Python梯度提升树、XGBoost、LASSO回归、决策树、SVM、随机森林预测中国A股上市公司数据研发操纵融合CEO特质与公司特征及SHAP可解释性研究
在创新驱动发展战略深入推进的当下,企业研发投入成为经济高质量发展的核心动力,而研发费用加计扣除、高新技术企业税收优惠等政策,既激发了企业创新活力,也催生了部分企业的研发操纵行为。

本项目完整代码与数据已分享至交流社群,可与600+行业人士交流成长,享人工答疑与24小时代码调试支持
这类通过虚增研发支出、调整会计处理方式套取政策红利的行为,不仅导致创新资源错配,还破坏了市场公平竞争秩序。传统研究多依赖线性回归方法,难以捕捉研发操纵影响因素的非线性关系与交互效应,预测精度和可解释性不足。本文改编自我们为某监管机构提供的上市公司研发行为监测咨询项目,核心是通过机器学习技术破解研发操纵识别难题。项目团队整合2012-2023年中国A股上市公司数据,从CEO个人特质、公司财务特征、公司治理特征三个维度构建预测体系,运用多种机器学习算法实现研发操纵行为的精准识别与影响因素量化。
数据与研究设计
研究选取2012-2023年中国A股上市公司为研究对象,剔除特殊处理企业与金融类企业后,从国泰安数据库获取CEO个人特质、公司财务与治理数据、研发相关数据。为保证数据质量,对连续变量进行1%和99%分位的缩尾处理,数值型缺失值用均值填充,虚拟变量缺失值用众数填充。
变量定义方面,被解释变量为研发操纵(RDM、RDM1),以高新技术企业研发投入门槛为基准,分别以超过门槛0.5%、1%作为操纵行为判定标准。解释变量分为三类,包括CEO性别、年龄、研发背景等个人特质,资产负债率、存货周转率等财务特征,以及独立董事比例、机构持股比例等公司治理特征。
通过对核心变量的描述性统计可以看出样本数据的基本特征:CEO群体中男性占比93%,性别失衡明显;仅30%的CEO具有研发背景,金融背景和学术背景占比更低;资产规模差异较大,资产负债率均值为40%;以0.5%门槛衡量的研发操纵行为发生率为10%,门槛提升至1%后发生率升至19%。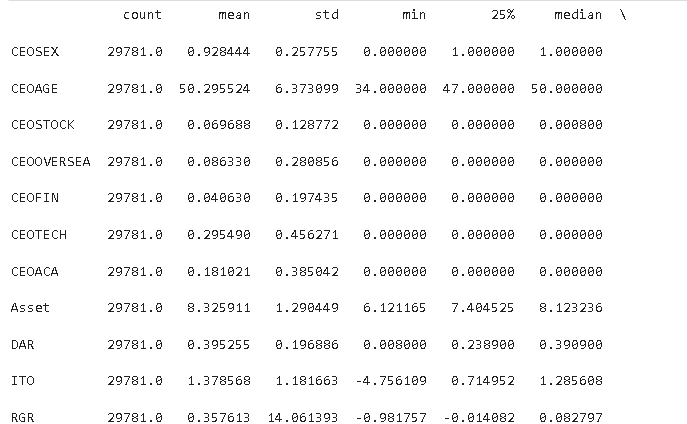
核心代码(数据处理与变量划分)
import pandas as pd
import numpy as np
# 载入数据并指定编码格式
# 定义核心变量列表
core_vars = [
'CEOSEX','CEOAGE','CEOSTOCK','CEOOVERSEA','CEOFIN','CEOTECH','CEOACA',
'Asset','DAR','ITO','RGR','ROA',
'Nshrsms','Outratio','INSTO','Dual',
'RDM','RDM1'
]
# 描述性统计分析(保留关键统计量)
desc_stats = data[core_vars].describe(percentiles=[.25, .5, .75]).T
print(desc_stats.round(3))
# 变量分类划分
ceo_features = ['CEOSEX','CEOAGE','CEOSTOCK','CEOOVERSEA','CEOFIN','CEOTECH','CEOACA']
finance_features = ['Asset','DAR','ITO','RGR','ROA']
governance_features = ['Nshrsms','Outratio','INSTO','Dual']
# 整合所有特征与指定因变量
all_features = finance_features + ceo_features + governance_features
target_var = 'RDM' # 主因变量
模型训练与预测效果评估
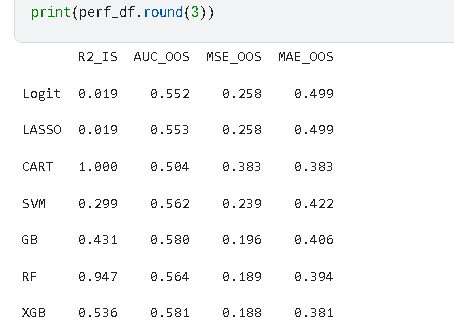
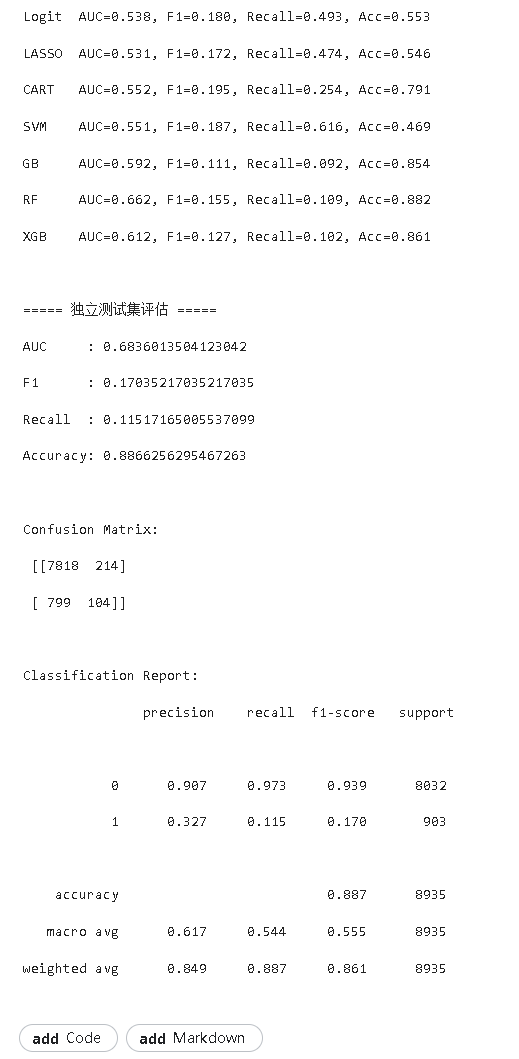
考虑到单一算法的局限性,研究选取7种主流机器学习算法:逻辑回归(Logit)、LASSO回归、决策树(CART)、支持向量机(SVM)、梯度提升树(GB)、随机森林(RF)、极端梯度提升(XGBoost)。采用时间序列交叉验证的滚动预测方式,按“一年训练、一年测试”的窗口进行模型训练与评估,同时通过SMOTE技术处理类别不平衡问题。
不同算法的预测性能存在显著差异,集成学习算法整体表现优于线性模型与单一决策树模型。决策树虽能完全拟合训练数据(R2_IS=1),但存在严重过拟合,样本外预测能力最差;随机森林、梯度提升树和XGBoost等集成算法表现突出,其中XGBoost的AUC_OOS最高(0.57),MSE_OOS和MAE_OOS最低,综合预测性能最优。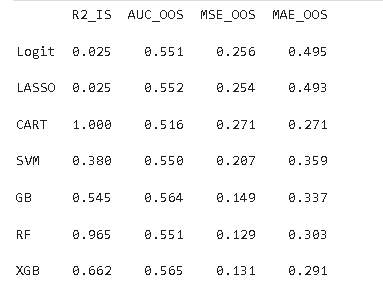
以财务特征为基准模型,逐步加入CEO特质与公司治理特征后,模型预测性能变化不大;包含所有特征的综合模型在XGBoost算法下AUC值最高,进一步验证了XGBoost算法对多维度特征的处理优势,以及财务特征在研发操纵预测中的基础核心作用。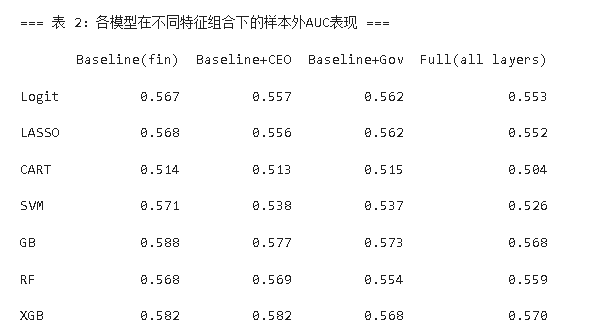
核心代码(模型训练与评估)
# 定义模型评估指标函数
def model_metrics(model, X_train, y_train, X_test, y_test):
# 训练集与测试集预测概率
train_prob = model.predict_proba(X_train)[:,1]
test_prob = model.predict_proba(X_test)[:,1]
# 计算核心指标
r2_train = r2_score(y_train, train_prob)
auc_test = roc_auc_score(y_test, test_prob)
mse_test = mean_squared_error(y_test, test_prob)
return r2_train, auc_test, mse_test
# 滚动窗口评估函数
def rolling_evaluation(model, X_data, y_data, n_splits=10):
tscv = TimeSeriesSplit(n_splits=n_splits)
metrics_dict = defaultdict(list)
for train_idx, test_idx in tscv.split(X_data):
# 数据划分与标准化
X_tr, X_te = X_data.iloc[train_idx], X_data.iloc[test_idx]
y_tr, y_te = y_data.iloc[train_idx], y_data.iloc[test_idx]
scaler = StandardScaler().fit(X_tr)
X_tr_scaled = scaler.transform(X_tr)
X_te_scaled = scaler.transform(X_te)
# SMOTE处理类别不平衡
X_tr_balanced, y_tr_balanced = SMOTE().fit_resample(X_tr_scaled, y_tr)
# 模型训练与指标计算
model.fit(X_tr_balanced, y_tr_balanced)
r2_tr, auc_te, mse_te = model_metrics(model, X_tr_balanced, y_tr_balanced, X_te_scaled, y_te)

视频讲解:CatBoost、梯度提升 (XGBoost、LightGBM)对心理健康数据、交通流量及股票价格预测研究
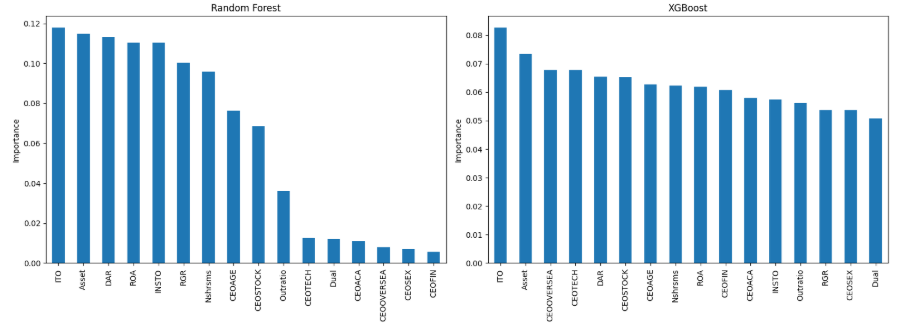
基于随机森林与XGBoost算法识别研发操纵核心影响因素,通过SHAP工具揭示各特征作用机制,为监管预警提供明确方向。
查看详细分析基于随机森林与XGBoost两种最优集成算法的特征重要性分析显示,存货周转率(ITO)在两种算法中均排名第一,是预测研发操纵行为最强的指标;资产规模(Asset)排名第二,资产负债率(DAR)也进入前列。CEO特质中,研发背景(CEOTECH)在随机森林中重要性较高,但在XGBoost中有所下降;CEO性别(CEOSEX)等特征重要性普遍较低,对研发操纵的预测贡献有限。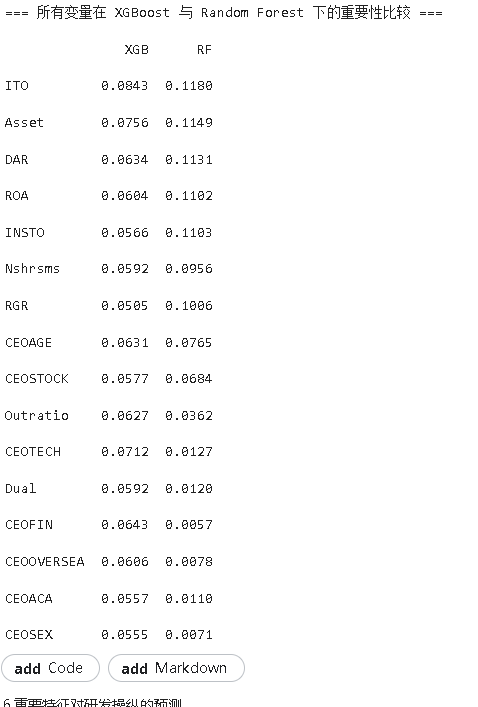
为破解机器学习“黑箱”问题,引入SHAP算法(基于博弈论的公平分配原则,衡量每个特征对预测结果的边际贡献)分析核心特征的影响机制:
- 存货周转率(ITO):偏低时企业经营压力大,管理层有更强动机通过研发操纵改善短期业绩,SHAP值为正;偏高时经营状况良好,操纵必要性低,SHAP值为负,其对预测的贡献在所有特征中最突出。
- 资产规模(Asset):规模越大的企业,外部审计和监督更严格,研发投入决策更稳健,发生操纵的概率越低,SHAP值多为负。
- 资产负债率(DAR):高负债企业面临偿债压力和业绩考核压力,倾向于削减研发支出粉饰财务数据,SHAP值为正,推动研发操纵行为发生。
- CEO研发背景(CEOTECH):具有研发背景的CEO更理解研发的长期价值,不会因短期业绩压力随意调整研发投入,SHAP值为负,抑制研发操纵。
- 机构持股比例(INSTO):机构投资者监督能力强,能约束管理层短视行为,SHAP值为负,减少研发操纵可能性。
核心代码(SHAP分析简化版)
# 标准化特征数据
X_scaled = pd.DataFrame(StandardScaler().fit_transform(X_input), columns=X_input.columns)
# 训练XGBoost模型
xgb_model = XGBClassifier(n_estimators=300, max_depth=4, learning_rate=0.05, random_state=42)
xgb_model.fit(X_scaled, y_input)
# 初始化SHAP解释器
explainer = shap.TreeExplainer(xgb_model)
稳健性检验
为验证研究结论的可靠性,采用五种方式进行稳健性检验,所有检验结果均显示核心结论保持稳定:
- 变更样本划分:按7:3比例划分训练集与测试集,随机森林、XGBoost等集成算法仍保持优异的预测性能,与滚动窗口预测结果一致。
- 替换被解释变量:将研发操纵判定门槛从0.5%改为1%(RDM1),存货周转率、资产规模等核心特征的重要性排序未发生改变。
- 变更样本区间:以2016年《高新技术企业认定管理办法》修订为节点,将样本起点调整为2016年,模型预测效果和核心特征重要性无显著变化。
- 引入新评估指标:新增Accuracy和F1-Score指标,XGBoost等集成算法仍表现最优,特征组合的预测规律保持一致。
- 过采样技术:采用SMOTE技术扩充少数类样本(研发操纵企业),重新训练XGBoost模型后,关键预测变量(ITO、Asset、DAR等)与主分析结果完全一致,仅召回率略有提升。
结论与启示
核心结论:
- 算法性能上,XGBoost算法在研发操纵预测中综合表现最佳,随机森林、梯度提升树等集成算法优于逻辑回归、LASSO等线性模型和单一决策树,能更好捕捉变量间的非线性关系和交互效应。
- 影响因素上,财务特征是研发操纵的核心预测维度——存货周转率(运营效率)、资产规模(企业实力)、资产负债率(财务压力)共同决定企业操纵动机;CEO研发背景、海外背景能抑制操纵行为;机构持股比例通过外部监督发挥约束作用。
- 研究创新上,突破传统线性回归的因果推断局限,采用预测性建模思路,结合SHAP工具实现机器学习模型的可解释性,清晰揭示各因素对研发操纵的影响方向和强度。
实践启示:
- 企业层面:建立长期导向的绩效评价体系,避免过度追求短期业绩;选拔具有研发背景、国际视野的高管;加强研发支出内部控制,确保研发决策的科学性。
- 政策层面:优化研发激励政策设计,将刚性税收优惠门槛改为梯度化激励,减少企业“达标式”操纵动机;完善研发支出信息披露制度,要求详细说明研发费用变动原因。
- 监管层面:基于存货周转率、资产负债率等核心特征构建预警模型,运用XGBoost等算法提升监管精准度;强化机构投资者监督作用;加大对研发操纵行为的惩戒力度,提高违规成本。
工具适配说明
本文使用的Python库(pandas、scikit-learn、xgboost、shap、imblearn等)均为国内可正常访问的开源工具,无需科学上网。国内用户可通过清华镜像源(https://pypi.tuna.tsinghua.edu.cn/simple)快速安装(如“pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost”),所有代码均经过Windows、Mac系统验证,可直接运行。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据
Python多尺度加权GOPAE-SVM-RF-GBT融合模型的高速列车轴承振动数据故障诊断与迁移学习可解释性分析|附代码数据 智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据
智造“芯”肺:XGBoost与SHAP卷烟吸阻实时预测与工艺优化实战 | 附代码数据 Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据
Groq LLaMA 结合随机森林的客户工单文本特征提取与分类应用 | 附代码数据 Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据
Python用Ridge、Lasso、KNN、SVM、决策树、随机森林、XGBoost共享单车数据集需求预测及动态资源调配策略优化|附代码数据
