LangChain与Ollama本地大语言模型的RAG私有知识库构建:融合向量数据库与多源文档查询
还在为如何高效构建LLM应用而烦恼?LangChain 1.0来了!作为当前最火热的AI应用开发框架,它提供了一套标准化的组件,让你像搭积木一样快速搭建复杂的LLM工作流。

成为新会员获取本项目完整教程资料
一、LangChain核心概念与第一个Chain
LangChain是一个开源框架,旨在简化基于大语言模型(LLM)的应用程序开发。它提供了一系列抽象组件,帮助开发者连接LLM、外部数据源和工具,并以“链”的方式组合成复杂的工作流。
1.1 核心组件概览
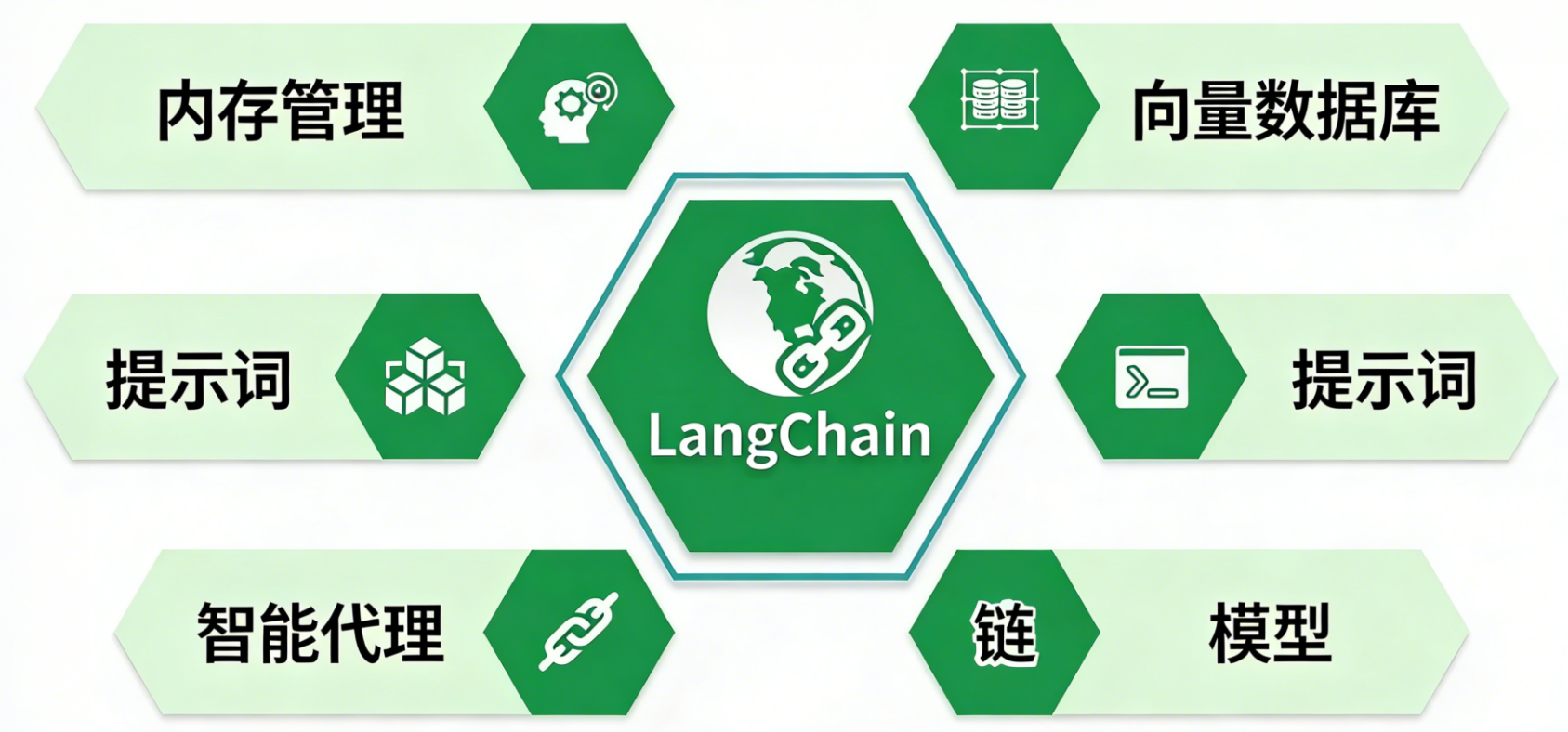
LangChain的核心组件包括:
- Chains(链):将多个步骤(如提示模板、LLM调用、数据处理)串联起来,形成可复用的工作流。
- Agents(代理):让LLM能够自主决定调用哪些工具(如搜索引擎、计算器)来完成任务。
- Memory(记忆):在多次对话中存储和传递上下文,实现连贯的交互。
- Vector Stores(向量存储):与RAG结合,存储文档的向量表示,支持相似性检索。
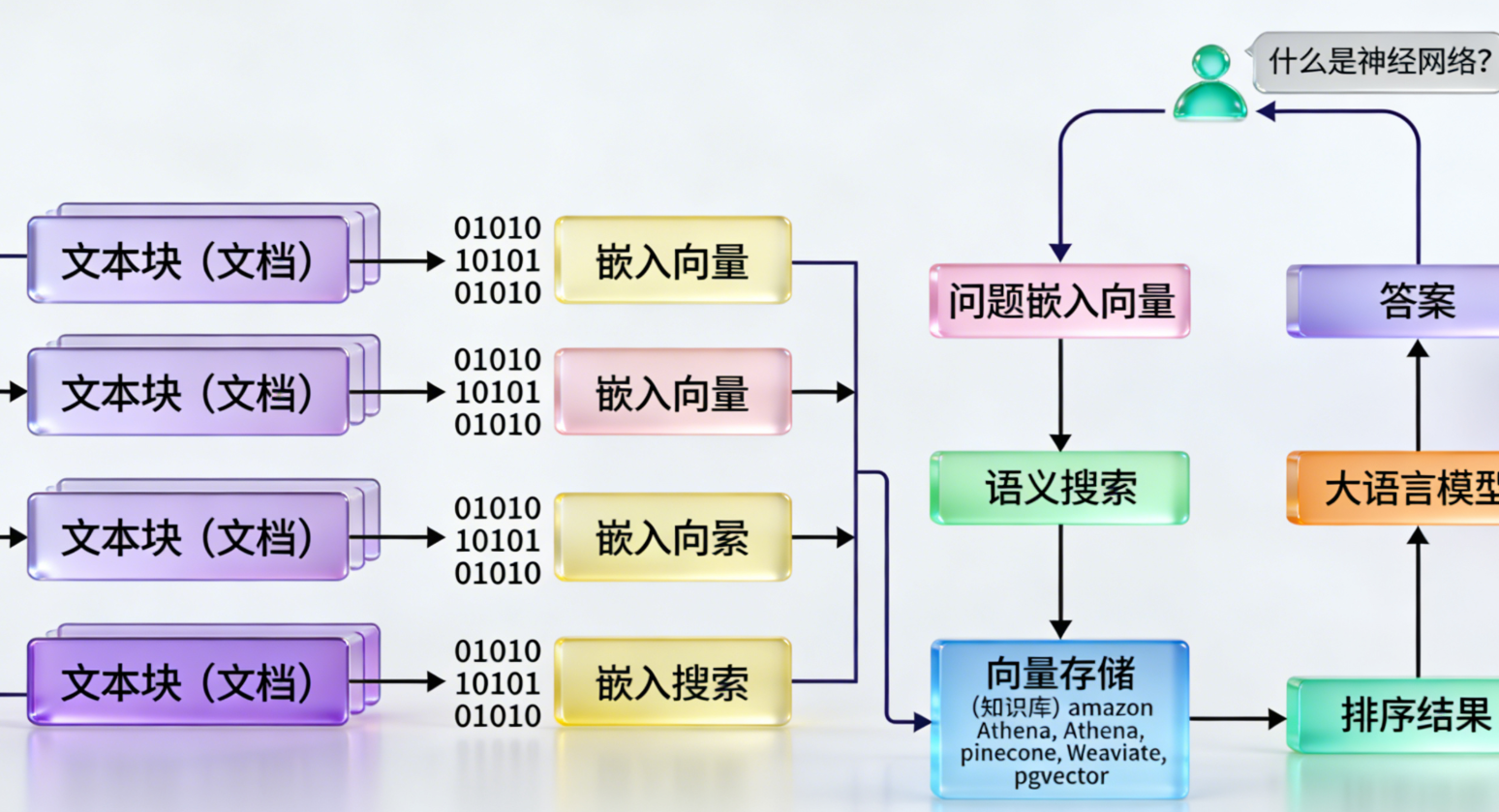
下图清晰地展示了这些组件的关系:
本项目完整教程资料
1.2 安装与第一个Chain
首先,确保已安装Python 3.8+,并创建虚拟环境。然后安装必要的库:
pip install langchain langchain-community langchain-ollama ollama接下来,下载本文所需的两个模型(一个用于嵌入,一个用于对话):
ollama pull mxbai-embed-large
ollama pull llama3:8b现在,我们来构建第一个最简单的Chain——一个直接调用LLM生成技能建议的程序。
# 导入所需模块
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 1. 初始化模型(使用本地ollama中的llama3)
llm = ChatOllama(model="llama3:8b", temperature=0.7)
# 2. 创建提示模板
prompt = ChatPromptTemplate.from_template("给我推荐3个2026年最具前景的编程技能。")
# 3. 构建Chain(使用LCEL语法,| 表示数据流传递)
chain = prompt | llm | StrOutputParser()
# 4. 执行Chain
response = chain.invoke({})
print("=== 推荐结果 ===")
print(response)运行后,你将看到类似如下的输出(实际内容可能略有差异):
=== 推荐结果 ===
1. AI/机器学习工程
2. 全栈Web开发(特别是AI应用集成)
3. 数据工程与实时分析这个简单的例子展示了LangChain的核心工作流:输入→提示模板→LLM→输出解析。StrOutputParser负责将LLM返回的复杂对象转换为纯文本。这便是LangChain的“乐高”积木式开发体验。
1.3 LangChain的工作流程
下图展示了LangChain处理用户查询的完整流程:
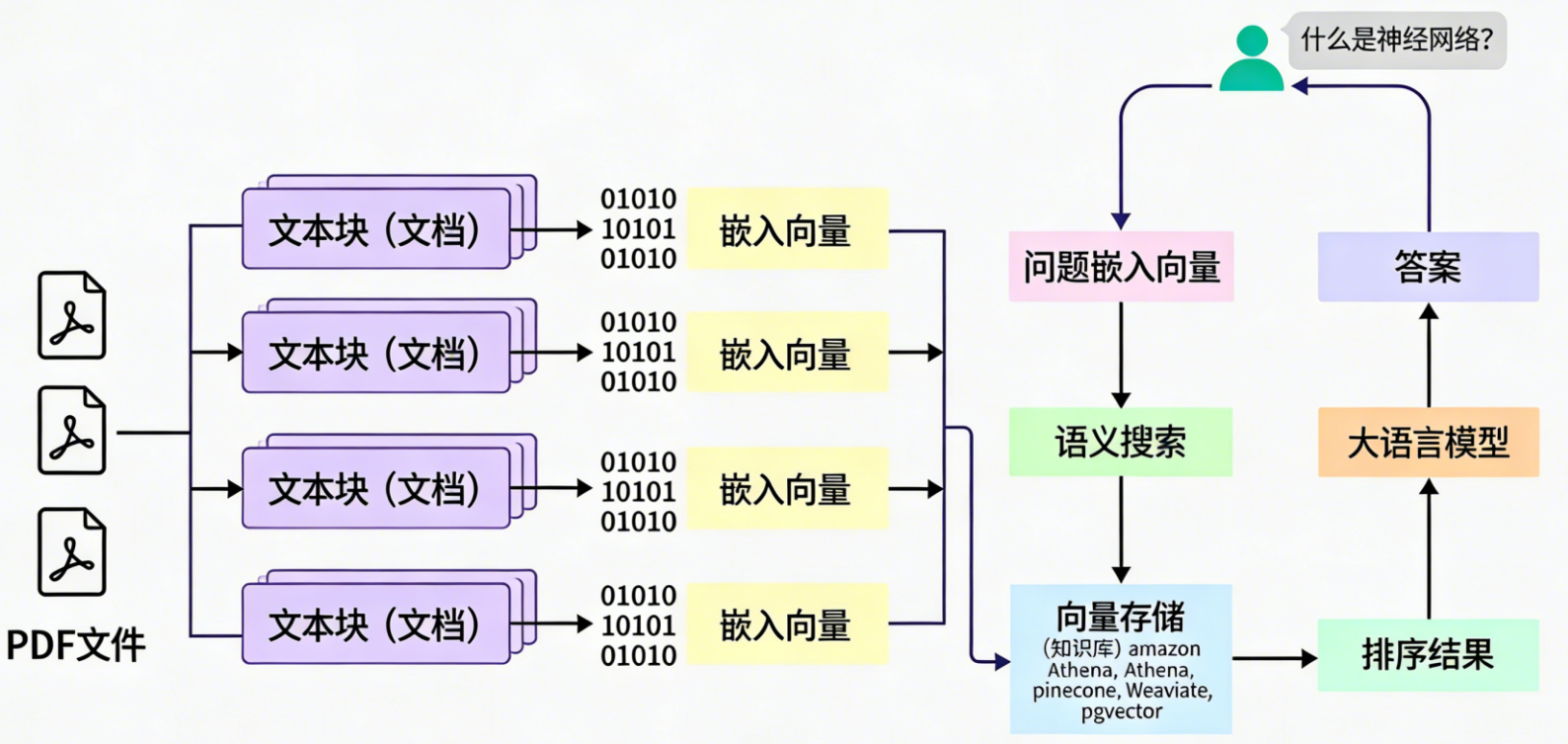
- 用户查询输入到Chain中。
- 根据查询,可能从向量数据库中检索相关信息(RAG场景)。
- 将查询和检索到的上下文组合成提示,发送给LLM。
- LLM生成回答,经过输出解析后返回给用户。
这种架构让开发者能够灵活控制每一步,避免“黑箱”操作。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
二、RAG实战:用Azure Cosmos DB构建本地知识库问答系统
RAG(检索增强生成)是当前最流行的LLM应用模式之一。它允许模型基于自有数据(如文档、数据库)回答问题,显著减少幻觉。本节我们将基于Azure Cosmos DB(或其模拟器)作为向量数据库,结合Ollama本地模型,构建一个文档问答系统。
2.1 准备工作:启动Azure Cosmos DB模拟器
为了完全本地化,我们使用Azure Cosmos DB模拟器。如果你有云账号,也可以直接使用云端服务。
# 拉取并运行模拟器容器
docker pull mcr.microsoft.com/cosmosdb/linux/azure-cosmos-emulator:latest
docker run --publish 8081:8081 -e AZURE_COSMOS_EMULATOR_PARTITION_COUNT=1 mcr.microsoft.com/cosmosdb/linux/azure-cosmos-emulator:latest然后下载并安装SSL证书(以Linux为例):
curl --insecure https://localhost:8081/_explorer/emulator.pem > ~/emulatorcert.crt
sudo update-ca-certificates现在,我们可以通过https://localhost:8081/_explorer/index.html访问模拟器的数据浏览器。
2.2 加载文档并生成嵌入
我们将使用Azure Cosmos DB官方文档作为示例数据。首先克隆项目代码并安装依赖:
git clone https://github.com/abhirockzz/local-llms-rag-cosmosdb
cd local-llms-rag-cosmosdb
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt设置环境变量(使用模拟器)并执行数据加载脚本:
export USE_EMULATOR="true"
export DATABASE_NAME="rag_local_llm_db"
export CONTAINER_NAME="docs"
export EMBEDDINGS_MODEL="mxbai-embed-large"
export DIMENSIONS="1024"
python3 load_data.py脚本会自动从拉取文档、分块、生成嵌入,并存入Cosmos DB。成功后会输出类似:
此时,数据已经就绪。你可以通过数据浏览器验证文档数量。
2.3 执行向量搜索
我们先测试一下向量检索的效果,确保能够找到相关文档片段。
输出将显示最相似的5个文档块及其相似度分数:
Searching top 5 results for query: "show me an example of a vector embedding policy"
...
Score: 0.7437641827298191
Content: ### A policy with two vector paths //....
2.4 构建RAG问答链
最后,我们使用llama3模型将检索到的上下文与问题结合,生成最终答案。
export CHAT_MODEL="llama3"
python3 rag_chain.py启动后,你会进入交互式问答界面:
可以看到,模型基于检索到的文档内容给出了准确的答案,完美体现了RAG的价值。
三、进阶调优:为对话机器人添加记忆与自检机制
在实际应用中,我们往往需要多轮对话能力,并希望模型能主动判断是否需要检索更多信息。本节我们将构建一个带记忆的对话机器人,并引入“多查询检索”技术,提升回答的可靠性。
3.1 项目结构
我们将使用Flask搭建一个简单的Web服务,包含两个核心功能:上传文档并嵌入,以及基于RAG的对话。
安装依赖(已包含在requirements.txt中):
pip install flask langchain chromadb pypdf
LangChain、FastAPI、Python大型语言模型LLM电商多智能体Multi-Agent客服系统|附代码
在电商行业数字化转型的进程中,客服系统作为连接企业与用户的核心触点,其智能化水平直接影响用户体验与运营效率。
探索观点
3.2 实现多查询检索(MultiQueryRetriever)
传统的RAG只使用原始问题去检索,但有时问题表述不清可能导致遗漏。MultiQueryRetriever让LLM生成原始问题的多个变体,然后用这些变体分别检索,最后合并结果,大大提高召回率。
在query.py中,我们定义了一个提示模板,让LLM将用户问题改写成5个不同版本:
from langchain.retrievers.multi_query import MultiQueryRetriever
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""你是一个AI助手。请将用户的问题改写成5个不同表述的版本,以帮助更全面地检索文档。
原问题:{question}""",
)
retriever = MultiQueryRetriever.from_llm(
db.as_retriever(),
llm,
prompt=QUERY_PROMPT
)然后在RAG链中使用这个retriever代替直接检索。
3.3 添加记忆(Memory)
为了让机器人记住之前的对话,我们使用ConversationBufferMemory。在app.py中,我们为每个会话维护一个记忆对象,并将历史记录作为上下文注入到提示中。
3.4 运行测试
首先启动Flask服务:
python3 app.py服务默认运行在http://localhost:8080。我们使用curl上传一个PDF文档:
curl --request POST \
--url http://localhost:8080/embed \
--header 'Content-Type: multipart/form-data' \
--form file=@/path/to/your/document.pdf
成功后,即可进行对话:
curl --request POST \
--url http://localhost:8080/query \
--header 'Content-Type: application/json' \
--data '{ "query": "这篇文档主要讲了什么?" }'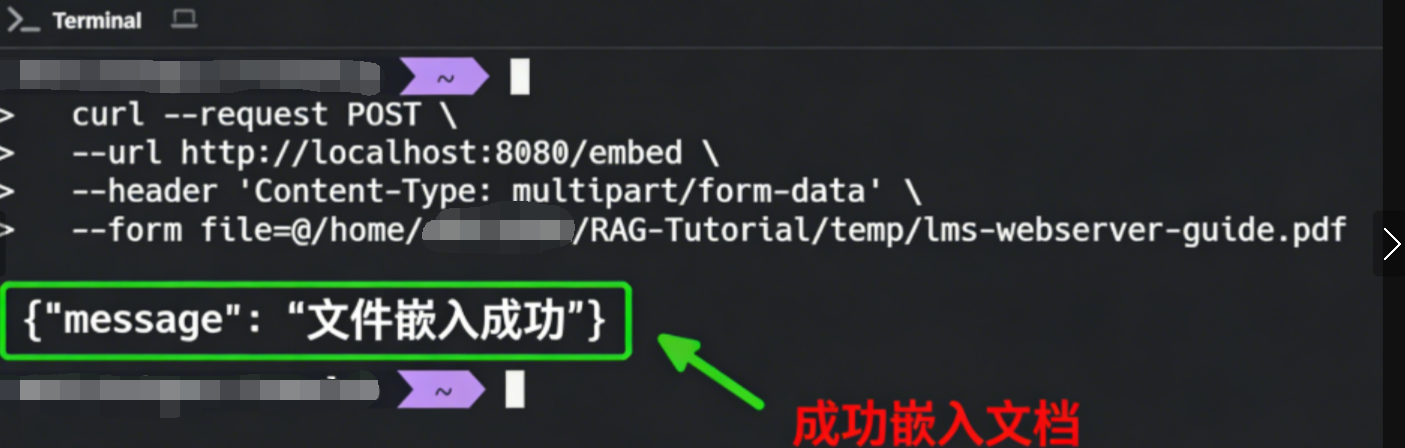
如果答案不够准确,可以调整检索策略或优化分块大小。下图展示了一次成功查询的结果:

3.5 自检机制:让模型知道“我不知道”
为了进一步提升可靠性,我们可以在提示中明确要求:如果检索到的内容无法回答问题,就回答“我不知道”。这避免了模型胡编乱造。例如:
prompt = f"""你是一个文档问答助手。请基于以下上下文回答问题。如果上下文中没有相关信息,请说“抱歉,我无法从文档中找到答案”。
上下文:{context}
问题:{question}
"""这种“自检”机制是生产级应用的关键。
四、LangChain生态与选型指南
除了上述实战,LangChain还提供了丰富的生态系统,包括LangSmith(调试与监控)、LangGraph(复杂工作流编排)等。在实际选型时,你可能需要考虑以下因素:
4.1 核心特性总结
| 特性 | 说明 |
|---|---|
| 链式组合 | 通过LCEL轻松构建复杂流水线 |
| 多模型支持 | 支持OpenAI、Anthropic、Ollama等30+模型 |
| 集成丰富 | 与向量库(Chroma、PGVector、Azure Cosmos DB等)、工具(SerpAPI、Wolfram)无缝对接 |
| 记忆管理 | 内置多种记忆类型,支持对话历史存储 |
| 代理能力 | 让LLM自主调用工具完成任务 |
4.2 定价与成本
LangChain本身是免费的开源框架(MIT许可证)。你需要支付的是:
- LLM API调用费用(如果使用云端模型)或本地硬件成本(如果使用Ollama)。
- 向量数据库托管费用(如使用Pinecone、Azure Cosmos DB)或自建服务器成本。
- 可选工具LangSmith的费用(有免费额度,生产环境按需付费)。
4.3 替代方案对比
| 框架 | 定位 | 优势 | 劣势 |
|---|---|---|---|
| LangChain | 通用LLM应用框架 | 生态最广,组件丰富,社区活跃 | 学习曲线较陡,抽象层次较高 |
| LlamaIndex | 数据-centric RAG | 数据处理能力强,索引策略多样 | 代理和链式能力相对较弱 |
| Haystack | 企业级搜索/RAG | 生产级特性(管道、监控)完善 | 定制灵活性略低 |
| Semantic Kernel | 微软生态集成 | 与.NET、Azure深度整合 | 跨语言支持有限 |
4.4 谁应该使用LangChain?
- AI原生初创团队:快速验证产品,构建MVP。
- B2B SaaS开发者:在现有产品中集成AI功能。
- 技术爱好者/学生:学习和实验LLM应用开发。
如果你的需求极其简单(如单次调用LLM),直接调用API可能更轻量。但对于复杂工作流,LangChain的价值无可替代。
五、总结与展望
通过本文的三大实战案例,你已经掌握了LangChain的核心用法:
- 基础Chain:理解了LCEL语法和组件化思想。
- RAG系统:学会了如何用向量数据库增强LLM的知识。
- 记忆与调优:实现了多轮对话和自检机制,提升了回答的可靠性。
下一步,你可以探索:
- 使用LangGraph构建更复杂的状态机工作流。
- 结合LangSmith进行调试和性能评估。
- 将应用容器化,部署到生产环境。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据
LSTM-Transformer混合模型与多源时空数据的全球水平面辐照度预测:Python实现、模型对比与消融分析 |附代码与数据 无代码智能体构建与LLM效能AI应用开发—LlamaAgents、GPT-5.4为例 | 附完整代码与数据
无代码智能体构建与LLM效能AI应用开发—LlamaAgents、GPT-5.4为例 | 附完整代码与数据 Claude Code多端协同 AI 开发环境构建与效率分析 |附教程文档
Claude Code多端协同 AI 开发环境构建与效率分析 |附教程文档 OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据
OpenClaw与LLM融合对抗性辩论与风险约束的多智能体量化交易系统设计与实现自动化投资架构 |附代码数据



