可以从许多统计软件包中运行Stan。到目前为止,我一直在从R运行Stan。
第一步是为Stan模型编写文件。
这包含一个文件linreg.stan:
可下载资源
data {
int N;
vector[N] x;
vector[N] y;
}
model {
y ~ normal(alpha + beta * x, sigma);
}该文件的第一部分称为数据,它声明了将作为输入传递给Stan的标量,向量和矩阵。
利用贝叶斯定理求出:
-
线性回归模型中的权重
的后验概率
的概率分布。
-
新数据点的预测值
的概率分布。
线性回归模型
其中 为噪声
理解线性回归
对于线性回归这个问题,可以分别从频率派和贝叶斯派的观点来理解它。
在频率派的观点中,权值 是一个未知的常数,因此将问题转化为最优化问题,并对权值进行点估计。做点估计的方法又分为两种:
-
最大似然估计(Maximum Likelihood Estimation, MLE):
该问题即等价于最小二乘估计(Least Squares Estimator)
-
最大后验估计(Maximum A Posterior Estimation, MAP):
该问题即等价于正则化(Regularized)的最小二乘估计
而在贝叶斯派的观点中,权值 是一个随机变量,因此求的是该随机变量的条件分布:
。本文的主题——贝叶斯线性回归模型就是沿用贝叶斯派的思路进行分析的。
条件分布
根据贝叶斯定理 ,后验概率可以由先验概率和似然概率共同求出。
首先,为方便起见,设先验概率(prior)为。
由于先验概率 与训练集
独立,上式可写为
由于个数据相互独立,可得
根据高斯分布的共轭性质, 也服从高斯分布,记为
。将
和
代入贝叶斯公式,可得
辅助结论
对于任意一个服从高斯分布的随机变量,
可见:二次项中含有方差的形式;一次项中既包含均值,又包含方差。由此,经过对比相应的项,即可从一次项和二次项中求出均值和方差。
将以上结论应用于 ,可以求出
和
:
预测
已知 以及
,
根据线性回归的模型以及高斯分布的性质,可得
最后加上噪声的影响,可得
接下来,我们可以通过运行以下R代码来模拟数据集,并使用Stan和我们的文件linreg.stan来拟合模型:
stan(file = 'linreg. ', data = mydata, iter = 1000, = 4)第一次安装Stan模型时,模型编译成C ++时会有几秒钟的延迟。然而,一旦编译了模型,就可以将其应用于新的数据集而无需重复编译过程(执行模拟研究具有很大的优势)。
视频
R语言中RStan贝叶斯层次模型分析示例
在上面的代码中,我们要求Stan运行4个独立的链,每个链有1000次迭代。运行后,我们可以通过以下方式汇总输出:
Inference for Stan model: linreg.
4 chains, each with iter=1000; warmup=500; thin=1;
post-warmup draws per chain=500, total post-warmup draws=2000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
alpha -0.10 0.00 0.10 -0.29 -0.16 -0.10 -0.04 0.09 1346 1
beta 0.95 0.00 0.11 0.75 0.88 0.95 1.02 1.17 1467 1
sigma 0.98 0.00 0.07 0.85 0.93 0.98 1.03 1.12 1265 1
lp__ -47.54 0.06 1.24 -50.77 -48.02 -47.24 -46.68 -46.17 503 1
Samples were drawn using NUTS(diag_e) at Mon Jun 08 18:35:58 2015.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
对于回归斜率β,我们的后验均值为0.95(接近用于模拟数据的真实值1)。为了形成95%的后验置信区间,我们简单地采用取样后验的2.5%和97.5%的百分位数,这里是0.75到1.17。
您可以从拟合的模型中获取各种其他数量。一种是绘制其中一个模型参数的后验分布。要获得回归斜率,我们可以执行以下操作:
hist(result$beta)β后验分布直方图
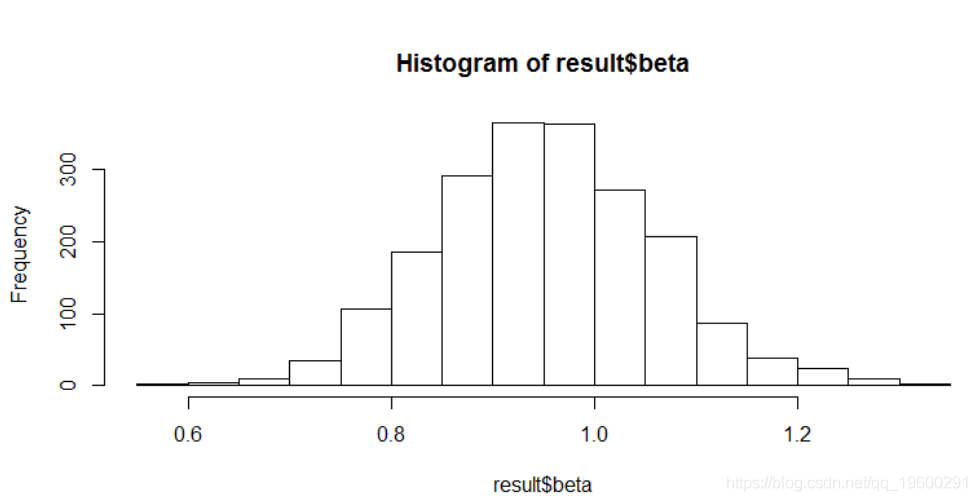
![]()
现在让我们使用标准普通最小二乘拟合线性模型:
Residuals:
Min 1Q Median 3Q Max
-1.9073 -0.6835 -0.0875 0.5806 3.2904
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.10280 0.09755 -1.054 0.295
x 0.94753 0.10688 8.865 3.5e-14 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.9707 on 98 degrees of freedom
Multiple R-squared: 0.4451, Adjusted R-squared: 0.4394
F-statistic: 78.6 on 1 and 98 DF, p-value: 3.497e-14这给出了我们对斜率0.95的估计,与Stan的后验平均值相差2位小数,标准误差为0.11,这与Stan的后验SD相同。

stan和贝叶斯推理
有兴趣探索Stan并使用它来执行贝叶斯推理,这是出于测量误差和数据缺失的问题。正如WinBUGS和作者所描述的,贝叶斯方法在解决不同的不确定性来源问题时非常自然,这些不确定性来源超出参数不确定性,例如缺失数据或用误差测量的协变量。实际上,对于流行的缺失数据多重插补方法是在贝叶斯范式内发展的。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据
Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据



