
本文介绍了冲积/桑基图,以及
定义了命名方案和冲积/桑基图的基本组成部分(轴、冲积层、流);描述了所识别的冲积/桑基图数据结构;展示了一些流行的主题。
冲积/桑基图
这里有一个典型的冲积/桑基图。

桑基图(Sankey Diagram),这个桑基也是一个人名,全名马修·亨利·菲尼亚斯·里尔·桑基(Matthew Henry Phineas Riall Sankey),是一名爱尔兰裔工程师,也是英国皇家陆军工兵的上尉。
他在1898年的时候就使用这种图来显示蒸汽机的能源效率。
著名的桑基图之一-1812年拿破仑俄国战役地图,是一个名叫查尔斯·约瑟夫·米纳德的法国土木工程师在1869年绘制的(咦,这图应该叫米纳德图才对吧~),这个图将桑基图和地理图叠加在一起了。
米纳德没有桑基有影响力,错失了一个被命名的机会。桑基之后,桑基图渐渐成为在科学和工程领域,代表热平衡、能量流、物质流的标准模型,在一些产品的生命周期评估中也常被使用。
桑基图应用
看完上节内容,可能会觉得跟第一部分的示例差别好大,桑基图在科学、工程上的应用太专业了,所以衍生出来的冲积图(第一部分中的示例)更适合大众应用。
桑基图用来显示流向和数量(彼此之间的比例),箭头或线的宽度用于显示大小,因此箭头越大,流量也越大。在每个流程阶段中,流向箭头或线可以组合在一起,或者往不同路径各自分开。我们可用不同颜色来区分图表中的不同类别,或表示从一个阶段到另一个阶段的转换。
桑基图非常适用于表达数据的流向,在能源、材料成分、金融等数据的可视化分析中都是可以使用,第一部分中,作为新冠病人的流向分析也是很直观的。
现在,我们以该图像为参考点,定义典型冲积图的以下元素。
- 轴是一个维度(变量),数据沿着这个维度在一个固定的水平位置被垂直分组。上面的图使用了三个分类轴。 船舱等级、性别和年龄。
- 每个轴上的组被描述为不透明的块,称为类别。例如,类别轴包含四个等级的舱:一等舱、二等舱、三等舱和船员。
- 水平样条被称为冲积流,横跨该图。在该图中,每个冲积层对应于每个轴变量的一个固定值,由其在轴上的垂直位置表示,由其填充颜色表示。
- 相邻轴对之间的冲积段是流动的。
- 冲积与层相交的节点。节点在上面的图中并不直观,但可以推断为填充的矩形,它将层中的流延伸到图的两端,或者将中心层两边的流连接起来。
正如下一节中的例子所示,这些元素中哪些被纳入冲积图,取决于基础数据的结构和创建者希望图中传达的内容。
冲积/桑基图数据
识别两种格式的 “冲积/桑基图数据”,它们基本上对应于分类重复测量数据的 “宽 “和 “长 “格式。第三种,表格(或数组)形式,流行于存储具有多个分类维度的数据,如泰坦尼克号幸存数据和大学录取情况数据集。

(宽)格式数据
宽格式数据每一行都对应于在每个变量上取一个特定值的观察队列,每个变量都有自己的列。另外一列包含了每一行的数量,如队列中的观察单元数,可用于控制层的高度。 基本上,宽格式由每一冲积层的一行组成。这是基础函数as.data.frame()转换频率表的格式,例如3维的大学录取情况数据集。
head(as.data.frame(UCBAdmissions), n = 12)
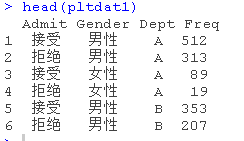
这种格式:用户声明数量的轴变量,识别并处理。
plot(pltdat1,
aes(y = Freq)) +
strat(width = 1/12) +
geom_label(stat = "stratum")) +
ggtitle("大学录取和拒绝情况,按性别和系别分列")+theme_bw()
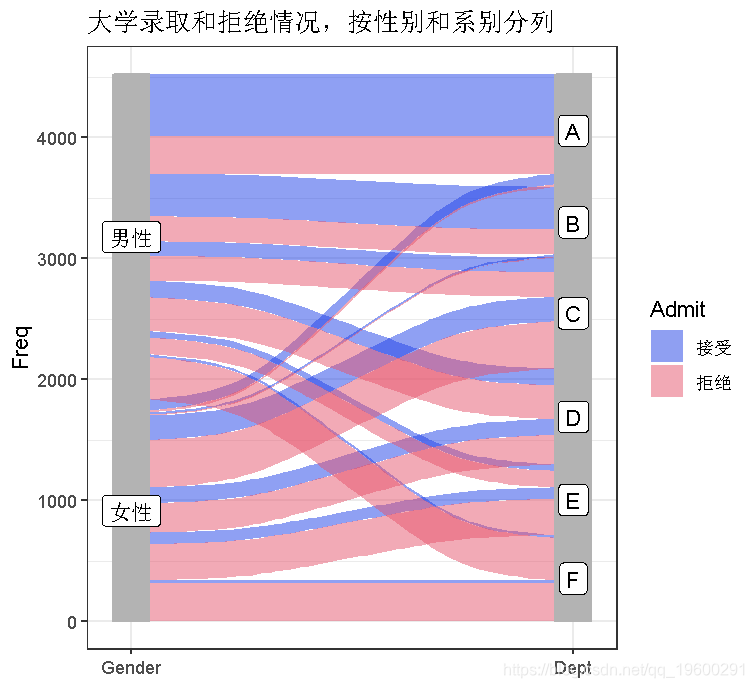
这些图的一个重要特征是纵轴的意义。各层之间没有插入空隙,所以图的总高度反映了观测值的累积数量。
随时关注您喜欢的主题
plot((Titanic),stratumwidth = 1/8, reverse = FALSE ,stat = "stratum", aes(label = after_stat(stratum)), labels = c("幸存", "性别", "船舱等级")) + title("按等级和性别划分的泰坦尼克号幸存状况")+theme_bw()
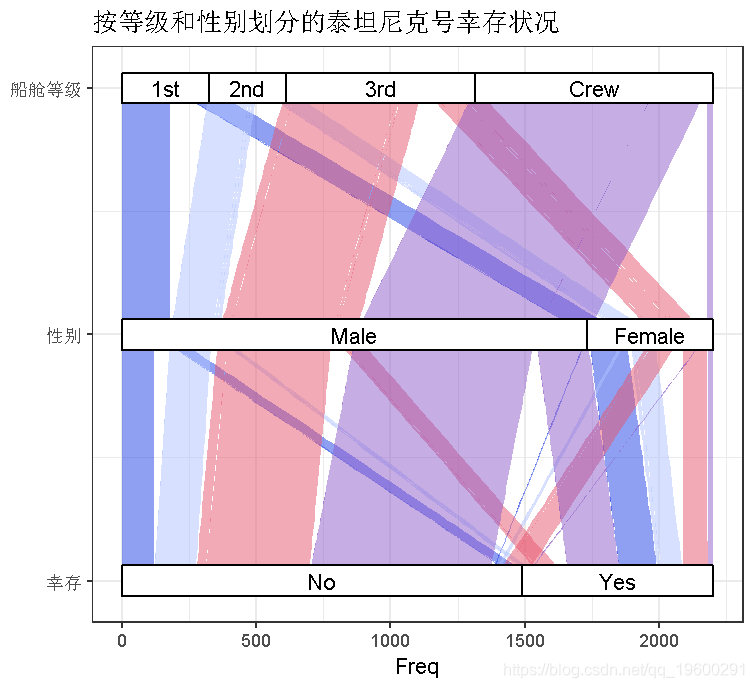
这种格式和功能对很多应用都很有用。
- axis[0-9]*表示位置。
- 由stat_stratum()产生的分层变量。
- 横轴反映识别该轴的隐含分类变量。
此外,像填充这样的格式美学对于每个冲积图来说都是固定的;例如,它们不能根据每个轴的取值而在轴之间变化。
这意味着,尽管它们可以重现平行集的分支树结构,但这种格式和功能不能产生具有这里(”冲积图”)和这里(”控制颜色”)特色的颜色方案的冲积图,它们在每个轴上都被 “重置”。
(长)格式
长格式包含了每一节的一行,变成一个键值对,编码轴为键,层为值的列。这种格式需要一个额外的索引列,将对应于一个共同队列的行连接起来,即一个冲积层的结点。
在宽格式(alluvia)和长格式(lodes)之间转换数据的函数包括几个参数。
同样的stat和geom可以使用一套不同的位置美学来接收这种格式的数据。
在这些情况下,分层没有包含比冲积层更多的信息,因此通常不会被绘制。
x,表示该行所对应的轴的 "键 "变量,要沿横轴排列。层,由x表示的轴变量的 "值";以及冲积层,连接单个冲积层的行的索引方案。
难民数据分析
作为一个例子,我们可以将难民数据集中的国家按地区分组,以比较不同规模的难民数量。
qplot(data = Refug,x = year, y = refugees, alluvium = country,fill = country, colour = country)
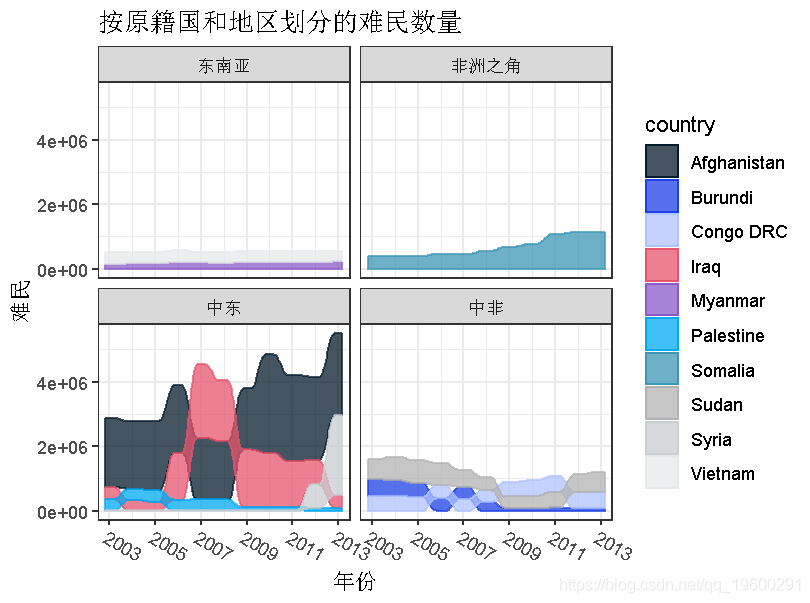
该格式允许我们指定沿同一冲积层的不同轴线变化的美学,对重复测量数据集很有用。需要为每个冲积物生成一个单独的图形对象。
学术课程分析
下面的图表使用了一组学生在几个学期内的学术课程的(变化)。在所有学期中跟踪每个学生。
ggplot(majos,flow = "alluvium", lode = "frontback",legend.position = "bottom")
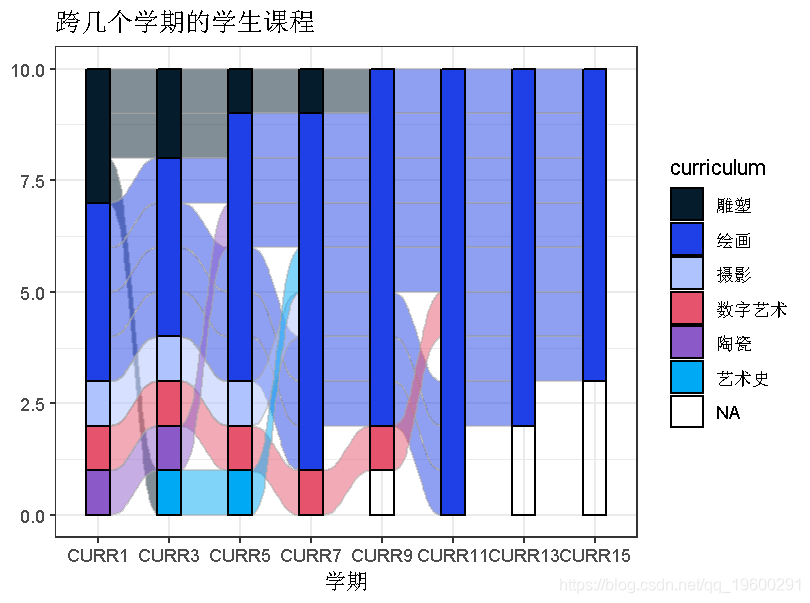
分层高度y没有被指定,所以每一行都被赋予单位高度。这个例子展示了处理缺失数据的一种方式。缺失数据的处理(特别是层的顺序)也取决于层变量是字符还是因子/数字的。
最后,我们提供了汇总相邻轴之间流量的选项。我们可以在流感疫苗调查的数据上演示这个选项。
qplot(vaccina,x = survey, stratum = response, alluvium = subject, y = freq, stat = "stratum", size = 3)
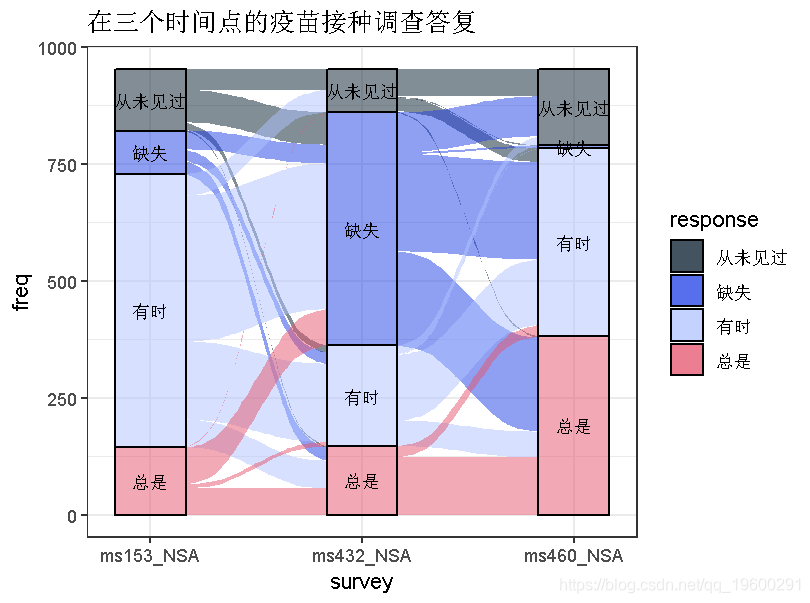
这张图忽略了轴之间流动的连续性。这种 “无记忆 “图产生了一个不那么杂乱的图,其中最多只有一个流量从一个轴上的每个层到下一个轴上的每个层。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载
2026年医疗趋势报告:医保改革、创新药、国产替代|附230+份报告PDF、数据、可视化模板汇总下载 2025-2026保健品行业报告:线上渠道、功效细分、种草营销 | 附80+份报告PDF、数据、可视化模板汇总下载
2025-2026保健品行业报告:线上渠道、功效细分、种草营销 | 附80+份报告PDF、数据、可视化模板汇总下载 2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载
2026脑机接口技术发展现状报告:市场格局与商业化落地 | 附60+份报告PDF、数据、可视化模板汇总下载



