本文使用R语言对mtcar数据进行相关矩阵分析及其可视化
数据准备
# 选择感兴趣的变量
mydata <- mtcars %>%
select(mpg, disp, hp, drat, wt, qsec)
#
mydata$hp[3] <- NA
# 查看数据
head(mydata, 3)可下载资源
## mpg disp hp drat wt qsec
## Mazda RX4 21.0 160 110 3.90 2.62 16.5
## Mazda RX4 Wag 21.0 160 110 3.90 2.88 17.0
## Datsun 710 22.8 108 NA 3.85 2.32 18.6计算相关矩阵
res.cor <- correlate(mydata)
res.cor1)Pearson积差相关系数:用于量度两个变量X和Y之间的线性相关。它具有+1和-1之间的值,其中1是总正线性相关性,0是非线性相关性,并且-1是总负线性相关性。Pearson相关系数的一个关键数学特性是它在两个变量的位置和尺度的单独变化下是不变的。也就是说,我们可以将X变换为a+bX并将Y变换为c+dY,而不改变相关系数,其中a,b,c和d是常数,b,d > 0。请注意,更一般的线性变换确实会改变相关性。
Pearson积差相关系数对应的计算公式如下:

积差相关系数的适用条件: 在相关分析中首先要考虑的问题就是两个变量是否可能存在相关关系,如果得到了肯定的结论,那才有必要进行下一步定量的分析。另外还必须注意以下几个问题: 1、 积差相关系数适用于线性相关的情形,对于曲线相关等更为复杂的情形,积差相关系数的大小并不能代表相关性的强弱。 2、 样本中存在的极端值对Pearson积差相关系数的影响极大,因此要慎重考虑和处理,必要时可以对其进行剔出,或者加以变量变换,以避免因为一两个数值导致出现错误的结论。 3、 Pearson积差相关系数要求相应的变量呈双变量正态分布,注意双变量正态分布并非简单的要求x变量和y变量各自服从正态分布,而是要求服从一个联合的双变量正态分布。 以上几条要求中,前两者的要求最严,第三条比较宽松,违反时系数的结果也是比较稳健的。
2)Spearman秩相关系数:使利用两变量的秩次大小作线性相关分析,对原始变量的分布不做要求,属于非参数统计方法。因此它的适用范围比Pearson相关系数要广的多。即使原始数据是等级资料也可以计算Spearman相关系数。对于服从Pearson相关系数的数据也可以计算Spearman相关系数,但统计效能比Pearson相关系数要低一些(不容易检测出两者事实上存在的相关关系)。如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。Spearman相关系数即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对Spearman相关性系数的影响也非常小。
计算公式:对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数ρ为
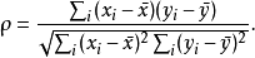
实际应用中,变量间的连结是无关紧要的,于是可以通过简单的步骤计算ρ.被观测的两个变量的等级的差值,则ρ为

3)Kendall秩相关系数: 是一种秩相关系数,用于反映分类变量相关性的指标,适用于两个变量均为有序分类的情况,用希腊字母τ(tau)表示其值。
【分类变量可以理解成有类别的变量,可以分为无序的,比如性别(男、女)、血型(A、B、O、AB);有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。通常需要求相关性系数的都是有序分类变量】
Kendall相关系数的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的。
计算公式:Kendall系数是基于协同的思想。对于X,Y的两对观察值Xi,Yi和Xj,Yj,如果Xi<Yi并且Xj<Yj,或者Xi>Yi并且Xj>Yj,则称这两对观察值是和谐的,否则就是不和谐。kendall相关系数的计算公式如下:
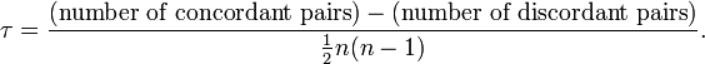
和谐的观察值对减去不和谐的观察值对的数量,除以总的观察值对数.
注意:三种相关系数都是对变量之间相关程度的度量,由于其计算方法不一样,用途和特点也不一样。
1)Pearson相关系数是在原始数据的方差和协方差基础上计算得到,所以对离群值比较敏感,它度量的是线性相关。因此,即使pearson相关系数为0,也只能说明变量之间不存在线性相关,但仍有可能存在曲线相关。
2)Spearman相关系数和kendall相关系数都是建立在秩和观测值的相对大小的基础上得到,是一种更为一般性的非参数方法,对离群值的敏感度较低,因而也更具有耐受性,度量的主要是变量之间的联系。
补充:无序分类变量的统计推断:卡方检验
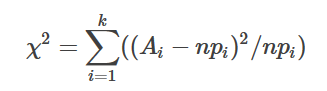
Ai为i水平的观测频数,Ei为i水平的期望频数,n为总频数,Pi为i水平的期望概率。 主要用于检验某无序分类变量各水平在两组或多组间的分布是否一致。还可以用于检验一个分类变量各水平出现的概率是否等于指定概率;一个连续变量的分布是否符合某种理论分布等。其主要用途: 1、 检验某个连续变量的分布是否与某种理论分布相一致。 2、 检验某个分类变量各类的出现概率是否等于制定概率。 3、 检验某两个分类变量是否相互独立。 4、 检验控制某种或某几种分类因素的作用以后,另两个分类变量是否相互独立。 5、 检验某两种方法的结果是否一致。
## # A tibble: 6 x 7
## rowname mpg disp hp drat wt qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA -0.848 -0.775 0.681 -0.868 0.419
## 2 disp -0.848 NA 0.786 -0.710 0.888 -0.434
## 3 hp -0.775 0.786 NA -0.443 0.651 -0.706
## 4 drat 0.681 -0.710 -0.443 NA -0.712 0.0912
## 5 wt -0.868 0.888 0.651 -0.712 NA -0.175
## 6 qsec 0.419 -0.434 -0.706 0.0912 -0.175 NA该函数的其他参数correlate()包括:
method:字符串,指示要计算哪个相关系数(或协方差)。“pearson”(默认),“kendall”或“spearman”之一:可以缩写。diagonal:将对角线设置为的值(通常为数字或NA)。
探索相关矩阵

过滤器相关性高于0.8:
## # A tibble: 6 x 3
## rowname colname cor
## <chr> <chr> <dbl>
## 1 disp mpg -0.848
## 2 wt mpg -0.868
## 3 mpg disp -0.848
## 4 wt disp 0.888
## 5 mpg wt -0.868
## 6 disp wt 0.888特定的列/行
该功能focus()使得可以focus()在列和行上进行操作。此函数的作用与dplyr类似slect(),但也会从行中排除选定的列。
- 选择与兴趣列相关的结果。所选列将从行中排除:
## # A tibble: 3 x 4
## rowname mpg disp hp
## <chr> <dbl> <dbl> <dbl>
## 1 drat 0.681 -0.710 -0.443
## 2 wt -0.868 0.888 0.651
## 3 qsec 0.419 -0.434 -0.706- 选定的列:
## # A tibble: 3 x 4
## rowname mpg disp hp
## <chr> <dbl> <dbl> <dbl>
## 1 mpg NA -0.848 -0.775
## 2 disp -0.848 NA 0.786
## 3 hp -0.775 0.786 NA- 删除不需要的列:
## # A tibble: 3 x 4
## rowname drat wt qsec
## <chr> <dbl> <dbl> <dbl>
## 1 mpg 0.681 -0.868 0.419
## 2 disp -0.710 0.888 -0.434
## 3 hp -0.443 0.651 -0.706- 按正则表达式选择列
## # A tibble: 4 x 3
## rowname disp drat
## <chr> <dbl> <dbl>
## 1 mpg -0.848 0.681
## 2 hp 0.786 -0.443
## 3 wt 0.888 -0.712
## 4 qsec -0.434 0.0912- 选择高于0.8的相关性:
## # A tibble: 2 x 3
## rowname disp wt
## <chr> <dbl> <dbl>
## 1 disp NA 0.888
## 2 wt 0.888 NA- 关注一个变量与所有其他变量的相关性:
# 提取相关性
## # A tibble: 5 x 2
## rowname mpg
## <chr> <dbl>
## 1 disp -0.848
## 2 hp -0.775
## 3 drat 0.681
## 4 wt -0.868
## 5 qsec 0.419# 绘制相关系数
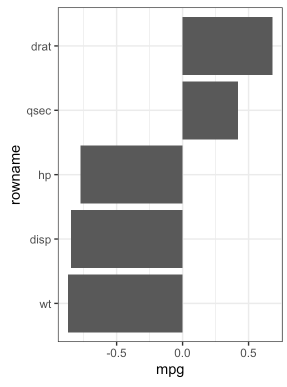

重新排序相关矩阵
## # A tibble: 6 x 7
## rowname wt drat disp mpg hp qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 wt NA -0.712 0.888 -0.868 0.651 -0.175
## 2 drat -0.712 NA -0.710 0.681 -0.443 0.0912
## 3 disp 0.888 -0.710 NA -0.848 0.786 -0.434
## 4 mpg -0.868 0.681 -0.848 NA -0.775 0.419
## 5 hp 0.651 -0.443 0.786 -0.775 NA -0.706
## 6 qsec -0.175 0.0912 -0.434 0.419 -0.706 NA
上/下三角
上/下三角形到缺失值
res.cor %>% shave()## # A tibble: 6 x 7
## rowname mpg disp hp drat wt qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA NA NA NA NA NA
## 2 disp -0.848 NA NA NA NA NA
## 3 hp -0.775 0.786 NA NA NA NA
## 4 drat 0.681 -0.710 -0.443 NA NA NA
## 5 wt -0.868 0.888 0.651 -0.712 NA NA
## 6 qsec 0.419 -0.434 -0.706 0.0912 -0.175 NA
将数据拉伸为长格式
res.cor %>% stretch()## # A tibble: 36 x 3
## x y r
## <chr> <chr> <dbl>
## 1 mpg mpg NA
## 2 mpg disp -0.848
## 3 mpg hp -0.775
## 4 mpg drat 0.681
## 5 mpg wt -0.868
## 6 mpg qsec 0.419
## # … with 30 more rows
使用tidyverse和corrr包处理相关性
可视化相关系数的分布:
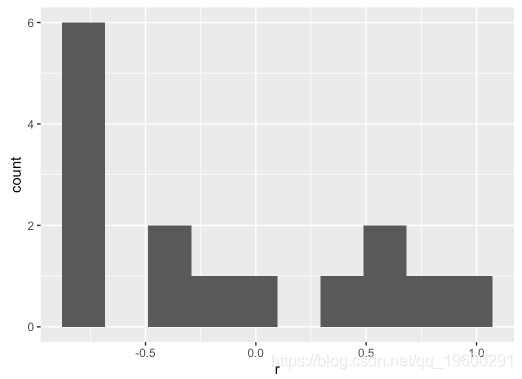

重新排列并过滤相关矩阵:
res.cor %>%
focus(mpg:drat, mirror = TRUE) %>%
## # A tibble: 3 x 4
## rowname mpg disp drat
## <chr> <dbl> <dbl> <dbl>
## 1 hp -0.775 0.786 -0.443
## 2 mpg NA -0.848 0.681
## 3 disp NA NA -0.710
解释相关性
## rowname mpg disp hp drat wt qsec
## 1 mpg -.85 -.77 .68 -.87 .42
## 2 disp -.85 .79 -.71 .89 -.43
## 3 hp -.77 .79 -.44 .65 -.71
## 4 drat .68 -.71 -.44 -.71 .09
## 5 wt -.87 .89 .65 -.71 -.17
## 6 qsec .42 -.43 -.71 .09 -.17res.cor %>%
focus(mpg:drat, mirror = TRUE)
## rowname mpg disp drat
## 1 hp -.77 .79 -.44
## 2 mpg -.85 .68
## 3 disp -.71
- 制作相关图:
- 重新排列然后绘制下三角形:

- 制作网络

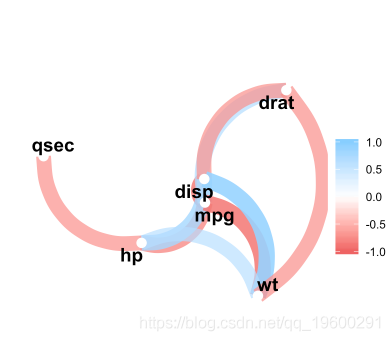
关联数据库中的数据
- 使用SQLite数据库:
con <- DBI::dbConnect(RSQLite::SQLite(), path = ":dbname:")
db_mtcars <- copy_to(con, mtcars)
class(db_mtcars)correlate()检测数据库后端,用于tidyeval计算数据库中的相关性,并返回相关数据。
db_mtcars %>% correlate(use = "complete.obs")- 使用spark:
sc <- sparklyr::spark_connect(master = "local")
mtcars_tbl <- copy_to(sc, mtcars)
correlate(mtcars_tbl, use = "complete.obs")可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载
2026年智能网联汽车(车联网)蓝皮书:渠道整合、新能源出海与市场分化|附200+份报告PDF、数据、可视化模板汇总下载 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 Claude Code多端协同 AI 开发环境构建与效率分析 |附教程文档
Claude Code多端协同 AI 开发环境构建与效率分析 |附教程文档



