在数据科学和机器学习领域,回归分析是一种强大的工具,用于探索变量之间的关系并预测未来的结果。
其中,套索回归(Lasso Regression)是一种线性回归方法,特别适用于解决高维数据和过拟合问题。它通过引入正则化项来限制模型复杂度,从而在保持模型预测能力的同时,降低模型的方差。
本文3个实例合集旨在通过实例帮助客户展示Python中套索回归的应用,特别是针对棒球运动员薪水数据的预测。
我们将通过详细的代码和数据集,展示如何使用套索回归来分析和预测棒球运动员的薪水。
此外,我们还将引入其他两种相关的回归技术——SCAD(Smoothly Clipped Absolute Deviation)和LARS(Least Angle Regression),以便读者能够更全面地了解线性回归模型的不同变体。
SCAD是一种具有平滑绝对偏差惩罚项的回归方法,它在处理高维数据时能够提供更好的模型解释性和预测性能。而LARS则是一种基于最小角回归的算法,它在选择特征时能够考虑特征之间的相关性,从而避免选择高度相关的特征。
1.Python套索回归lasso分析棒球运动员薪水
数据
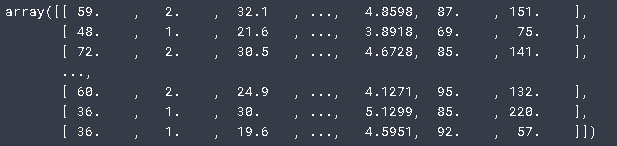
该数据集包含20个变量和322个观察值,涉及大联盟球员的数据。我们希望基于球员上一年度的各种统计数据来预测棒球运动员的薪水。
导入
缺失值
请注意,有些球员的薪水数据是缺失的:

视频
Lasso回归、岭回归等正则化回归数学原理及R语言实例
视频
R语言机器学习高维数据应用:Lasso回归和交叉验证预测房屋市场租金价格
dummies = pd.get_dummies(df[['League', 'Division','NewLeague']])
接下来,我们创建标签y:
我们删除包含结果变量(Salary)的列,以及已经创建了哑变量的分类列:
X_numerical = df.drop(['Salary', 'League', 'Division', 'NewLeague'], axis=1).astype('float64')
列出所有数值特征(稍后需要用到):
# 创建所有特征
X = pd.concat([X_numerical, dummies[['League_N', 'Division_W', 'NewLeague_N']]], axis=1)
随时关注您喜欢的主题
其中:
- x 是特征中的一个观测值
- μ 是该特征的均值
- s 是该特征的标准差
为了避免数据泄漏,数值特征的标准化应始终在数据划分之后进行,并且仅使用训练数据。此外,我们从训练数据中获取特征所需的所有统计信息(均值和标准差),并在测试数据上使用它们。注意,我们不标准化哑变量(它们只取0或1的值)。
首先,我们在训练集上应用Lasso回归,并任意选择一个正则化参数α为1。

请注意,如果α=0,那么lasso将给出最小二乘拟合,而当α变得非常大时,lasso将给出所有系数估计都等于零的空模型。
coefs.append(lasso.coef_)
ax = plt.gca()
从图形的左侧到右侧,我们观察到最初lasso模型包含许多预测器,并且系数估计的绝对值很大。随着α的增加,系数估计逐渐趋近于零。
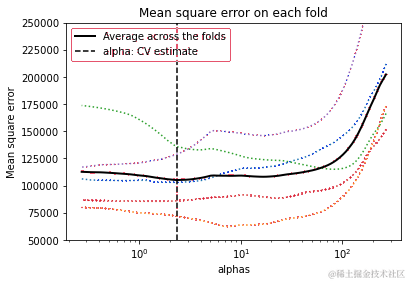
接下来,我们使用交叉验证来找到α的最佳值。
使用最佳α值的Lasso回归
为了找到α的最佳值,我们使用scikit-learn的Lasso线性模型进行迭代拟合,同时沿着正则化路径进行交叉验证(LassoCV)。最佳模型是通过交叉验证选择的。
k折交叉验证
显示交叉验证选择的最佳惩罚值:
python复制代码
model.alpha_
最佳模型
使用最佳α值构建最终模型:
lasso_best.fit(X_train, y_train)
显示模型系数和名称:
# 获取最佳模型的系数
coef = lasso_best.coef_
# 将系数和特征名称结合起来
# 显示特征及其对应系数
print(feature_coef.sort_values())
请注意,上面的代码片段假设您有一个包含特征名称的DataFrame X_df。在实际应用中,您需要将X_train转换为DataFrame(如果它不是的话),并指定相应的列名。然后,您可以创建一个Series对象,将系数与特征名称关联起来,并按值排序来显示哪些特征对模型的影响最大。如果X_train已经是DataFrame并且包含列名,那么您可以直接使用这些列名。如果X_train是NumPy数组,则需要手动创建一个包含特征名称的列表。
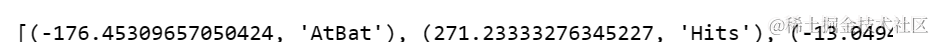
模型评估
为了评估模型的性能,我们可以使用训练集和测试集的R平方分数(决定系数),以及均方误差(Mean Squared Error, MSE)。
这将显示模型在训练集和测试集上的拟合程度。R平方分数越接近1,表示模型的拟合效果越好。
均方误差(MSE)是预测值与真实值之间差异的平方的平均值,它可以帮助我们了解模型预测的错误程度。MSE值越小,说明模型的预测能力越强。
此外,为了更深入地了解模型选择过程,我们还可以绘制Lasso路径图,该图展示了交叉验证过程中不同alpha值对应的均方误差。这有助于我们理解alpha参数如何影响模型的复杂度以及预测性能。
python复制代码
# 绘制Lasso路径图
plt.plot(alphas, coefs.T, '-')
这段代码将生成一个图表,展示随着alpha值的变化,各特征的系数是如何变化的。通过此图,我们可以更直观地理解正则化强度对模型系数的影响,以及哪些特征在模型中更重要。
请注意,绘制Lasso路径图可能需要安装额外的库,如matplotlib,并确保你的环境中有这些库。此外,上面的代码示例假设你已经拟合了LassoCV模型,并将其存储在变量model中。如果你的模型变量名称不同,请相应地替换。
plt.axvline(
model.alpha_, linestyle="--", color="k", label="alpha: CV
2.Python高维统计建模变量选择:SCAD平滑剪切绝对偏差惩罚、Lasso惩罚函数比较
变量选择是高维统计建模的重要组成部分。许多流行的变量选择方法,例如 LASSO,都存在偏差。带平滑削边绝对偏离(smoothly clipped absolute deviation,SCAD)正则项的回归问题或平滑剪切绝对偏差 (SCAD) 估计试图缓解这种偏差问题,同时还保留了稀疏性的连续惩罚。
惩罚最小二乘法
一大类变量选择模型可以在称为“惩罚最小二乘法”的模型族下进行描述。这些目标函数的一般形式是
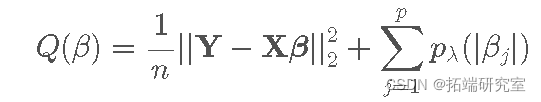
其中 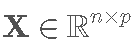 是设计矩阵,
是设计矩阵, 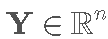 是因变量的向量,
是因变量的向量,  是系数的向量,
是系数的向量,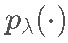 是由正则化参数索引的惩罚函数
是由正则化参数索引的惩罚函数  .
.
作为特殊情况,请注意 LASSO 对应的惩罚函数为 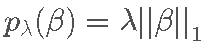 ,而岭回归对应于
,而岭回归对应于 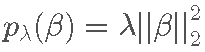 . 回想下面这些单变量惩罚的图形形状。
. 回想下面这些单变量惩罚的图形形状。
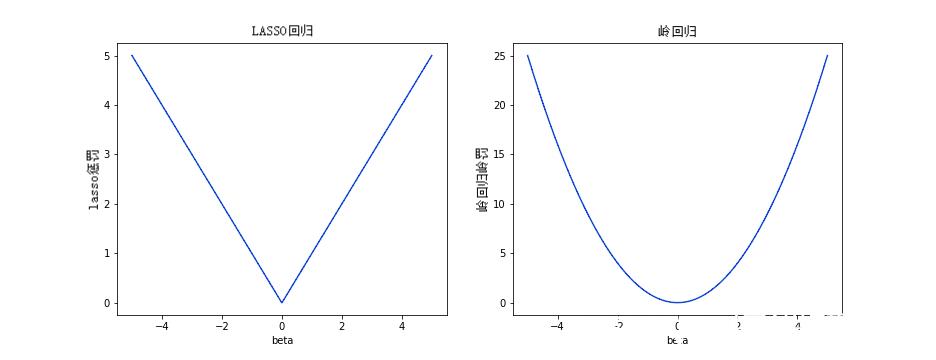
SCAD
Fan和Li(2001)提出的平滑剪切绝对偏差(SCAD)惩罚,旨在鼓励最小二乘法问题的稀疏解,同时也允许大值的 β
. SCAD惩罚是一个更大的系列,被称为 “折叠凹陷惩罚”,它在以下方面是凹的, R+ 和 R-
. 从图形上看,SCAD 惩罚如下所示:

有点奇怪的是,SCAD 惩罚通常主要由它的一阶导数定义  , 而不是
, 而不是 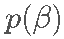 . 它的导数是
. 它的导数是
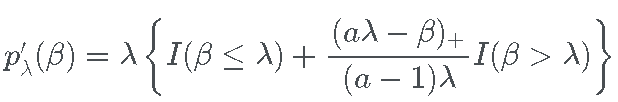
其中 a 是一个可调参数,用于控制 β 值的惩罚下降的速度,以及函数 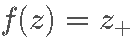 等于
等于 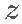 如果
如果 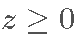 , 否则为 0。
, 否则为 0。
我们可以通过分解惩罚函数在不同数值下的导数来获得一些洞察力 λ:

对于较大的 β 值 (其中 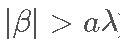 ),惩罚对于 β 是恒定的。换句话说,在 β 变得足够大之后,β 的较高值 不会受到更多的惩罚。这与 LASSO 惩罚形成对比,后者具有关于 |β|的单调递增惩罚:
),惩罚对于 β 是恒定的。换句话说,在 β 变得足够大之后,β 的较高值 不会受到更多的惩罚。这与 LASSO 惩罚形成对比,后者具有关于 |β|的单调递增惩罚:
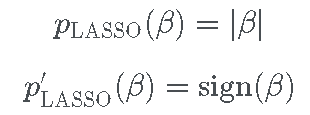
但是,这意味着对于大系数值,他们的 LASSO 估计将向下偏置。
另一方面,对于较小的 β 值 (其中 |β|≤λ),SCAD 惩罚在 β 中是线性的。对于 β 的中等值(其中  ),惩罚是二次的。
),惩罚是二次的。
分段定义,pλ(β) 是

在 Python 中,SCAD 惩罚及其导数可以定义如下:
def scad:
s_lar
iudic =np.lgicand
iscsat = (vl * laval) < np.abs
lie_prt = md_val * pab* iliear
return liprt + urtirt + cosaat
使用 SCAD 拟合模型
拟合惩罚最小二乘模型(包括 SCAD 惩罚模型)的一种通用方法是使用局部二次近似。这种方法相当于在初始点 β0 周围拟合二次函数 q(β),使得近似:
- 关于 0 对称,
- 满足 q(β0)=pλ(|β0|),
- 满足 q ′ (β0) = p′λ (| β0 |)。
因此,逼近函数必须具有以下形式
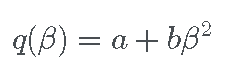
对于不依赖于 β 的系数 a 和 b 。上面的约束为我们提供了一个可以求解的两个方程组:

为了完整起见,让我们来看看解决方案。重新排列第二个方程,我们有
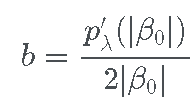
将其代入第一个方程,我们有
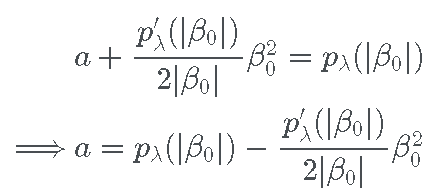
因此,完整的二次方程是
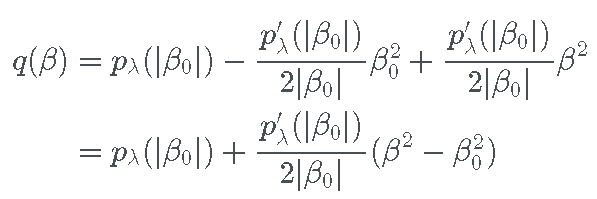
现在,对于系数值的任何初始猜测 β0,我们可以使用上面的 q 构造惩罚的二次估计。然后,与初始 SCAD 惩罚相比,找到此二次方的最小值要容易得多。
从图形上看,二次近似如下所示:

将 SCAD 惩罚的二次逼近代入完整的最小二乘目标函数,优化问题变为:

忽略不依赖于 β 的项,这个最小化问题等价于
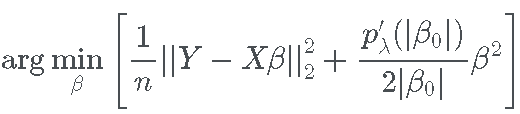
巧妙地,我们可以注意到这是一个岭回归问题,其中
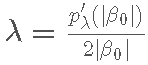
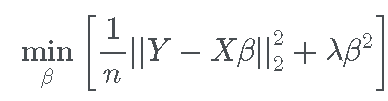
回想一下, 岭回归 是
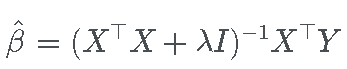
这意味着近似的 SCAD 解是

3.Python中的Lasso回归之最小角算法LARS
假设我们期望因变量由潜在协变量子集的线性组合确定。然后,LARS算法提供了一种方法,可用于估计要包含的变量及其系数。
LARS解决方案没有给出矢量结果,而是由一条曲线组成,该曲线表示针对参数矢量L1范数的每个值的解决方案。该算法类似于逐步回归,但不是在每个步骤中都包含变量,而是在与每个变量的相关性与残差相关的方向上增加了估计的参数。
优点:
1.计算速度与逐步回归一样快。
2.它会生成完整的分段线性求解路径,这在交叉验证或类似的模型调整尝试中很有用。
3.如果两个变量与因变量几乎同等相关,则它们的系数应以大致相同的速率增加。该算法因此更加稳定。
4.可以轻松对其进行修改为其他估算模型(例如LASSO)提供解决方案。
5.在p >> n的情况下有效 (即,当维数明显大于样本数时)。
缺点:
1.因变量中有任何数量的噪声,并且自变量具有 多重共线性 ,无法确定选定的变量很有可能成为实际的潜在因果变量。这个问题不是LARS独有的,因为它是变量选择方法的普遍问题。但是,由于LARS基于残差的迭代拟合,因此它似乎对噪声的影响特别敏感。
2.由于现实世界中几乎所有高维数据都会偶然地在某些变量上表现出一定程度的共线性,因此LARS具有相关变量的问题可能会限制其在高维数据中的应用。
Python代码:
import matplotlib.pyplot as plt # 绘图
diabetes
查看数据
x /= np.sqrt(np.sum((x)**2, axis=0)) # 归一化 x
lars.steps() # 执行的步骤数
est = lars.est() # 返回所有LARS估算值
plt.show()


可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R语言Lasso、Ridge岭回归、XGBoost分析Airbnb房屋数据:旅游市场差异、价格预测
Python、R语言Lasso、Ridge岭回归、XGBoost分析Airbnb房屋数据:旅游市场差异、价格预测 R语言软件对房价数据预测:回归、LASSO、决策树、随机森林、GBM、神经网络和SVM可视化
R语言软件对房价数据预测:回归、LASSO、决策树、随机森林、GBM、神经网络和SVM可视化 Python用正则化Lasso、岭回归预测房价、随机森林交叉验证鸢尾花数据可视化2案例
Python用正则化Lasso、岭回归预测房价、随机森林交叉验证鸢尾花数据可视化2案例 R语言lasso惩罚稀疏加法模型SPAM拟合非线性数据和可视化
R语言lasso惩罚稀疏加法模型SPAM拟合非线性数据和可视化


