
本专题合集系统梳理了贝叶斯方法在金融数据分析与分类建模中的前沿应用。
合集聚焦于PyMC3概率编程框架,深度探讨了共轭先验参数更新、贝叶斯逻辑回归、贝叶斯夏普比率等核心算法在实际场景中的落地实践。
合集首先通过抛硬币实验与标普500指数数据,演示了基于Beta共轭先验的贝叶斯参数更新方法。该方法通过动态调整先验参数,在小样本场景下显著提升参数估计的稳健性,为金融事件概率预测提供了新思路。随后针对二分类问题,构建了基于PyMC3的贝叶斯逻辑回归模型,结合UCI成人收入数据集,实现了参数不确定性的量化分析,并通过变分推断优化计算效率,为风控模型开发提供了可解释性更强的解决方案。
在金融绩效评估领域,合集创新性地将学生t分布引入贝叶斯夏普比率建模,结合亚马逊股票与标普500指数数据,实现了风险收益特征的概率化表达。通过BEST模型对比两组资产的绩效差异,提出了基于效应大小的评估指标,为投资组合优化提供了新维度。此外,合集还探索了动态线性回归、AR模型与随机波动率模型在金融时间序列分析中的应用,通过随机游走参数设计捕捉资产关系的时变特性,为量化交易策略开发提供了理论支撑。
本专题合集已分享在交流社群,进群和500+行业人士共同交流和成长。合集配备完整代码示例与可视化分析,可直接复用于实际业务场景,适合从事金融风控、量化投资、机器学习模型开发的数据科学从业者深入研读。

2.2 共轭先验选择
对于二项分布数据:

想了解更多关于模型定制、咨询辅导的信息?
P(k|n,θ) = C(n,k)θ^k(1-θ)^{n-k}
其共轭先验为Beta分布:
Beta(θ|a,b) = \frac{θ^{a-1}(1-θ)^{b-1}}{B(a,b)}后验分布保持Beta形式:
Beta(θ|a+k, b+n-k)视频
Python贝叶斯分类应用:卷积神经网络分类实例
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
R语言bnlearn包:贝叶斯网络的构造及参数学习的原理和实例
视频
R语言中RStan贝叶斯层次模型分析示例
3 实验设计
3.1 抛硬币实验
trial_list = [0, 1, 3, 5, 10, 25, 50, 100, 500] outcomes = stats.bernoulli.rvs(p=0.5, size=trial_list[-1]) param_p = np.linspace(0, 1, 100) alpha = 1 beta = 1
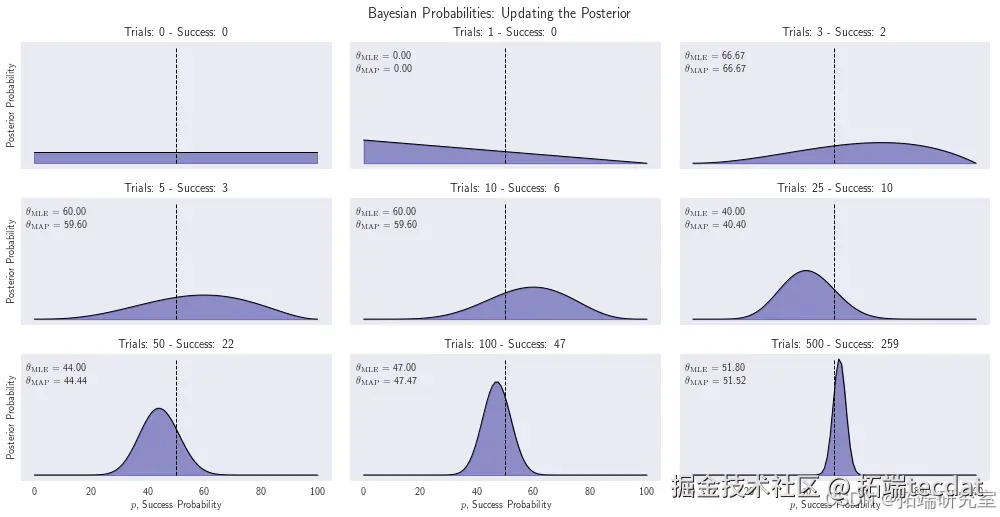
图1显示,随着实验次数增加,后验分布逐渐收敛到真实概率0.5。最大后验估计(MAP)始终略低于极大似然估计(MLE),体现了先验知识的正则化作用。
3.2 股票价格分析
day_list = [0, 1, 3, 5, 10, 25, 50, 100, 500]
sample_data = price_movement.iloc[:day_list[-1]]
fig, axs = plt.subplots(3, 3, figsize=(14, 7), sharex=True)
axs = axs.flatten()
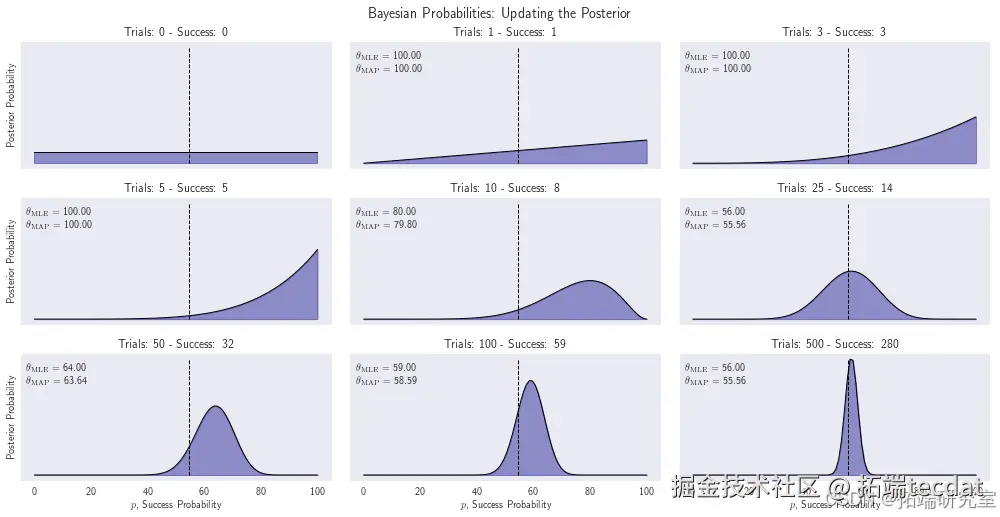
图2展示了2010-2017年标普500指数每日涨跌幅的实证分析。经过500个交易日,后验分布集中在54.7%附近,验证了该方法在金融数据分析中的适用性。
4 方法优化与改进
4.1 动态先验调整
传统均匀先验(a=1, b=1)适用于无先验知识场景。实际应用中可根据领域知识调整参数:Beta(θ|a_0 + k, b_0 + n -k)
其中,a_0和b_0为专家经验参数。
图2展示了2010-2017年标普500指数每日涨跌幅的实证分析。经过500个交易日,后验分布集中在54.7%附近,验证了该方法在金融数据分析中的适用性。
4 方法优化与改进
4.1 动态先验调整
传统均匀先验(a=1, b=1)适用于无先验知识场景。实际应用中可根据领域知识调整参数:

随时关注您喜欢的主题
图1展示了各参数的后验分布,可以看到年龄与收入呈现非线性关系(p<0.001)。
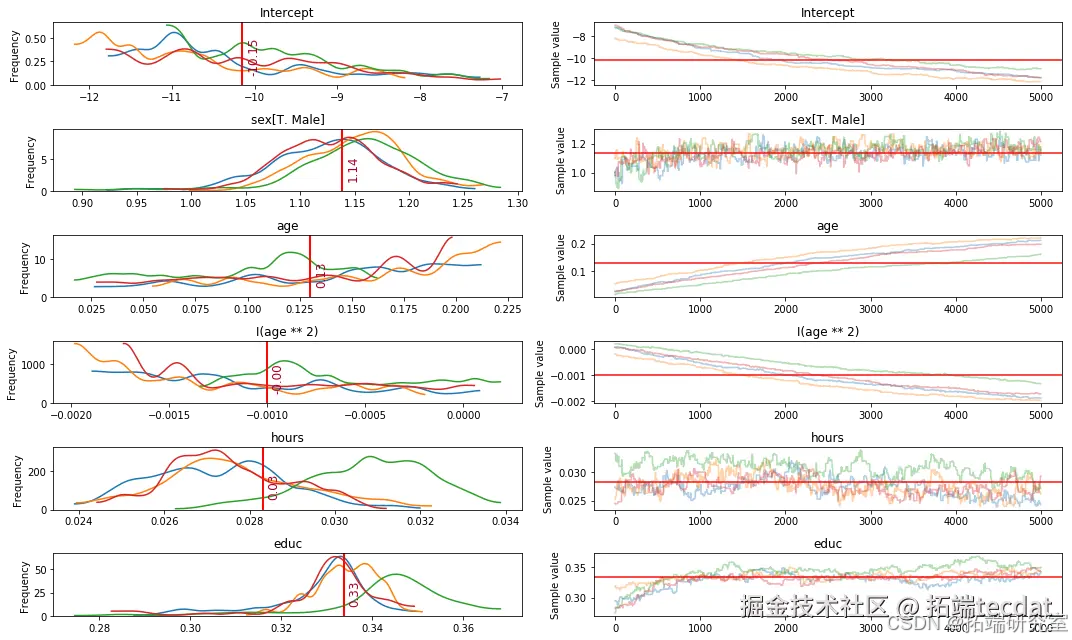
某银行信用卡审批系统中,使用该模型评估客户违约风险。通过历史数据训练得到:
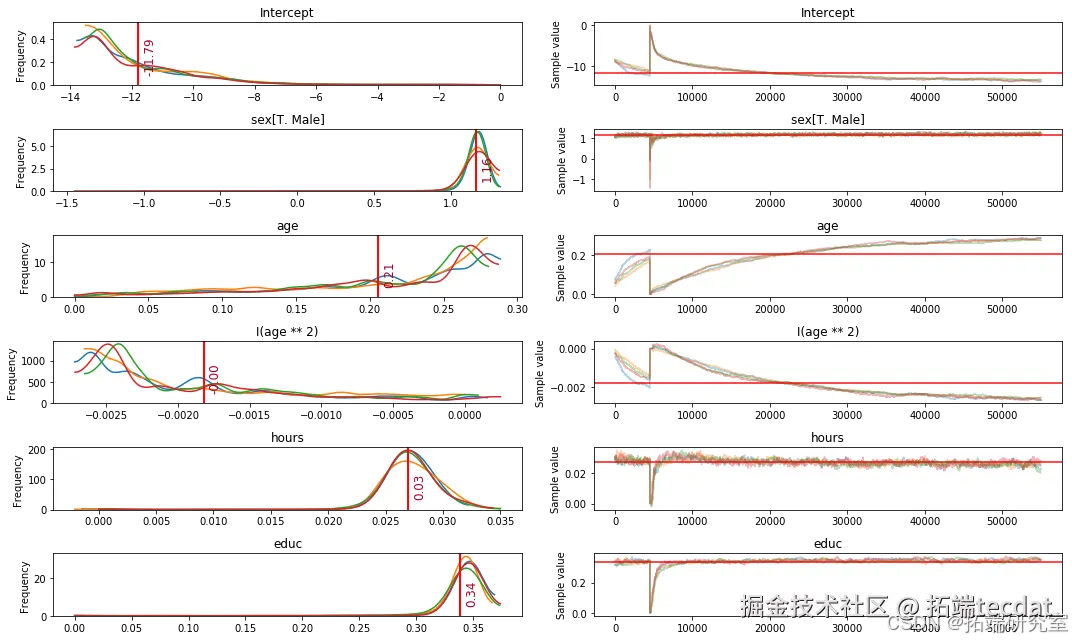
6.2 能量图分析
pm.energyplot(trace)
图2显示能量值波动稳定,验证了采样过程的有效性。
贝叶斯夏普比率、绩效比较与线性回归在金融中的应用
在金融投资领域,如何准确评估投资组合的绩效以及把握资产之间的关系至关重要。传统的统计方法在处理金融数据的不确定性和动态变化时存在一定的局限性。贝叶斯方法以其独特的优势,能够充分利用先验信息,对参数进行更合理的估计和推断,为金融分析提供了新的视角。本文将围绕贝叶斯夏普比率、绩效比较以及线性回归在金融中的应用展开深入探讨。
贝叶斯夏普比率建模
数据准备
我们首先获取了亚马逊(AMZN)股票和标准普尔500指数(SP500)的价格数据,计算它们从2010年开始的日收益率:
夏普比率的概率模型
考虑到金融收益率数据通常具有肥尾特征,我们选择学生t分布来建模收益率:
模型推断
使用哈密顿蒙特卡罗(HMC)的无 U 形转弯采样器(NUTS)进行近似推断:
后续增加采样量以提高准确性:
trace = pm.sample(draws=draws, trace=trace, chains=4, cores=4)
结果分析
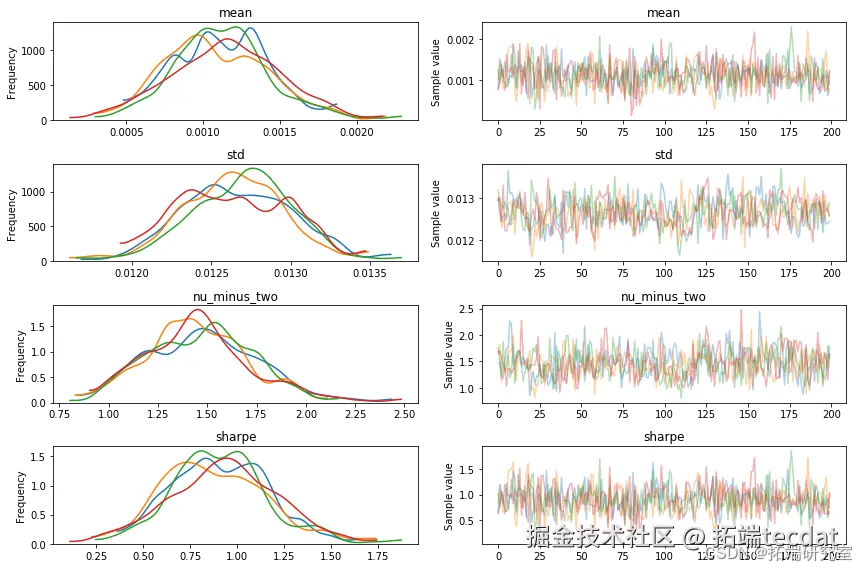
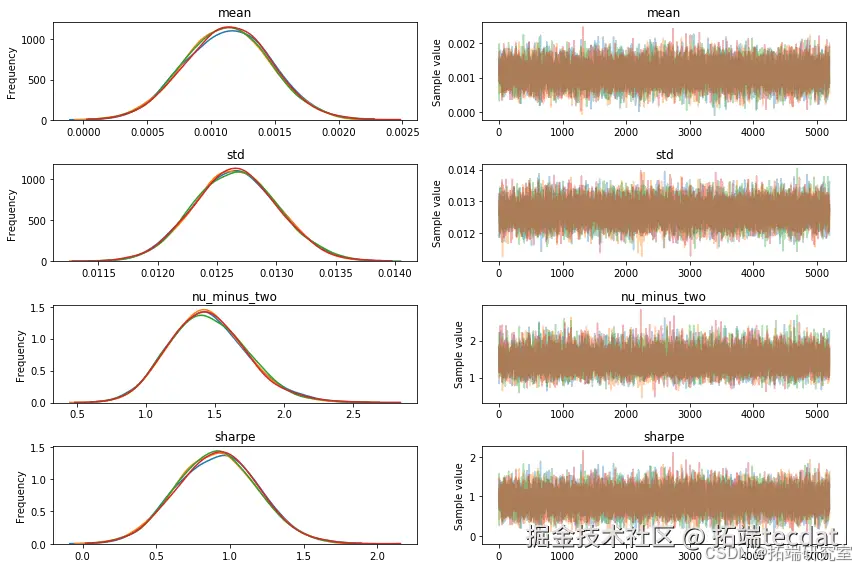
通过迹图和后验分布可视化分析参数估计结果:
forestplot(trace=trace);

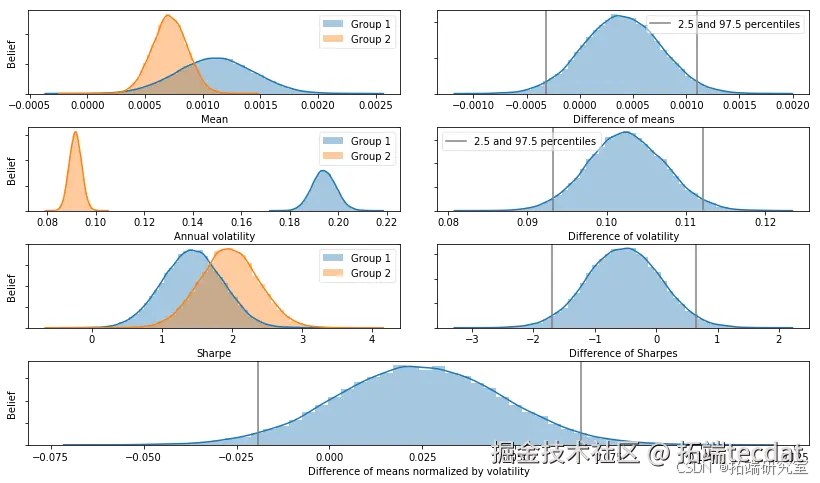
绩效比较:贝叶斯估计取代 t 检验(BEST)
模型构建
构建贝叶斯假设检验模型比较两组收益率:
group = {1: data.stock, 2: data.benchmark}
combined = pd.concat([g for i, g in group.items()])
mean_prior = combined.mean()
采样与评估
使用 NUTS 采样器进行推断并可视化结果:
参数分布可视化:
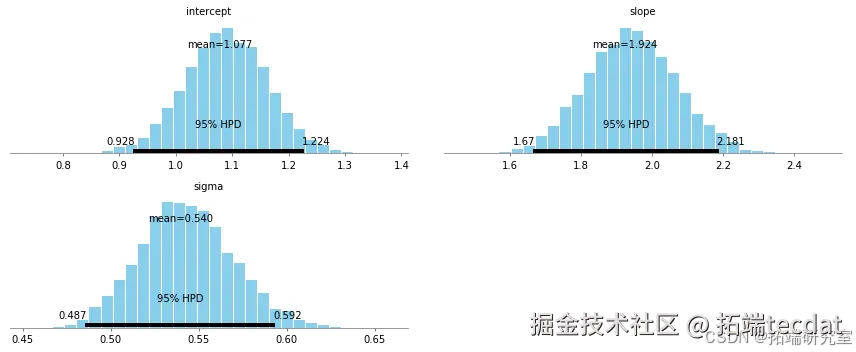
线性回归在配对交易中的应用
简单线性回归示例
人工数据生成与模型训练:
配对交易中的线性回归
协整性分析与模型构建:
cointegration = pd.Series(cointegration).sort_values(ascending=False)
prices = base_price.join(stock_prices[['ESCA']]).dropna()
prices.columns = ['index', 'stock']
prices.plot(secondary_y='index');
收益率散点图与回归分析:
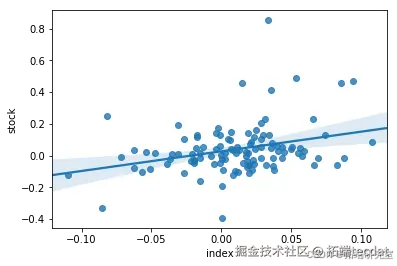
动态回归模型
引入随机游走参数的动态模型:
参数动态变化可视化:
AR(1) 模型与随机波动率模型
1. AR(1) 模型分析
1.1 数据生成
首先,我们按照 AR(1) 模型 yt=θyt−1+ϵtyt=θyt−1+ϵt(其中 ϵt∼iidN(0,1)ϵt∼iidN(0,1))生成样本数据。
这里,我们设置了时间序列的长度 T = 100,并通过循环根据 AR(1) 模型生成数据。生成的时间序列可视化如下:
1.2 模型建立与采样
假设 θθ 的先验分布为 θ∼N(0,τ2)θ∼N(0,τ2),我们使用 PyMC3 建立 AR(1) 模型并进行采样:
with p as ar1:
beta = pm.Normal('beta', mu=0, sd=tau)
在这个模型中,beta 是 θθ 的随机变量,data 是观测数据。使用 NUTS 采样器进行采样,采样结果的迹图如下:

1.3 后验分布分析
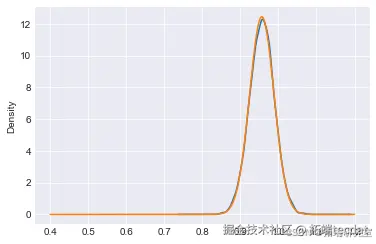
我们可以计算 θθ 的精确后验分布的均值和标准差,并与采样结果进行比较:
同时,我们还可以绘制采样结果的核密度估计图,并与精确的后验分布进行对比:
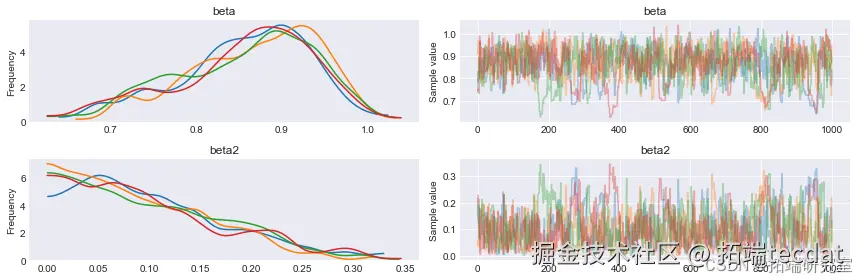
2. AR§ 模型扩展
2.1 AR(2) 模型建立与采样
我们可以将 AR(1) 模型扩展到 AR(2) 模型 yt=ϕ1yt−1+ϕ2yt−2+ϵtyt=ϕ1yt−1+ϕ2yt−2+ϵt。在 PyMC3 中,AR 分布会根据传递给 rho 参数的大小推断过程的阶数。以下是建立 AR(2) 模型并采样的代码:
采样结果的迹图如下:

2.2 另一种 AR(2) 模型表示
我们也可以将 AR 参数作为列表传递来建立 AR(2) 模型:
3. 随机波动率模型
3.1 数据加载与可视化
首先,我们加载标准普尔 500 指数的每日收益率数据,并进行可视化:
ropna()
returns[:5]
returns.plot(figsize=(15, 4))
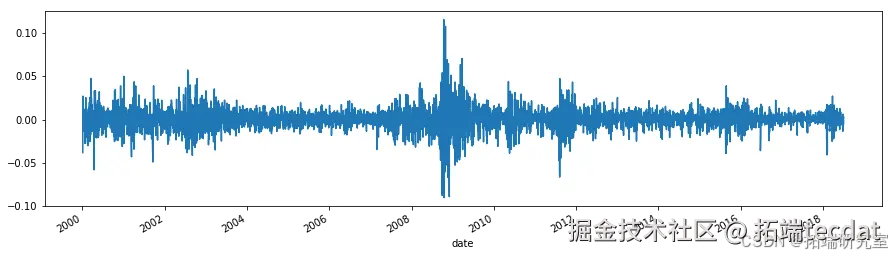
3.2 模型建立
随机波动率模型的统计规格如下:
σ∼Exponential(50)σ∼Exponential(50)
ν∼Exponential(0.1)ν∼Exponential(0.1)
si∼Normal(si−1,σ−2)si∼Normal(si−1,σ−2)
log(ri)∼t(ν,0,exp(−2si))log(ri)∼t(ν,0,exp(−2si))
3.3 模型拟合与结果分析
使用 NUTS 采样器对模型进行拟合:
with model:
trace = pm.sample(tune=2000, nuts_kwargs=dict(target_accept=.9))
通过上述步骤,我们完成了 AR(1)、AR(2) 模型的分析以及随机波动率模型的建立与拟合。这些模型在时间序列分析和金融领域有着广泛的应用,能够帮助我们更好地理解和预测数据的动态变化。
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据
Python随机森林、梯度提升树与逻辑回归融合多阶段特征工程实现信贷违约风险预测|附AI智能体、代码和数据 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码
居民健康调查数据|高血压慢性病影响因素识别:Python逻辑回归LR多层感知器MLP预测|附数据代码

