Python逻辑回归、XGBoost、CNN、随机森林及BP神经网络融合预测二型糖尿病:加权线性回归细化变量及PCA降维创新
在当今慢性病防控领域,二型糖尿病的早期预测成为提升公共健康水平的关键一环。随着医疗数据采集技术的进步,基础信息、生活习惯、心电图以及血液蛋白等多源数据的整合应用,为疾病预测提供了新的可能。

相关的专题项目数据代码文件已分享在交流社群,阅读原文进群和600+行业人士共同交流和成长。
我们团队在为医疗健康机构提供咨询服务时发现,单一数据源往往难以全面捕捉疾病风险特征。比如仅靠生活习惯数据,预测准确率常停留在70%左右;而加入心电图等生理信号后,模型性能能显著提升。基于这个实际需求,我们开展了多模态数据融合预测二型糖尿病的研究。研究通过三个递进式任务展开:先用基础信息和生活习惯数据构建预测模型,再加入处理后的心电图数据提升性能,最后融入血液蛋白数据实现发病时间预测。过程中解决了数据缺失、噪声干扰、特征冗余等实际问题,提出的加权线性回归细化变量和类间PCA降维等方法,有效提升了模型的准确性和稳定性。
技术路线流程图
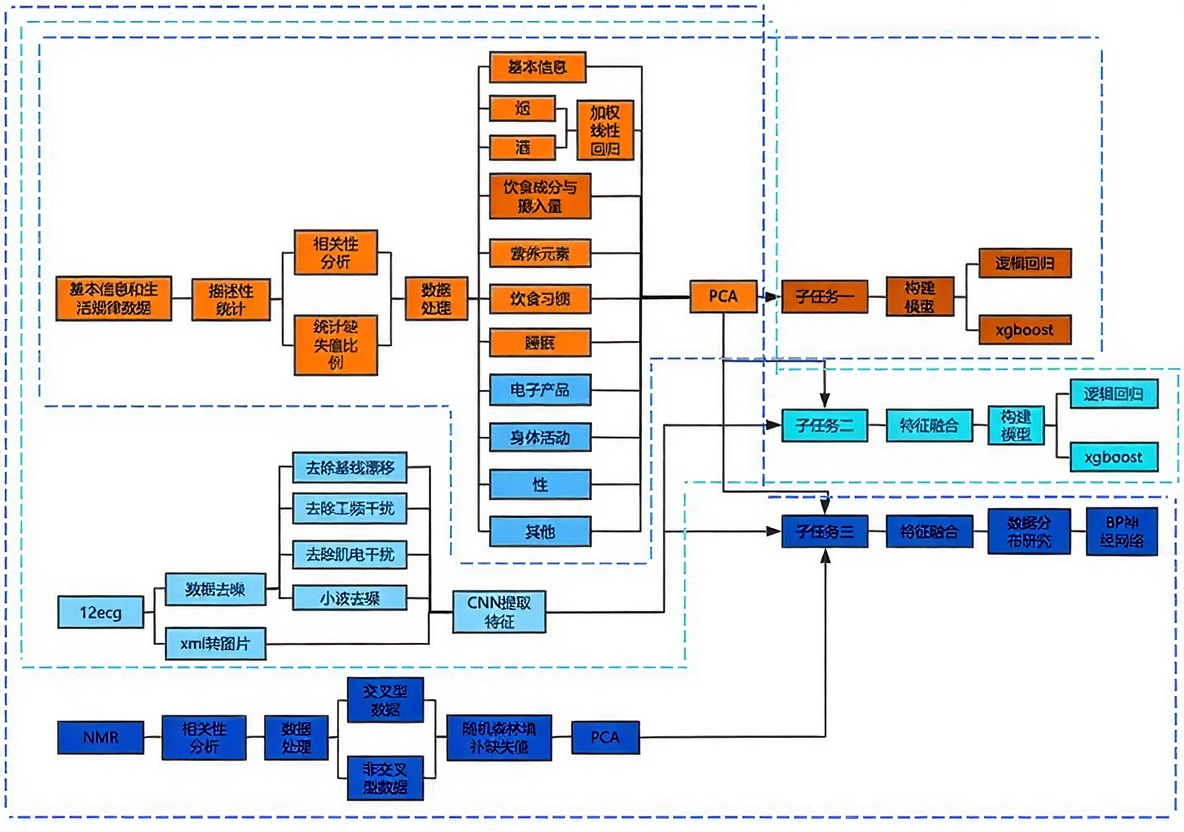
数据与方法
数据来源
研究整合了四类数据:基础信息(年龄、性别等)、生活习惯(吸烟、饮酒等)、12导联心电图(ECG)以及血液蛋白(NMR)数据,总样本量4000例,含健康人群和二型糖尿病患者。
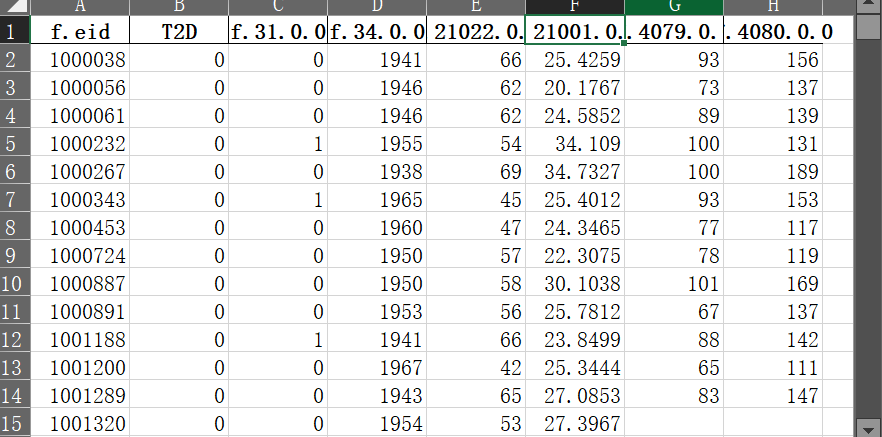
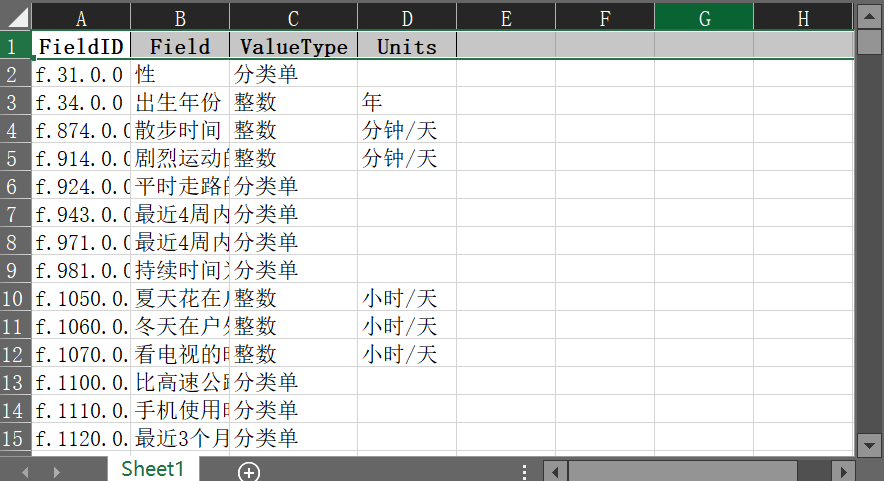
关键方法
- 数据预处理
-
缺失值处理:对吸烟相关等缺失率高的变量,用加权线性回归融合后细化原离散变量值;对NMR数据,用随机森林基于其他数据预测填补缺失值。
-
降噪处理:对心电图数据,依次用巴特沃斯滤波器去除基线漂移和肌电干扰,用IIR陷波滤波器去除工频干扰,最后用离散小波变换处理残留噪声。
-
降维处理:对分类后的变量进行类间PCA降维,减少特征冗余。
- 模型构建
-
逻辑回归:用于二分类任务,公式为P=1/(1+e^-(w0 + w1x1 +…+ wnxn)),其中P为患病概率,w为权重。
-
XGBoost:集成学习模型,通过多棵决策树集成提升性能。
-
卷积神经网络(CNN):用于提取心电图图像特征,含卷积层、池化层和全连接层。
-
随机森林:由多棵决策树组成,用于预测NMR缺失值。
-
BP神经网络:用于预测发病时间,通过前向传播和反向传播优化参数。
实现过程与结果
子任务 1:基础信息与生活习惯数据预测
处理生活习惯数据时,以吸烟情况为例,提取重度吸烟者样本,用加权线性回归融合相关变量:
# 加权线性回归融合吸烟相关变量
import numpy as np
from sklearn.linear_model import LinearRegression
# 准备数据,x为吸烟相关变量,y为目标变量
x = np.array([[10, 2, 30, 5], [15, 3, 25, 4], [8, 1, 35, 6]]) # 示例数据
y = np.array([0.2, 0.5, 0.1])
weights = np.array([0.3, 0.4, 0.3]) # 权重
# 加权处理
x_weighted = x * weights[:, np.newaxis]
model = LinearRegression()
model.fit(x_weighted, y)
fused_feature = model.predict(x_weighted) # 融合后的特征
Python糖尿病数据分析:多种模型优化训练评估选择
本文介绍了使用深度学习、逻辑回归、K近邻、决策树、随机森林、支持向量机等多种算法进行糖尿病数据分析与预测的方法,以及模型优化和评估的全过程。
阅读全文融合后与原吸烟史变量结合,细化离散值。经PCA降维后,分别用逻辑回归和XGBoost建模,结果显示逻辑回归性能更优,AUROC为0.782。
子任务 2:加入心电图数据预测
对心电图数据进行降噪处理,处理前后对比图如下:
原始心电图:
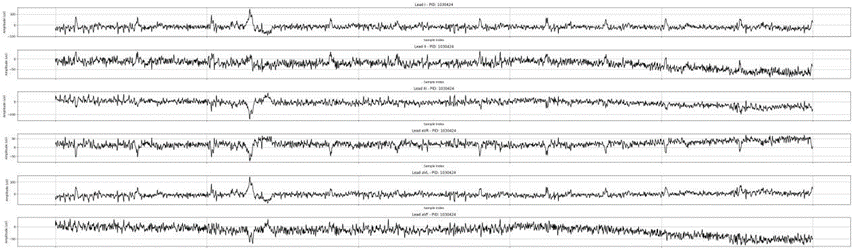
去除基线漂移后:
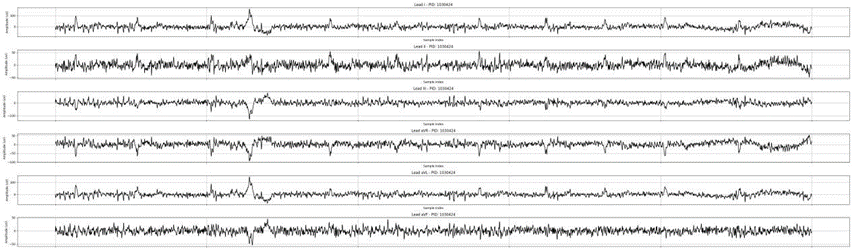
去除工频干扰后:
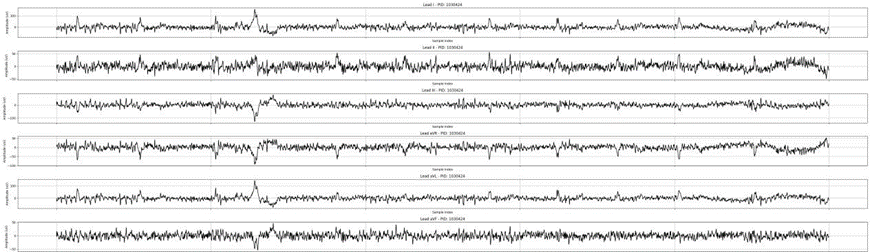
去除肌电干扰后:
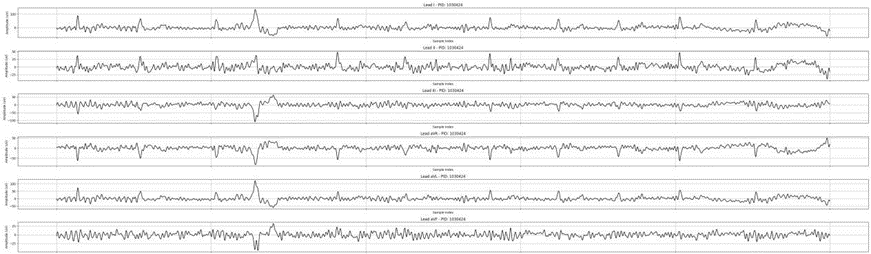
小波去噪后:
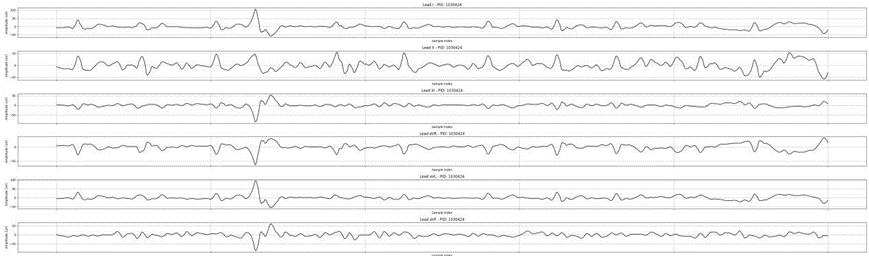
用CNN提取特征后与其他数据融合,代码片段如下:
# CNN提取心电图特征
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
# 构建模型
model = Sequential()
model.add(Conv2D(16, (3, 3), activation='relu', input_shape=(224, 224, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
# 提取特征
features = model.predict(ecg_images) # ecg_images为处理后的心电图图像融合后用XGBoost建模,AUROC达0.97,准确率0.94,优于逻辑回归。
子任务 3:加入 NMR 数据预测发病时间
用随机森林填补NMR缺失值后,经PCA降维,与其他数据融合,用BP神经网络预测发病年龄。模型训练损失和测试损失曲线如下:
训练损失曲线:
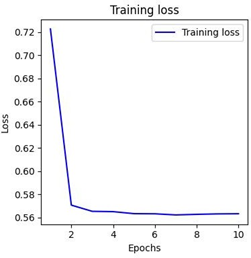
测试损失曲线:
发病年龄分布:
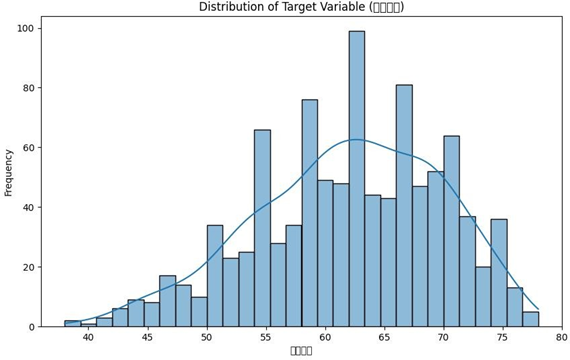
结果显示,模型R²为0.68,PCC为0.79,能较好预测发病时间。
创新点
-
对缺失率高的变量,用加权线性回归融合后细化原离散值,而非直接剔除,保留更多信息。
-
对分类后的变量进行类间PCA降维,针对性处理不同类型数据,提升降维效果。
-
综合多种滤波方法处理心电图噪声,提升数据质量。
-
用随机森林基于已有数据预测NMR缺失值,解决高缺失率问题。
应用价值
研究提出的多模态数据融合方法,能有效提升二型糖尿病预测准确性,为早期干预提供科学依据。模型可集成到医疗信息系统,辅助医生进行风险评估,具有实际应用意义。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 DeepSeek与LangGraph共享单车需求数据预测:LSTM与XGBoost多模型融合方法及Streamlit可视化应用 | 附代码数据
DeepSeek与LangGraph共享单车需求数据预测:LSTM与XGBoost多模型融合方法及Streamlit可视化应用 | 附代码数据 DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据
DeepSeek高维城市经济与宜居度面板数据分析——PGSA寻优、聚类、CNN、ARIMA、GM(1,1)与智能交互|附代码数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据



