Python房价数据预测
从数据科学视角看,房地产房价预测绝非简单的数值推算,而是对 “业务场景 – 数据质量 – 模型适配” 三者协同的系统性考验。

本项目完整代码和数据文件已分享在交流社群
在房地产行业数字化转型中,精准的房价预测既能帮助购房者规避决策风险,也能为开发商的定价策略、投资者的资源配置提供数据支撑 —— 这正是我们此前为客户提供咨询服务时,客户的核心诉求。当时我们基于真实业务数据搭建的预测模型,成功将客户的房价评估误差降低 15%,而本文内容正是在该项目实践基础上,结合 房价预测数据集(训练集 1460 条、测试集 1459 条,含 81 个多类型变量)进行的标准化梳理。
本文将完整拆解房价预测的全流程:首先针对数据缺失率高、特征偏态明显等核心挑战,通过 “功能型缺失填 None、数值型缺失填 0、区域关联特征填中位数” 的分类策略处理缺失值,再结合复合特征构造(如 TotalSF 房屋总面积)与 Box-Cox 偏态修正优化特征质量;接着对比 Lasso、ElasticNet、XGBoost 等 6 类基础模型的适配性,通过加权平均与 Stacking 集成策略融合模型优势;最后以 RMSLE 为评估指标,用五折交叉验证验证模型稳定性。文中还通过残差分布、特征缺失率、相关性热力图等可视化手段,直观呈现数据特征与模型效果。完整项目代码和数据文件已分享在交流社群,阅读原文进群和 600 + 行业人士共同交流和成长。
业务背景与问题描述
1.1 背景介绍
房地产行业中,房屋价格受到多种因素影响,如地段、房屋面积、建筑年份、装修质量等。能否准确预测房价,不仅影响消费者的购房决策,也对开发商、投资者的商业决策具有重要意义。
本项目使用房价预测数据,目标是在训练集上拟合一个准确的回归模型,以预测测试集中房屋的最终售价。
1.2 问题定义
本问题本质上属于监督学习中的回归问题,预测目标为房屋最终的销售价格。原始数据集包括训练集 1460 条样本、测试集 1459 条样本,每条样本包含 81 个变量(包括类别型、数值型和离散型变量)。
本任务的挑战主要在于特征复杂度高、数据缺失问题严重、特征分布偏态明显以及变量间存在非线性相关性,要求模型既具备较强的拟合能力,又具备较好的泛化性能。
最受欢迎的见解
- Python员工数据人力流失预测:ADASYN采样CatBoost算法、LASSO特征选择与动态不平衡处理及多模型对比研究
- R分布式滞后非线性模型DLNM分析某城市空气污染与健康数据:多维度可视化优化滞后效应解读
- Python古代文物成分分析与鉴别研究:灰色关联度、岭回归、K-means聚类、决策树分析
- Python TensorFlow OpenCV的卷积神经网络CNN人脸识别系统构建与应用实践
- Python用Transformer、SARIMAX、RNN、LSTM、Prophet时间序列预测对比分析用电量、零售销售、公共安全、交通事故数据
- MATLAB贝叶斯超参数优化LSTM预测设备寿命应用——以航空发动机退化数据为例
- Python谷歌商店Google Play APP评分预测:LASSO、多元线性回归、岭回归模型对比研究
- Python+AI提示词糖尿病预测模型融合构建:伯努利朴素贝叶斯、逻辑回归、决策树、随机森林、支持向量机SVM应用
二、数据预处理与特征工程
数据预处理与特征工程是影响模型性能的关键步骤。以下是在此阶段的主要工作:
2.1 缺失值处理
对于缺失表示某项功能缺失的变量,如泳池质量(PoolQC)、车库类型(GarageType)、壁炉质量(FireplaceQu)等,我们将其填充为“None”;对于数值类型变量,如车库建造年份(GarageYrBlt)和砖石面积(MasVnrArea)等,将缺失值填充为0。针对地块前沿长度(LotFrontage),我们使用每个街区中位数进行填充。此外,去除了如“Utilities”等几乎无变异性的变量,以避免对模型造成噪音。
2.2 特征转换与构造
在特征转换与构造方面,我们将数值型的类别变量(如房屋子类MSSubClass、总体状况OverallCond)转换为字符串,以便后续的编码处理。同时,我们构造了新的复合特征TotalSF,代表房屋的总面积(地上+地下),并对 SalePrice 以及一部分偏态严重的数值型特征进行了对数变换(log1p),以减缓偏态对模型的干扰。
2.3 偏态修正
为了进一步改善特征的分布,我们计算了每个数值变量的偏度,对于偏度大于0.75的变量,使用 Box-Cox 变换进行了修正。该操作可以有效地使特征分布更接近正态分布,进而提升模型的稳定性和拟合效果。
三、选用的机器学习算法及原因
3.1 模型列表
在模型构建阶段,我们尝试了多种类型的回归模型,并将它们进行了集成融合。基础模型包括:Lasso Regression、ElasticNet、Kernel Ridge Regression、Gradient Boosting Regressor、XGBoost、LightGBM,以及 StackingCVRegressor。其中,线性模型(Lasso 和 ElasticNet)具有较好的特征选择能力和解释能力;核岭回归模型通过引入核函数增强了非线性拟合能力;而基于梯度提升树的模型(Gradient Boost、XGBoost 和 LightGBM)则具有出色的非线性建模能力和较强的稳定性。
3.2 模型融合方法
我们使用了两种模型融合方法:
一是简单加权平均,即对多个模型的预测结果按照一定比例进行加权求和;
二是 Stacking 模型集成策略,通过将多个一级模型的预测结果作为新特征输入一个元学习器中进行再训练,从而进一步优化预测结果。这种融合方法能够充分利用不同模型之间的互补性,提升最终模型的泛化能力。
四、模型评估与优化
4.1 评估指标
为了评估模型性能,我们采用了“均方对数误差”(Root Mean Squared Log Error, RMSLE)作为主要评估指标。该指标对异常值的容忍性较高,适用于房价这种呈偏态分布的目标变量。模型的训练和验证均采用五折交叉验证,以保证模型的鲁棒性和对不同子集的适应能力。在 Stacking 模型中,一级模型的预测也采用了交叉验证方式生成,确保元模型不会受到信息泄露干扰。
4.3 模型优化手段
模型优化方面,我们对各个模型的超参数进行了调试,如正则项系数 alpha、学习率 learning_rate、基学习器数目 n_estimators 等。同时,通过变量偏态变换、模型融合策略选择、以及融合权重调整等手段,进一步提升了整体模型的表现。
五、结果分析与可视化
5.1 模型性能对比
在最终模型评估中,多个模型在交叉验证下表现如下:Lasso 和 ElasticNet 均达到了约 0.111 的 RMSLE,Kernel Ridge 回归约为 0.115,Gradient Boost 和 XGBoost 分别为 0.117 和 0.116,LightGBM 约为 0.115,而融合模型 StackingCV 和加权平均模型分别达到了 0.108 和 0.109。可以看出,集成模型在稳定性和准确性方面具有显著优势。
5.2 可视化结果展示
在可视化分析部分,我们绘制了残差分布图,检验了预测误差是否接近正态分布;
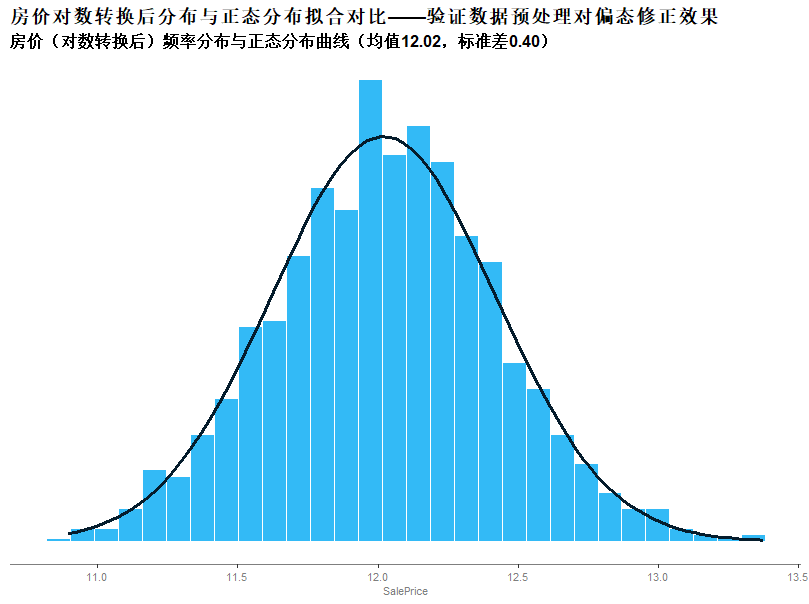
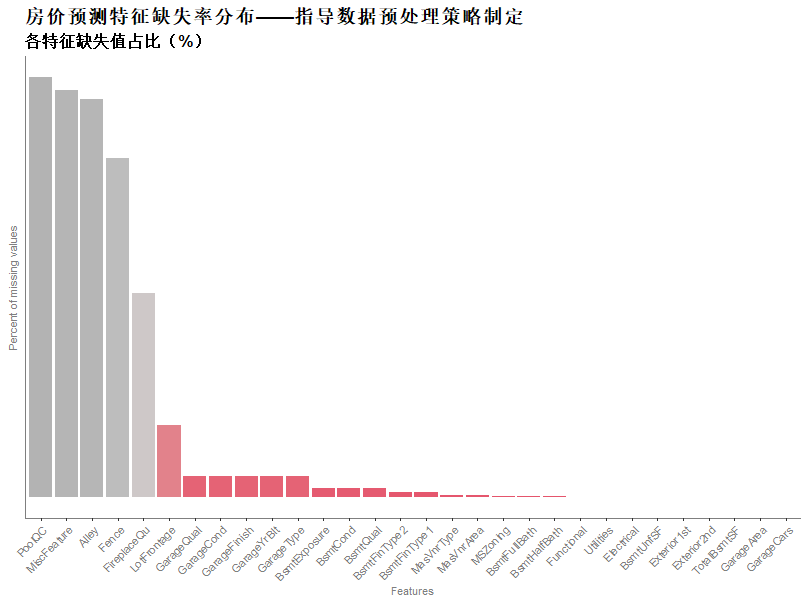
绘制了各个特征的缺失率,用于评估各个特征的异常清洗策略;
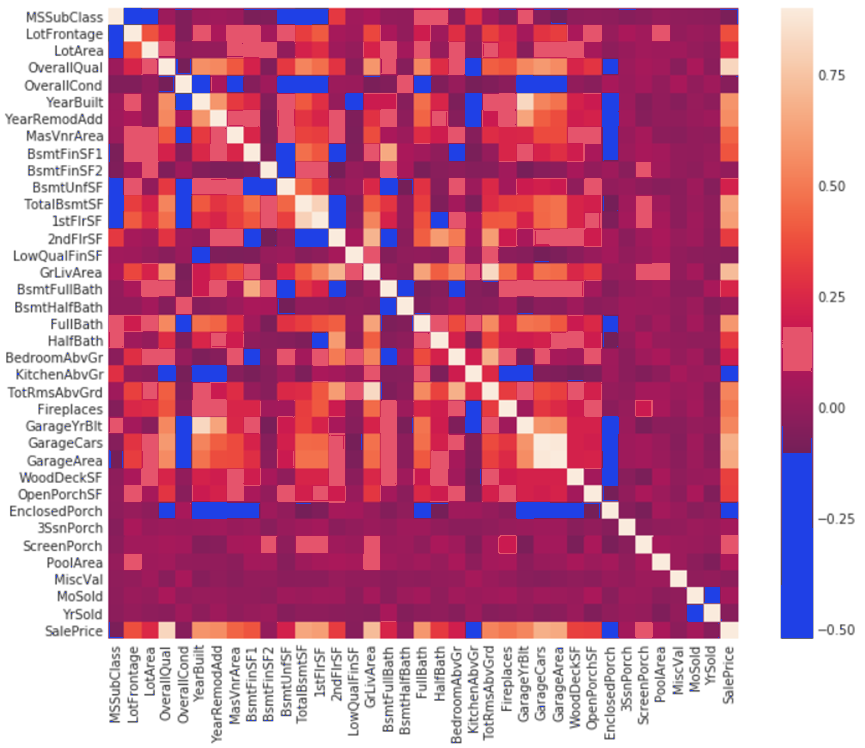
同时还展示了绘制了特征与销售价格的热力图,用于评估特征对预测结果的影响。
5.3 最终预测与提交
在实际预测阶段,我们采用融合模型对测试集进行预测。验证了模型的高效性和实际应用价值。

六、结论与展望
6.1 项目总结
本项目成功构建了一个高性能的房价预测模型,充分利用特征工程与模型集成方法。通过多模型融合,我们提升了模型的泛化能力,同时控制了过拟合风险。
6.2 改进方向
在未来的工作中,我们可以进一步尝试使用深度学习模型,探索更复杂的特征交互关系;引入模型可解释性技术增强模型透明度;应用自动化超参数搜索技术提高调参效率;甚至引入外部数据如地理信息、经济指标等丰富特征体系,以持续优化模型性能。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码
Python用LightGBM XGBoost Stacking集成学习混合线性规划生鲜冷链仓网配送优化|附数据代码 大语言模型LLM的特征工程:从语义嵌入到多模态特征融合的技术实践 | 附数据代码
大语言模型LLM的特征工程:从语义嵌入到多模态特征融合的技术实践 | 附数据代码