Python融合RNN、GRU、LSTM多变量空气质量多步预测
时间序列预测一直是量化决策的核心,从金融风控到环境监测,精准捕捉时序数据中的非线性与长期依赖关系,是算法落地产生价值的关键。

成为新会员获取本项目完整报告、代码、数据和AI智能体
深度学习是人工智能的一个领域,专注于创建基于神经网络的模型,使其能够学习非线性表示。循环神经网络(RNN)是一种专门为序列数据设计的深度学习架构,信息通过循环连接传播,使网络能够学习时间依赖性。
本项目完整报告、代码、数据和AI智能体
传统的RNN在每个时间步接收当前数据点和上一个隐藏状态(网络的”记忆”),并更新隐藏状态。这种结构使其能够”记住”数据中的趋势和模式。然而,简单RNN在处理长期依赖时,会遇到梯度消失或爆炸的问题。为了解决上述问题,更先进的长短期记忆网络(LSTM)和门控循环单元(GRU)应运而生。它们通过巧妙的”门控”机制,能更好地捕捉时间序列中的长期复杂模式。LSTM的核心是记忆单元,并由三个门控制信息的流动。这就像是给网络配了一个专业的档案管理员,它知道何时该记住、何时该遗忘、何时该调用信息:遗忘门决定从过去的记忆中丢弃哪些信息;输入门控制有多少新信息需要存入记忆;输出门决定基于当前的记忆输出多少信息。
GRU是LSTM的一个简化且高效的变体。它只有两个门(重置门和更新门),参数更少,计算效率更高,但在许多任务上能达到与LSTM相似的效果。这就像是用一台性能优化的发动机,在降低油耗的同时,保证了充足的马力。预测问题的复杂性通常由三个核心问题决定:使用哪些序列训练模型?目标是预测哪些序列(一个还是多个)?希望预测未来多少个时间步?这衍生出三种典型的预测场景:单变量、单输出:仅用目标序列的过去值来预测其未来值。例如,仅用历史气温预测明天的气温。多变量、单输出:使用多个序列作为预测因子,但目标序列只有一个。例如,用历史气温、湿度和气压来预测未来的气温。多变量、多输出:使用多个序列作为预测因子,并同时预测多个目标序列。例如,同时预测未来多个污染物的浓度。
本文使用某城市2019年至2021年的每小时空气质量数据,包含PM2.5、PM10、CO、NO2等多种污染物浓度。首先,我们加载必要的库并读取数据。在开始前,需要设置Keras的后端(如PyTorch或TensorFlow),这一步决定了后续模型训练的基础架构。这段代码的核心作用是初始化所有依赖库,并显式指定Keras使用PyTorch作为计算后端。这样做的好处是能利用PyTorch的动态图特性和强大的GPU加速能力。接下来,我们从远程获取数据集,并将其划分为训练集、验证集和测试集。这是一个标准操作,训练集用于拟合模型,验证集用于调整超参数和防止过拟合,测试集则在最后评估模型的泛化能力。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
我们通过图表来直观感受下各个序列的走势,这对理解数据特性至关重要。
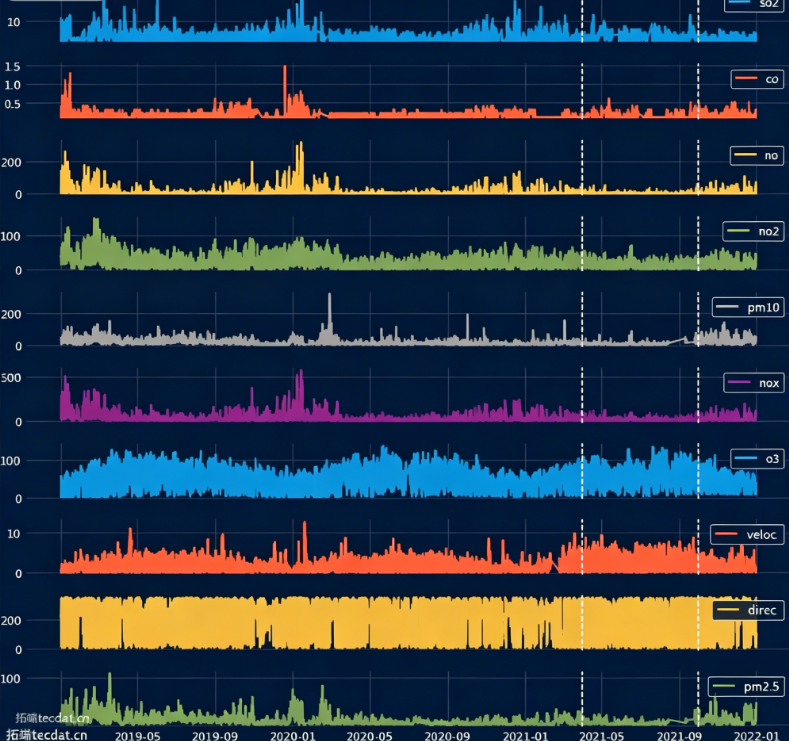
图:数据集所有序列的可视化展示,白色虚线划分了训练、验证、测试集。
create_and_compile_model 函数是skforecast提供的一个强大工具,它极大地简化了RNN模型的构建过程。我们只需指定序列、滞后观测数、预测步数和循环层类型,即可快速生成一个可用的Keras模型。以下是使用该函数的一个基础调用示例,我们试图用一个简单的GRU模型来预测未来24小时的臭氧浓度。这个函数也提供了高度灵活的接口用于高级定制,例如堆叠多层LSTM或GRU,并为每一层设置不同的激活函数。在这个场景下,我们仅使用序列o3的过去值来预测其未来24小时的值。这是一个纯粹的从自身历史推断未来的自回归问题。创建ForecasterRnn对象,并传入验证数据、回调函数等训练参数。使用EarlyStopping可以在验证集损失不再下降时自动停止训练,防止过拟合。
训练过程的损失曲线是诊断模型学习状态的重要依据。
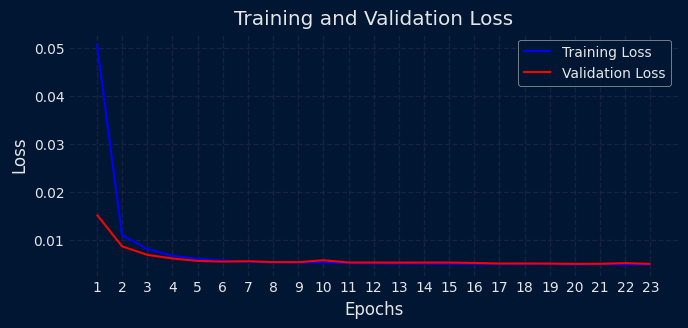
图:训练损失与验证损失曲线。两条曲线紧密贴合并稳定下降,表明模型未出现过拟合。
当训练和验证的损失量级差异较大时,使用双轴图可以更清晰地对比。
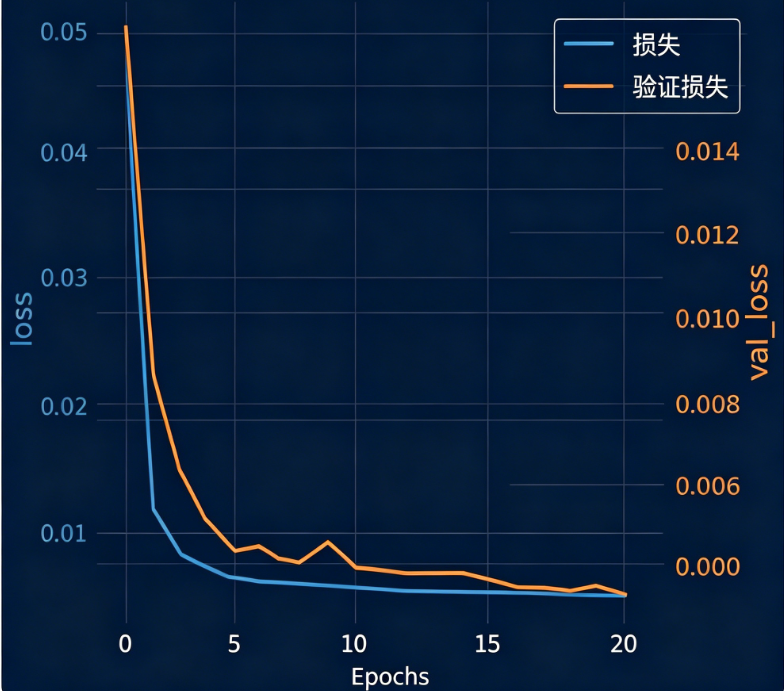
图:使用双轴绘制的训练与验证损失,可以更好观察各自的收敛趋势。
接下来进行回测,以评估模型在未知数据上的表现。首先更新训练参数,将验证集纳入训练,然后执行回测。最终,将预测值与真实值进行可视化对比,可以直观判断模型的效果。当目标序列受其他相关因素影响时,引入多个预测因子往往能提升效果。下面的代码展示了如何使用全部10个序列来预测o3。这个场景是最复杂的,目标是使用所有输入序列,同时预测多个目标(如o3, pm2.5, pm10)。这意味着单一模型能学习并捕捉不同序列间的相互关系。
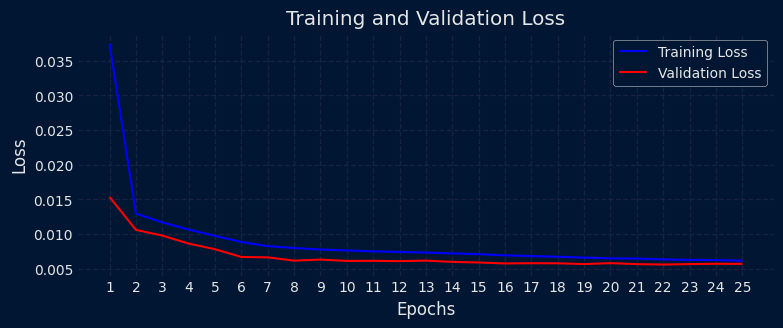
图:多输出模型的训练历史。
下表对比了三种策略下模型对o3序列的预测平均绝对误差(MAE)。结果显示,在本案例中,增加预测因子或多任务输出并未显著降低误差,甚至略有升高。这提醒我们,模型的复杂度和输入特征并非越多越好,必须结合领域知识和实际效果进行选择。
外生变量是指不依赖目标序列本身,但对其有影响的外部特征,如节假日、天气等。为了演示,我们加载一个包含天气和节假日信息的共享单车数据集。为了让模型理解时间的周期性,我们将日期特征(如小时、星期几)通过正弦和余弦进行循环编码。循环编码:为什么不用0-23直接表示小时?因为这样会让模型误以为23点和0点相差很远(数值上差了23),而实际上它们是循环相接的。通过正弦和余弦变换,可以将这种循环关系自然地嵌入到模型中。在create_and_compile_model中,只需将构建好的外生变量DataFrame传入exog参数,模型会自动调整输入层结构,将时间序列特征与外生特征在适当的维度上进行拼接。
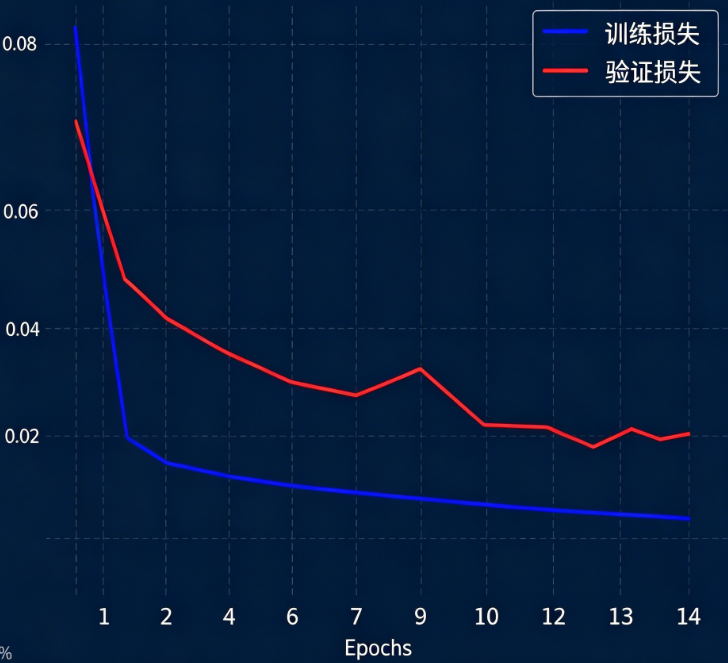
图:引入外生变量后模型的训练历史。验证损失出现波动,存在一定程度的过拟合风险。
点预测只能给出一个期望值,而业务决策往往需要知道预测的”靠谱程度”。通过共形预测框架,我们可以利用历史残差来构建预测区间。
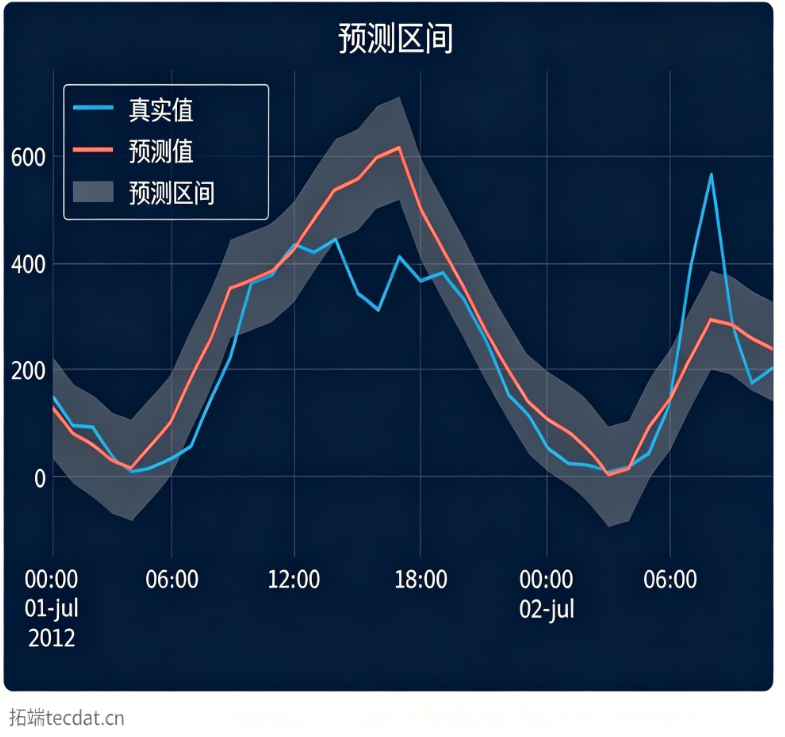
图:共形预测生成的80%预测区间。灰色区域代表了预测的不确定性范围。

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附AI智能体、代码和数据
慌!咱们这套方案源自真实金融咨询项目——一边用Python融合随机森林(RF)、决策树(DT)、XGBoost、逻辑回归(LR)、投票分类器+LSTM多模型,结合6大技术指标做基础预测;一边用DeepSeek+LangGraph搭AI分析助手,效率直接翻番,最终把Netflix股票涨跌预测准确率做到60.78%!
探索观点本文通过一个贯穿始终的空气质量与共享单车预测案例,系统地展示了使用Python生态进行深度学习时间序列预测的全流程。我们从理论出发,落地到实战,涵盖了从数据准备、模型搭建、训练评估到高级应用的全过程。模型适配性验证:我们实践了三种预测场景(单变量、多变量单输出、多变量多输出),并定量对比了不同策略下的模型误差,发现模型复杂度与实际性能并非简单线性关系,为模型选型提供了实证依据。核心工具链掌握:详细解析了ForecasterRnn和create_and_compile_model的使用方法,它们极大简化了RNN模型的构建、训练和回测流程,让开发者能将精力聚焦于特征工程和业务逻辑本身。进阶需求实现:展示了如何通过加入外生变量来丰富模型的信息输入,以及如何利用共形预测对预测结果的不确定性进行量化,满足了更高级的决策支持需求。工程实践启示:讨论了GPU训练、自定义损失函数等实际应用中会遇到的工程问题,为模型从理论原型走向生产部署提供了思路。
本文配套的论文建模可直接套用的AI智能体、完整代码包、实证分析,可加小助手:tecdat_cn。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据
Python定制Claude Managed Agent智能体实现销售数据自动化开发|附AI智能体、代码和数据

