KNN是一种非参数学习算法,这意味着它不会对底层数据做出任何假设。
这是一个非常有用的特性,因为大多数客户的数据并不真正遵循任何理论假设,例如线性可分性,均匀分布等等。
何时应使用KNN?
可下载资源
假设您想要租一间公寓并最近发现您的朋友的邻居可能在两周内将她的公寓出租。由于该公寓尚未出现在租赁网站上,因此您如何尝试估算其租金?
假设您的朋友每月支付1,200的租金。则您的租金价值可能约为该数字,但是公寓并不完全相同(方向、面积、家具质量等),因此如果有更多其他公寓的数据将会很好。
通过询问其他邻居并查看同一建筑物上的租赁网站列出的公寓,最接近的三个邻居公寓的租金分别为1,200、1,210、1,210和1,215。这些公寓在您朋友的公寓所在街区和楼层上。
视频
K近邻KNN算法原理与R语言结合新冠疫情对股票价格预测
视频
检测异常值的4种方法和R语言时间序列分解异常检测
在同一楼层但不同街区的其他公寓的租金分别为1,400、1,430、1,500和1,470。它们似乎更昂贵,因为晚上有更多的阳光。
考虑到公寓的接近性,估计您的租金应该约为1,210。这就是K-最近邻(KNN)算法的一般思想!
Scikit-Learn住房数据集
我们将使用住房数据集来说明KNN算法的工作原理。该数据集源于1990年的人口普查。数据集的一行代表一个街区的普查。
街区组是人口普查局发布样本数据的最小地理单位。除了街区组之外,还有一个术语是家庭,家庭是住在同一所房子里的一群人。
该数据集包含九个属性:
MedInc– 每个街区的收入中位数。HouseAge– 每个街区的房屋年龄中位数。AveRooms– 每户人家的平均房间数量。AveBedrms– 每户人家的平均卧室数量。Population– 街区人口。AveOccup– 平均每户人家的居住成员数量。Latitude– 街区纬度。Longitude– 街区经度。MedHouseVal– 房屋中位价值(以千元为单位)。
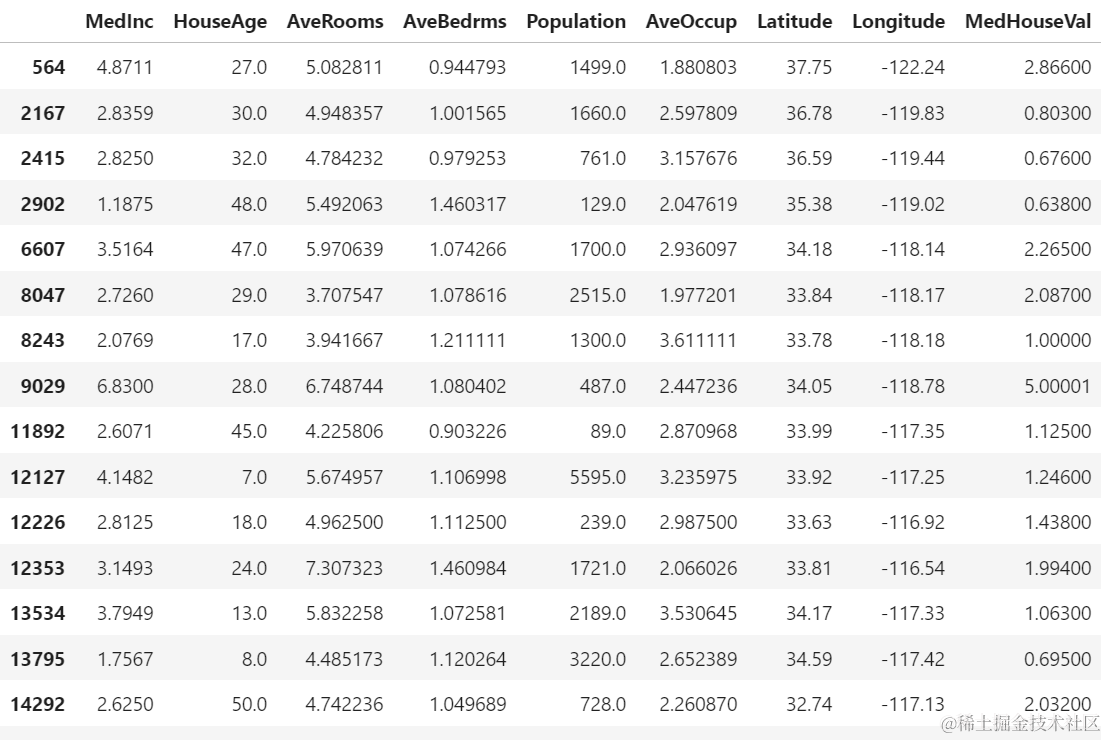
让我们导入 Pandas 并查看前几行数据:df.head()
执行该代码将显示我们数据集的前五行:
我们将使用 MedInc、HouseAge、AveRooms、AveBedrms、Population、AveOccup、Latitude、Longitude 来预测 MedHouseVal。
现在,让我们直接实现 KNN 回归算法。
使用 Scikit-Learn 进行 K-Nearest Neighbors 回归
到目前为止,我们已经了解了数据集,现在可以继续进行 KNN 算法的其他步骤。
为 KNN 回归预处理数据
y = df['Mexis = 1)
为了进行特征标准化,我们将在稍后使用Scikit-Learn的StandardScaler类。
将数据拆分为训练集和测试集
为了能够在没有泄漏的情况下标准化数据,同时评估我们的结果并避免过拟合,我们将把数据集分为训练集和测试集。
为了使这个过程可重现(使该方法始终对相同的数据点进行采样),我们将random_state参数设置为一个特定的SEED:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=SEED)
这段代码将数据的75%用于训练,将数据的25%用于测试。通过将test_size更改为0.3,例如,您可以使用70%的数据进行训练,并使用30%进行测试。
现在我们可以在X_train数据集上拟合数据标准化,并对X_train和X_test进行标准化,而不会将任何数据从X_test泄漏到X_train中。
KNN回归的特征标准化
通过导入StandardScaler,实例化它,根据我们的训练数据进行拟合,并对训练和测试数据集进行转换,我们可以进行特征标准化:
# 仅在X_train上进行拟合
scaler.fit(X_train)
# 对X_train和X_test进行缩放
X_test = scaler.transform(X_test)
现在我们的数据已经标准化。
KNN回归的训练和预测
拟合到我们的训练数据:
......
regressor.fit(X_train, y_train)
最后一步是对我们的测试数据进行预测。要这样做,请执行以下脚本:
predict(X_test)
现在,我们可以评估我们的模型在具有标签(真实值)的新数据上的泛化能力-即测试集!
评估KNN回归算法
用于评估算法的最常用的回归指标是平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)和决定系数(R2)
可以使用sklearn.metrics的mean_absolute_error()和mean_squared_error()方法来计算这些指标,如下面的代码片段所示:
......
print(f'mse: {mse}')
print(f'rmse: {rmse}')
上面脚本的输出结果如下:

随时关注您喜欢的主题
可以使用score()方法直接计算R2:
regrscore(X_test, y_test)
输出结果如下:
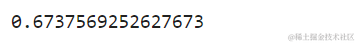
平均值为2.06,标准差为平均值的1.15,因此我们的得分约为0.44,既不是非常好,也不是太糟糕。
对于R2,得分越接近1(或100),越好。R2表示KNN能够理解(解释)多少数据变化或数据方差。
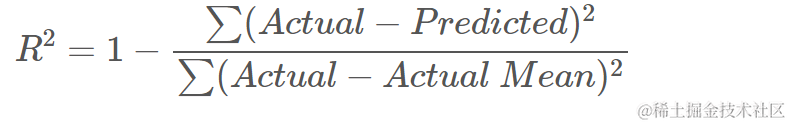
得分为0.67,我们可以看到模型解释了67%的数据方差。这已经超过了50%,还可以,但不是非常好。我们能否有其他方法提高预测的效果?
为了确定理想的K值,我们可以分析算法的误差并选择最小化损失的K。
查找最佳的K值
为此,我们将创建一个for循环,并运行具有从1到X个邻居的模型。在每次交互时,我们将计算MAE并绘制K值以及MAE结果:
error = []
# 计算不同k的MAE误差
for i in range(1, 40):
......
error.append(mae)
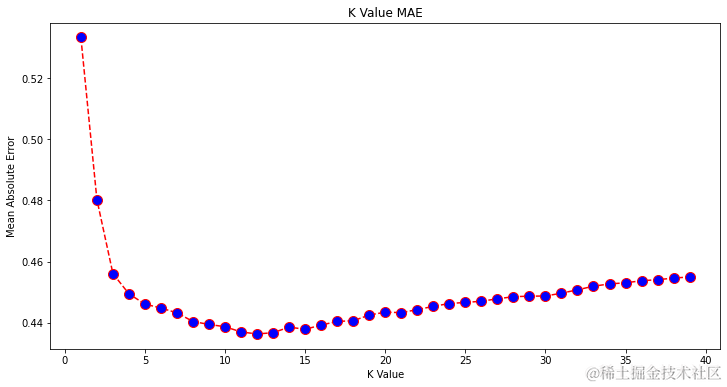
现在,让我们绘制error:
看着图表,当 K 值为 12 时,似乎最小的平均绝对误差(MAE)值。
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
......
plt.ylabel('Mean Absolute Error')
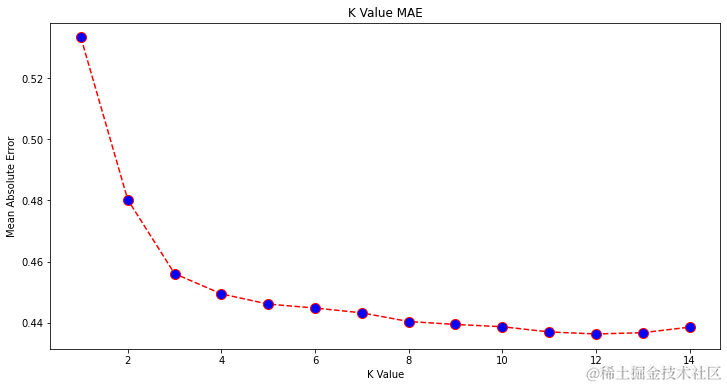
让我们通过绘制更少的数据来仔细观察图表,确认一下:
plt.figure(figsize=(12, 6))
......
您还可以使用内置的 min() 函数(适用于列表)获取最小误差及其索引,或将列表转换为 NumPy 数组并使用 argmin() 函数(找出具有最小值的元素的索引):
import numpy as np
......
print(np.array(error).argmin()) # 11
我们从 1 开始计数邻居,而数组从 0 开始,所以第 11 个索引是 12 邻居!
这意味着我们需要 12 个邻居才能以最小的 MAE 误差预测一个点。我们可以再次使用 12 个邻居执行模型和指标,以比较结果:
knn_reg12 = KNei......
print(f'r2: {r2}, \nmae: {mae12} \nmse: {mse12} \nrmse: {rmse12}')
以下代码输出:

我们已经看到了如何使用 KNN 进行回归,但如果我们想要分类一个点而不是预测其值呢?现在,我们可以看看如何使用 KNN 进行分类。
使用 Scikit-Learn 进行 K-Nearest Neighbors 分类
在这个任务中,我们不再预测连续值,而是想要预测这些街区群组属于的类别。为了做到这一点,我们可以将区域的房屋中位数价值划分为具有不同房屋价值范围或“箱子”(bins)的组。
为分类预处理数据
让我们创建数据的箱子,将连续值转化为类别:
# 创建 4 个类别并将其分配给 MedHouseValCat 列
df["M......False, labels=[1, 2, 3, 4])
然后,我们可以将数据集拆分为属性和标签:
y = df['Med......], axis = 1)
由于我们使用 MedHouseVal 列创建了箱子,我们需要从 X 中删除 MedHouseVal 列和 MedHouseValCat 列。
将数据集拆分为训练集和测试集
与回归一样,我们还将将数据集分为训练集和测试集。由于我们有不同的数据,因此我们需要重复这个过程:
from sklearn.model_selection ......_test_split(X, y, test_size=0.25, random_state=SEED)
我们将再次使用标准的 Scikit-Learn 值,即 75% 的训练数据和 25% 的测试数据。这意味着我们的训练和测试记录数量与之前的回归相同。
对分类进行特征标准化
由于我们处理的是相同的未经处理的数据集及其不同的测量单位,我们将再次执行特征标准化,方式与之前的回归数据相同:
from sklearn.preprocessing import StandardScaler
......
X_test = scaler.transform(X_test)
进行分类的训练和预测
在对数据进行分箱、拆分和标准化之后,我们终于可以在其上拟合一个分类器了。对于预测,我们将再次使用 5 个邻居作为基线。您也可以实例化KNeighbors_类而不使用任何参数,它将自动使用 5 个邻居。这次,我们将导入KNeighborsClassifier类而不是KNeighborsRegressor:
from sklearn.neighbors import KNeighborsClassifier
......
classifier.fit(X_train, y_train)
在拟合之后,我们可以预测测试数据的类别:
评估 KNN 进行分类
要评估 KNN 分类器,我们可以使用score方法,但它执行不同的度量标准,因为我们评分的是分类器而不是回归器。
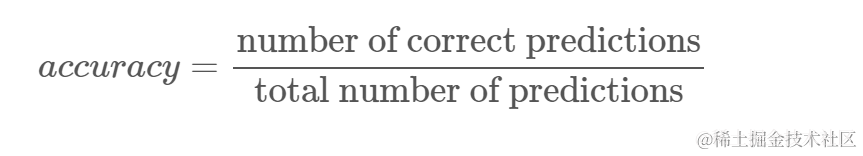
让我们评分我们的分类器:
acc = classifier.score(X_test, y_test)
print(acc) # 0.6191860465116279
通过观察得分结果,我们可以推断出我们的分类器大约有 62% 的类别预测正确。这已经有助于分析,尽管仅仅知道分类器预测正确的内容并不容易改进它。
我们可以使用其他指标更深入地研究结果,以确定。在这里,我们将使用与回归不同的步骤:
- 混淆矩阵:了解我们对每个类别预测正确或错误的程度。被正确预测的值称为真阳性,被预测为阳性但不是阳性的称为假阳性。同样,真阴性和假阴性的命名方式适用于负值。
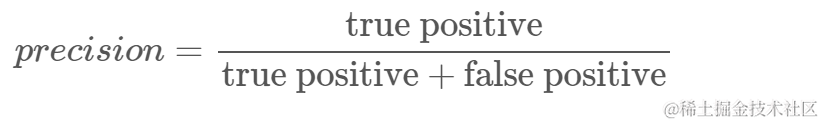
- 精度:了解分类器认为哪些正确预测值是正确的。 精度将真阳性值除以任何被预测为阳性的值;
- 召回率:了解分类器识别出多少真阳性。召回率通过将真阳性除以应该被预测为阳性的任何值来计算。
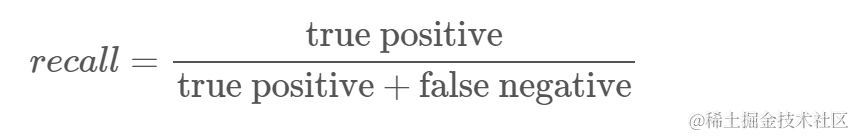
- F1得分:是精度和召回率的平衡或谐波平均值。最低值为0,最高值为1。当f1-score等于1时,意味着所有类别都被正确预测 – 这是使用真实数据非常难获得的分数(几乎总会存在例外情况)。

要获取度量值,请执行以下代码段:
## 导入Seaborn以使用热力图
import seaborn as sns
# # 为更好的解释添加类别名称
classes_names = ['cla......
# # 使用Seaborn的热力图更好地可视化混淆矩阵
sns.hea......ue, fmt='d');
print(cla......t(y_test, y_pred))
上述脚本的输出如下所示:
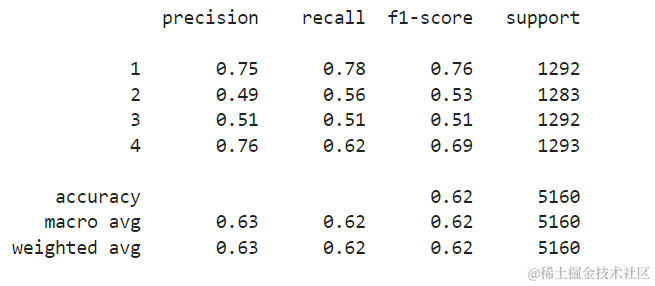
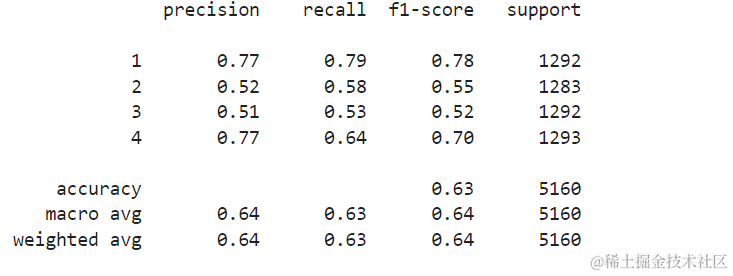
结果表明,KNN能够以62%的准确率对测试集中的所有5160个记录进行分类,这高于平均水平。支持度相当平均(数据集中类别的分布相当均匀),因此带权重的F1和未加权的F1将大致相同。
通过观察混淆矩阵,我们可以看到以下情况:
类别1在238个样本中大多被误分类为类别2类别2在256个样本中被误分类为类别1,在260个样本中被误分类为类别3类别3在374个样本中大多被误分类为类别2,在193个样本中被误分类为类别4类别4在339个样本中被错误地分类为类别3,在130个样本中被误分类为类别2
寻找最佳的K值进行KNN分类
让我们重复之前用于回归的操作,并绘制K值和测试集的相应指标的图表。您也可以选择适合您上下文的指标,这里我们将选择f1-score。
f1s = []
# 计算K值在1到40之间的f1分数
for i in range(1, 40):
......
# 使用average='weighted'计算4个类别的加权平均值
f1s.append(f1_sc......hted'))
下一步是绘制f1_score值与K值的关系图。与回归不同的是,这次我们不再选择最小化误差的K值,而是选择最大化f1-score值的K值。
执行以下脚本创建绘图:
plt.figure(figsize=(12, 6))
plt.plot(r......
plt.ylabel('F1 Score')
输出的图表如下所示:
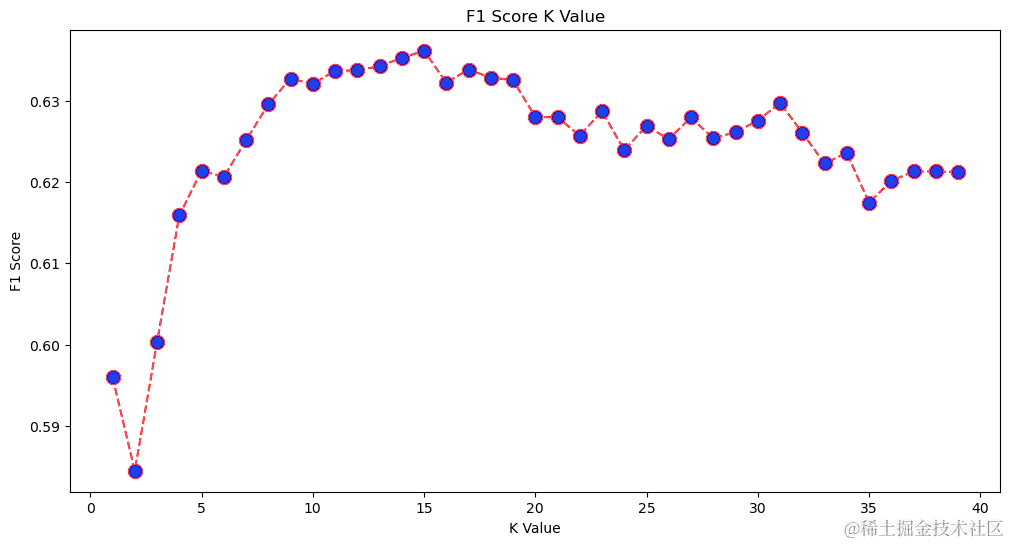
从输出中我们可以看到,当K值为15时,f1-score最高。让我们使用15个邻居重新训练分类器,并查看它对分类报告结果的影响:
classiier15 = ......est)
print(clasificaion_report(y_test, y_pred15))
这将输出以下结果:
除了在回归和分类中使用KNN来确定块值和确定块类别之外,我们还可以使用KNN来检测与大部分数据不同的均值块值 – 不遵循大部分数据趋势的块值。换句话说,我们可以使用KNN来检测异常值。
使用Scikit-Learn实现异常值检测的KNN算法
异常值检测使用一种与我们之前进行回归和分类不同的方法。
导入后,我们将实例化一个带有5个邻居的NearestNeighbors类 – 你也可以使用12个邻居实例化它来识别回归示例中的异常值,或者使用15个邻居执行分类示例相同的操作。然后,我们将拟合我们的训练数据,并使用kneighbors()方法找到每个数据点和邻居索引的计算距离:
nbrs.fit(X_train)
# 距离和邻居的索引
distances,......hbors(X_train)
现在,我们对于每个数据点有了5个距离 – 它与其5个邻居之间的距离,并且还有一个标识它们的索引。让我们看一下前三个结果以及数组的形状,以更好地可视化。
执行以下代码以查看前三个距离的形状:
distances[:3], distances.shape

观察到有3行,每行有5个距离。我们也可以查看邻居的索引:
indexes[:3], indexes[:3].shape
在上面的输出中,我们可以看到每个5个邻居的索引。现在,我们可以继续计算这5个距离的平均值,并绘制一张图表,X轴上计数每一行,Y轴上显示每个平均距离:
dist_means = distances.mean(axis=1)
plt.plot(dis......)
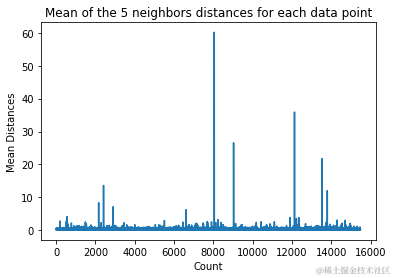
注意到图表中有一个部分,平均距离具有均匀的值。当平均距离不太高也不太低时,表示该点是我们需要识别并剔除异常值的点。
在此示例中,平均距离为3.让我们再次绘制该图表,并使用水平虚线来标记它:
dist_means = distan(axis=1)
plt.plot(......)
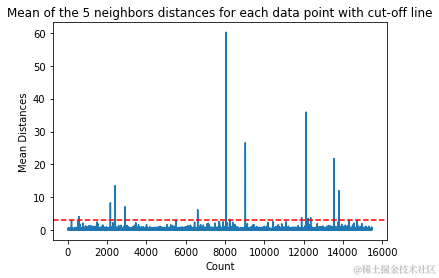
这条线标记了平均距离,在该线上方的所有值都是变化的异常值。这意味着所有平均距离大于3的点都是异常值。
# 目视确定大于3的截断值
outlie......here(dist_means > 3)
outlierndex
以上代码输出的结果为:
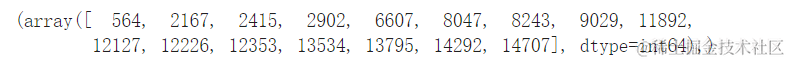
# 过滤异常值
outlies = df.ioc[outier_index]
outlier_lues
我们的异常值检测完成了。这就是我们找到与整体数据趋势不符的每个数据点的方法。我们可以看到在我们的训练数据中有16个点应该进一步查看、调查、处理,甚至从我们的数据中删除(如果它们是错误输入)以改善结果。这些点可能是由于输入错误、均值块值不一致或两者兼而有之导致的。
KNN算法的优缺点
优点
- 实现简单
- 它是一种惰性学习算法,因此不需要对所有数据点进行训练(仅使用K个最近邻来预测)。这使得KNN算法比其他需要使用整个数据集进行训练的算法(如支持向量机和线性回归等)要快得多。
- 由于KNN在进行预测之前不需要训练,因此可以无缝添加新数据。
- 使用KNN只需要两个参数,即K的值和距离函数。
缺点
- KNN算法在处理高维数据时效果不好,因为在高维空间中,点与点之间的距离不一致,而我们使用的距离度量方法就不再适用。
- 最后,KNN算法在处理具有分类特征的数据时效果不佳,因为很难计算具有分类特征的维度之间的距离。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据
R语言与MATLAB定制开发SARIMAX双模型预测与PSO多目标优化消费券发放策略|附AI智能体、代码和数据 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据 Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据
Python融合SVD矩阵分解与NCF神经协同过滤的电影评分预测与推荐系统|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据