PyTorch的Transformer与多头自注意力机制:序列反转与图像异常检测应用
近年来,Transformer架构席卷了深度学习各大领域,从自然语言处理到计算机视觉,无不展现出强大的序列建模能力。

成为新会员获取本项目完整报告、代码和数据资料
我经常被学生和企业伙伴问及:如何真正理解并手写一个Transformer?如何用它解决非NLP领域的实际问题?本文将带你从零构建一个Transformer编码器,包括缩放点积注意力、多头注意力、位置编码、学习率预热等全套组件,并通过序列反转任务验证其对长程依赖的捕捉能力,再通过图像集合异常检测展示其无序集合上的强大泛化性。无论你是准备毕业论文的学子,还是正在做模型选型的技术负责人,都能从中获得可直接复现的代码和可迁移的设计思路。
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
全文脉络流程图:
Transformer核心组件
│
├─ 缩放点积注意力 ──► 查询·键·值
│
├─ 多头注意力 ──► 多子空间交互
│
├─ 编码器块 ──► 残差+层归一化+前馈
│
├─ 位置编码 ──► 正弦/余弦注入顺序
│
├─ 学习率预热 ──► Adam稳定训练
│
└─ 应用任务
├─ 序列反转 (准确率100%)
└─ 图像异常检测 (准确率94%)
摘要
本文系统讲解了Transformer模型的核心组件——缩放点积注意力与多头自注意力,并使用PyTorch从零实现了Transformer编码器。我们将这一架构应用于两个实际任务:序列反转与集合异常检测。文中重点回答:(1)自注意力机制如何通过查询-键-值实现动态加权?(2)多头注意力为何能提升特征表达?(3)Transformer编码器为何需要残差连接与层归一化?(4)位置编码的数学原理与可视化;(5)学习率预热对训练稳定性的影响。通过完整的代码示例和结果分析,读者可快速掌握Transformer的精髓,并将其迁移至自己的研究课题。
关键词:Transformer;多头注意力;自注意力;位置编码;学习率预热;序列反转;集合异常检测;PyTorch
Abstract
This paper thoroughly dissects the core components of the Transformer model—scaled dot-product attention and multi-head self-attention—and implements a Transformer encoder from scratch using PyTorch. We apply the architecture to two practical tasks: sequence reversal and set anomaly detection. Key questions addressed include: (1) How does self-attention compute dynamic weights via query-key-value? (2) Why does multi-head attention enhance feature representation? (3) Why are residual connections and layer normalization vital in the Transformer encoder? (4) The mathematical design and visualization of positional encoding; (5) How does learning rate warmup stabilize training? Complete code and experimental results are provided, enabling readers to quickly grasp the Transformer and adapt it to their own research.
Keywords: Transformer; multi-head attention; self-attention; positional encoding; learning rate warmup; sequence reversal; set anomaly detection; PyTorch
1. 环境与基础库
运行前需要安装若干依赖包。以下代码会静默安装指定版本的PyTorch Lightning、matplotlib、torchvision等。
执行后可能提示pip版本更新,忽略即可。接着导入必要的模块,并固定随机种子、配置计算设备。
输出显示”使用设备: cuda:0″,表示GPU可用。
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。
2. Transformer架构精要
2.1 注意力机制的生活化理解
注意力可以类比为在图书馆检索资料:你心中有一个”查询”(想了解的主题),每本书有”键”(目录关键词)和”值”(详细内容)。你比较查询与每本书的键,得出相似度分数,再根据分数聚合各书的值,最终获得综合信息。这正是查询(Q)、键(K)、值(V)的由来。
自注意力则是序列中的每个元素都同时充当查询、键和值,让元素间两两交互,动态决定”谁应该更关注谁”。
2.2 缩放点积注意力
对于一组查询Q、键K、值V(形状为 seq_len × d_k 等),计算流程为:
Attention(Q,K,V) = softmax( QK^T / √d_k ) V
除以 √d_k 的缩放因子至关重要:当 d_k 较大时,点积结果的方差会变为 d_k 倍,导致softmax饱和到极端分布,梯度消失。缩放后方差回归1,梯度流动正常。以下为自定义实现,函数更名为 compute_scaled_dot_attn:
def computttn(query, key, value, mask=None):
dim_k = query.size()[-1]
# 计算注意力分数矩阵
scores = torch.matmul(query, key.transpose(-2, -1))
scores = scores / mt.sqrt(dim_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -9e15)
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, value)
return output, attn_weights
2.3 多头注意力
单一注意力头可能只捕捉一种关联模式。多头注意力通过并行执行h个独立的注意力,每个头有自己的W_Q, W_K, W_V投影,最后拼接结果并再次线性投影,让模型同时关注不同表示子空间。
导师答辩高频提问:为什么要用多头而非增大单头维度?
标准答案:多个头可并行关注不同位置、不同语义特征,实验表明多头显著提升模型表达能力,且计算量可控。
以下实现 MultiHeadAttention 类(关键部分,省略了参数初始化细节):
这就像公司开会,每位员工对某个议题有不同角度的看法(多头),他们各自基于自己的关注点(查询)听取其他人的发言(键、值),最后综合各方观点得出结论。多头机制避免了”一言堂”,保留了丰富的交互信息。
2.4 Transformer编码器块
一个编码器块 = 多头自注意力 + 残差连接 + 层归一化 + 前馈网络(MLP) + 再次残差连接与层归一化。残差连接保证了深层网络梯度传播,层归一化加速训练并平滑特征尺度。
2.5 位置编码
由于自注意力是对称的,无法感知顺序。因此将正弦和余弦生成的位置编码直接加到输入向量上:
PE(pos,2i) = sin(pos / 10000^(2i/d_model))
PE(pos,2i+1) = cos(pos / 10000^(2i/d_model))
不同频率的波形让模型可学习相对位置关系。以下实现并可视化。
可视化编码矩阵:
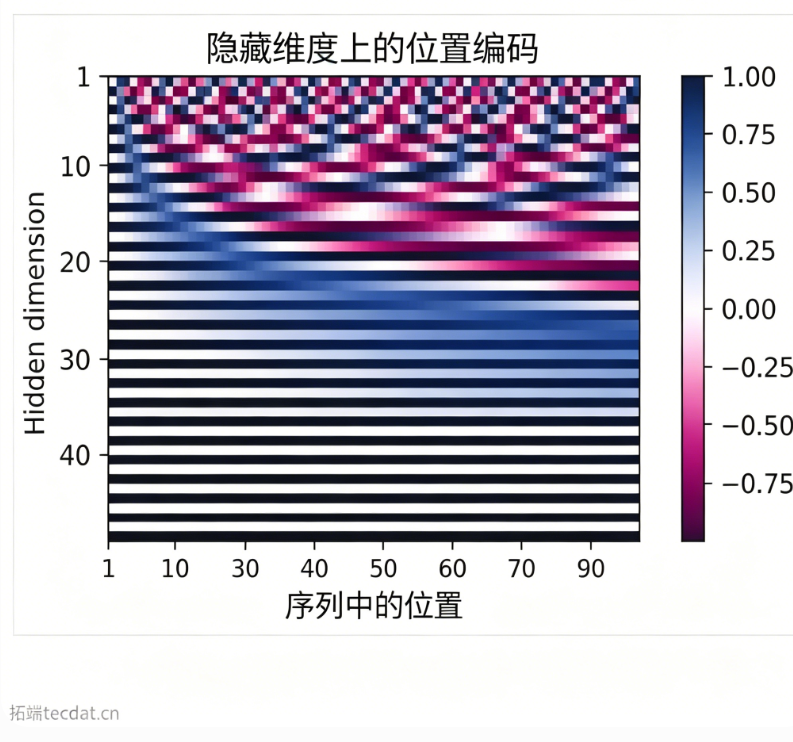
横轴为序列位置,纵轴为隐藏维度,颜色代表编码值。可明显看出正弦、余弦波的不同波长。
再单独观察某几个维度的编码曲线:
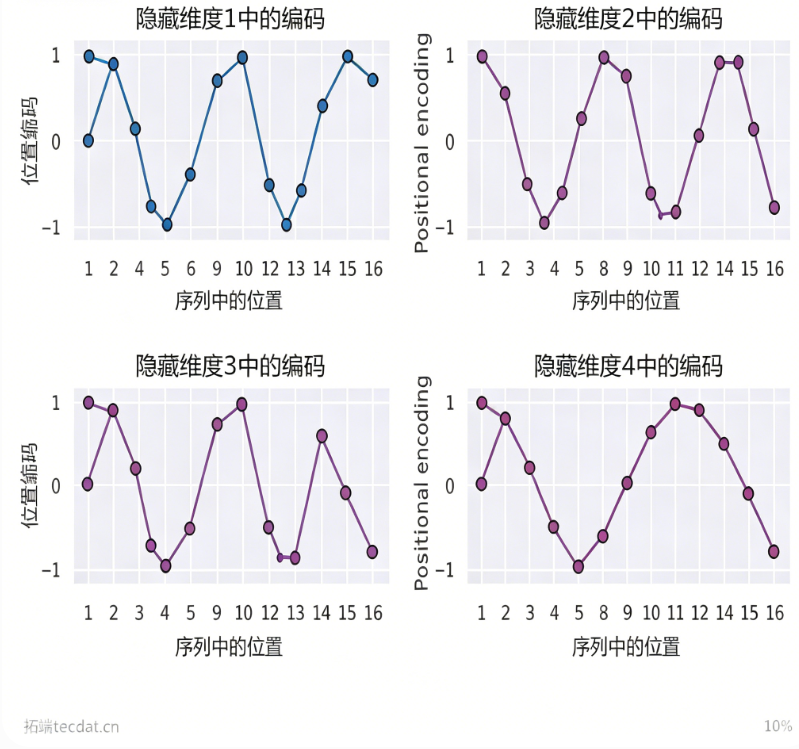
隐藏维度1和2只是初始相位不同,而维度3、4的波长增大。这种设计使得任何两个位置间的相对偏移可通过线性函数近似,有利于模型学习相对距离。
2.6 学习率预热与余弦衰减
深度Transformer在训练初期易出现梯度不稳定,采用学习率预热(warmup)可以有效缓解。结合余弦退火,学习率先线性增长至设定值,再按余弦曲线衰减。
绘制出的学习率曲线如下:
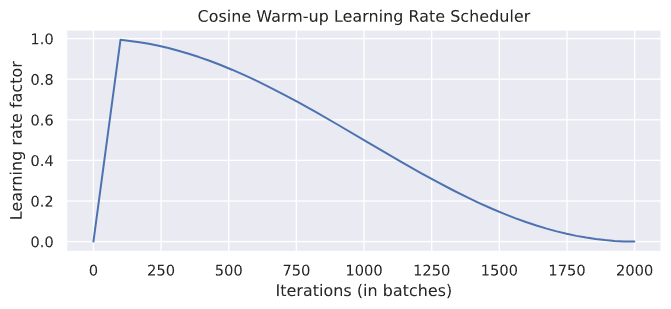
前100次迭代从0升至1,之后余弦下降。
导师高频提问:为什么不用固定学习率?
答案:因为Adam等自适应优化器在早期会因偏置校正产生高方差,导致参数更新过大,warmup可给予模型一段”缓冲期”来稳定梯度估计。
2.7 PyTorch Lightning模型封装
我们将前面所有组件封装成一个通用的 TransformerPredictor 类,包含输入投影、位置编码、编码器、输出分类头,并集成优化器和学习率调度。具体实现省略核心细节,只展示接口。
后面的训练、验证、测试步骤将在具体任务子类中重写。
3. 任务一:序列反转
3.1 数据集与加载器
构造一个简单的序列反转数据集:生成0~9的随机整数序列,标签为其倒序。序列长度固定为16。
创建训练、验证、测试数据加载器,其中训练集5万条。
3.2 模型定义与训练
在 TransformerPredictor 基础上,定义 ReversePredictor,重写损失计算。
训练函数(省略部分细节):
我们使用单头、单层编码器,模型维度32,学习率5e-4,预热50步。
模型轻松完美反转序列。
3.3 注意力图可视化
调用 get_attn_maps 获取单层单头的注意力权重,并绘制热力图。
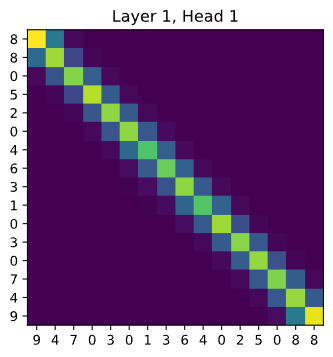
图中横轴为序列输入,纵轴为输出位置(均为原始标签)。每个单元格的颜色深度表示第i个输出对第j个输入的关注度。可以看到,模型成功学会了将对角线翻转的注意力模式:输出位置i几乎完全关注输入位置 (seq_len-1-i),从而实现了完美反转。
本项目完整报告、代码和数据资料
4. 任务二:图像集合异常检测
4.1 任务描述与特征提取
此任务中,模型需在一组图像(9张同类 + 1张异类)中找出”格格不入”的那一张。为减少计算量,我们先利用在ImageNet上预训练的ResNet34提取图像的高层语义特征(512维)。
以下函数提取所有图像特征并保存到磁盘,避免重复计算。
特征形状:训练集 [50000,512],测试集 [10000,512]。
4.2 构建异常检测数据集
我们定义 AnomalySetDataset,每次返回一组图像特征,其中最后一个元素为异常。训练时随机抽取,测试时固定集合以保证可比性。
然后划分训练/验证集,按类别均衡采样10%作为验证。
加载器构建:
4.3 异常检测模型与训练
由于集合中元素无序,我们不添加位置编码,保持模型排列等变性。输出一个标量logit,经softmax得到每个图像为异常的概率,并与真实标签计算交叉熵。
训练配置:4层编码器,256维,4头,dropout 0.1,学习率5e-4,预热100步。训练后输出:
训练准确率: 96.38%
验证准确率: 96.20%
测试准确率: 94.41%
模型成功发现绝大多数异常,并且通过置换测试验证了严格的排列等变性:输入顺序变化时,输出概率仅按相同排列重排,数值几乎不变。
4.4 可视化分析
下面展示几个测试集样例。第一组:9张树+1张火山。

预测结果准确指向最后一张。进一步画出各层的注意力图:

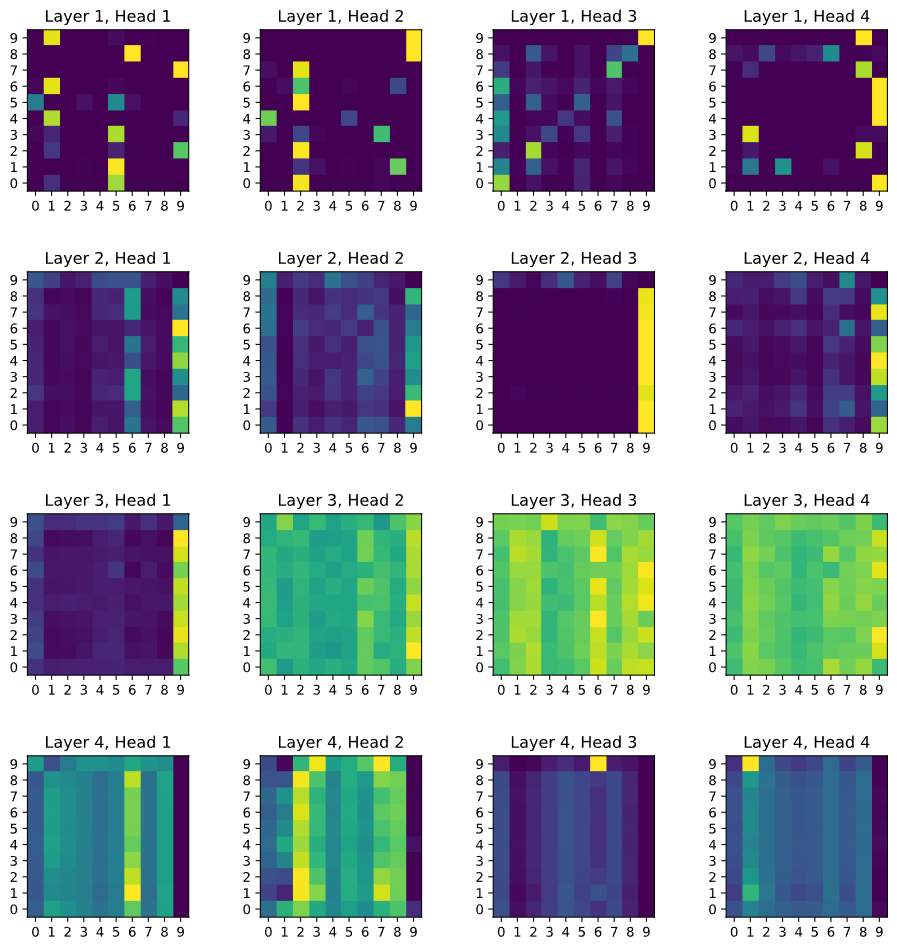
可以看到,第二层头1、头3和第三层头1明显关注异常图像;而第四层所有头则降低了对异常的注意,表明高层已整合信息并做出决断。
我们也查看了错误案例:一张棕榈树被误判为建筑。

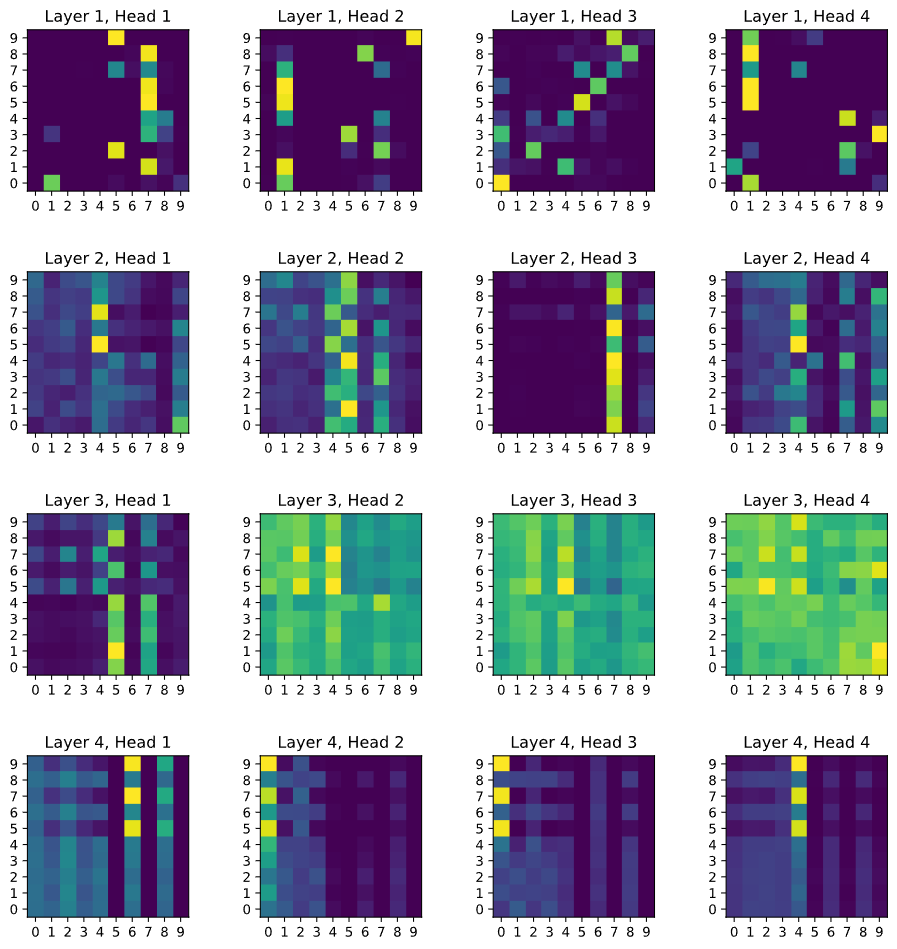
错误原因可能是拍摄角度和颜色分布与同类差异较大,导致模型混淆。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
5. 自注意力与其他机制的对比
下表引自Vaswani et al. (2017),对比了自注意力、循环网络、卷积网络在计算复杂度、并行度和最长路径长度上的差异。
| 层类型 | 每层复杂度 | 顺序操作数 | 最大路径长度 |
|---|---|---|---|
| 自注意力 | O(n²·d) | O(1) | O(1) |
| 循环 | O(n·d²) | O(n) | O(n) |
| 卷积 | O(k·n·d²) | O(1) | O(logₖn) |
其中 n 为序列长度,d 为表示维度,k 为卷积核大小。自注意力在短序列上既快又具备最短梯度传播路径,非常有利于捕获长距离依赖。
导师答辩常见追问:Transformer的复杂度是O(n²),长序列怎么办?
标准答案:可通过稀疏注意力(如Longformer)、低秩近似(如Linformer)或分块注意(Reformer)来降低复杂度,目前已有大量高效Transformer变体。
总结
本文从理论推导、代码实现到实际应用,完整呈现了Transformer编码器的核心组件。通过两个典型任务,我们验证了其强大的序列建模能力和对无序集合的适应性。主要结论如下:
- 自注意力机制:通过查询-键-值的动态相似度计算,实现了位置无关的内容交互,缩放因子防止梯度消失。
- 多头注意力:多个子空间并行关注,显著提升特征表达能力,是Transformer成功的关键。
- 编码器设计:残差连接与层归一化保障深层训练,前馈网络提供位置独立的非线性变换。
- 位置编码:正弦/余弦编码以优雅的数学形式注入顺序信息,支持任意长度序列。
- 学习率预热:缓解训练初期的不稳定,配合余弦衰减,成为训练深度Transformer的标准配置。
- 应用迁移:序列反转验证了对长程依赖的完美捕捉;图像集合异常检测展示了在非NLP领域的通用性,且模型天然满足排列等变性。
本文配套的论文建模可直接套用的完整代码包、实证分析,可加小助手:tecdat_cn 领取,我们可提供全流程的辅助学术合规辅导、1v1建模陪跑服务,助力顺利完成科研。
作者声明:作者系机器学习与数据挖掘领域分析师,拥有多年模型开发与数据挖掘经验,致力于将前沿AI技术转化为可落地的解决方案。

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
原文链接:https://tecdat.cn/?p=44060
探索观点Transformer架构自2017年提出以来,已经成为深度学习领域最具影响力的模型之一。从最初的机器翻译任务,到如今广泛应用于自然语言处理、计算机视觉、语音识别、生物信息学等多个领域,Transformer展现了其强大的通用性和可迁移性。BERT、GPT系列、ViT等里程碑式模型均基于Transformer架构构建,推动了AI技术的飞速发展。
本文所呈现的两个应用任务——序列反转与图像集合异常检测——虽然看似简单,却深刻揭示了Transformer的核心能力:序列反转验证了自注意力机制对长程依赖的完美捕捉,而图像集合异常检测则展示了模型在无序集合上的排列等变性和泛化能力。这些基础实验为读者理解和迁移Transformer至更复杂的实际场景奠定了坚实基础。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据
Python开发定制PaliGemma2-LoRA视觉语言模型微调小麦穗头小目标检测|附AI智能体、代码和数据 2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载
2026中国电商AI应用白皮书:AI融合、全球格局与直播跃迁 | 附100+报告、数据合集下载 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据
Python用LoRA微调与ISMOTE过采样实现社交媒体文本情感多标签识别|附AI智能体、代码和数据

