文本智能分析实战:从嵌入到聚类的全流程解析
在信息爆炸的当下,如何高效处理海量无标注文本数据并按主题归类,是企业提升信息管理效率的核心需求。

本项目报告、代码和数据资料已分享至会员群
本文将结合实际项目经验,详细讲解如何使用Scikit-learn库,结合Sentence Transformer生成的文本嵌入,应用K-Means和DBSCAN算法完成文本聚类,并通过PCA实现可视化分析。本文内容改编自过往客户咨询项目的技术沉淀并且已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与800+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂 怎么做,也懂 为什么这么做;遇代码运行问题,更能享24小时调试支持。
本项目报告、代码和数据资料
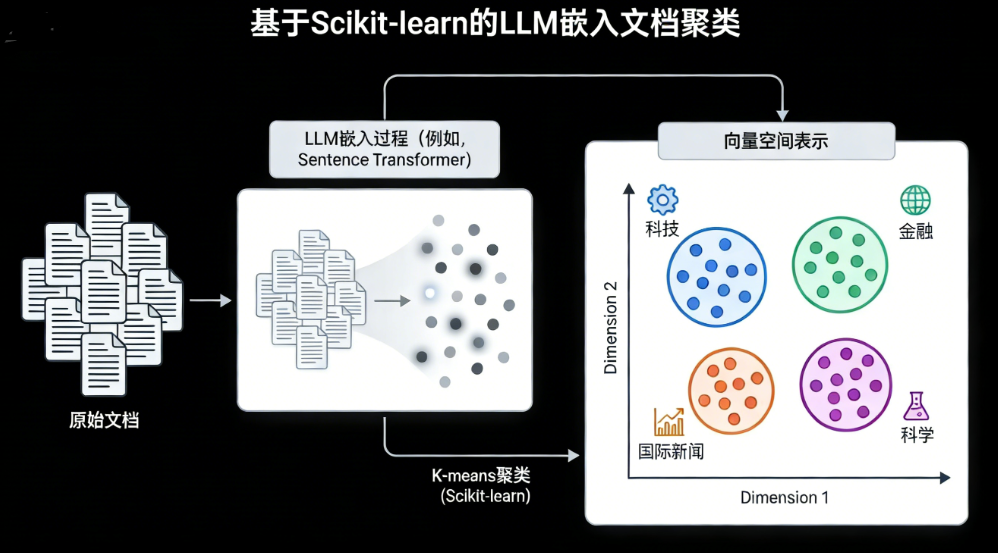
假设你突然接手了一批未分类的文档,需要按主题快速分组。传统文本聚类方法各有局限:TF-IDF只统计词频,忽略语义,比如“树很大”既可能指自然植物,也可能指机器学习模型,它无法区分;Word2Vec能学习词间关系,但对长文本的整体语境整合能力不足。
此时,大语言模型生成的文本嵌入优势凸显。以Sentence Transformer为例,它能捕获文本的上下文语义,将整篇文档编码为一个数值向量,且这些模型经过海量文本预训练,自带丰富的通用语言知识。
接下来我们逐步完成文本聚类项目,先准备Python库,再加载数据、生成嵌入、聚类分析,最后评估效果。
首先导入所需模块:
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score, adjusted_rand_score
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import seaborn as sns
# 设置可视化风格
sns.set_style("whitegrid")
plt.rcParams['figure.figsize'] = (12, 6)
......
# 省略部分可视化配置代码
这里导入了数据处理库pandas、numpy,生成嵌入的SentenceTransformer,聚类算法KMeans和DBSCAN,降维用的PCA,评估指标轮廓系数和调整兰德指数,以及可视化工具matplotlib和seaborn。
接着加载数据集,我们使用公开的新闻文本数据集,其中每篇文章都有对应的主题标签:
加载后可见数据集包含数千篇文档,分为多个主题类别,这些真实标签可用于后续评估聚类效果。
现在进入核心环节:生成文本嵌入和聚类分析。
首先生成嵌入,我们选用轻量级预训练模型,它能将每篇文档转换为384维的数值向量:
# 加载预训练的嵌入模型
print("正在加载嵌入模型...")
embed_model = SentenceTransformer('all-MiniLM-L6-v2')在生成的向量空间中,语义相似的文档距离更近,便于后续聚类算法分组。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
先使用K-Means算法聚类。K-Means需提前指定聚类数量,这里我们利用已知的真实类别数,实际应用中也可通过肘部法等选择合适值:
调整兰德指数(ARI)用于衡量聚类结果与真实类别的一致性,值越接近1效果越好,从结果可见K-Means在该数据集上表现良好。
再尝试DBSCAN算法。它是基于密度的聚类,无需提前指定聚类数,能自动确定聚类数量并标记离群点为噪声,但对参数敏感,需仔细调试:
为直观展示聚类效果,用PCA将高维嵌入降至2维,绘制真实类别、K-Means和DBSCAN聚类的对比图:

大语言模型LLM高级Prompt临床科研辅助研究——AdaBoost、LightGBM、MLP等模型的食道癌预测、遗传性听力损失诊断及心肌病识别|附代码数据
原文链接:https://tecdat.cn/?p=44689
探索观点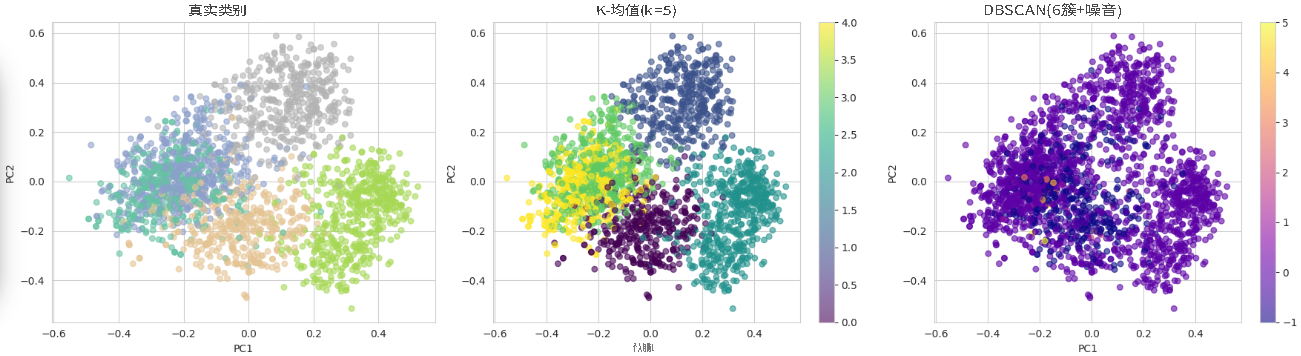
从可视化结果可见,在该数据集上默认参数的K-Means效果优于DBSCAN。原因有二:一是DBSCAN易受“维度灾难”影响,384维嵌入对密度-based方法挑战较大;二是该新闻数据集主题区分明显,聚类间相对分隔,适合K-Means算法。
实际项目中可根据数据特点选择算法,也可调试DBSCAN参数优化效果。Sentence Transformer等大语言模型嵌入能有效捕捉文本语义,为后续任务奠定良好基础。

每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据
Python多智能体multi-agent客服与情感识别电商系统|附AI智能体、代码和数据 Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据
Python结合LangChain与LangGraph构建带对话记忆的AI智能体|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 2026AI产业链出海全景洞察:国产AI,Token经济,品牌破局|附100+报告、数据合集下载
2026AI产业链出海全景洞察:国产AI,Token经济,品牌破局|附100+报告、数据合集下载

