在常规的马尔可夫链模型中,我们通常感兴趣的是找到一个平衡分布。
MCMC则是反过来思考——我们将平衡分布固定为后验分布
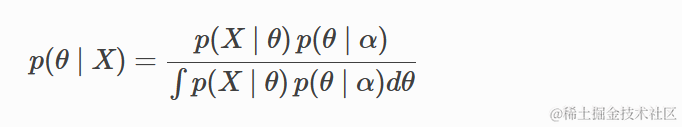
可下载资源
并寻找一种转移核,使其收敛到该平衡分布。
视频
马尔可夫链蒙特卡罗方法MCMC原理与R语言实现
视频
R语言中RStan贝叶斯层次模型分析示例
以一个有趣的例子开始,讲述了政治家访问一系列岛屿以争取支持的情况——由于缺乏经验,政治家使用简单的规则来确定下一个要访问的岛屿。每天,政治家选择一个相邻的岛屿,并将其人口与当前岛屿的人口进行比较。
如果相邻的岛屿人口更多,则政治家前往该岛屿。如果相邻的岛屿人口更少,则政治家以概率 p=pneighbor/pcurrent=neighbor/current 访问该岛屿;否则,政治家就留在同一个岛上。经过多天的访问后,政治家最终会在每个岛上花费的时间与每个岛的人口成比例——换句话说,正确地估计了每个岛的人口分布。
pos = start # 起始位置
......
for i in range(niter):
# 从建议分布中生成样本
......
next_pos = pos + k
# 在建议位置处计算未归一化的目标分布值
next_pop = islands[next_pos]
# 计算接受概率
p = min(1, next_pop/pop)
# 使用均匀分布的随机数决定接受/拒绝建议
......
真实人口比例
......
sns.barplot(x=np.arange(len(data)), y=data)
pass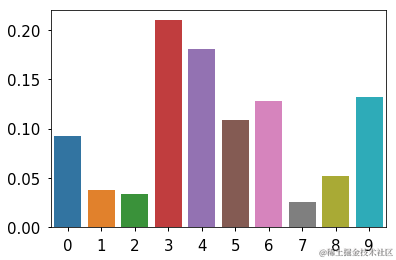
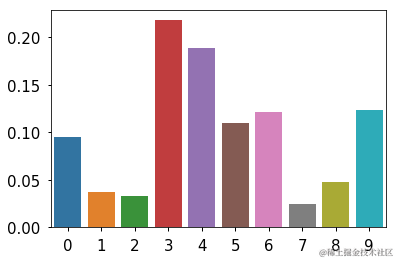
估计人口比例
......
sns.barplot(x=np.arange(len(data)), y=data)
pass
通用 Metropolis 算法
pythonCopy Code
def metroplis(start, target, proposal, niter, nburn=0):
......
if np.random.random() < p:
current = proposed
post.append(current)
return post[nburn:]
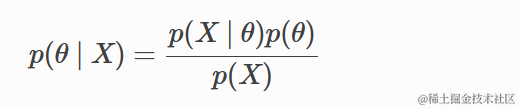
随时关注您喜欢的主题
其中分母为
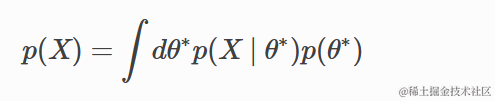
在这里,
- p(X | θ) 是似然函数,
- p(θ) 是先验分布,
- p(X) 是归一化常数,也称为证据或边缘似然
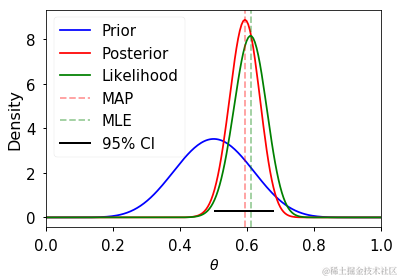
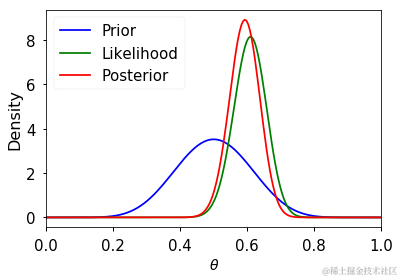
如果我们将贝塔分布作为先验分布,那么后验分布有一个闭合形式的解。
......
ci = post.interval(0.95)
thetas = np.linspace(0, 1, 200)
......
plt.legend(loc='upper left')
pass
数值积分
数值积分的一种简单方法是在一组θ值的网格上估计值。为了计算后验分布,我们找到每个θ值的先验和似然函数,并且对于边际似然,我们用等价的求和替换积分。
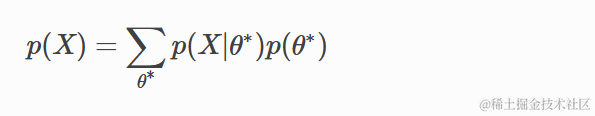
这样做的一个优点是先验分布不必是共轭的(尽管下面的示例为了方便比较使用了相同的贝塔先验),因此在选择适当的先验分布时没有限制。
thetas = np.linspace(0, 1, 200)
......
plt.xlim([0, 1])
plt.xlabel(r'$\theta$', fontsize=14)
plt.ylabel('Density', fontsize=16)
plt.legend()
pass
马尔可夫链蒙特卡洛(MCMC)
本文只涵盖了MCMC的基本思想和三种常见变体- Metroplis,Metropolis-Hastings和Gibbs采样。所有代码都将从头开始构建,以说明拟合MCMC模型所涉及的内容,但只展示了玩具示例,因为目标是概念理解。
在贝叶斯统计中,我们希望估计后验分布,但由于分母中的高维积分(边际似然)通常难以处理。我们在蒙特卡洛积分中遇到的其他一些思想在这里也是相关的,例如独立样本的蒙特卡洛积分和提议分布的使用(例如拒绝采样和重要性采样)。正如我们从蒙特卡洛积分中看到的那样,如果我们可以以某种方式抽取许多来自后验分布的样本,我们就可以近似表示后验p(θ|X)。对于普通蒙特卡洛积分,我们需要样本是来自后验分布的独立抽取,如果我们实际上不知道后验分布是什么(因为我们无法计算边际似然),这就是一个问题。
MCMC有几种变体,但最容易理解的是Metropolis-Hastings随机游走算法,我们将从这里开始。
用于估计硬币偏倚的Metropolis-Hastings随机游走算法
要执行Metropolis-Hastings算法,我们需要从以下分布中随机抽取样本:
- 标准均匀分布
- 我们选择为N(0,σ)的提议分布p(x)
- 与后验概率成比例的目标分布g(x)
给定对于θ的初始猜测,具有正概率被抽取,Metropolis-Hastings算法按如下方式进行:
- 选择一个新的建议值(θp),使得θp=θ+Δθ,其中Δθ∼N(0,σ)
- 计算比值
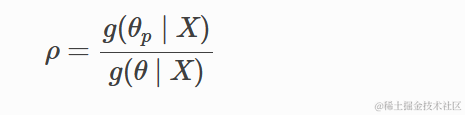
其中g是后验概率。
- 如果提议分布不对称,我们需要加权接受概率以保持稳定分布的细节平衡(可逆性),并计算
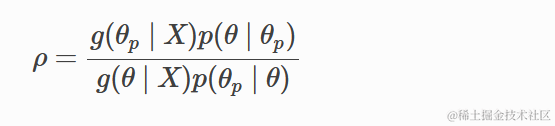
由于我们正在取比值,分母会取消任何与g成比例的分布 – 因此我们可以使用
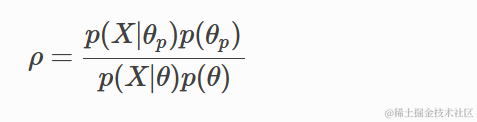
- 如果ρ≥1,则设置θ=θp
- 如果ρ<1,则以概率ρ将θ=θp,否则设置θ=θ(这是我们使用标准均匀分布的地方)
- 重复前面的步骤
经过一定数量的迭代,样本 θk+1, θk+2, … 将是从后验分布中抽取的样本。
Metropolis-Hastings可以使用不同的提议分布:
- 独立采样器使用与当前值θ无关的提议分布。在这种情况下,为了效率,提议分布需要与后验分布相似,同时确保接受比率在后验的尾部区域有界。
- 随机游走采样器(在此示例中使用)在当前值θ为中心处进行随机步骤 – 效率在小步长和高接受概率之间进行权衡,以及大步长和低接受概率之间进行权衡。请注意(课堂上将绘制图示),随机游走可能需要很长时间才能遍历概率分布的狭窄区域。通过更改步长(例如,对于多变量正态提议分布,缩放ΣΣ)以使目标比例的建议被接受,称为“调整”。
- 目前正在进行关于不同提议分布以有效采样后验分布的研究。
我们首先看一个数值示例,然后尝试理解其原理为什么有效。
def target(lik, prior, n, h, theta):
......
lik = stats.binom
prior = stats.beta(a, b)
......
for i in range(niters):
......
print("Efficiency = ", naccept/niters)

post = stats.beta(h+a, n-h+b)
......
plt.legend(loc='upper left')
pass
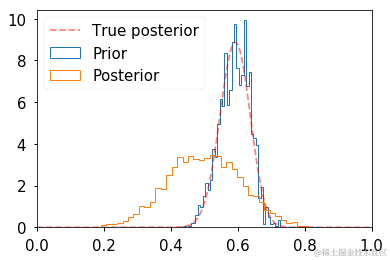
评估收敛性
迹线图通常用于非正式地评估随机收敛。严格证明收敛是一个未解决的问题,但是在实践中经常采用运行多个链并检查它们是否收敛到类似分布的简单想法。
def mhin(niters, n, h, theta, lik, prior, sigma):
......
if u < rho:
theta = theta_p
samples.append(theta)
return samples
n = 100
......
) for theta in np.arange(0.1, 1, 0.2)]
# 多链收敛性
for samples in sampless:
......
plt.ylim([0, 1]);
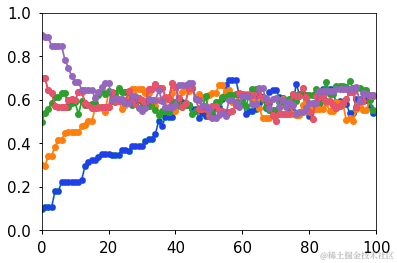
为什么 Metropolis-Hastings 算法有效?
有两个主要的想法——首先,MCMC 生成的样本构成了一个马尔科夫链,并且这个马尔科夫链具有唯一的稳态分布,如果我们生成了非常多的样本,它总是会达到这个稳态分布。第二个想法是证明这个稳态分布正是我们所寻找的后验分布。这里只给出直观的理解。
一:存在唯一的稳态
由于可能的转换只依赖于当前和建议的 θ 值,Metropolis-Hastings 样本中 θ 的连续值构成了一条马尔科夫链。请记住,对于具有转移矩阵 T 的马尔科夫链,

意味着π是一个稳态分布。如果可以从任何状态转换到任何其他状态,则矩阵是不可约的。如果此外,不可能陷入振荡,则矩阵也是周期性或混合的。对于有限状态空间,不可约性和非周期性保证了唯一稳态。对于连续状态空间,我们需要正反馈的另一个属性——从任何状态开始,回到原始状态的预期时间必须是有限的。如果我们具有不可约性、非周期性和正反馈的所有 3 个属性,则存在唯一的稳态分布。术语遍历有点令人困惑——大多数标准定义将遍历性视为等同于不可约性,但是经常在贝叶斯文本中,遍历性意味着不可约性、非周期性和正反馈,我们将遵循后一种惯例。对于另一种直观的视角,随机游走 Metropolis-Hasting 算法类似于扩散过程。由于所有状态都是相互通信的(通过设计),最终系统将进入平衡状态。这类似于收敛到稳态。
示例
我们将使用熟悉的示例来估计两个硬币的偏差,给定样本对 (z1,n1)(θ1,η1) 和 (z2,n2)(θ2,η2),其中 zi 是硬币 i 中 n_i 次投掷中头的个数。
def b:
......
return np.clip(theta**z * (1-theta)**(N-z), 0, 1)
def bern......
return bern(theta1, z1, N1) * bern(theta2, z2, N2)
def maketas(xmin, xmax, n):
......
return thetas
from m......
t_kw=dict(projection=projection, aspect='equal'), figsize=(12,3))
if projection == '3d':
......
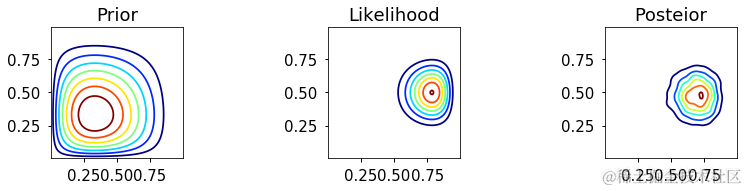
ax[0].contour(X, Y, prior, cmap=plt.cm.jet)
ax[1].contour(X, Y, likelihood, cmap=plt.cm.jet)
......
plt.tight_layout()
the......
etas(0, 1, 101)
X, Y = np.meshgrid(thetas1, thetas2)
分析方法
......
prior = stats.beta(a, b).pdf(X) * stats.beta(a, b).pdf(Y)
l......
)
make_plots(X, Y, prior, likelihood, posterior, projection='3d')
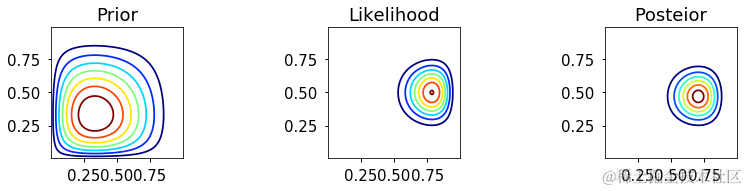
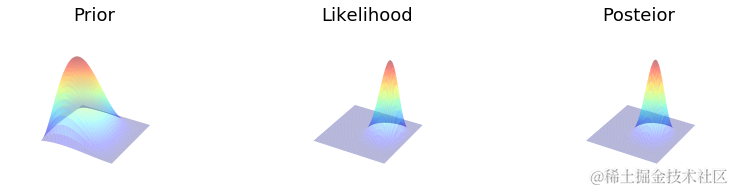
网格近似
def ......
as1[1] - thetas1[0]
width2 = thetas2[1] - thetas2[0]
......
return pmf
_prior = bern2(X, Y,......
10, 10)
prior_grid = c2d(thetas1, thetas2, _prior)
_like......
lihood, posterior_grid)
make_plots(X, Y, prior......
jection='3d')
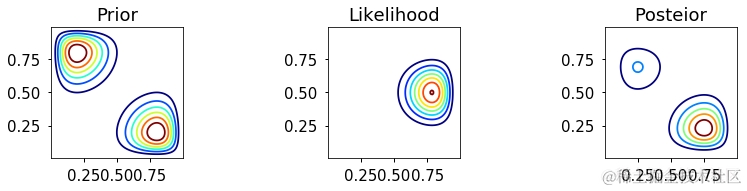
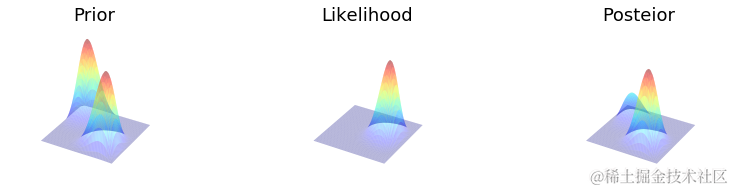
Metropolis
a = 2
b = 3
......
prior = lambda theta1, theta2: stats.beta(a, b).pdf(theta1) * stats.beta(a, b).pdf(theta2)
lik = partial(......
(theta1, theta2)
theta = np.array([0.5, 0.5])
......
thetas = np.zeros((ni......
float)
for i in range(niters):
......
if i >= burnin:
thetas[i-burnin] = theta
kde = stats.gaussian_kde(thetas.T)
......
make_plots(X, Y, prior(X, Y), lik......
metroplis, projection='3d')
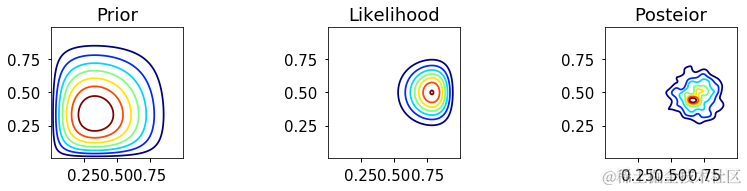
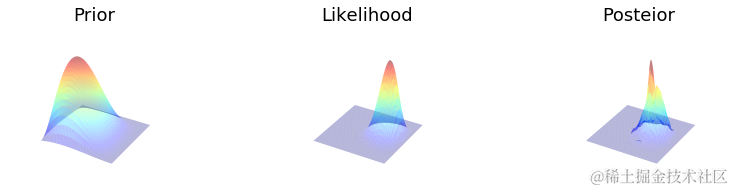
Gibbs
a = 2
......
N2 = 14
prior = lambda theta1,......
, N2=N2)
target = lambda theta1, theta2: prior(theta1, theta2) * lik(theta1, theta2)
theta = np.ar......
)
thetas = np.zeros((niters-burnin,2), np.float)
for i in r......
N2 - z2).rvs()]
if i >= burnin:
thetas[i-burnin] = theta
kde = stats.gaussian_kde(thetas.T)
X......
gibbs, projection='3d')

分层模型
分层模型具有以下结构 – 首先,我们指定数据来自具有参数 θ 的分布
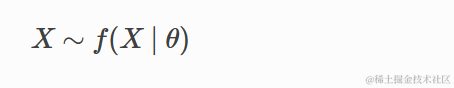
而参数本身来自具有超参数 λ 的另一个分布

最后,λ 来自先验分布

可以有更多层次的分层模型 – 例如,可以为 λ 的分布指定超级超参数,依此类推。
请注意,由于分层模型具有条件独立的结构,Gibbs采样通常是MCMC采样策略的自然选择。
from numpy.random import gamma as rgamma # 重命名,以便我们可以将 gamma 用作参数名称。
def lambda_updat......
def gibbs(niter,......
a_, y)
lambda_ = lambda_update(alpha, beta_, y, t)
betas_[i] = beta_
lambdas_[i,:] = lambda_
return betas_, lambdas_
......
beta0 = 1
y = np.arr......
np.float)
niter = 1000
betas, lambdas = gibbs(nit......
print('%.3f' % betas.std(ddof=1))
print(lambdas.mean(axis=0))
print(lambdas.std(ddof=1, axis=0))

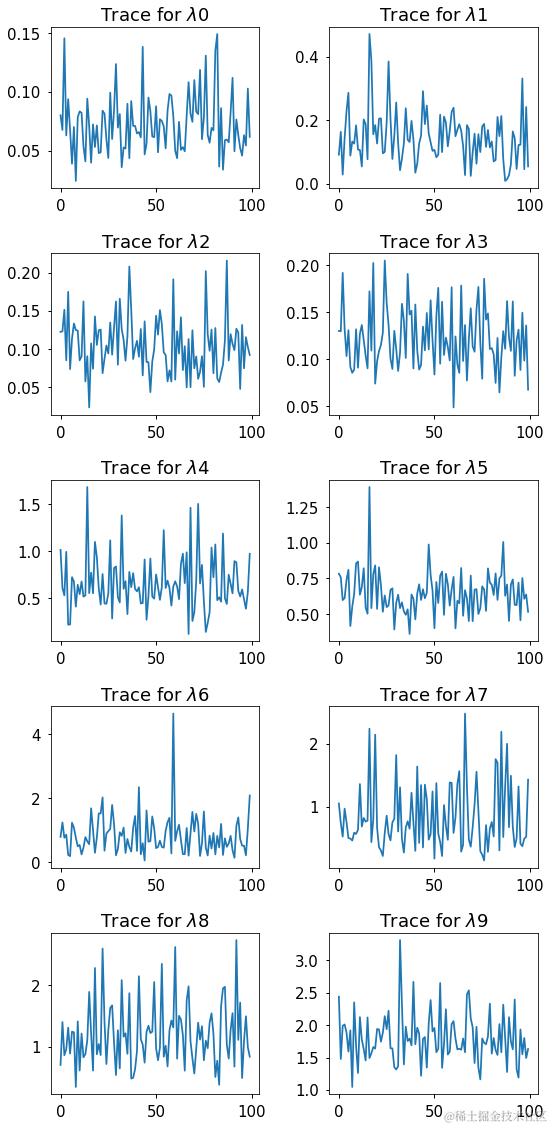
for i in range(len(lambdas.T)):
......
plt.title('Trace for $\lambda$%d' % i)
plt.tight_layout()
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据 【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用
【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用 Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据
Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据 视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践
视频讲解|核密度估计朴素贝叶斯:业务数据分类—从理论到实践



