Python深度强化学习RL用GAT、GraphSAGE、GCN图神经网络PPO环境建模
作为在谷歌深耕机器学习、算法与数据挖掘的技术人,同时也在高校指导学生,我始终关注如何将前沿的图学习方法落地到实际的序贯决策场景。

成为新会员获取本项目完整报告、代码和数据资料
过去几年,图神经网络(GNN)在建模关系型数据方面取得了瞩目成绩,但在强化学习(RL)领域的应用却长期滞后。很多业务场景——如物流调度、算力网络、多智能体协同——天生就是图结构,传统架构(MLP、CNN)要求固定尺寸的输入和输出,难以适应动态变化的节点和边。
本文旨在系统梳理GNN融入深度强化学习的关键设计模式,并给出可运行的实现示例。希望能帮助更多研究者和从业者解锁图结构环境下的智能决策能力。
阅读原文进群获取本文完整代码数据及更多最新AI见解和行业洞察,可与900+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路;遇代码运行问题,更能享24小时调试支持。
摘要
- 图神经网络(GNN)如何解决传统深度强化学习(RL)中的排列敏感、固定输出维度、固定输入尺寸等问题?
- 如何将环境建模为图,并设计动态动作空间(如邻居节点、节点评分、原型动作等)?
- 在加权最小顶点覆盖(Weighted MVC)任务中,GNN结合PPO的训练效果与无效动作屏蔽策略的优势如何体现?
- 如何基于PyTorch Geometric和Stable Baselines3实现可跨图大小的GNN‑RL策略?
Abstract
- How do Graph Neural Networks (GNNs) address permutation sensitivity, fixed output dimensions, and fixed input sizes in conventional deep RL?
- How to model environments as graphs and design dynamic action spaces (neighbor‑based, node‑scoring, proto‑action, etc.)?
- What are the training outcomes of GNN‑PPO on the Weighted Minimum Vertex Cover (MVC) task, and why is action masking critical?
- How to implement a cross‑graph‑size GNN‑RL policy using PyTorch Geometric and Stable Baselines3?
全文脉络流程图:
图神经网络 (GNN) 基础
│
├─ 消息传递框架 ── 聚合邻居 → 更新节点嵌入
│
└─ 传统RL局限 ── 排列敏感、固定维度、输入尺寸固定
│
└─ GNN 的优势 ── 置换不变性、变长动作空间、跨图泛化
│
├─ 环境图设计 ── 节点/边定义、动作空间设计
│ ├─ 固定动作空间(特征提取)
│ ├─ 邻居作为动作
│ ├─ 节点评分动作
│ ├─ 原型动作(Proto‑Action)
│ └─ 边作为动作
│
├─ 无效动作处理 ── 动作屏蔽 vs 惩罚 → 屏蔽效果更优
│
└─ 实现示例 ── 加权最小顶点覆盖 (MVC)
├─ 特征提取器 → MatrixObservationToGraph
├─ 处理器 → GAT / GraphSAGE / GCN
├─ 策略网络 → ProtoActionNetwork
└─ 训练 (PPO) + 跨图测试1 图神经网络与强化学习基础
1.1 强化学习简述
强化学习通过马尔可夫决策过程(MDP)对序贯决策建模。MDP 由状态集 S、动作集 A、转移函数 P、奖励函数 R 和折扣因子 γ 构成。智能体在每个时间步基于策略 π 选择动作,环境返回新状态和奖励,目标是最大化累积回报。
深度强化学习(Deep RL)使用神经网络逼近策略 π 或值函数 Q。典型架构包含观测编码器和策略/价值网络,如图1所示。
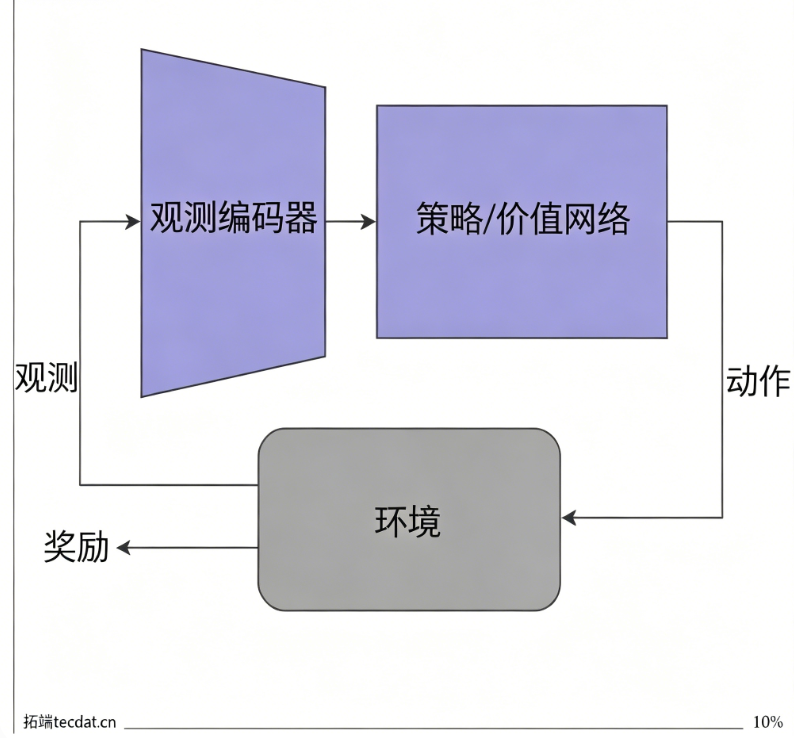
传统架构使用 CNN 处理图像、MLP 处理向量,其输入输出维度固定,这限制了在结构动态变化环境中的应用。
本项目完整报告、代码和数据资料
1.2 图神经网络核心思想
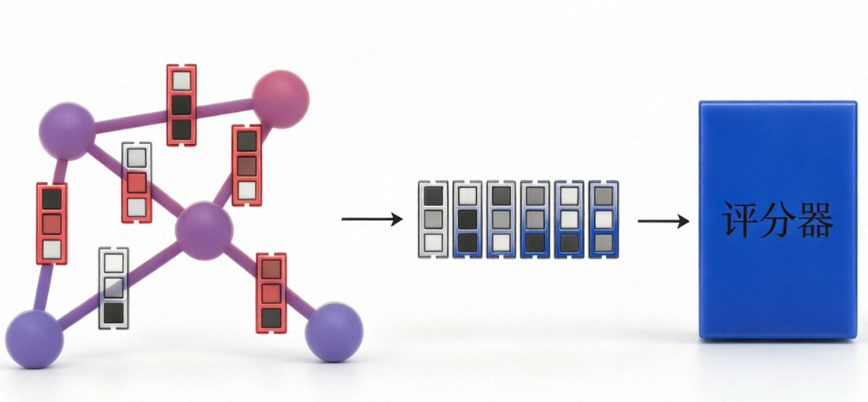
图 G = (V, E) 由节点和边构成,节点与边可带有特征向量。GNN 通过邻域聚合学习节点表示:每一层中,节点通过聚合邻居的消息更新自身嵌入,类似于在图上做卷积。消息传递框架可统一描述多数 GNN:
- 消息函数 M:从邻居节点计算消息
- 更新函数 U:结合自身与聚合消息生成新嵌入
数学上,节点 v 在第 l+1 层的嵌入 h_v^{(l+1)} = U(h_v^{(l)}, Σ_{u∈N(v)} M(h_v^{(l)}, h_u^{(l)}, e_{vu})),其中 e 为边特征。多层堆叠后,每个节点捕获其 k‑跳邻域信息。图级嵌入通过全局池化(如求和、平均、最大值)获得,从而保持置换不变性。
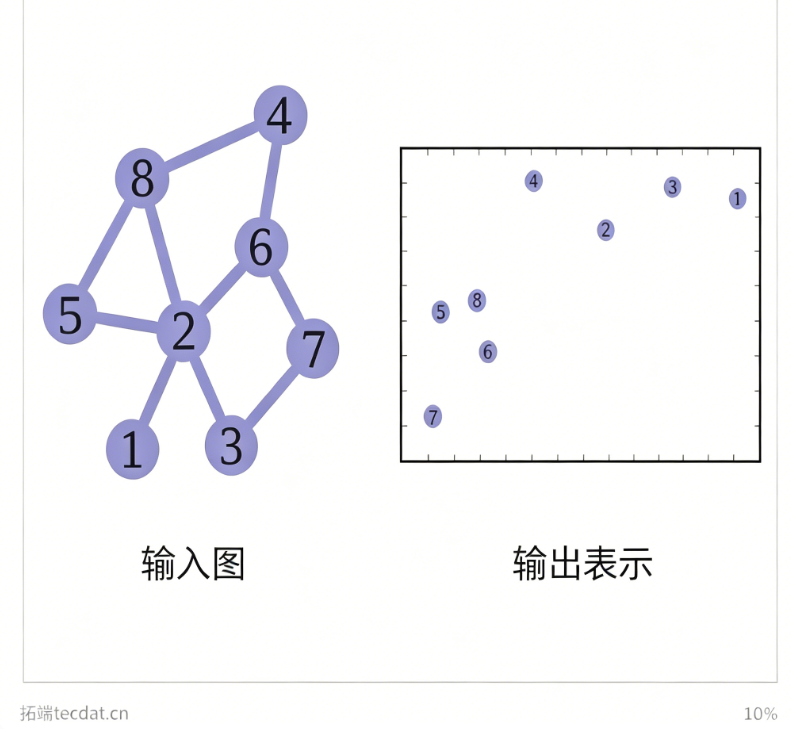
形象理解:消息传递好比朋友聚会,每个人通过听取周围人的意见(邻居消息)来修正自己的想法(节点更新),几轮交流后,每个人对全局的看法趋于综合。这种机制天然忽略了人员编号顺序,只关心关系结构,这就是置换不变性的直观来源。
2 传统架构在深度RL中的三大局限
2.1 排列敏感性
同一幅图的不同邻接矩阵排列,在MLP或CNN眼中是截然不同的输入。GNN则因置换不变性输出一致,大幅压缩了需要学习的等效状态数量。
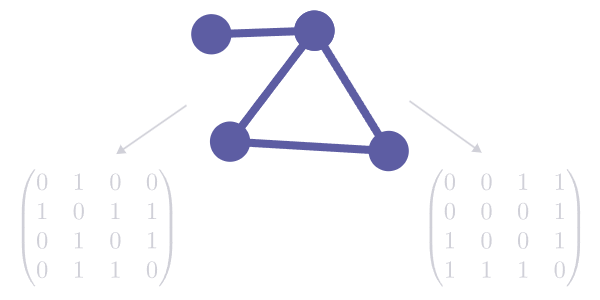
验证测试:随机生成5节点图,生成所有120种邻接矩阵排列,分别输入未训练的MLP、CNN、GNN,观察输出差异。
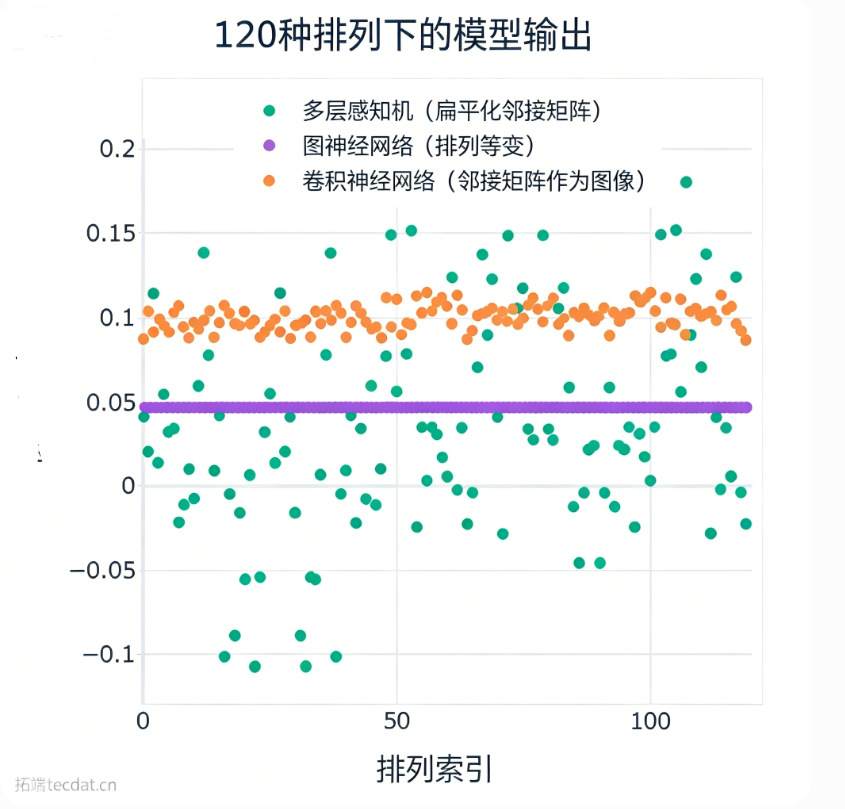
结果显示MLP和CNN输出剧烈波动,GNN则对所有排列输出完全相同的值。这意味着,若用GNN作为策略网络,无需数据增强即可天然处理等价状态。
2.2 固定输出维度
传统RL要求动作数固定,无法应对可变动作空间。例如房间导航中,不同房间的门数量不同,固定动作空间会导致掩码或填充,降低训练效率。GNN可将邻居节点直接作为可选动作,使动作空间随当前节点动态伸缩。
2.3 固定输入尺寸
MLP策略要求固定大小的输入,若在更大图上测试则无法直接推理。GNN的消息传递与图大小无关,可训练于小图,测试于大图,实现泛化。这一特性在组合优化、大规模网络中极具价值。
3 图环境设计核心要素
使用GNN做RL,需要将环境抽象为图,重点回答四个问题:节点是什么?边是什么?节点/边特征有哪些?动作空间如何与图关联?其中动作空间设计最富挑战,下面逐一解析。
3.1 固定动作空间(GNN作特征提取器)
最简单的方式是保留固定动作数,用GNN编码图观测,池化得到图级或节点级嵌入,再送入MLP输出动作分布。
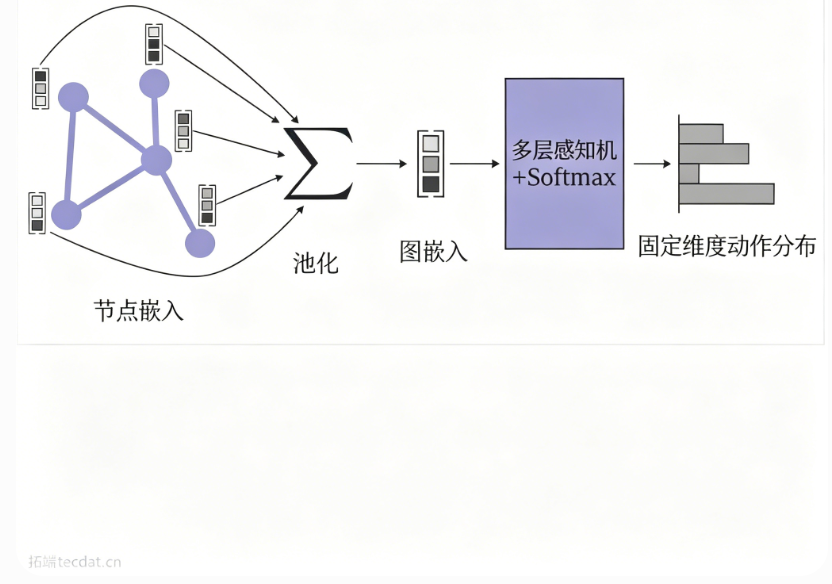
应用案例:多机器人路径规划中,每个机器人利用CNN提取局部观测作为节点特征,通过通信图进行消息传递,最后经MLP+Softmax输出固定动作(上、下、左、右、静止);异构任务分配中也用类似结构实现集中训练、分散执行。
3.2 邻居节点作为动作
适用于智能体位于某节点,需移动到相邻节点的场景。GNN为每个节点生成嵌入,当前节点的邻居嵌入经过评分网络(如MLP)得到分值,再通过Softmax形成选择概率。
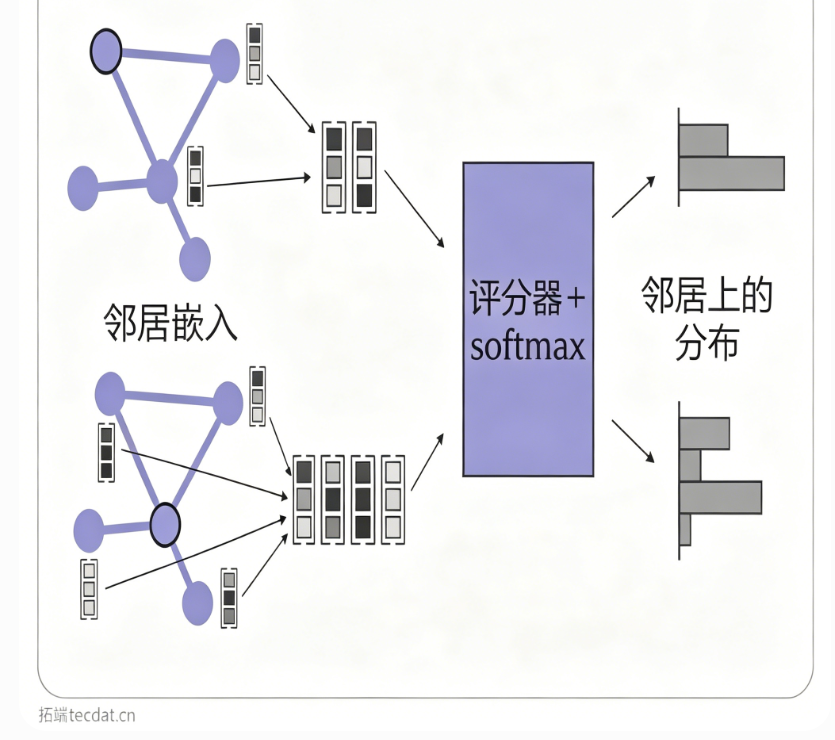
实例:多智能体巡逻问题中,每个智能体根据当前节点邻居的嵌入评分选择下一跳;分布式图搜索中,携带消息的智能体利用目标节点嵌入和邻居嵌入计算值,经Softmax决定转发节点。
3.3 所有节点作为动作——评分机制
将图中所有节点视为可选动作,适用于组合优化问题。GNN输出节点嵌入,经评分函数(如内积、MLP)计算每个节点的价值,再产生动作分布。
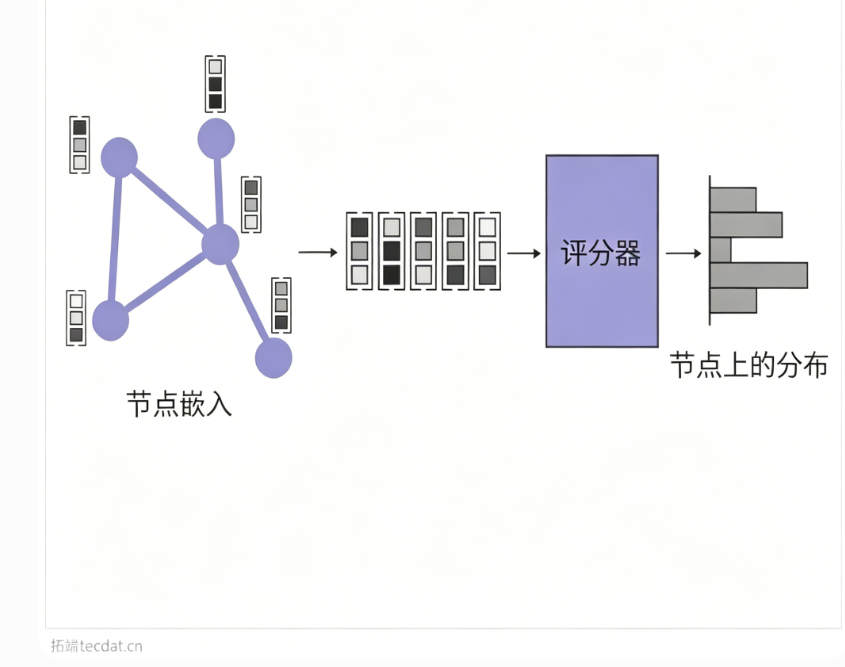
实例:旅行商问题(TSP)和最小顶点覆盖(MVC)中,每步选择一个节点加入解,Q值由节点嵌入与图嵌入拼接后送入MLP估计;卫星观测调度中,将各层节点嵌入拼接后经线性层压缩为标量logits。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
3.4 原型动作(Proto‑Action)
网络先输出一个”理想动作”的嵌入表示(proto‑action),再与所有候选节点嵌入计算相似度(如欧氏距离、余弦相似度),得到动作分布。
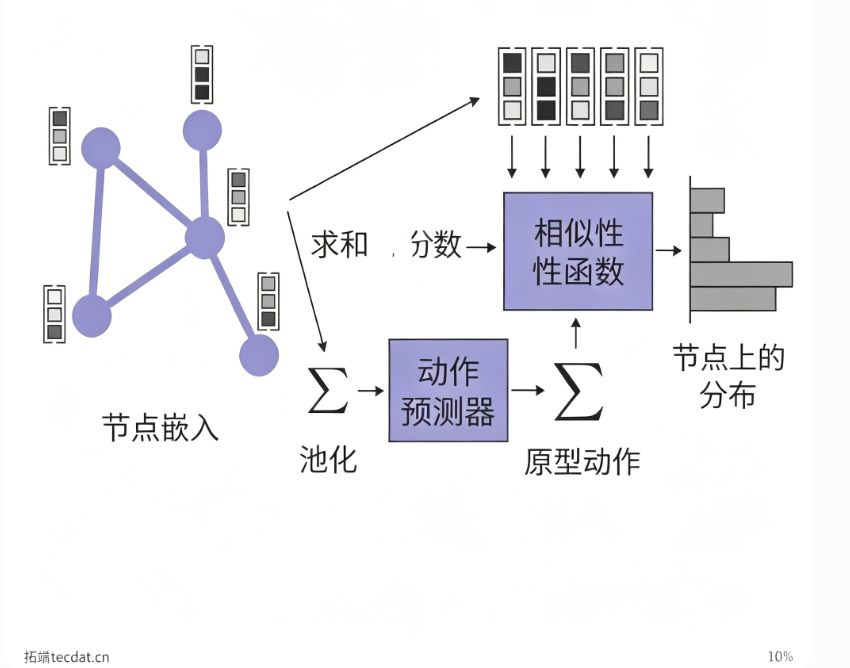
优势:原型动作由整个图状态提炼而来,能自适应图的大小变化,且相似度匹配使动作选择更稳定。在公共品博弈和最大独立集问题中,原型动作由全局池化嵌入经过MLP得到,再与节点嵌入计算欧氏距离后Softmax生成概率。
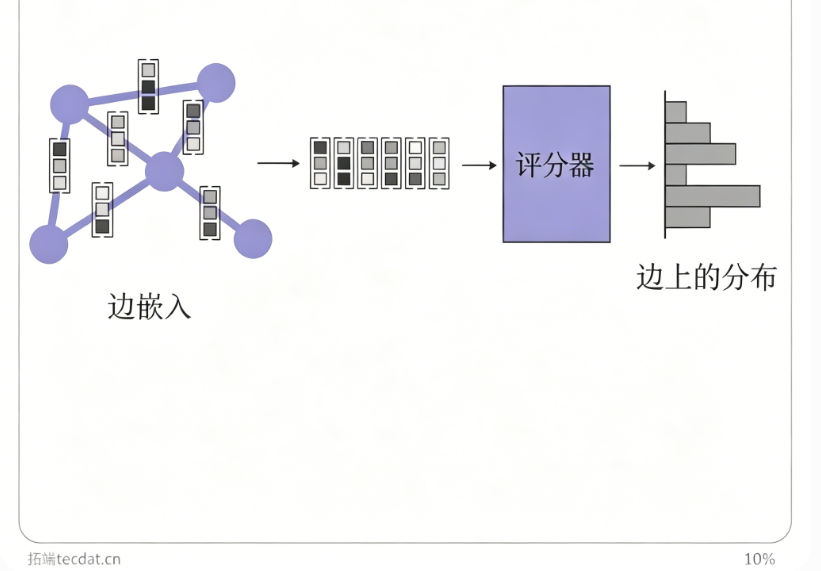
3.5 边作为动作
当决策对象是边(如网络路由、图中边扰动)时,可将边选择分解为两次节点选择,或直接计算边嵌入。边嵌入可通过边‑中心GNN、节点嵌入拼接或线图转换获得。然后使用评分或原型动作方法生成边分布。
4 无效动作处理策略对比
图结构环境中,很多动作在某状态下无效(如重复选择已覆盖节点)。常用两种应对方法:
- 动作屏蔽:输出分布前将无效动作概率置零并重新归一化,强制只选有效动作。
- 无效动作惩罚:允许选择无效动作,但给予负奖励,让智能体自行学会规避。
我们在加权最小顶点覆盖(MVC)任务上对比了二者效果。采用相同的GNN架构(2层GraphSAGE)和PPO超参,训练于5、10、15节点随机图,验证于15节点图。无效动作惩罚设置为‑1,并限制最大步长等于节点数以控制长度。
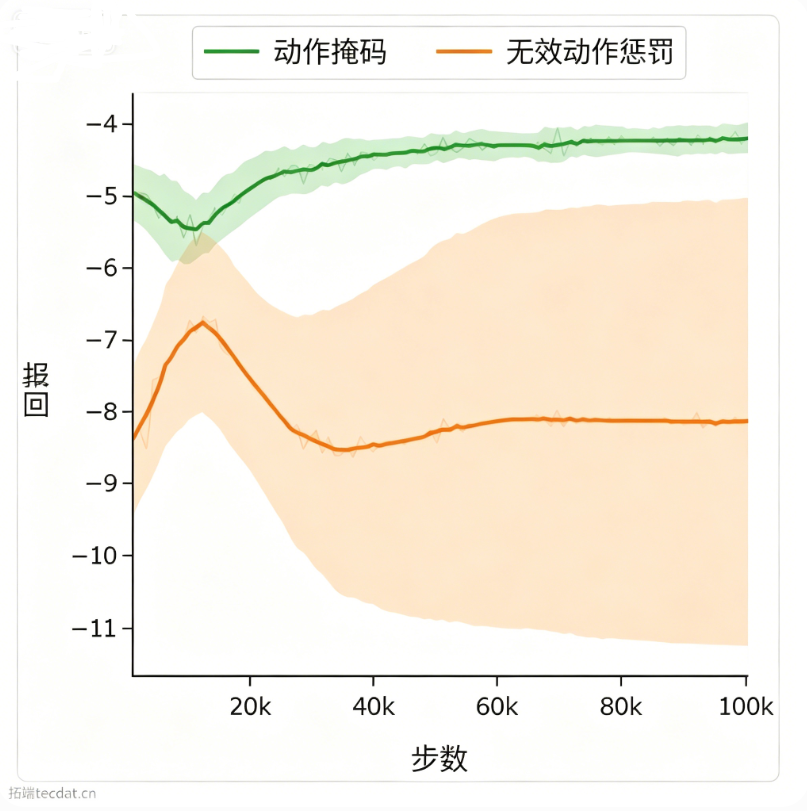
5条随机种子下的验证曲线显示:动作屏蔽能快速稳定收敛到高质量策略,而惩罚机制受初始化影响大,多数种子无法学到有效策略,说明在动态无效动作集场景中,动作屏蔽是更可靠的选择。
5 实现示例:加权最小顶点覆盖
下面使用PyTorch Geometric和Stable Baselines3(SB3)搭建GNN‑PPO策略,解决加权MVC问题。环境为:给定无向图 G=(V,E),节点带有权重 w_i,目标选择节点子集 C 覆盖所有边,同时最小化总权重 Σ_{i∈C} w_i。每步选择一个节点加入覆盖集,直至所有边被覆盖。
核心挑战:动态有效动作(不能选已选节点)、变长图、置换不变状态表示。
5.1 SB3集成要点
SB3要求观测和动作空间为固定维度,因此我们设置 max_nodes 作为最大节点数,观测以字典形式给出固定大小的矩阵,特征提取器负责转换为PyTorch Geometric的Data对象,并在转换时剔除填充部分。该 max_nodes 仅在训练时约束存储,GNN本身无此限制,测试时可更改以处理更大图。
5.2 整体架构
沿用SB3的Actor‑Critic范式,使用 MaskableActorCriticPolicy 基类以支持动作屏蔽。架构分为三部分:
- 特征提取器:
MatrixObservationToGraph,将矩阵观测转为图Data对象。 - 图处理器:
GraphActorCriticProcessor,包含GNN骨干,输出节点嵌入和图嵌入,供Actor和Critic共享。 - 策略头与价值头:策略头采用原型动作网络
ProtoActionNetwork;价值头由SB3自动构建的MLP给出。
5.3 特征提取器
环境观测字典键为 node_features(max_nodes × node_dim)、edge_features(max_nodes × max_nodes × edge_dim)、adjacency_matrix(邻接矩阵)。提取器去除全零行(填充节点),构建PyTorch Geometric Batch。
5.4 图处理器(GNN骨干)
定义可配置的GNN,本例提供GAT、GraphSAGE、GCN三种实现,并统一为 GraphProcessor 类,输出节点嵌入和图级嵌入。
5.5 原型动作策略网络
阅读原文进群获取完整内容及更多AI见解、行业洞察,与900+行业人士交流成长。

DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌|附完整代码数据
DeepSeek、LangGraph和Python融合LSTM、RF、XGBoost、LR多模型预测NFLX股票涨跌
探索观点5.6 完整策略装配
class MaskableGraphActorCriticPolicy(MaskableActorCriticPolicy):
"""
带动作屏蔽的图Actor‑Critic策略
"""
def __init__(self, observation_space, action_space, lr_schedule,
embed_dim=128, pooling_type='mean', dist_metric='euclidean',
temperature=1.0, gnn_type='gat', **kwargs):
self.embed_dim = embed_dim
# 覆盖默认特征提取器
kwargs.setdefault("features_extractor_class", ObservationToGraphExtractor)
super().__init__(observation_space, action_space, lr_schedule, **kwargs)
# 替换策略网络为原型动作网络
self.action_net = ProtoActionPolicy(
embed_dim=embed_dim, max_node_cnt=action_space.n,
dist_metric=dist_metric, temperature=temperature
)
def _build_mlp_extractor(self):
self.mlp_extractor = GraphProcessor(
node_dim=self.observation_space['node_features'].shape[-1],
edge_dim=self.observation_space['edge_features'].shape[-1],
embed_dim=self.embed_dim,
pooling=self.pooling_type,
gnn_type='gat' # 可切换为 'gcn', 'sage'
)5.7 环境接口(MVC)
5.8 训练与跨图测试
使用SB3的PPO进行训练,训练图随机生成5、10、15节点,验证集为15节点图。
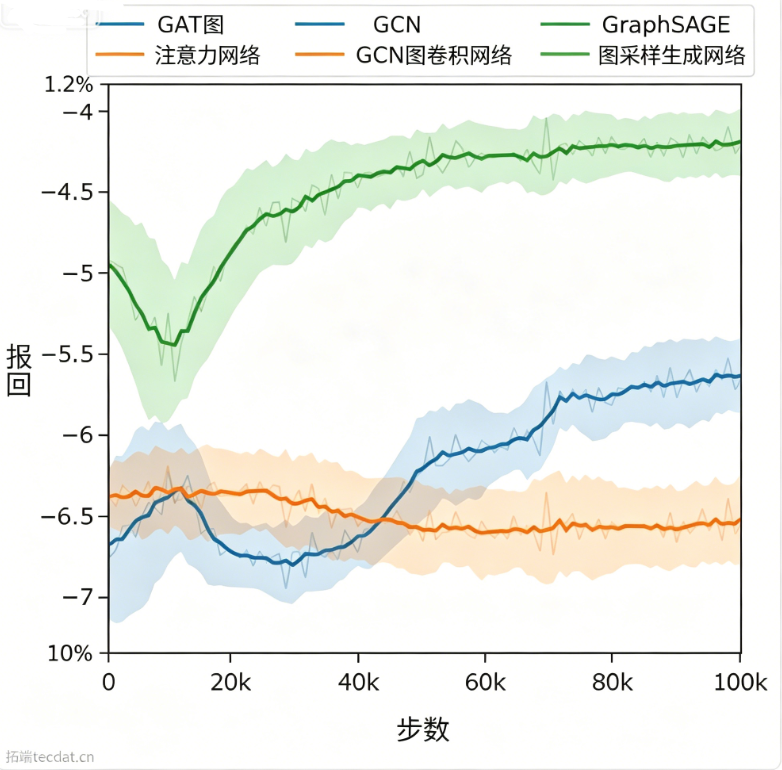
GAT和GraphSAGE表现出稳定提升,GCN因过度平滑问题性能较弱。默认超参下GraphSAGE取得最优平均奖励。
测试更大图(20节点)时,只需创建新环境并调用下述函数加载权值:
def adapt_policy_to_env(policy, new_env):
params = policy._get_constructor_parameters()
params["observation_space"] = new_env.observation_space
params["action_space"] = new_env.action_space
new_policy = type(policy)(**params)
new_policy.load_state_dict(policy.state_dict())
return new_policy各模型在20节点测试集上的表现如下:
| 模型 | 平均奖励 | 平均幕长 |
|---|---|---|
| GAT | -8.02 ± 1.42 | 17.31 ± 0.80 |
| GCN | -8.60 ± 1.41 | 17.76 ± 0.97 |
| GraphSAGE | -5.82 ± 1.21 | 14.47 ± 0.97 |
GraphSAGE依然表现最佳,验证了GNN‑RL策略跨图尺寸的泛化能力。
6 总结
- 核心价值:GNN为RL提供了置换不变的状态编码、自适应动作空间和跨图尺寸泛化三大关键能力,尤其适合组合优化、多智能体和资源分配等图结构问题。
- 动作空间设计:介绍了固定动作、邻居动作、节点评分、原型动作、边动作五种模式,其中原型动作方法在可变动作空间和泛化性上优势突出。
- 无效动作屏蔽优于惩罚:实测结果表明,在动态无效动作环境下,动作屏蔽比负奖励惩罚更稳定、更高效。
- 工程实现:基于PyTorch Geometric和Stable Baselines3,给出了完整的GNN‑PPO策略实现,并验证了在加权MVC任务上的有效性及跨图泛化。
- 未来方向:需进一步探索混合动作空间(离散‑连续)、异质图支持、长程依赖缓解,以及标准化图‑RL库和基准。
图神经网络与强化学习的结合仍处于快速发展阶段。从理论基础到工程实践,从算法设计到实际部署,每个环节都充满机遇与挑战。本文所展示的GNN‑PPO框架仅是一个起点,未来还有更多值得探索的方向——异质图结构下的策略学习、连续动作空间与离散动作空间的混合决策、以及更大规模图上的高效训练方法等。期待更多研究者加入到这一交叉领域,共同推动图结构智能决策的发展。
随着图数据在各行各业的普及,GNN‑RL技术将在更多实际场景中发挥作用。无论是智慧城市的交通调度、通信网络的资源分配,还是生物医药的分子设计,图结构无处不在。将强化学习的决策能力与图神经网络的表示能力相结合,有望为这些复杂系统带来更智能、更高效的解决方案。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据
Python、R开发SMOTE过采样随机森林与粒子群算法(PSO)融合模型实现肥胖等级预测|附AI智能体、代码和数据 Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据
Python、R开发K-Means、CART、LR、SVM、BP神经网络五模型对比实现电信客户流失预测挽留|附AI智能体、代码和数据 Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据
Python开发LR、SVM、DT、HistGB及XGBoost多模型对比实现学生抑郁风险预测|附AI智能体、代码和数据 2026化工行业深度报告:AI算力、航天与双碳材料 | 附100+报告、数据合集下载
2026化工行业深度报告:AI算力、航天与双碳材料 | 附100+报告、数据合集下载