在数据驱动决策的时代,时间序列预测作为数据科学的核心应用之一,始终是各行业探索未来趋势的关键工具。
无论是金融市场的黄金价格波动,还是能源领域的能耗变化,精准的预测都能为企业和决策者带来巨大的价值提升。
作为数据科学家,我们在协助客户完成的咨询项目中,深入探索了贝叶斯优化算法与长短期记忆网络(LSTM)的融合应用,在黄金收盘价预测与能耗预测两大场景中取得了显著成果。
在金融市场的项目中,黄金价格的复杂性让传统预测方法难以施展拳脚。我们引入贝叶斯优化长短期记忆网络(BO-LSTM),通过对数据的深度探索与预处理,结合超参数优化,大幅提升了预测准确率,为投资者提供了更可靠的决策依据。
而在能源领域的项目里,我们基于 PyTorch 构建贝叶斯 LSTM 模型,利用蒙特卡罗 dropout 实现不确定性量化,让能耗预测不仅有了精准的数值,更附带了可靠的置信区间,为能源调度等工作提供了丰富的决策参考。
这两个项目的实践成果,不仅是技术应用的创新,更是数据科学方法论在不同领域的成功验证。如今,BO-LSTM能耗预测专题项目文件已分享在交流社群,进群和 500 + 行业人士共同交流和成长,期待与更多数据科学领域的同行,共同探讨时间序列预测的前沿技术与应用场景,解锁数据背后的无限可能。

Python贝叶斯优化长短期记忆网络BO-LSTM的能耗预测可视化|附数据代码
本文介绍了如何使用PyTorch实现近似贝叶斯递归神经网络,用于能耗预测。通过使用蒙特卡罗 dropout 近似贝叶斯推理,使模型的预测具有明确的不确定性和置信区间。文中使用了特定的能耗数据集,对数据进行预处理、构建模型、训练及评估,展示了贝叶斯LSTM在能耗预测任务中的应用及效果,并分析了其不确定性量化的方法及存在的问题。
视频
【讲解】ARIMA、XGBOOST、PROPHET和LSTM预测比特币价格
视频
【视频讲解】Python用LSTM、Wavenet神经网络、LightGBM预测股价
视频
【视频讲解】Python深度学习股价预测、量化交易策略:LSTM、GRU深度门控循环神经网络附代码数据
视频
【讲解】线性时间序列原理及混合ARIMA-LSTM神经网络模型预测股票收盘价研究实例
一、引言
在能耗预测等关键应用中,不仅需要准确的预测结果,还需要对预测的不确定性进行量化,以便更好地做出决策。贝叶斯神经网络通过对模型参数的概率分布进行建模,能够提供预测的不确定性信息,从而满足这类应用的需求。长短期记忆网络(LSTM)作为一种强大的递归神经网络,适合处理时间序列数据。本文将贝叶斯方法与LSTM相结合,使用PyTorch框架实现了一个用于能耗预测的贝叶斯LSTM模型。
二、数据预处理
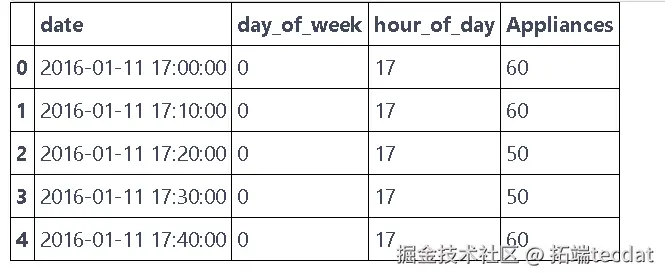
我们使用了一个能耗数据集,为了简化和加快运行速度,只选取了时间相关和自回归相关的特征,包括日期时间(每10分钟采样一次)、能耗(对应10分钟时间戳的瓦时)、星期几(星期一对应0)、一天中的小时数。
AI提示词:读取能耗数据集,将日期列转换为日期时间格式,并提取出月份、日期、星期几和小时数等信息,然后选取指定的列作为有效数据。
import pandas as pd
# day_of_week=0 对应星期一
energy_df['day_of_week'] = energy_df['date'].dt.dayofweek.astype(int)
energy_df['hour_of_day'] = energy_df['date'].dt.hour.astype(int)
selected_co
为了进行更有意义的分析,对数据集进行以下转换:
- 以每小时的频率重新采样。
- 对目标变量(能耗)进行对数变换,以减轻指数效应。
- 仅使用星期几、一天中的小时数和之前的能耗值作为特征。
AI提示词:将数据集的索引设置为日期时间,以每小时的频率重新采样并计算均值,添加新列存储对数变换后的能耗值,选取特征列和目标列,并为了可视化和展示,仅保留前150小时的数据。
feature_columns = datetime_columns + ['log_energy_consumption']
# 为了可视化和展示的清晰性,仅考虑前150小时的数据
resample_df = resample_df[feature_columns]
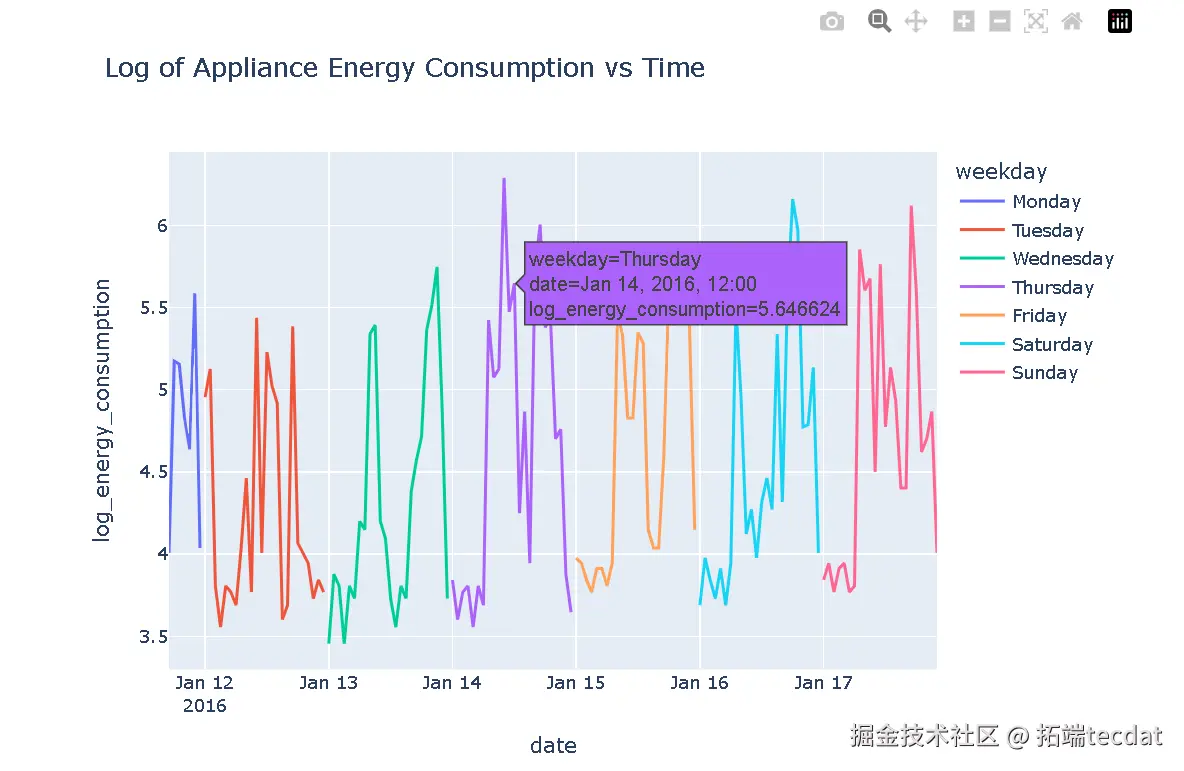
使用plotly.express绘制能耗随时间变化的折线图,展示不同星期几的对数能耗情况。
AI提示词:从重新采样后的数据中选取前150小时的数据,添加星期几的名称列,使用plotly.express绘制折线图,以日期为x轴,对数能耗为y轴,按星期几进行颜色区分。
三、准备训练数据
使用滑动窗口的方法,每个窗口包含10个数据点(相当于10小时),用于预测下一个数据点。对训练数据进行Min-Max缩放,以帮助神经网络收敛。
AI提示词:定义创建滑动窗口数据的函数,根据给定的训练集比例划分训练集和测试集,对特征和目标值分别进行Min-Max缩放,然后使用滑动窗口函数创建训练和测试的特征及目标数据。
四、定义贝叶斯LSTM架构
模型架构包括编码器-解码器阶段和预测器阶段:
- 编码器-解码器阶段:一个单向LSTM,有2个堆叠层和128个隐藏单元作为编码层,构建固定维度的嵌入状态;另一个单向LSTM,有2个堆叠层和32个隐藏单元作为解码层,用于产生未来步骤的预测。在两个LSTM层的训练和推理过程中都应用dropout。
- 预测器阶段:一个全连接输出层,有1个输出,用于预测目标变量的值。
AI提示词:定义贝叶斯LSTM类,初始化模型的参数,包括隐藏层大小、层数、dropout概率等,定义LSTM层、全连接层和损失函数,实现前向传播、初始化隐藏状态和计算损失的方法。
五、模型训练
使用ADAM优化器和小批量梯度下降(batch_size = 128)训练贝叶斯LSTM,训练150个epoch。模型在数据集的前70%上进行训练,剩余30%用于测试。
AI提示词:定义模型训练所需的参数,包括特征数量、序列长度、输出长度、批量大小、训练轮数和学习率等,初始化贝叶斯LSTM模型、损失函数和优化器,进行训练循环,在每个epoch中对每个小批量数据进行前向传播、计算损失、反向传播和优化器更新,并打印训练过程中的损失值。

想了解更多关于模型定制、咨询辅导的信息?

六、模型性能评估
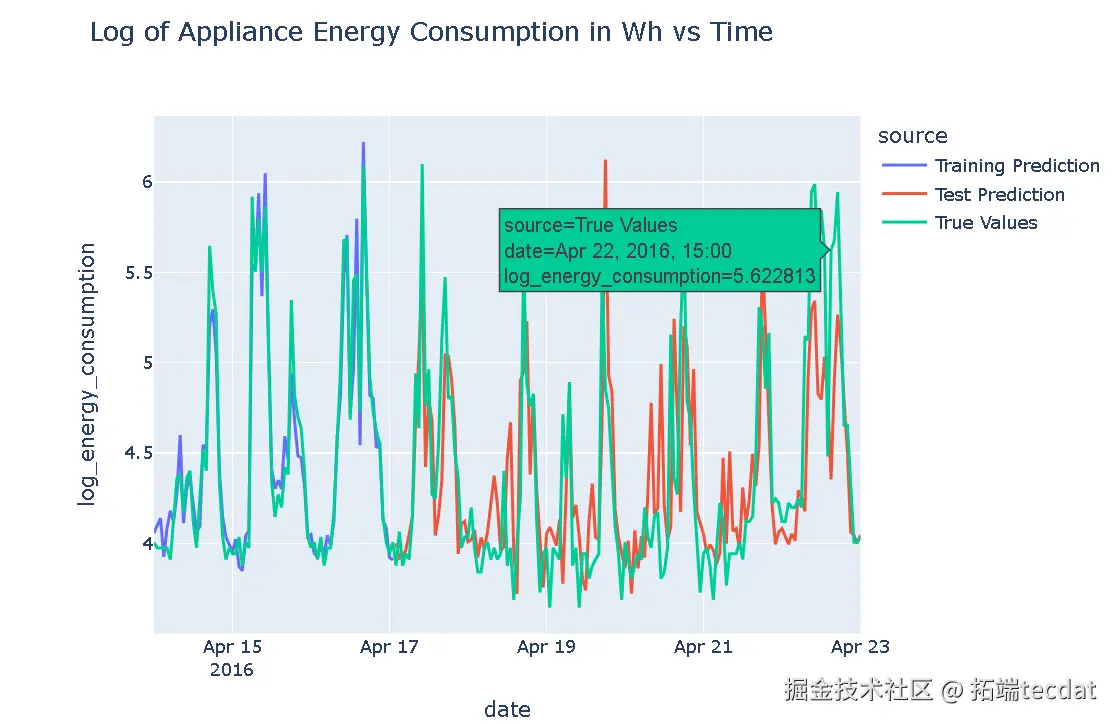
模型在训练集和测试集上都能产生合理准确和合理的结果,与其他现有的基于频率的机器学习和深度学习方法相当。通过对预测值进行逆变换,将其转换回原始尺度,并与真实值进行比较。
AI提示词:定义偏移量,对训练集和测试集的预测值进行逆变换,将预测值和真实值分别存储在数据框中,并添加相应的来源标签,然后将这些数据框连接起来,使用plotly.express绘制对比折线图,展示训练集和测试集上预测值和真实值的对比情况。
七、不确定性量化
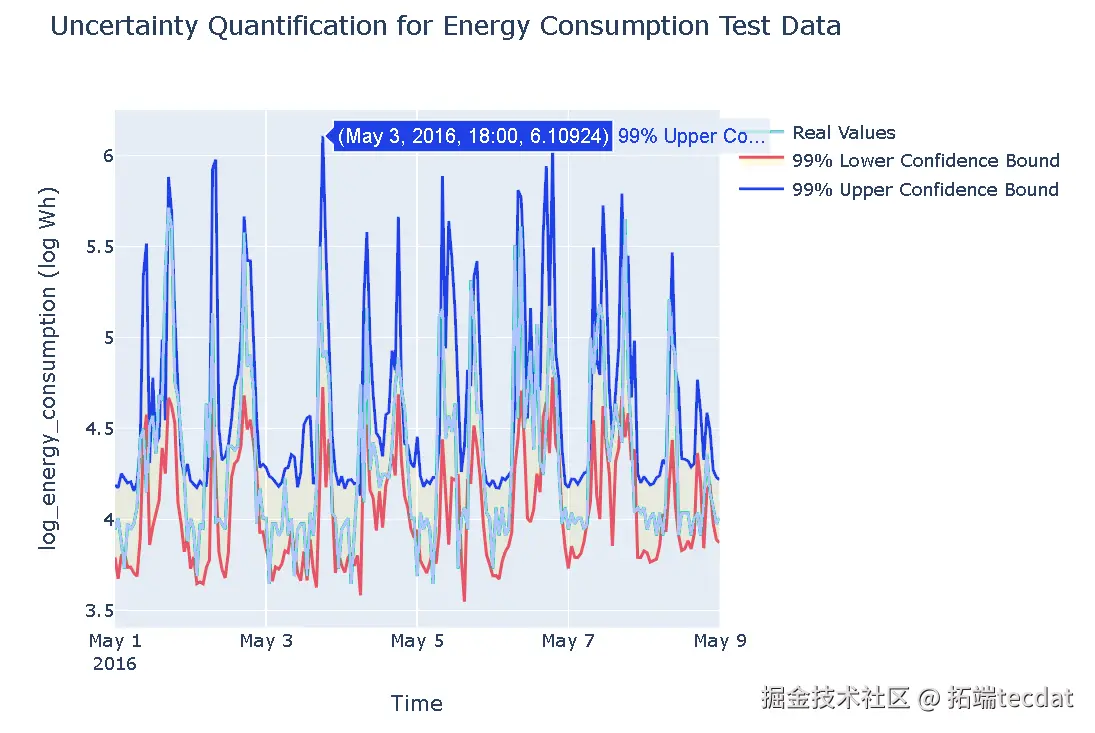
贝叶斯LSTM在每个LSTM层后应用随机dropout,使得模型输出可以被解释为目标变量后验分布的随机样本。通过运行多次实验/预测,可以近似后验分布的参数,即均值和方差,从而为每个预测创建置信区间。在本示例中,构建了99%的置信区间,其范围是每个预测近似均值的三个标准差。
AI提示词:定义实验次数,对测试集进行多次预测,将每次预测的结果存储在数据框中,计算预测值的均值和标准差,添加到数据框中,然后计算置信区间的上下界,并使用plotly.graph_objects绘制包含真实值、置信区间上下界的可视化图形。
# 使用99%置信区间边界
bounds_df['lower_bound'] = test_uncertainty_plot_df['lower_bound']
bounds_df['prediction'] = test_uncertainty_plot_df['log_energy_consumption_mean']
bounds_df['real_value'] = truth_uncertainty_plot_df['log_energy_consumption']尽管置信区间覆盖比例不理想,但贝叶斯LSTM在不确定性量化方面的尝试,为能耗预测等应用提供了更丰富的决策依据。例如在电力调度场景中,调度人员可结合预测值与置信区间,灵活安排发电计划,应对可能的能耗波动。

随时关注您喜欢的主题
从实践结果来看,贝叶斯LSTM在能耗预测任务中,与传统基于频率的模型表现相当。其独特之处在于通过随机dropout机制,实现了对目标变量后验分布的近似,从而能够为预测结果构建置信区间,提供不确定性信息。这一特性在对风险评估和决策可靠性要求较高的领域具有显著优势。
然而,贝叶斯LSTM也存在局限性。一方面,它仅能处理认知模型的不确定性,对数据中天然存在的随机噪声等无能为力;另一方面,为构建置信区间,在推理阶段需要进行多次预测,这带来了较高的计算开销,难以满足实时性要求较高的应用场景。
展望未来,可进一步探索如何将贝叶斯LSTM与其他方法结合,更全面地量化不同类型的不确定性;同时,研究如何优化模型结构和计算方法,降低推理阶段的计算成本,推动贝叶斯LSTM在实际能耗预测及更多领域的广泛应用 。
在整个研究过程中,数据预处理、模型构建、训练与评估等环节紧密相连。通过对能耗数据的精心处理,为模型训练奠定了良好基础;贝叶斯LSTM模型的创新应用,让我们对时间序列预测有了新的认识。尽管模型还存在不足,但此次探索为后续研究指明了方向,也为解决实际能耗预测问题提供了新思路和方法。
关于分析师

在此对 Yuanxiang Meng 对本文所作的贡献表示诚挚感谢,他毕业于计算机科学与技术专业,熟练掌握 MATLAB,在深度学习、计算机视觉、数据分析等领域具备扎实的专业能力。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据
Python融合RNN、GRU、LSTM多变量空气质量多步预测|附AI智能体、代码和数据 Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据
Python、LSTM神经网络模型与沪深300、中证500股指预测|附AI智能体、代码和数据 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据
Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据

