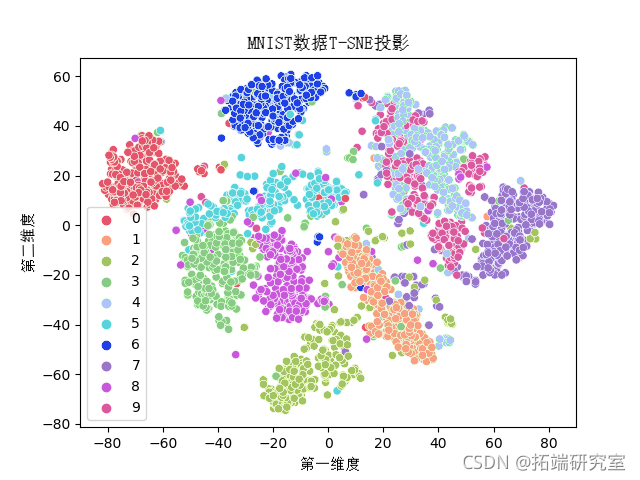

该图显示了 MNIST 数据的二维可视化。颜色定义了目标数字及其在 2D 空间中的特征数据位置。
随时关注您喜欢的主题
在本教程中,我们简要地学习了如何在 Python 中使用 TSNE 拟合和可视化数据。
参考:
1、https://blog.csdn.net/u01216261
2、 Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research.
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究
Python对2028奥运奖牌预测分析:贝叶斯推断、梯度提升机GBM、时间序列、随机森林、二元分类教练效应量化研究 Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化
Python酒店预订数据:随机森林与逻辑回归模型ROC曲线可视化 视频讲解|Python图神经网络GNN原理与应用探索交通数据预测
视频讲解|Python图神经网络GNN原理与应用探索交通数据预测 专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察
专题|LSTM-XGBoost,ARMA-LSTM,LDA-LSTM黄金比特币价格混合预测,蔬菜包发放时空协同调配,知乎综艺评论情感时序洞察


