如果您可以写出模型的似然函数,则 Metropolis-Hastings算法可以负责其余部分(即MCMC )。
在统计学与数据分析的前沿领域,贝叶斯估计凭借其将先验信息与样本数据相结合的独特优势,成为解决复杂参数估计问题的重要方法。
它能够在不确定性环境下,对未知参数进行合理推断,广泛应用于生物统计、金融计量、环境科学等多个领域。然而,当面对高维、复杂的后验分布时,直接计算贝叶斯估计往往困难重重。
Metropolis – Hastings(M – H)采样算法作为马尔可夫链蒙特卡罗(MCMC)方法的核心算法之一,为解决这一难题提供了强大的工具。该算法通过构建马尔可夫链,使得其平稳分布逼近目标后验分布,从而可以从后验分布中进行采样,进而实现参数的贝叶斯估计。而且,自适应版本的 Metropolis – Hastings 算法能根据采样过程中的信息自动调整采样策略,进一步提高采样效率和估计精度。
R 语言以其丰富的统计库、强大的编程能力和出色的可视化功能,成为实现 Metropolis – Hastings 采样算法进行自适应贝叶斯估计与可视化的理想选择。通过 R 语言,研究者可以方便地实现算法逻辑,并将估计结果以直观的图形展示出来,为深入理解数据和模型提供有力支持。
我写了r代码来简化对任意模型的后验分布的估计。具体如下:

a<-pars[1] #截距
b<-pars[2] #斜率
sd_e<-pars[3] #残差
if(sd_e<=0){return(NaN)}
log_likelihood<-sum( dnorm(data[,2],pred,sd_e, log=TRUE) )
1.1 基本概念
-
从一个概率分布(目标分布
)中得到随机样本序列
-
这个序列可以用于:a) 近似估计分布
-
用于高维分布取样
-
缺陷: MCMC固有缺点, 样本自相关性
1.2 优势
-
可以从任意的概率分布
成比例于
-
更宽松的要求:
1.3 要点
-
生成样本值序列;样本值产生得越多,这些值的分布就越近似于
-
迭代产生样本值:下一个样本的分布仅仅取决于当前样本值(马尔科夫链特性)
-
接受/拒绝概率:接受计算出的值为下一个样本值/拒绝并重复使用当前样本值;基于
(当前值)和
(备选值)得出
1.4 Metropolis Algorithm (对称分布)
-
Input:
1. 初始化:
-
: 取任意点作为第一个样本值
-
: 任意的概率密度函数;给定上一个样本值
,计算出下一个样本值
; 一般我们设定
;我们也会令
分布,即越靠近
-
将样本序列制成随机游走(random walk);
: 假定密度/跳跃分布(jumping distribution)
2. 迭代
-
通过密度函数
生成备选样本值
-
计算接受备选样本值的比率:
;由于
。
-
若
,
比
更接近
;否则,以
的概率接受备选样本值
。
1.5 缺陷
-
样本自相关:相邻的样本会相互相关,虽然可以通过每
步取样的方式来减少相关性,但这样的后果就是很难让样本近似于目标分布
-
自相关性可通过增加步调长度(jumping width,与jumping function
-
过大或过小的jumping size会导致slow-mixing Markov Chain, 即高度自相关的一组样本,以至于我们需要得到非常大的样本量
-
初始值的选择:尽管Markov Chain最后都会收敛到目标分布,然而初始值的选择直接影响到运算时间,尤其是把初始值选在在了“低密度”区域。因此,选择初值时,最好加入一个“burn-in period”(预烧期,预选期)。
1.6 优势
-
抗“高维魔咒”(curse of dimensionality):维度增加,对于rejection sampling方法来说,拒绝的概率就是呈指数增长。而MCMC则成为了解决这种问题的唯一方法
-
多元分布中,为了避免多元初始值以及
1.7 衍生算法
Metropolis-Hastings算法的目的是根据目标分布生成一个状态集。算法运用了渐进于平稳分布
的Markov过程使得
。
Markov过程由它的状态转换概率所决定的。为从任意状态
转化到另外一个任意状态
的转换概率。当它符合以下两点是,它有唯一的平稳分布
:
-
平稳分布
的存在性:充分但非必要条件为细致平衡(detailed balance):每一个转换
都是可逆的,即对任意连个状态
的概率等于在状态
的概率,即
-
平稳分布
-
非周期性的(aperiodic):系统不会再某一个固定时间区间内回到原状态
-
正递归的(positive recurrent):回到同一个状态的步数的期望是有限值
Metropolis-Hastings算法需要通过构建转换概率来构建一个Markov过程且需要满足以上两点来使得Markov过程的平稳分布就是目标分布
。算法衍生从满足细致平衡条件开始:
,
即 (1)
这样就把转换的细致平衡转化为两步:提议和接受-拒绝。
提议分布为给定状态
时提出状态
的条件概率,接受分布
为接受所提出的状态
的概率。转换概率就能写成它们的乘积:
(2)
由(1)和(2)就有:
之后就要选一个满足上面条件的接受函数了。一般我们选Metropolis选项,即:
满足了Metropolis算法的基本步骤,即大于1的时候总是接受,小于1的时候按比例接受和拒绝。
则Metropolis-Hastings算法可以概述为:
-
初始化:随机选取初始状态
-
根据
随机选取状态
-
根据
选择接受或拒绝状态
-
返回步骤2,直到生成了
个状态
-
保存状态
原则上说,被保存的状态是从分布中生成的,因为步骤4保证了这些状态是非相关的。取值
需根据不同的特性选取,如提出的分布以及,它必须是Markov过程自相关时间的阶。
关于的选取需具体问题具体分析和调整。
先验:
epsilon<-pars[3] #残差
prior_a<-dnorm(a,0,100,log=TRUE) ##所有的非信息性先验
prior_b<-dnorm(b,0,100,log=TRUE) ## 参数.
prior_epsilon<-dgamma(epsilon,1,1/100,log=TRUE)
1)现在让我们模拟一些数据以进行运行测试:
x<-runif(30,5,15)
y<-x+rnorm(30,0,5) ##斜率=1, 截距=0, epsilon=5
2)Metro Hastings 完成所有工作。
MH(li_func=li_reg,pars=c(0,1,1),
3)您可以使用plotMH()查看所有模型参数的后验
plot(mcmc) 绘制所有参数之间的相关性。
4)输出后验置信区间。
BCI
# 0.025 0.975
# a -5.3345970 6.841016
# b 0.4216079 1.690075
# epsilon 3.8863393 6.660037接下来,我想提供一种直观的方法来可视化此算法运行的情况。
主要思想是从分布中抽取样本。积分很重要,贝叶斯定理本身:
P(θ| D)= P(D |θ)P(θ)/ P(D)
其中P(D)是观察数据的无条件概率。由于这不依赖于推断的模型(θ)参数,因此P(D)是归一化常数。
因此,我们有一个非归一化的概率密度函数,我们希望通过随机抽样来估计。对于复杂的模型而言,随机抽样本身的过程通常很困难,因此,我们使用马尔可夫链来探索分布。我们需要一个链,如果运行时间足够长,它将作为目标分布的随机样本整体。我们构建的马尔可夫链的这种特性称为 遍历性。Metropolis-Hastings算法是构建这种链的一种方法。
步骤
- 在参数空间k_X中选择一些起点
- 选择一个候选点k_Y
- 移至候选点的概率为:min(π(k_Y)/π(K_X),1)
- 重复。
以下代码通过简单的正态目标分布演示了此过程。
### Metropolis-Hastings 可视化 #######
k_X = seed; ##将k_X设置为种子位置
for(i in 1:iter)
{
track<-c(track,k_X) ## 链
k_Y = rnorm(1,k_X,prop_sd) ##候选点
## -- 绘制链的核密度估计
lines(density(track,adjust=1.5),col='red',lwd=2)
## -- 绘制链
plot(track,1:i,xlim=plot_range,main='',type='l',ylab='Trace')
## -- 绘制目标分布和提议分布
curve(dnorm(x,k_X,prop_sd),col='black',add=TRUE)
abline(v=k_X,lwd=2)
## 接受概率为a_X_Y
if (log(runif(1))<=a_X_Y)
points(k_Y,0,pch=19,col='green',cex=2)
## 调整提议
if(i>100)
prop_sd=sd(track[floor(i/2):i])
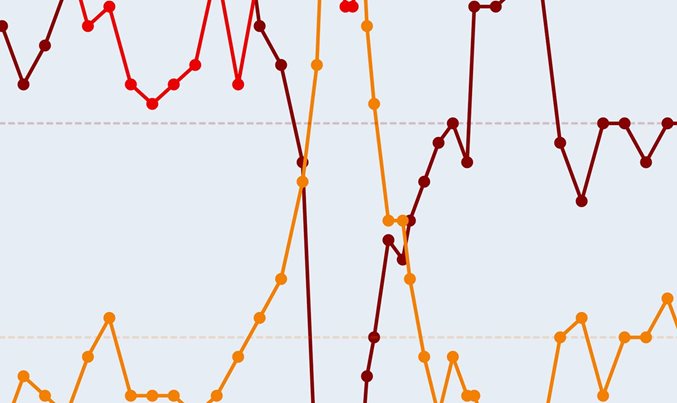
该算法实现中的一个普遍问题是σ的选择。当σ接近目标分布的标准偏差时,将发生有效混合(链收敛到目标分布)。当我们不知道这个值时。我们可以允许σ根据到目前为止的链历史记录进行调整。在上面的示例中,将σ更新为链中某些先验点的标准偏差值。
输出为多页pdf,可以滚动浏览。
随时关注您喜欢的主题
注意:请注意,前100次左右的迭代是目标分布的较差表示。在实践中,我们将“预烧”该链的前n个迭代-通常是前100-1000个。
顶部显示了目标分布(蓝色虚线)和通过MCMC样本对目标进行的核平滑估计。第二面板显示了链的轨迹,底部显示了算法本身的步骤。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据
Python酒厂智能排产多目标优化:粒子群算法PSO、ANSGA-II、蒙特卡洛仿真、熵权法与历史排产数据应用|附代码数据 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据
Python农作物种植策略研究GA-BP神经网络、蒙特卡洛算法、自注意力Stacking集成模型及粒子群算法PSO优化基于华北山区乡村农作物数据及地块数据



