在这篇文章中,我想介绍 现代 投 资组合理论 (MPT)_、 _有效边界 以及它对投资组合构建的一些影响。
我对如何设计和构建投资组合非常感兴趣。
尽管 现代投资组合理论 有其局限性,但它仍然很好地介绍了投资组合构建和投资组合理论。
第一部分将简要回顾理解_MPT_ 及其含义 所需的一些数学和概念 。
第二部分 将讨论 MPT 和 _有效边界_。
第三部分 将深入探讨使用真实市场数据的 Python 实现。我将在这部分博客中使用我之前构建的数据仓库
第一部分
让我们讨论投资组合收益、投资组合标准差、相关性和夏普比率。 现代投资组合理论 建立了一种构建组合资产组合的方法,因此我们将在相同的背景下定义这些概念。
让我们使用具有以下标准的虚构投资组合:
- 我们的投资组合包含三个资产:A、B 和 C。
- 每个持股在我们的投资组合中的权重相同(每个 33%)。
- 持股 A、B 和 C 的期望收益率分别为 5%、8% 和 10%。
投资组合收益
要计算投资组合的期望收益,我们只需将每只股票的期望收益乘以它们在我们投资组合中的权重,然后将所有部分相加。在这种情况下,我们的权重总和为 1.0,期望收益将代表一个百分比。
可下载资源
作者

使用我们虚构投资组合的信息:

投资组合标准偏差——又名投资组合风险或波动率
人们会认为计算投资组合标准差与投资组合收益相同,但这就是 _现代投资组合理论_的一些魅力所在 。
投资组合标准差不是每只股票的风险权重乘以其权重的总和,还必须考虑每只股票与所有其他股票的相关性。
让我们用符号’σ’_表示标准偏差 ,将两种资产之间的相关性表示为 ‘ _Corr(x,y) ‘ 并将权重表示为 _’w’_。
在三资产组合中,我们将按如下方式计算投资组合标准差:


上面的公式看起来很简单。
如果我们在我们的投资组合中引入第四种资产,即资产“D”,我们将简单地扩展我们的公式:

相关性
我不会深入研究如何计算相关性,但我确实想讨论它如何影响个别证券。
随时关注您喜欢的主题
在两个资产的简单例子中,x和y,相关性将衡量资产y相对于资产x的变化程度,这个衡量标准可以是正的或负的,范围从-1.0到+1.0。
两种资产的相关公式将产生一个相关系数(也被称为 “r”),这个数字是一个数值,将告诉我们两种资产之间的关系有多强。
-0.8 相关性意味着每次“ x” 增加 1 元,“ y” 将减少 0.80 元。对于 +0.80 的相关性,情况正好相反。0.0 的相关性告诉我们,两种资产之间没有任何线性关系。
夏普比率
我想介绍 夏普比率 ,因为在接下来的工作中,我们将尝试分离出 _夏普比率_最高的投资组合。
该比率为我们提供了如何比较具有不同收益和风险的不同投资组合的基础。
为了计算 夏普比率, 我们将投资组合收益减去无风险利率,然后除以投资组合的 标准差 。
想象一下以下两个投资组合:
- 投资组合 A:期望收益率为 10%,投资组合标准差为 5%。
- 投资组合 B:期望收益率为 15%,投资组合标准差为 10%。
哪个投资组合更好?

尽管投资组合 B 具有更高的期望收益,但如果我们根据投资组合风险比较这些投资组合,实际上是投资组合 A 具有更好的“风险调整后”收益。
他的理论基于以下关于投资者的假设:
第二部分
现代投资组合理论
1952 年,Harry Markowitz 博士撰写了题为“投资组合选择”的论文。
- 每个投资者的目标都是在给定的风险水平下最大化收益。
- 通过个别的、不相关的证券使投资组合多样化,可以降低风险。
- 所有投资者都可以使用相同的信息。
当时,投资者主要围绕期望收益建立投资组合。Markowitz 解释说,通过结合低相关风险资产,可以实现比单独持有一项资产更好的整体投资组合,或者比简单地选择具有最高期望收益的股票更好。
Markowitz 的整个论文将相关性纳入投资组合构建中。这允许使用高风险和低相关资产构建投资组合,同时与单独拥有每个单独的证券相比,为投资者提供整体较低的投资组合风险!
什么被认为是“更好”的整体投资组合?
“_更好_”的投资组合被定义为在给定风险水平下最大化收益的投资组合。风险被定义为我们在 第一部分中介绍的投资组合标准差。
根据现代投资组合理论建立投资组合
要建立基于 _MPT_的投资组合,投资者需要以下数据:
- 资产的期望收益,E(r)。
- 资产的标准差,σ
- 资产与投资组合中持有的其他资产的相关性,corr(X,Y)
使用上述数据,我们可以为每种资产随机分配不同的权重,并计算该特定投资组合的收益和标准差。
投资组合示例
在下图中,您会发现 50,000 个不同的投资组合,由四种股票组成:股票代码分别为:NOC、AAPL、MSFT、MMM。底轴(x 轴)是投资组合的计算风险(_标准差_),左轴(y 轴)是投资组合的期望收益。
每次随机生成投资组合时,它都会为我们的四只股票中的每一种分配不同的权重,然后计算投资组合的收益和标准差。
通过运行 50,000 次随机模拟,我们可以看到一个看起来像子弹形状的图。我们生成如此多的投资组合的原因是,我们可以尝试找到最优的投资组合权重,从而在给定的风险水平下最大化我们的收益。
每次我们生成一个随机投资组合时,每只股票的权重都会发生变化。在某些投资组合中,苹果可能占投资组合的 20%、投资组合的 75% 甚至是投资组合的 1%,对于我们资产组合中包含的所有其他股票也是如此。但是,所有权重的总和始终等于 1。
这是一张图表,说明了 50,000 个随机生成的投资组合:
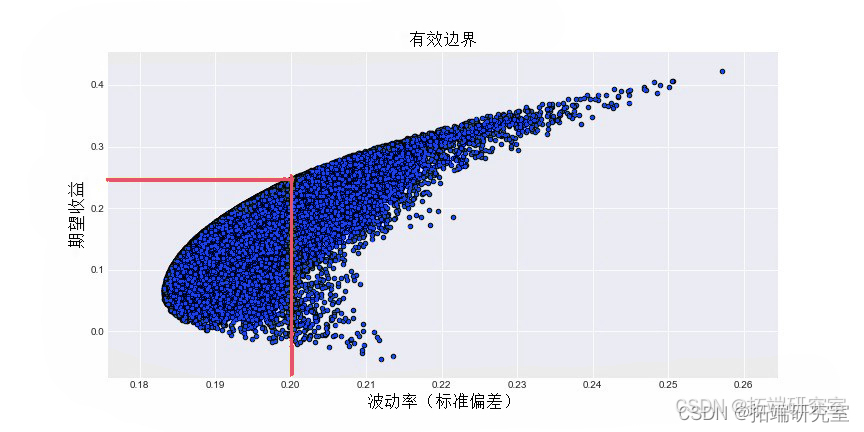
x 轴:投资组合波动率(风险),y 轴:投资组合收益
为了进一步说明我们的示例,假设在我们生成的 50,000 个随机投资组合中,投资者想要风险不超过 20% 的投资组合(垂直绘制在 x 轴上的 0.20 标记处)。位于这条线右侧的所有投资组合都将被忽略,位于这条线左侧的所有投资组合都是可接受的投资组合。
在 0.2 处绘制黄线时, _MPT _推测投资者会选择在这条线上具有 最高 收益的投资组合。在这种情况下,这将是我们的两条线相交的地方。_应该_根据 _MPT _选择精确的投资组合,以使所选风险 水平 的收益最大化 。
对于给定的投资组合风险水平,在我们曲线的顶部边缘最大化收益的所有其他投资组合呢?
进入有效边界
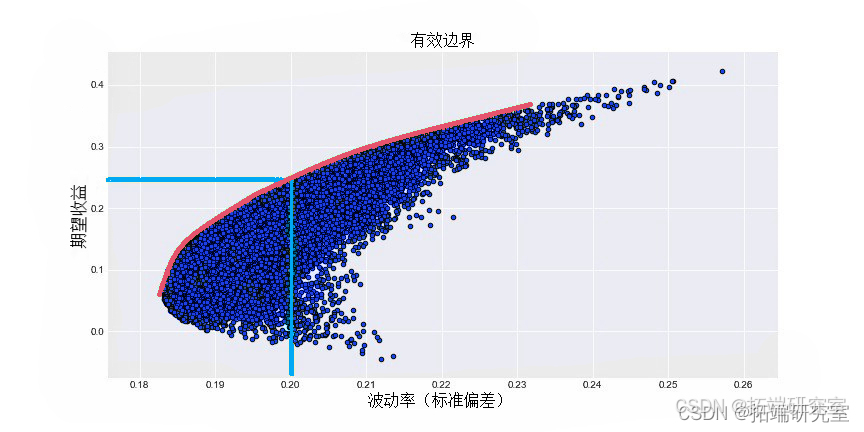
有效边界是一条在每个风险水平上都遵循最高收益的曲线。在下图中,有效边界是红色曲线。
根据 _MPT_的说法,除了沿着这条曲线找到的投资组合之外,任何投资者都不应该投资于投资组合。
第三部分
Python 实现
现在让我们回顾一下这个实现中使用的一些 Python 代码,并尝试生成一些新的有效边界。
于以下代码,使用以下规范创建一个 pandas 数据_框“dta”_ :
- dfta:每列是个股的价格,按日期排序。就我而言,数据框的索引是参考日期。
import seaborn as sns# 生成我们市场数据的每日收益率 dans = df_mage()# 生成我们每日收益率的相关矩阵df tns.corr()# 使用seaborn生成一个热图 heatmap(corre)
上面的代码将生成一个漂亮的表格来可视化每只股票的相关性。在 第一部分中,需要相关性来计算投资组合标准差。
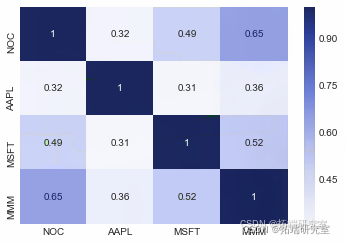
相关性热图
下面是用于生成我们的有效边界图和 50,000 个随机投资组合的代码。
col = coy * 252for sio in range(nuos):
利润率=收益率/波动率
pots.append(reuns)
potity.append(votty)
stts.append(eihs)# 每个投资组合的收益和风险值
portfolio = {'Returns': orttrns,
'Volatility': potvtilty,
'夏普比率': shp_tio}。
# 数据框架
df = pd.DataFrame
# 为所需的列的安排获得更好的标签
df = df\[cm_der\]
现在,为了生成一个漂亮的有效边界图,让我们找到夏普比率最高的投资组合和波动率最低的投资组合。
ma\_a\_row = df.iloc\[df\['夏普比率'\].idxmax()\] 。 maxhr\_TN = mashrow\_\['收益率'\] maha\_VOL = m\_hae\_o\_\['Volatility'\] plt.scatr plt.corar(label='夏普比率') plt.scaer(ma\_p\_OL, axhpTN, c='red', s=50) plt.sow()

上方点:夏普比率最高的投资组合,下方点:波动率最低的投资组合。
我们对 50000 个随机生成的投资组合进行了很好的可视化,并带有两个额外的点。回想一下,上方的点代表具有最高夏普比率的投资组合,而下方的点代表我们具有最低风险(波动性)的投资组合。
让我们检查一下从我们最初的四只股票中产生这些投资组合的权重。
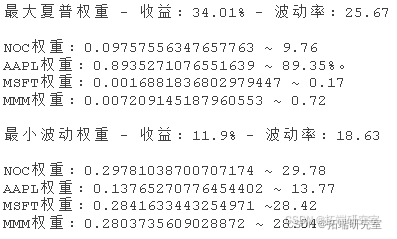
结论
_MPT _的主要限制之一是它使用历史(过去)数据。根据历史收益、相关性和风险(标准差)创建投资组合,并不能保证未来看起来是一样的。
然而,MPT确实为我们提供了一些非常有用的好处,如资产配置、多样化和投资组合再平衡。
- 资产配置 允许投资者根据他们的年龄和财务目标设定一定的风险。
- 多元化 有助于评估高风险、低相关性资产作为一个整体投资组合,并以易于理解和评估的方式(风险和收益)。
- 投资组合再平衡 为投资者提供路线图,以定期审查其当前的投资组合,并在需要时帮助重新调整头寸。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程
llama的Qwen3.5大模型单GPU高效部署与股票筛选应用|附代码教程 R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据
R语言优化沪深股票投资组合:粒子群优化算法PSO、重要性采样、均值-方差模型、梯度下降法|附代码数据 Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别
Python可口可乐股票交易数据分析:KMeans-RF-LSTM多模型融合聚类、随机森林回归价格预测与交易模式识别 DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测股票NFLX涨跌|附完整代码数据
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测股票NFLX涨跌|附完整代码数据
