本研究旨在利用机器学习和深度学习模型对糖尿病数据进行分析和预测。通过对糖尿病数据集的读取、预处理、特征分析,运用多种机器学习算法如逻辑回归、K近邻、决策树、随机森林、支持向量机以及前馈神经网络等进行模型训练和评估。
比较不同模型在训练集和测试集上的准确率等指标,分析各模型的性能特点,最终为糖尿病的预测提供有效的模型选择和参考依据。
关键词
糖尿病预测;机器学习;深度学习;模型评估
一、引言
糖尿病作为一种常见的慢性疾病,对全球公共卫生造成了巨大的负担。准确地预测糖尿病的发生对于早期干预和治疗具有重要意义。机器学习和深度学习技术在医学数据的分析和预测方面展现出了强大的能力。本研究将运用多种机器学习和深度学习算法对糖尿病数据集进行处理和分析,构建能够准确预测糖尿病的模型。
二、数据获取与预处理
2.1 数据获取
从特定路径读取糖尿病数据集,该数据集包含了多个特征,如怀孕次数(Pregnancies)、血糖值(Glucose)、血压(BloodPressure)、皮肤厚度(SkinThickness)、胰岛素水平(Insulin)、身体质量指数(BMI)、糖尿病家族遗传函数(DiabetesPedigreeFunction)、年龄(Age)以及是否患有糖尿病的结果(Outcome)等信息。

df.shape
检查数据集中是否存在缺失值,结果显示该数据集中没有缺失值。
df.isnull().sum()


想了解更多关于模型定制、咨询辅导的信息?
查看数据集的信息,了解各特征的数据类型,其中大部分特征为整数类型,BMI和DiabetesPedigreeFunction为浮点数类型。
视频
Python深度神经网络DNNs-K-Means(K-均值)聚类方法
视频
【视频讲解】Python深度学习股价预测、量化交易策略:LSTM、GRU深度门控循环神经网络附代码数据
视频
ResNet深度学习神经网络原理及其在图像分类中的应用Python代码
视频
【视频讲解】CatBoost、LightGBM和随机森林的海域气田开发分类研究
视频
从决策树到随机森林:R语言信用卡违约分析信贷数据实例
df.info()

2.3 统计分析
对数据集进行描述性统计分析,获取各特征的统计量,如计数、均值、标准差、最小值、25%分位数、50%分位数、75%分位数和最大值等。
df.describe()

统计患有糖尿病和未患有糖尿病的患者数量,结果显示未患有糖尿病的患者有500人,患有糖尿病的患者有268人,占比分别为65%和35%。

对数据按是否患有糖尿病进行分组,计算各特征的均值。结果表明,糖尿病患者的所有特征均值普遍高于非糖尿病患者,特别是血糖和胰岛素水平,糖尿病患者的值明显更高。

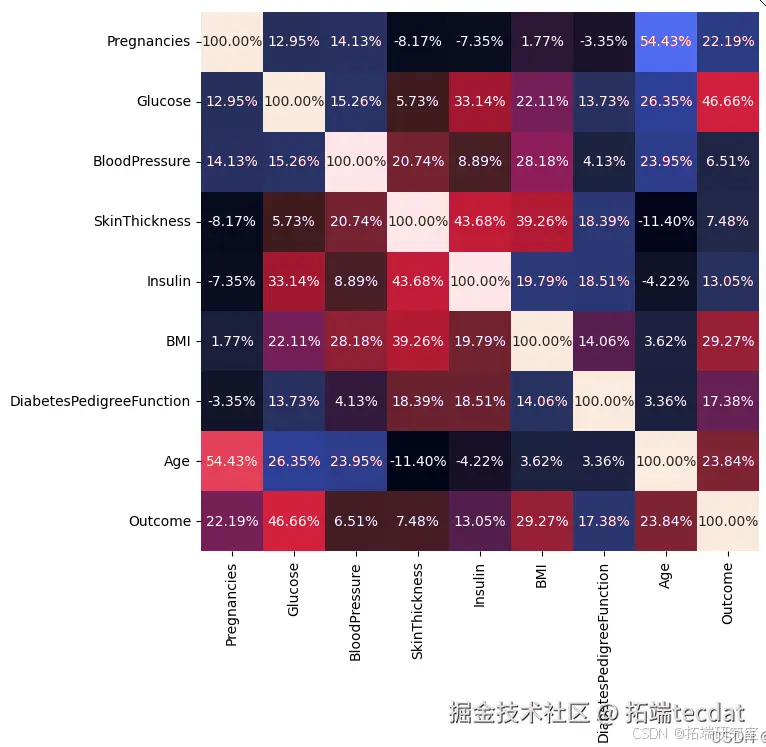
绘制相关系数热图,分析各特征之间的相关性,发现所有特征之间存在中等程度的相关性。
三、数据准备
将数据集的特征和标签进行分离,特征数据存储在变量x中,标签数据存储在变量y中。
x = df.drop(columns='Outcome', axis = 1)
y = df['Outcome']
对特征数据进行标准化处理,使用StandardScaler将数据转换为均值为0,标准差为1的标准正态分布。
scalar = StandardScaler()
scalar.fit(x)

将标准化后的数据划分为训练集和测试集,测试集占比为20%,并设置随机种子为2,以确保结果的可重复性。
四、机器学习模型训练与评估
4.1 逻辑回归模型
使用逻辑回归模型对训练数据进行训练,并对训练集和测试集进行预测。逻辑回归模型在训练集上的准确率为79%,在测试集上的准确率为76%。
lr = LogisticRegression()
lr = lr.fit(train_x, train_y)

4.2 K近邻模型
构建K近邻模型,设置邻居数量为50,对训练数据进行训练和预测。K近邻模型在训练集上的准确率为77%,在测试集上的准确率为73%。

4.3 决策树模型
通过循环找到最优的随机种子,以获得最佳的决策树模型。决策树模型在训练集上的准确率达到了100%,但在测试集上的准确率为73%,存在一定的过拟合现象。

4.4 随机森林模型
构建随机森林模型,设置树的数量为500,并使用最优随机种子。随机森林模型在训练集上的准确率为100%,在测试集上的准确率为73%。
rf = RandomForestClassifier(n_estimators=500, random_state = best_random_state)
rf.fit(train_x, train_y)
rf_train_pred = rf.predict(train_x)
rf_test_pred = rf.predict(test_x)
print("Random Forest Training Accuracy: ", round(accuracy_score(train_y, rf_train_pred), 2)*100)
print("Random Forest Testing Accuracy: ", round(accuracy_score(test_y, rf_test_pred), 2)*100)

4.5 支持向量机模型
使用支持向量机模型,核函数选择线性核。支持向量机模型在训练集上的准确率为78.66%,在测试集上的准确率为77.27%。
classifier = SVC(kernel = 'linear')
classifier.fit(train_x, train_y)
print("SVM Training Accuracy: ", round(classifier.score(train_x, train_y)*100, 2))
print("SVM Testing Accuracy: ", round(classifier.score(test_x, test_y)*100, 2))

随时关注您喜欢的主题
history = model.fit(train_X, train_y, epochs=50, batch_size=32, validation_data=(test_X, test_y))
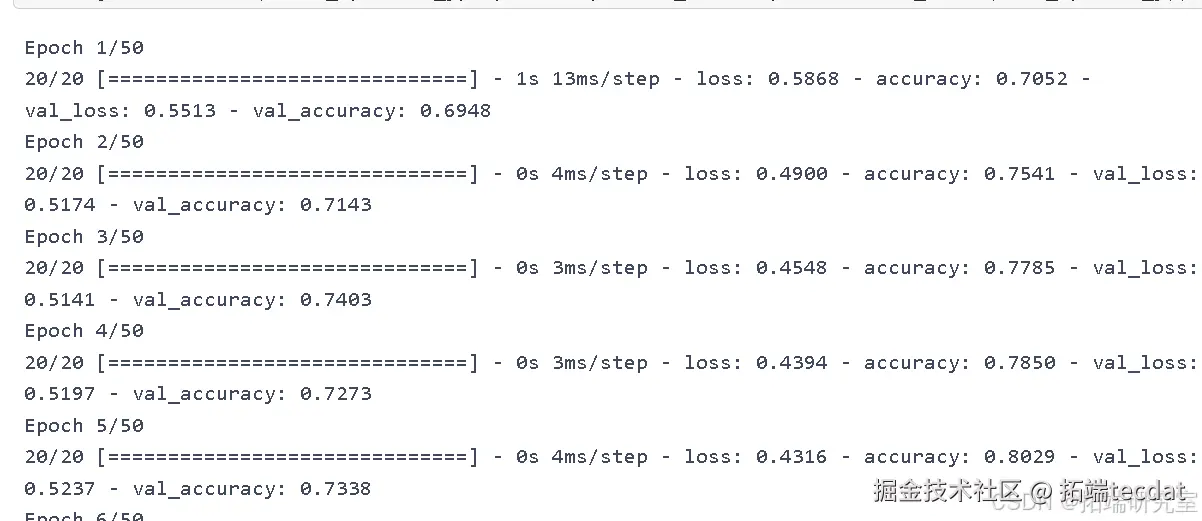

经过优化后的模型,在训练集上的准确率为80.46%,在测试集上的准确率为75.32%,过拟合现象得到了一定程度的缓解。

六、模型应用与结果可视化
将训练好的随机森林模型保存,以便后续使用。对新的输入数据进行预测,判断该患者是否患有糖尿病。
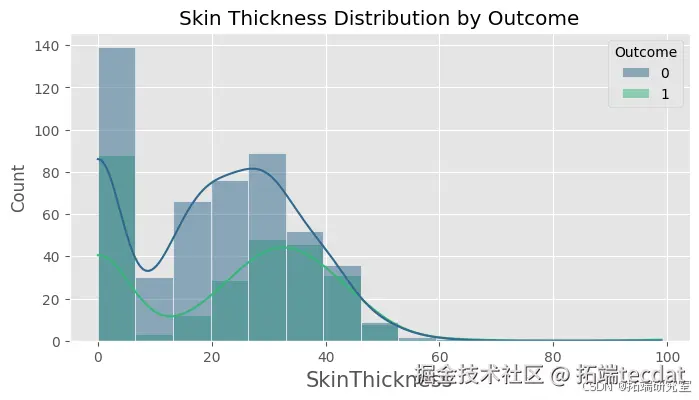
绘制各特征按是否患有糖尿病的分布直方图,直观地展示不同特征在糖尿病患者和非糖尿病患者中的分布情况。
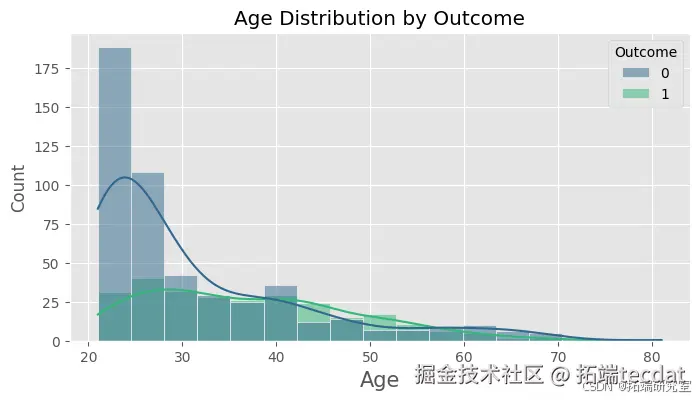
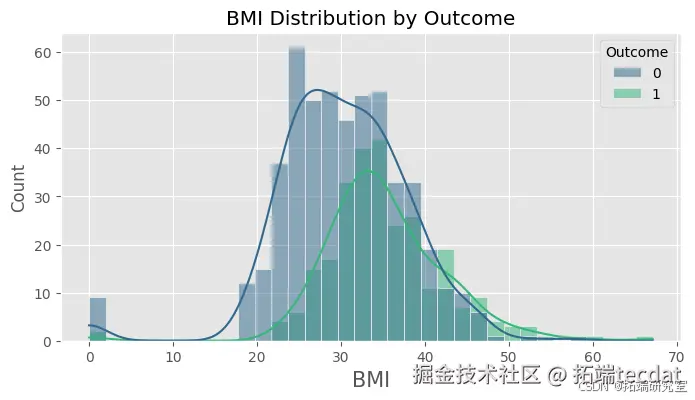
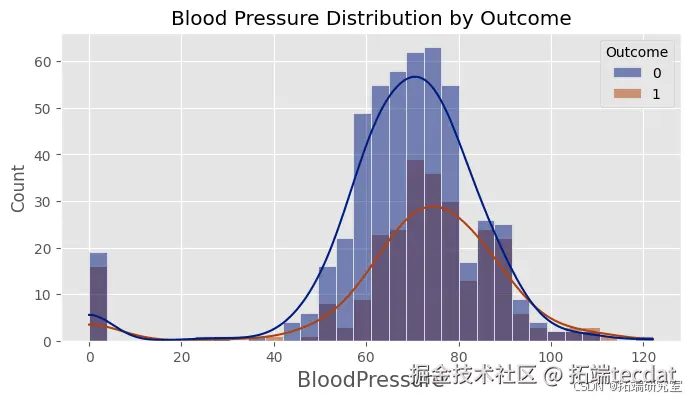
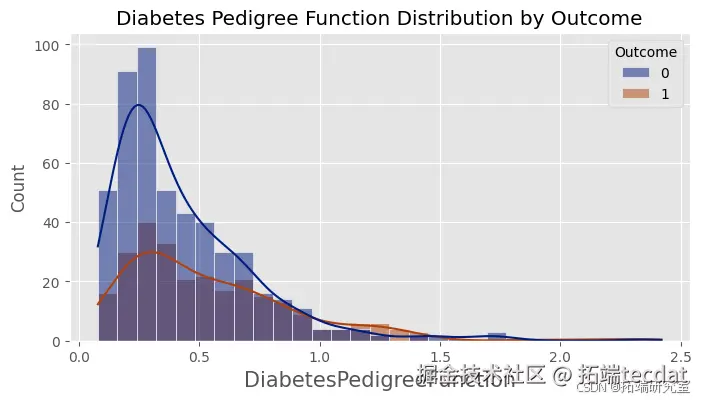
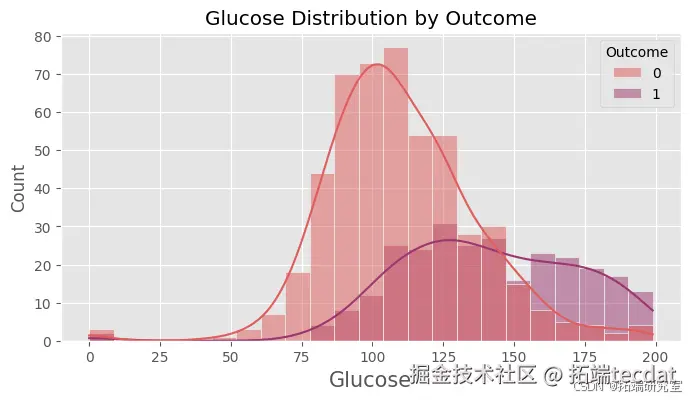
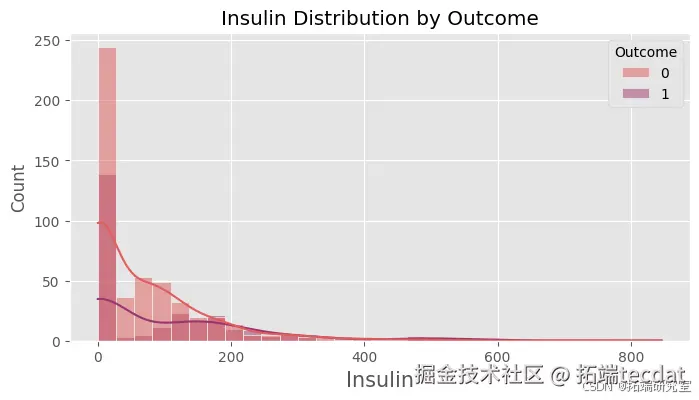
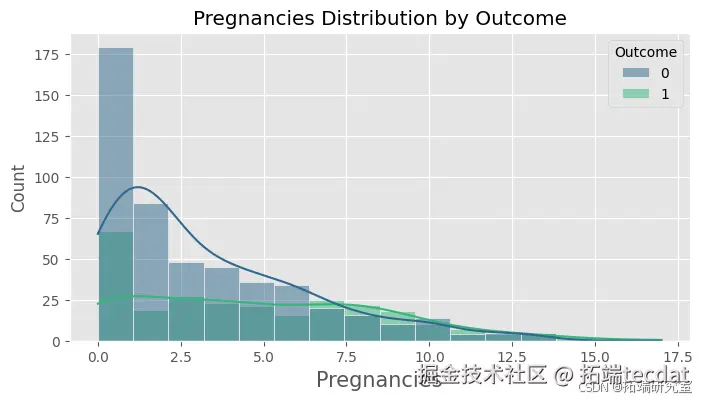
绘制随机森林模型在测试集上的混淆矩阵,计算精确率、召回率和F1值等指标,进一步评估模型的性能。
绘制随机森林模型在测试集上的混淆矩阵,计算精确率、召回率和F1值等指标,进一步评估模型的性能。
复制代码cf_matrix = confusion_matrix(test_y, rf_test_pred)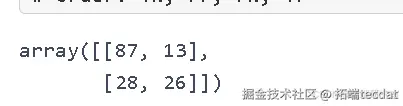
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码 Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据
Python信贷冷启动信用风险评估:WOE编码、IV筛选、代价敏感学习与逻辑回归稀疏样本建模 | 附代码数据

