通常,GLM的连接函数可能比分布更重要。
为了说明,考虑以下数据集,其中包含5个观察值
x = c(1,2,3,4,5)
y = c(1,2,4,2,6)
base = data.frame(x,y)然后考虑具有不同分布的几个模型,以及一个链接
regNId = glm(y~x,family=gaussian(link="identity"),data=base)
regNlog = glm(y~x,family=gaussian(link="log"),data=base)
regPId = glm(y~x,family=poisson(link="identity"),data=base)
regPlog = glm(y~x,family=poisson(link="log"),data=base)
regGId = glm(y~x,family=Gamma(link="identity"),data=base)
regGlog = glm(y~x,family=Gamma(link="log"),data=base)
regIGId = glm(y~x,family=inverse.gaussian(link="identity"),data=base)
regIGlog = glm(y~x,family=inverse.gaussian(link="log"),data=base还可以考虑一些Tweedie分布,甚至更一般
考虑使用线性链接函数在第一种情况下获得的预测
plot(x,y,pch=19)
abline(regNId,col=darkcols[1])
abline(regPId,col=darkcols[2])
abline(regGId,col=darkcols[3])
abline(regIGId,col=darkcols[4])
abline(regTwId,lty=2)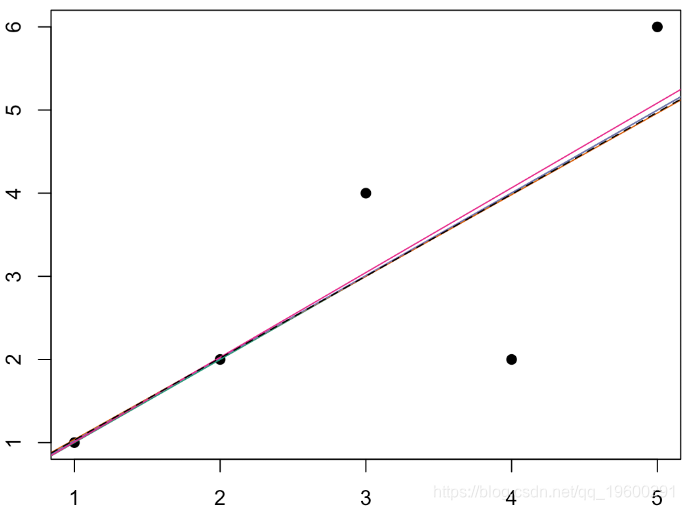
这些预测非常接近。在指数预测的情况下,我们获得

我们实际上可以近距离看。例如,在线性情况下,考虑使用Tweedie模型获得的斜率(实际上将包括此处提到的所有参数famile)
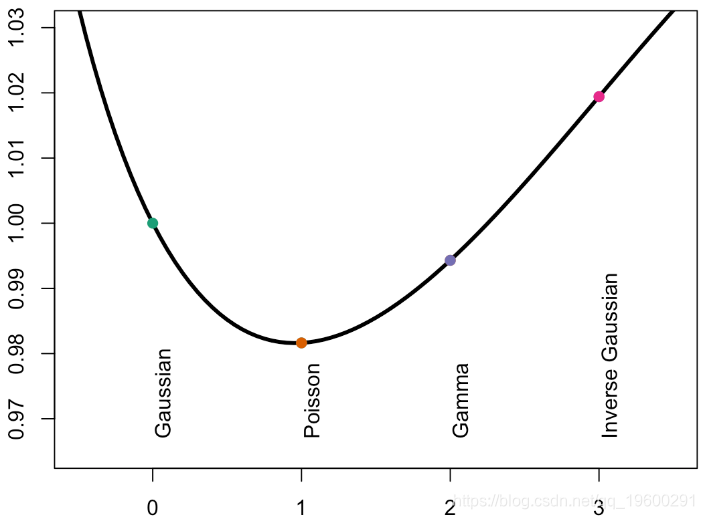
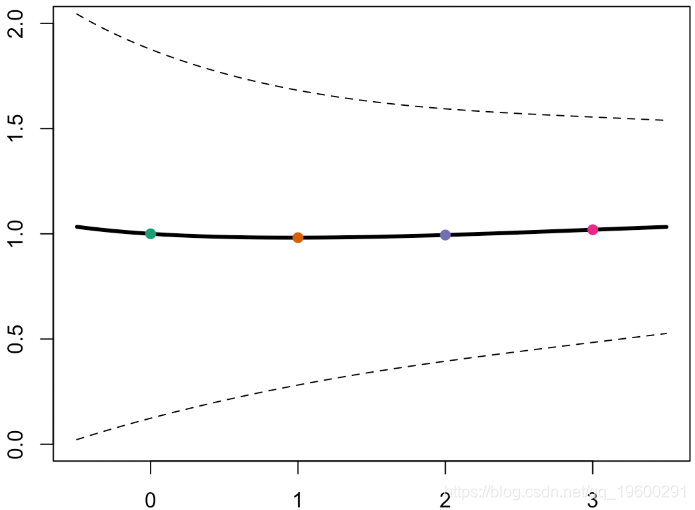
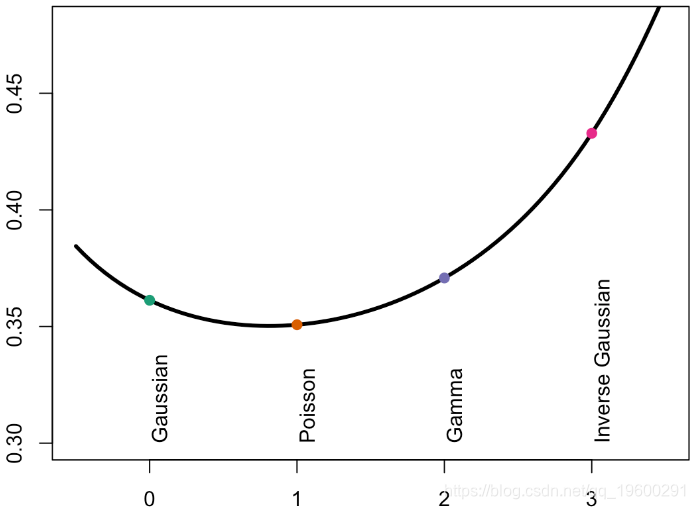
这里的坡度总是非常接近,如果我们添加一个置信区间,则

对于Gamma回归或高斯逆回归,由于方差是预测的幂,因此,如果预测较小,则方差应该较小。因此,在图的左侧,误差应该较小,并且方差函数的功效更高。
plot(Vgamma,Verreur,type="l",lwd=3,ylim=c(-.1,.04),xlab="power",ylab="error")
abline(h=0,lty=2)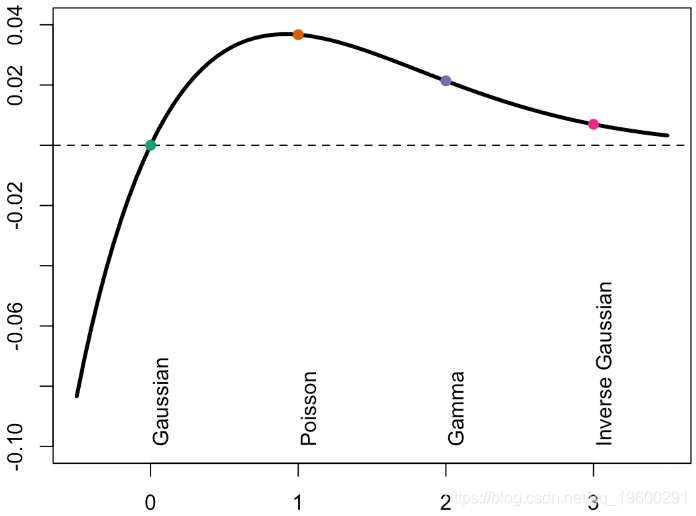
随时关注您喜欢的主题
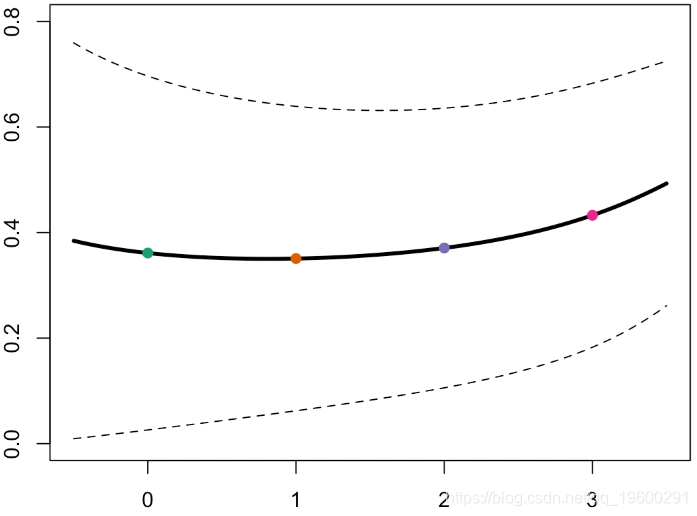
或者,如果我们添加置信区间,我们将获得
当然,我们可以对指数模型做同样的事情
或者,如果我们添加置信区间,我们将获得
因此,这里的“斜率”也非常相似…如果我们看一下在图表左侧产生的误差,可以得出
plot(Vgamma,Verreur,type="l",lwd=3,ylim=c(.001,.32),xlab="power",ylab="error")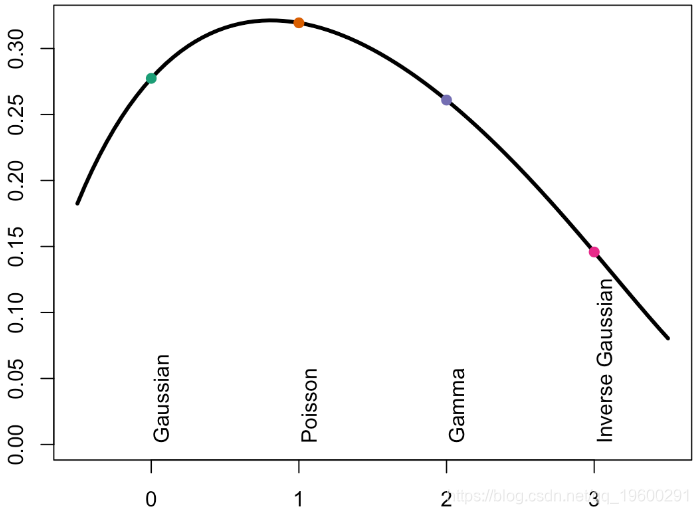
因此,分布通常也不是GLM上最重要的一点。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据
R语言广义加性模型GAM、Tweedie分布的SaaS客户生命周期价值CLV预测研究——非线性关系捕捉与异方差性适配创新|附代码数据 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析
视频讲解|Stata和R语言自助法Bootstrap结合GARCH对sp500收益率数据分析 高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据
高维变量选择专题|R、Python用HOLP、Lasso、SCAD、PCR、ElasticNet实例合集分析企业财务、糖尿病、基因数据



