结合POT模型的洪水风险评估能够从有限的实测资料中获取更多的洪水风险信息。最近我们被客户要求撰写关于POT模型的研究报告,包括一些图形和统计输出。
结合POT模型的洪水风险评估得到更贴近事实的风险评估结果,能为决策者提供更多的依据,从而使决策结果更加可靠实用。
可下载资源
对于这些同样面临挑战的人,我希望这个博客将有助于简化工作。
案例POT序列在47年的记录期内提供了高于74 m 3 / s 阈值的47个峰值。

我们的目标是将概率模型拟合到这些数据并估算洪水分位数。
我从获取了每次洪水的日期,并将其包含在文件中。有趣的是,最早的洪水流量是1943年,而最后一次是1985年,是43年的记录,而不是47年。这是因为1939年至1943年的洪水都小于74 m 3 / s的阈值。
先计算这些数据点的绘制位置。
![]()
- T给定排放超标之间的平均间隔(年)
- R是POT系列中的流量等级(最大流量是等级1)
- n是数据的年数。
请注意,这是记录的年数,而不是峰值数。
同样,重要的是要认识到,方程式1对POT系列的作用与年度系列不同。让我们看一个显示这种差异的示例。考虑以下情况:我们根据47年的数据分析了POT系列的94个峰。在这种情况下,最小的峰的等级为94。重复间隔为:
![]()
这大约是半年或6个月,这似乎是合理的(47年中有94个高峰,因此平均每年有2个高峰,平均相隔约6个月)。
将绘图位置解释为年度超出概率将得出以下结果:
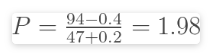
也就是说,概率大于1,这没有意义。因此,我们不能使用绘图位置公式来计算阈值峰值序列中的数据的AEP。取而代之的是,方程式1的逆可以解释为EY,即每年的预期超出次数。
ARR示例将指数分布拟合为概率模型。
为了计算L2,我们使用QJ Wang(Wang,1996)的公式
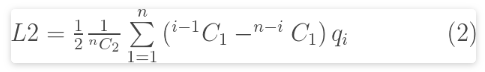
L2 <- function(q){
q <- sort(q)
n <- length(q)
0.5*(1/choose(n,2))*sum((0:(n-1) - (n-1):0)*q)
}L2 = 79.12
指数分布的参数可以用L矩表示。我们使用的是广义帕累托(GP)公式。
对于指数分布:
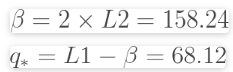
这些参数估计值的置信区间可以使用bootstrapping计算得出。
Beta的95%置信区间是(37.4,89.4)和
param_errors_df %>%
ggplot(aes(x = V1, y = V2)) +
geom_point(size = 0.1) +
scale_x_continuous(name = 'beta') +
scale_y_continuous(name = bquote('q'['*'])) +
stat_ellipse(colour = 'red') + # 95% 置信区间
theme_gray(base_size = 7)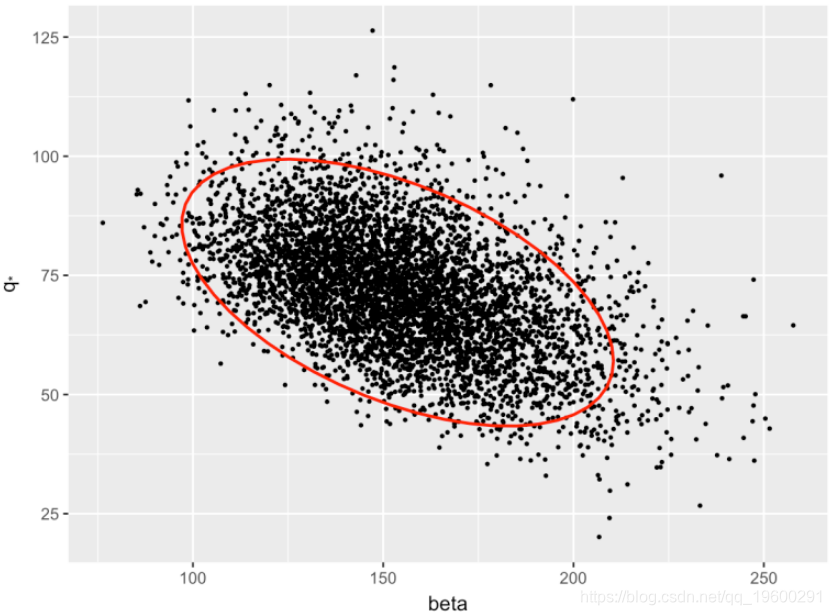
图1:参数的不确定性。椭圆显示置信限度为95%
指数分布将超出概率与流的大小相关。在这种情况下,在任何POT事件中
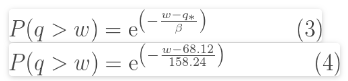
这是针对超额概率的。在水文学中,我们通常使用超出概率(洪水大于特定值的概率),因此所需方程式为一个减去所示方程式。
通过将每年超过阈值的洪峰平均数乘以POT概率,我们可以将POT概率转换为每年的预期超标次数。
74 m 3 / s阈值,POT系列中有47个值,并且有47年的数据,因此每年的平均峰值数为1。因此,EY可以表示为:
![]()
其中,q是每年POT洪水的平均数量,
w也可以与EY以下内容相关 :
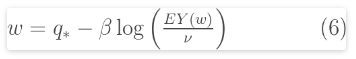
我们还可以EY通过以下公式与年度超出概率相关:
![]()
因此,通过以下等式,洪水幅度可以与AEP相关,而AEP可以与洪水幅度相关。
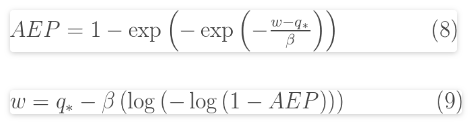
这些方程式可用于估计标准EY值的分位数。使用bootstrap自举法估计了置信区间(95%)(表1)。
res| EY | AEP | AEP (1 IN X) | ARI | Q | LWR | UPR |
|---|---|---|---|---|---|---|
| 1.00 | 0.63 | 1.6 | 1.0 | 68 | 39 | 90 |
| 0.69 | 0.50 | 2.0 | 1.4 | 127 | 106 | 150 |
| 0.50 | 0.39 | 2.5 | 2.0 | 178 | 151 | 215 |
| 0.22 | 0.20 | 5.1 | 4.5 | 308 | 253 | 404 |
| 0.20 | 0.18 | 5.5 | 5.0 | 323 | 267 | 427 |
| 0.11 | 0.10 | 9.6 | 9.1 | 417 | 335 | 565 |
| 0.05 | 0.05 | 20.5 | 20.0 | 542 | 434 | 754 |
| 0.02 | 0.02 | 50.5 | 50.0 | 687 | 548 | 965 |
| 0.01 | 0.01 | 100.5 | 100.0 | 797 | 627 | 1167 |
现在绘制数据和拟合度(图2)。x值是根据等式1的逆计算的EY;y值是流量。拟合基于等式6。使用bootstrap自举法计算分位数的置信区间。
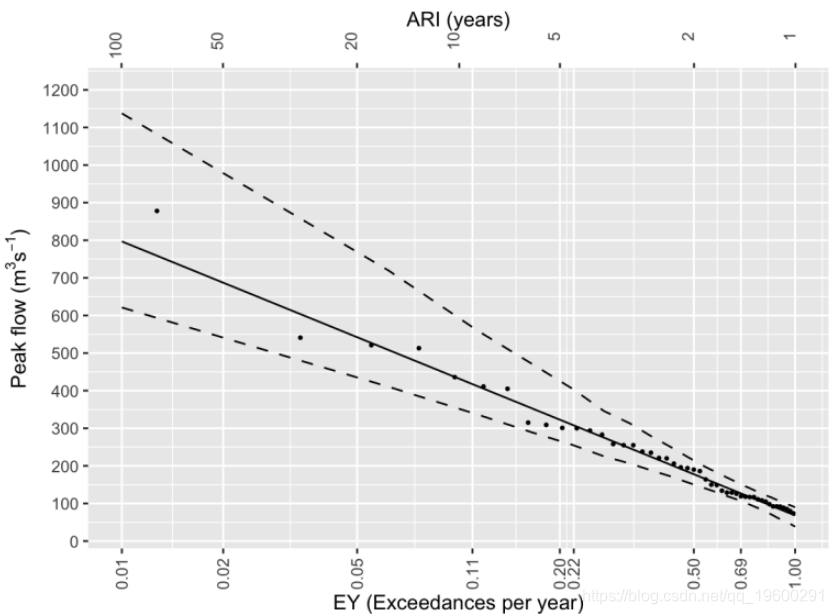
图2:河流的部分序列显示契合度和置信区间
我个人更希望该图向右增加,这通常是洪水频率曲线的绘制方式。这仅涉及使用ARI作为纵坐标(图3)。
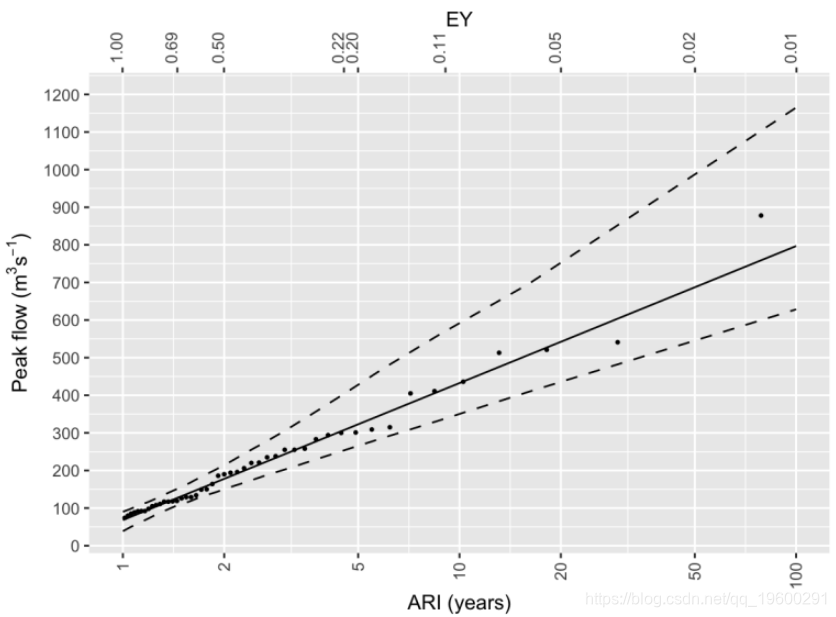
图3:河流部分序列显示契合度和置信区间
 OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据
OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 2025人工智能AI研究报告:算力、应用、风险与就业|附1000+份报告PDF、数据、可视化模板汇总下载
2025人工智能AI研究报告:算力、应用、风险与就业|附1000+份报告PDF、数据、可视化模板汇总下载



