二十多年来,自动发现裸体图片一直是计算机视觉中的中心问题,并且由于其悠久的历史和直接的目标,它成为该领域如何发展的一个很好的例子。
在这篇博文中,我将使用裸露检测问题来说明现代卷积神经网络(convnets)的训练与过去的研究有何不同。
可下载资源
(警告和免责声明:这篇文章包含了裸露的可视化效果,以用于科学目的。如果您未满18岁,请勿继续阅读。)
神经网络(neual networks)是人工智能研究领域的一部分,当前最流行的神经网络是深度卷积神经网络(deep convolutional neural networks, CNNs),虽然卷积网络也存在浅层结构,但是因为准确度和表现力等原因很少使用。目前提到CNNs和卷积神经网络,学术界和工业界不再进行特意区分,一般都指深层结构的卷积神经网络,层数从”几层“到”几十上百“不定。
CNNs目前在很多很多研究领域取得了巨大的成功,例如: 语音识别,图像识别,图像分割,自然语言处理等。虽然这些领域中解决的问题并不相同,但是这些应用方法都可以被归纳为:
CNNs可以自动从(通常是大规模)数据中学习特征,并把结果向同类型未知数据泛化。
背景
半个世纪以前,图像识别就已经是一个火热的研究课题。
1950年中-1960年初,感知机吸引了机器学习学者的广泛关注。这是因为当时数学证明表明,如果输入数据线性可分,感知机可以在有限迭代次数内收敛[1]。感知机的解是超平面参数集,这个超平面可以用作数据分类。然而,感知机却在实际应用中遇到了很大困难,因为1)多层感知机暂时没有有效训练方法,导致层数无法加深,2)由于采用线性激活函数,导致无法处理线性不可分问题,比如“与或”。
这些问题随着后向传播(back propagation,BP)算法和非线性激活函数的提出得到解决。1989年,BP算法被首次用于CNN中处理2-D信号(图像)。
2012年,ImageNet挑战赛中CNN证明了它的实力,从此在图像识别和其他应用中被广泛采纳。
通过机器进行模式识别 ,通常可以被认为有四个阶段:
-
数据获取: 比如数字化图像
-
预处理: 比如图像去噪和图像几何修正
-
特征提取:寻找一些计算机识别的属性,这些属性用以描述当前图像与其它图像的不同之处
-
数据分类:把输入图像划分给某一特定类别
CNN是目前图像领域特征提取最好的方式,也因此大幅度提升了数据分类精度,我将在下文详细解释。
网络结构
基础的CNN由 卷积(convolution), 激活(activation), and 池化(pooling)三种结构组成。CNN输出的结果是每幅图像的特定特征空间。当处理图像分类任务时,我们会把CNN输出的特征空间作为全连接层或全连接神经网络(fully connected neural network, FCN)的输入,用全连接层来完成从输入图像到标签集的映射,即分类。当然,整个过程最重要的工作就是如何通过训练数据迭代调整网络权重,也就是后向传播算法。目前主流的卷积神经网络(CNNs),比如VGG, ResNet都是由简单的CNN调整,组合而来。
这些加粗名词将会在下文详细解释。
CNN
一个stage中的一个CNN,通常会由三种映射空间组成(Maps Volume, 这里不确定是不是应该翻译为映射空间,或许映射体积会更准确),
-
输入映射空间(input maps volume)
-
特征映射空间(feature maps volume)
-
池化映射空间(pooled maps volume)
例如图中,输入的是彩色RGB图像,那么输入的maps volume由红,黄,蓝三通道/三种map构成。我们之所以用input map volume这个词来形容,是因为对于多通道图像输入图像实际上是由高度,宽度,深度三种信息构成,可以被形象理解为一种"体积"。这里的“深度”,在RGB中就是3,红,黄,蓝三种颜色构成的图像,在灰度图像中,就是1。
卷积
CNN中最基础的操作是卷积convolution,再精确一点,基础CNN所用的卷积是一种2-D卷积。也就是说,kernel只能在x,y上滑动位移,不能进行深度 (跨通道) 位移。对于图中的RGB图像,采用了三个独立的2-D kernel,如黄色部分所示,所以这个kernel的维度是 。在基础CNN的不同stage中,kernel的深度都应当一致,等于输入图像的通道数。
卷积需要输入两个参数,实质是二维空间滤波,滤波的性质与kernel选择有关,CNN的卷积是在一个2-D kernel 和输入的 2-D input map 之间,RGB中各图像通道分别完成。
我们假设单一通道输入图像的空间坐标为 ,卷积核大小是
,kernel权重为
,图像亮度值是
,卷积过程就是kernel 所有权重与其在输入图像上对应元素亮度之和,可以表示为,
。
该领域的开创性著作是Fleck等人的恰当命名为“ Finding Naked People”。它于90年代中期出版,为计算机视觉研究人员在卷积网络接管之前进行的这类工作提供了一个很好的例子。
2014年
深度学习研究人员没有设计正式的规则来描述输入数据应如何表示,而是设计了网络体系结构和数据集,使AI系统可以直接从数据中学习表示形式。但是,由于深度学习研究人员没有确切指定网络在给定输入下的行为,因此出现了一个新问题:如何理解卷积网络在激活什么?

了解卷积网络的操作需要在各个层次上解释要素活动。在本文的其余部分中,我们将通过将活动从顶层向下映射到输入像素空间来检查NSFW模型的早期版本。这将使我们能够看到是什么输入模式最初在功能图中导致了给定的激活(即,为什么将图像标记为“ NSFW”)。
触觉敏感度
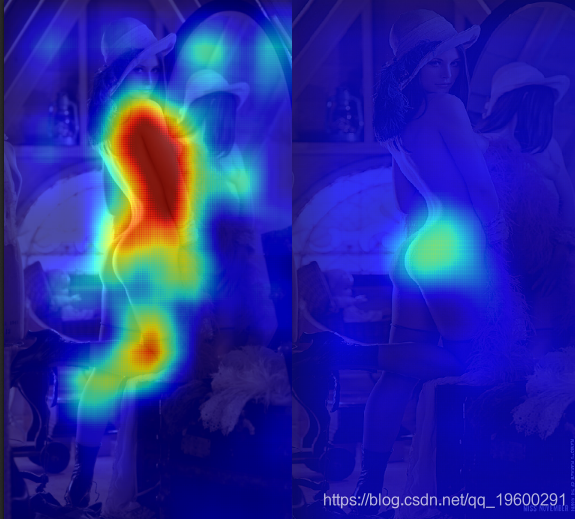
为了在左侧建立热图,我们将每个窗口发送到convnet并平均每个像素的“ NSFW”得分。当卷积网看到作物充满了皮肤时,往往会预测为“ NSFW”,这会导致莉娜身体上的大红色区域。为了在右侧创建热图,我们系统地遮住了原始图像的一部分,并报告1减去平均“ NSFW”得分(即“ SFW”得分)。当大多数NSFW区域被遮挡时,“ SFW”得分会增加,并且我们会在热图中看到更高的值。
为了清楚起见,下图举例说明了上述两个实验分别将哪种图像馈入卷积网络:

这些遮挡实验的优点之一是,当分类器是一个完整的黑匣子时,可以执行它们。这是一个通过我们的API再现这些结果的代码片段:
# 实验
from StringIO import StringIO
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw
import requests
import scipy.sparse as sp
from clarifai.client import ClarifaiApi
CLARIFAI_APP_ID = '...'
CLARIFAI_APP_SECRET = '...'
clarifai = ClarifaiApi(app_id=CLARIFAI_APP_ID,
app_secret=CLARIFAI_APP_SECRET,
base_url='https://api.clarifai.com')
def batch_request(imgs, bboxes):
"""use the API to tag a batch of occulded images"""
assert len(bboxes) < 128
#convert to image bytes
stringios = []
for img in imgs:
stringio = StringIO()
img.save(stringio, format='JPEG')
stringios.append(stringio)
#调用 api
output = []
response = clarifai.tag_images(stringios, model='nsfw-v1.0')
for result,bbox in zip(response['results'], bboxes):
nsfw_idx = result['result']['tag']['classes'].index("sfw")
nsfw_score = result['result']['tag']['probs'][nsfw_idx]
output.append((nsfw_score, bbox))
return output
尽管这些类型的实验提供了一种显示分类器输出的简单方法,但它们的一个缺点是生成的可视化效果通常很模糊。这使我们无法获得对网络实际运行情况的有意义的洞察力 。
反卷积网络
在给定的数据集上训练了网络之后,我们希望能够拍摄图像和课程,并向卷积网络提出类似的要求 :
这是当我们使用deconvnet可视化如何修改Lena的照片 (注意:此处使用的deconvnet需要一个正方形图像才能正常运行-我们填充了完整的Lena图像以获得正确的外观比):

根据我们的deconvnet,我们可以通过增加红色来修饰芭芭拉,使其看起来更像PG:

这张詹姆斯·邦德电影《无博士》中乌斯拉·安德列斯(Hors Rider)饰演的《蜜月骑士》(Honey Rider)在2003年的一项英国调查中被评选为“屏幕历史上最伟大的100个性感时刻”的第一名:

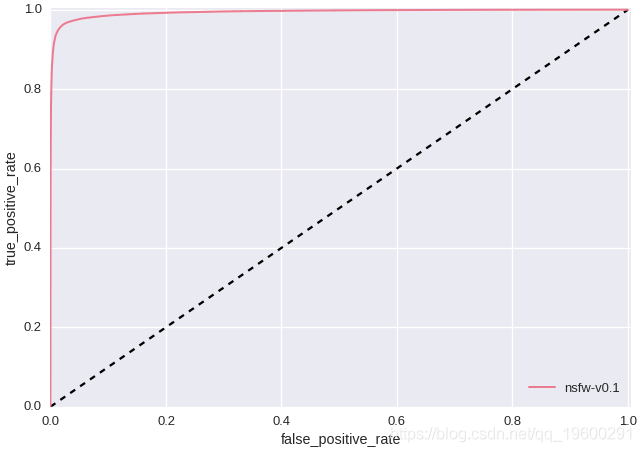
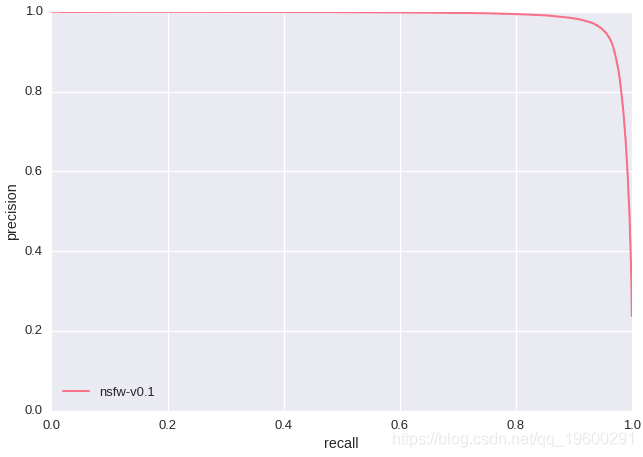
上述实验的一个显着特征是,卷积神经网络学习了红唇和肚脐,表示“ NSFW”。这可能意味着我们在“ SFW”训练数据中没有包含足够的红唇和肚脐图像。如果我们仅通过检查精度/召回率和ROC曲线(如下所示-测试集大小:428,271)来评估模型,我们将永远不会发现此问题,因为我们的测试数据也存在相同的缺点。这凸显了基于训练规则的分类器与现代AI研究之间的根本区别。与其手动设计功能,不如重新设计训练数据,直到发现的功能得到改善为止。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据 Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据
Python定制层次贝叶斯模型进行加密货币交易|附AI智能体、代码和数据 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据

