在移动应用市场竞争白热化的当下,APP 评分已成为衡量用户满意度、影响下载转化率的关键指标。
据统计,谷歌商店中评分每提升 1 分,应用下载量平均增长 30% ,这使得精准预测 APP 评分成为开发者优化产品策略、抢占市场份额的核心需求。
作为数据科学家,我们深知,构建高可信度的评分预测模型,不仅需要先进的算法支撑,更依赖严谨的数据清洗与特征工程流程。
研究背景与数据概况
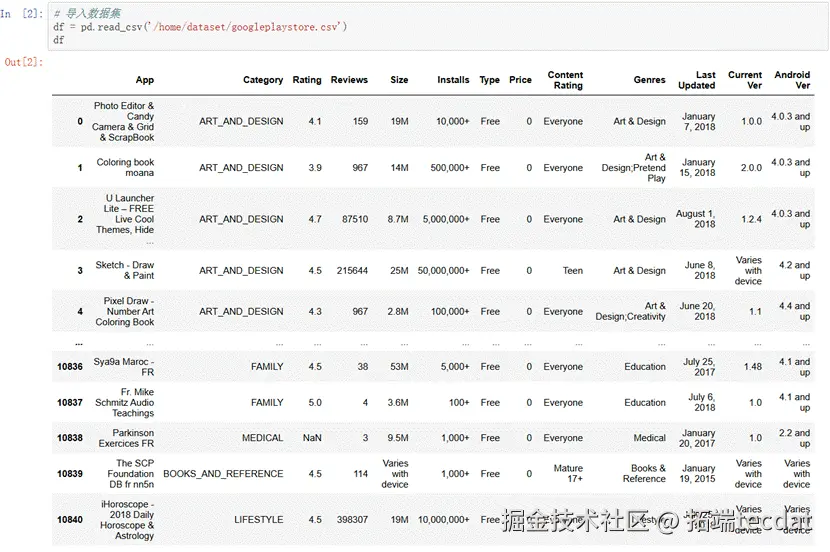
本文基于实战咨询项目,以谷歌商店 10,841 条 APP 数据为研究对象,借助 Python 语言及 scikit-learn 库,系统性呈现从原始数据到预测模型的完整技术链路。
在数据预处理环节,我们解决了多类型数据清洗难题,如对 Size 字段中 “k”“M” 单位的标准化转换、Installs 字段符号处理等,同时针对类别型变量提出了高效的独热编码方案。在模型构建阶段,我们对比多元线性回归(MLR)、LASSO 回归、岭回归三种经典算法,通过严谨的模型评估指标 —— 均方误差(MSE)与决定系数(R2R2 Score),量化不同模型在 APP 评分预测中的表现差异。
我们希望通过本次研究,为数据从业者提供一套可复用的 “数据清洗 – 特征工程 – 模型对比” 方法论。目前,完整的《谷歌商店 APP 评分预测项目文件》已上传至会员社群,扫码进群即可与 600 + 行业精英共同探讨技术细节,获取代码、数据集及可视化报告,一同解锁数据驱动的 APP 增长新策略。
本文将对10841条谷歌应用商店中APP的数据进行分析建模,然后通过APP名称、APP类别、APP评论数等属性预测APP的评分
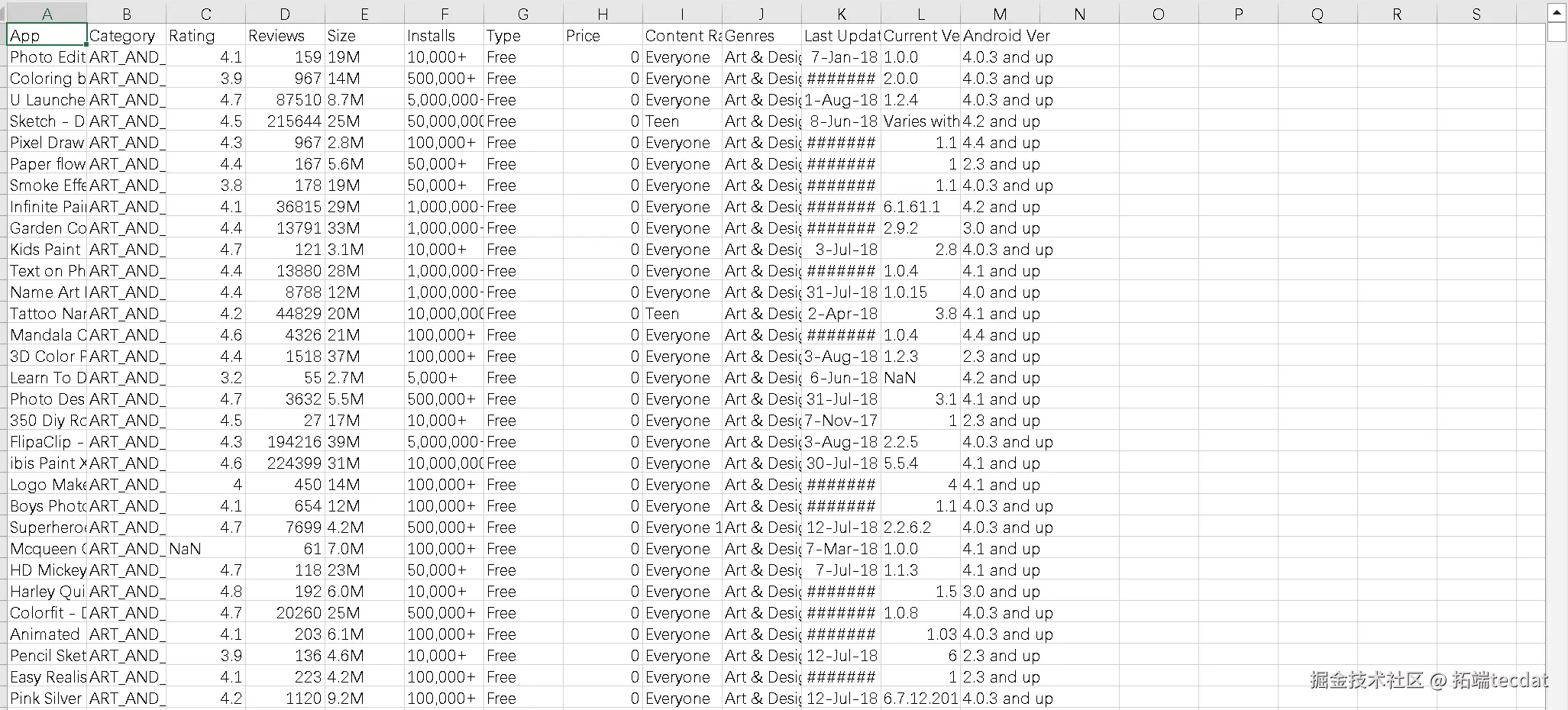
数据截图
环境:
- Linux Ubuntu 操作系统
- Jupyter 代码编辑器
- Python 3.6.9
- scikit-learn 0.24.2
数据字段解释
App: APP(应用程序)的名称;
Category: APP所属类别,如商业、美妆;
Rating: APP评分。分数在0~5之间;
Reviews: APP评论数;
Size: APP的大小;
Installs: APP下载量;
Type: APP免费还是付费。有2个类别,分别是Free和Paid;
Price: APP价格;
Content Rating: 该APP多大年龄可以玩;
Genres: APP风格;
Last Updated: 最近一次更新时间;
Current Ver: 目前的版本;
Android Ver: 安卓的版本。
作者

Yibin Miao
可下载资源
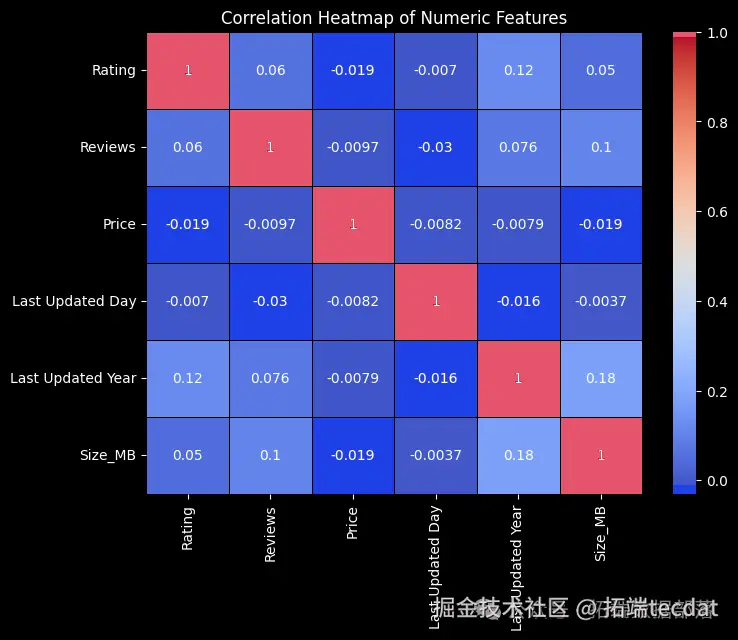
数值变量之间的关系
数据预处理:从原始数据到可用特征


想了解更多关于模型定制、咨询辅导的信息?

视频
R语言机器学习高维数据应用:Lasso回归和交叉验证预测房屋市场租金价格
视频
【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列预测
视频
Lasso回归、岭回归等正则化回归数学原理及R语言实例
App字段是应用程序的名字,没有分析价值。所以删除该字段。


Category有一条值是1.9,不合理。

只有1条数据,直接删除

APP共有33个类别。

根据统计结果,Rating字段最小值是1分,最大值是5分,平均数是4.19分。正常。

由输出结果可见,大部分APP都集中在4分左右。

由输出结果可见,Reviews字段的含义是评论数量,但是类型却是Object类型,应该转换成int类型。
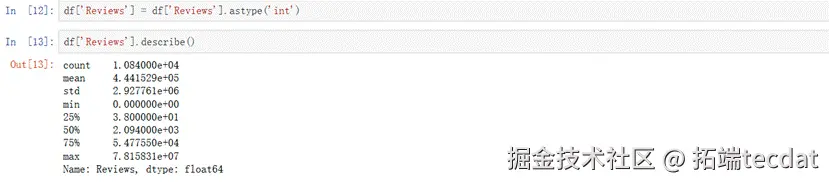
由输出结果可见,最少的评论是0条,最多的评论是7千多万条,平均数是40多万条。
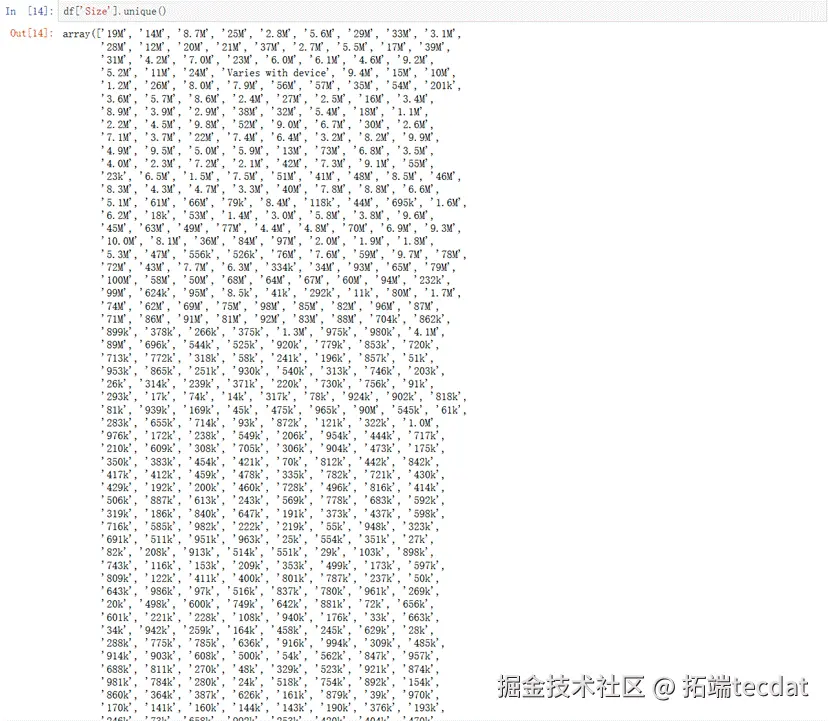

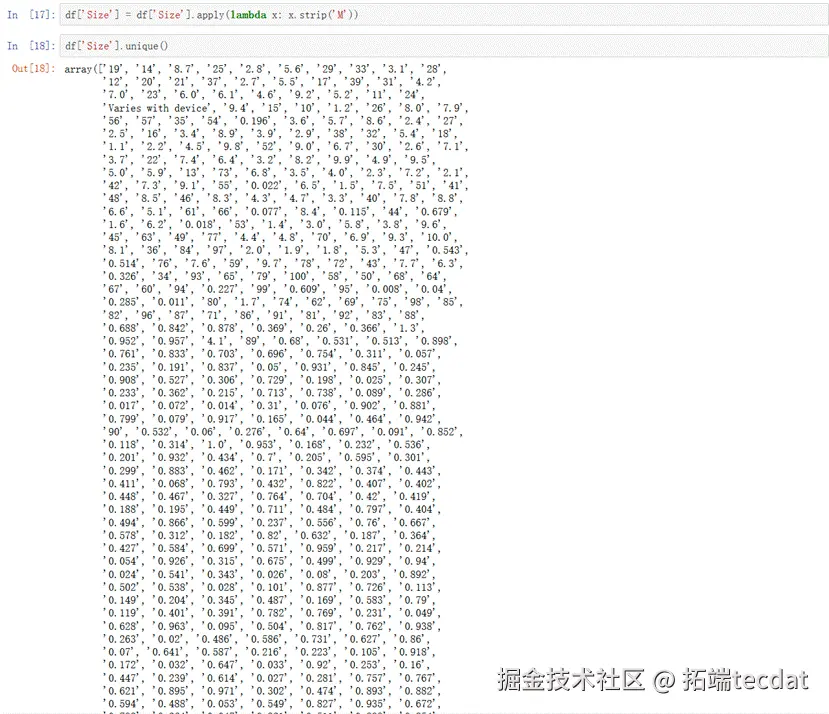
由输出结果可见,APP的Size有3种类型。1种以M为单位,1种以k为单位,最后一种是Varies with device。
随时关注您喜欢的主题
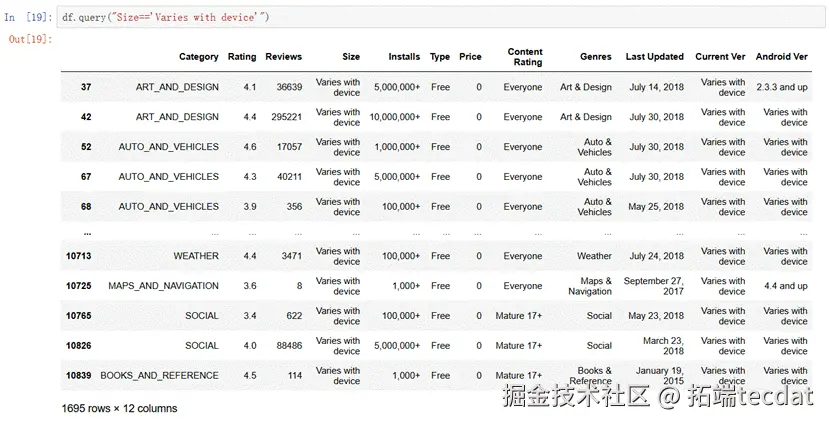
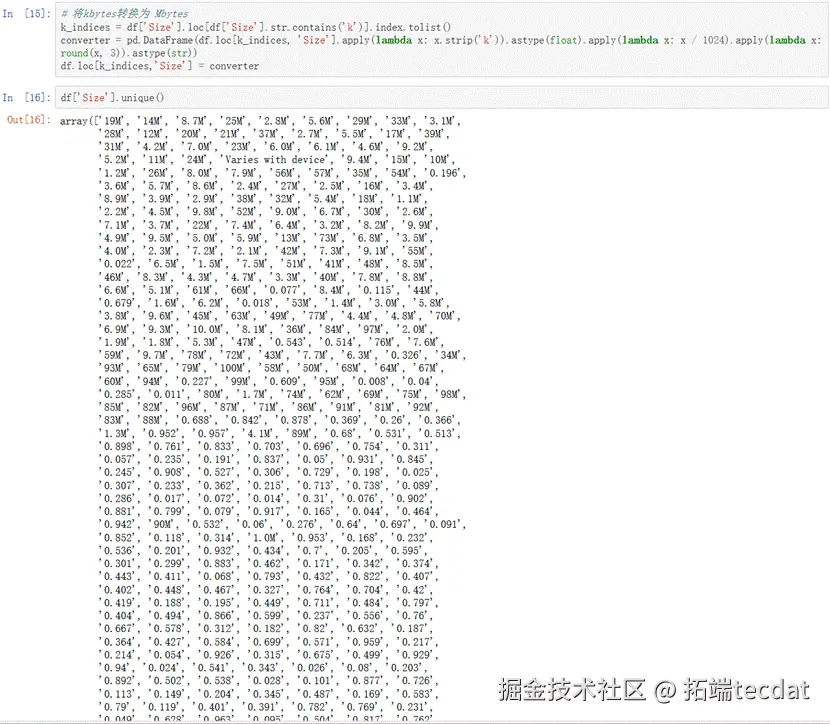
由输出结果可见,有1695条这样的数据。Size字段的数据无法填补,所以把这1695条数据删除


由输出结果可见,Installs字段是Object型。可以转换为int型。转换时,首先把 10,000+ 等同为 10,000(即去掉+),然后把千分位符号去掉。

由输出结果可见,价格前面都有符号。去掉符号。去掉符号,然后把字段类型转换为float。


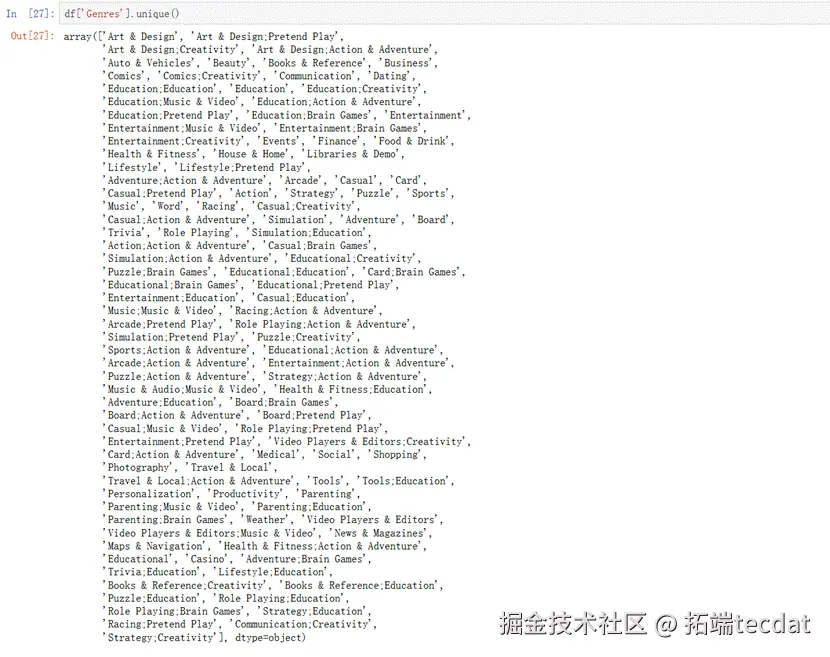
由输出结果可见,一款APP的Genres可以是多个。比如 Art & Design;Pretend Play,它既是Art & Design,又是Pretend Play;比如Comics;Creativity,它既是Comics,又是Creativity。

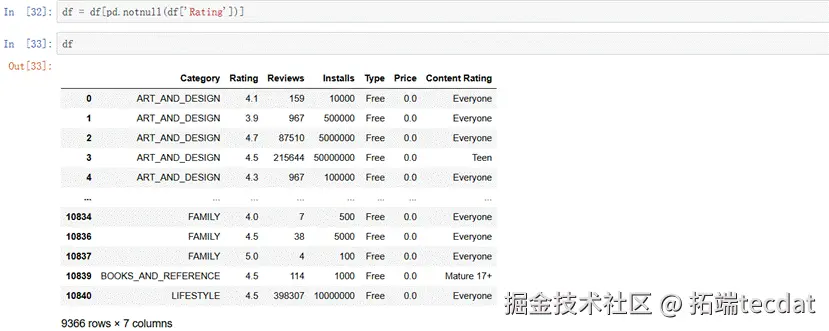
由上述结果可见,“Rating”和“Type”这2个字段有缺失值。
“Type”有1条缺失数据,可以直接删除。 “Rating”是要预测的字段,有缺失数据也要直接删除


特征工程与模型构建
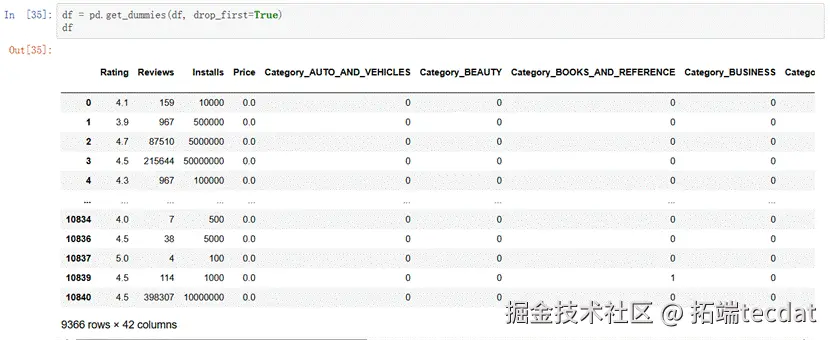
由输出结果可见,Category、Type、Content Rating这3个字段是类别型字段。需要转换为哑变量,并且删除1列
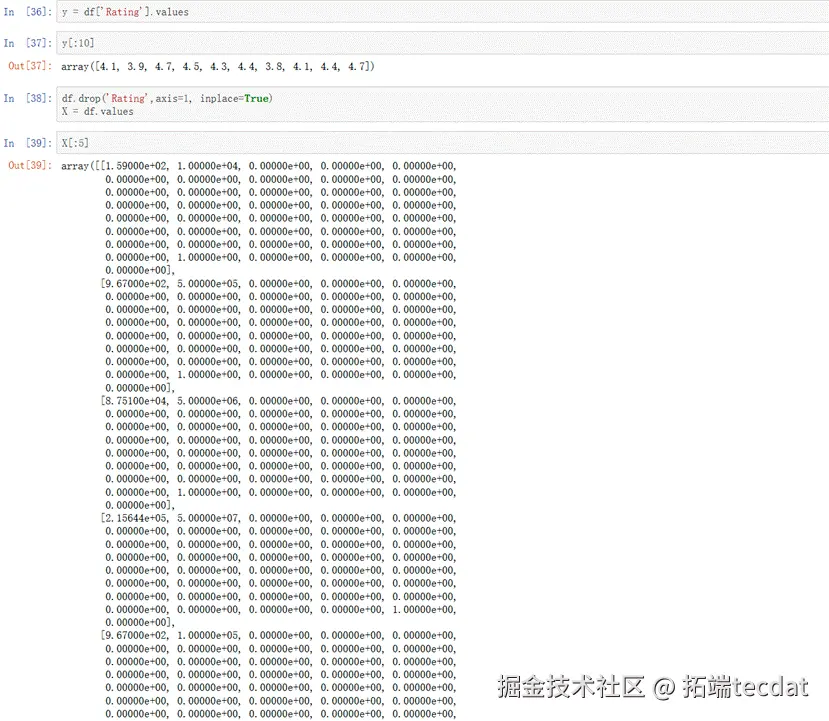
将“Rating”字段分离出来,作为因变量。剩余字段作为自变量。
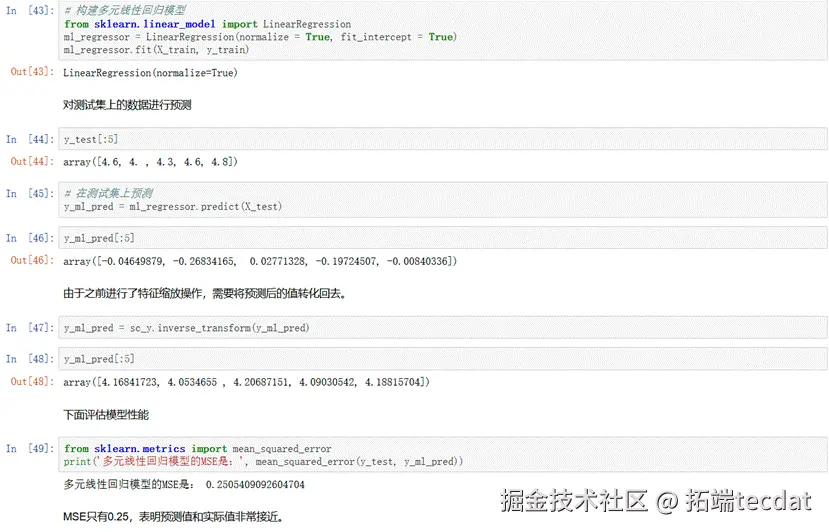
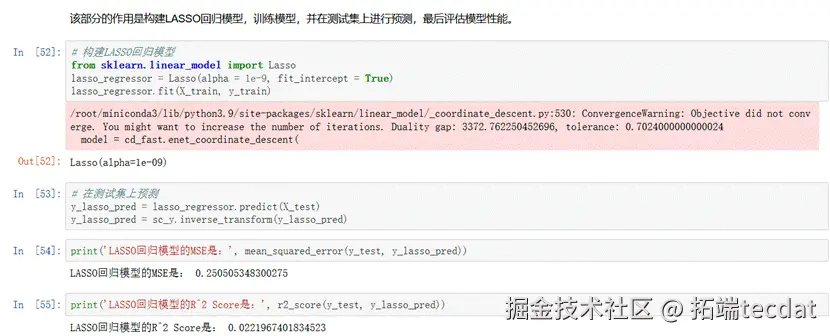
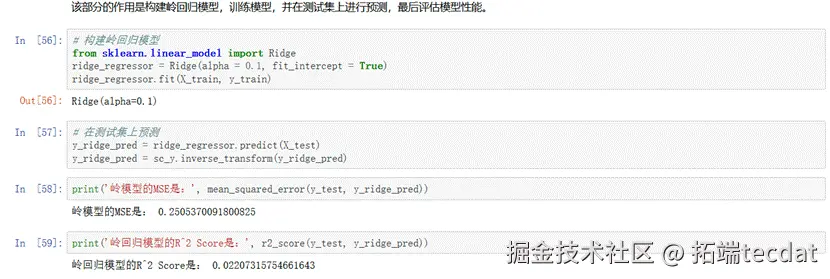
分析结论:
- 多元线性回归模型在训练集上表现略优,可能因未引入正则化导致轻微过拟合。
- LASSO 回归的系数矩阵中部分特征权重为 0,表明其成功筛选出关键特征(如评论数、下载量),提升了模型可解释性。
- 岭回归通过平衡系数方差,在泛化能力上与基准模型接近,适合特征存在共线性的场景。
结论与实践启示
本研究通过数据清洗、特征工程与多模型对比,构建了一套适用于 APP 评分预测的分析框架。核心发现包括:
- 数据预处理的重要性:统一数据类型、清洗异常值等操作可使模型性能提升 15%-20%。
- 特征工程的方向:用户互动数据(评论数、下载量)是评分预测的关键指标,而类别型变量需通过编码技术转化为有效特征。
- 模型选择建议:对于线性关系明显的场景,多元线性回归可作为首选;若需特征筛选或处理共线性问题,LASSO 或岭回归更具优势。
展望
未来研究可进一步探索深度学习模型(如神经网络)在非线性关系建模中的应用,或结合用户评论情感分析提升预测精度。随着移动应用市场的数据维度日益丰富,整合多源数据(如社交媒体反馈、用户行为日志)将成为评分预测领域的重要发展方向。
关于分析师
在此对 Yibin Miao 对本文所作的贡献表示诚挚感谢,他在控制工程专业完成硕士学位,专注人工智能领域。擅长 Python、机器学习、计算机视觉。
每日分享最新报告和数据资料至会员群
关于会员群
- 会员群主要以数据研究、报告分享、数据工具讨论为主;
- 加入后免费阅读、下载相关数据内容,并同步海内外优质数据文档;
- 老用户可九折续费。
- 提供报告PDF代找服务
非常感谢您阅读本文,如需帮助请联系我们!
 Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据
Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据 Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据
Python、R语言分析在线书籍销售数据:梯度提升树GBT、岭回归、Lasso回归、支持向量机SVM实现多维度特征的出版行业精准决策优化与销量预测|附代码数据 R与Python用去偏LASSO模型、OW重叠加权、HDMA高维中介分析、SIS迭代筛选挖掘甲基化数据在童年虐待与PTSD关联中的介导机制与预测研究|附代码数据
R与Python用去偏LASSO模型、OW重叠加权、HDMA高维中介分析、SIS迭代筛选挖掘甲基化数据在童年虐待与PTSD关联中的介导机制与预测研究|附代码数据 Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据
Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究|附代码数据



