
在空间数据分析领域,准确的模型和有效的工具对于研究人员至关重要。
本文为区域数据的贝叶斯模型分析提供了一套完整的工作流程,基于Stan这一先进的贝叶斯建模平台构建,帮助客户为空间分析带来了新的解决方案。
特性
(一)空间回归与疾病映射
本文处理区域单元(如州、县或普查区域)或网络记录的数据统计模型,其中包括空间计量经济学模型。在疾病映射方面,可用于估计小区域(如县)的疾病风险,分析健康结果与其他区域变量的协变关系。例如在公共卫生研究中,研究人员可以利用该功能探究不同地区疾病的分布情况,分析发病率与环境、人口密度等因素的关联。
(二)空间分析工具
本文提供了可视化和测量空间自相关及地图模式的工具,用于探索性分析和模型诊断。在进行空间数据分析时,这些工具可以帮助研究人员直观地了解数据的空间分布特征,判断数据是否存在自相关现象,为后续的建模和分析提供依据。
(三)观测不确定性处理
本文可以将数据可靠性信息,比如社区调查估计的标准误差,纳入到任何模型中。这一特性使得模型能够更好地处理数据的不确定性,提高模型的准确性和可靠性。在实际应用中,数据往往存在各种误差和不确定性,这一功能能够有效考虑这些因素,使分析结果更符合实际情况。

(四)缺失和审查观测值处理
在生命统计和疾病监测系统中,会对低于阈值数量的病例数进行审查。能够对存在审查观测值或缺失观测值的小区域疾病或死亡率风险进行建模。例如在分析某地区的死亡率数据时,可能存在部分数据因各种原因被审查或缺失,可以通过合适的模型对这些数据进行处理,从而得到更准确的死亡率估计。

视频
Python贝叶斯分类应用:卷积神经网络分类实例
视频
贝叶斯推断线性回归与R语言预测工人工资数据
视频
R语言bnlearn包:贝叶斯网络的构造及参数学习的原理和实例
视频
R语言中RStan贝叶斯层次模型分析示例
对空间数据进行可视化总结,包括直方图、莫兰散点图和地图。莫兰散点图用于展示数据值与其相邻值的汇总对比,回归线的斜率可衡量自相关程度。
以下代码用于创建邻接矩阵,计算每10,000人的粗死亡率,并进行快速空间诊断:
# 快速空间诊断
diag(mortaate, georgia, w = adjacenix")
执行上述代码后,得到的可视化结果如下:
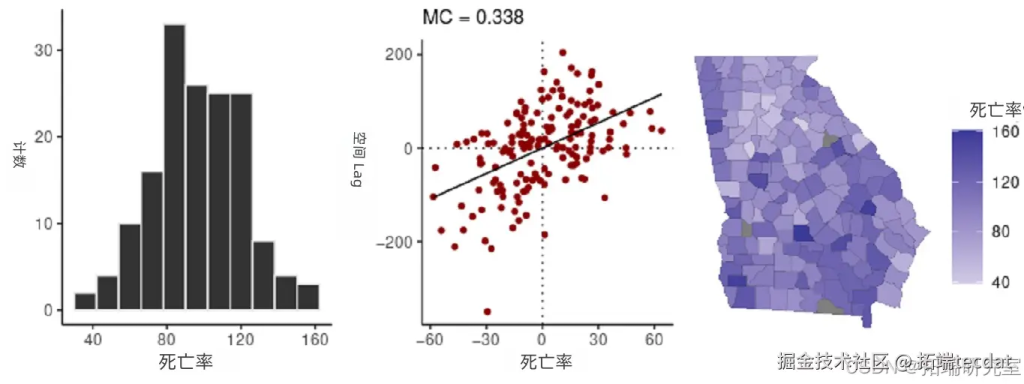
(二)空间条件自回归(CAR)模型拟合
空间条件自回归(CAR)模型是一种用于分析具有空间结构数据的统计模型。这种模型考虑了空间上的相关性,即邻近位置的数据之间存在一定的关联。它通过引入空间权重矩阵来描述这种空间关系,并在回归模型中加入空间自回归项,以捕捉空间依赖性。CAR 模型在地理学、生态学、经济学等领域有广泛应用,例如用于研究区域经济增长的空间效应、物种分布的空间格局等。
由于县的死亡率和其他健康统计数据在许多情况下是高度不稳定的估计值,不能直接用于公共建议或推断(因为人口规模较小),因此需要使用模型从小区域数据中进行推断。
以下代码使用空间条件自回归(CAR)模型对女性县死亡率数据进行拟合:
# 对女性死亡率数据拟合模型
stacar(deaths.female ~ offse
将拟合好的模型传递给函数,可返回空间模型的一组诊断信息:
使用print方法可以返回模型参数的概率分布摘要,以及来自Stan的马尔可夫链蒙特卡罗(MCMC)诊断信息(均值的蒙特卡罗标准误差se_mean、有效样本大小n_eff和R-hat统计量Rhat):
print(modefit)
执行sp_g(mode_i, grgia)后,得到的诊断信息可视化结果如下:
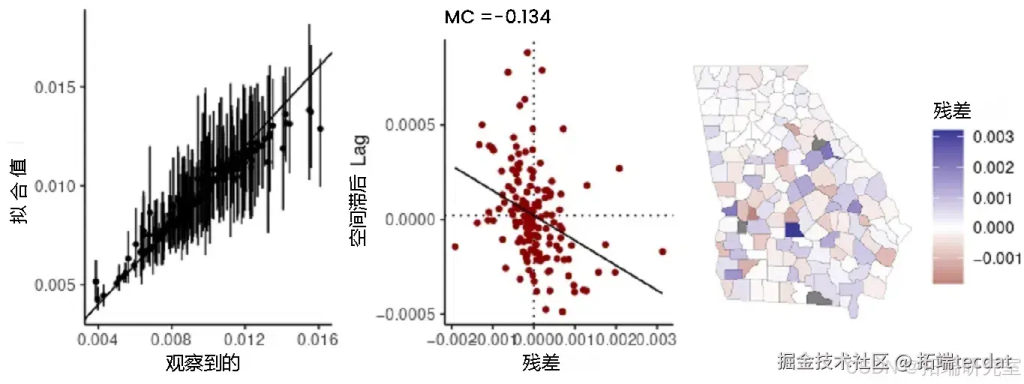
(三)提取死亡率估计值与可视化
通过fitted方法提取县死亡率估计值,乘以10,000得到每10,000人的死亡率:
# 每10,000人的死亡率估计值
moraitystimtes <- ftted(de_fit) * 10e3
将估计值放入分箱中用于地图颜色显示,创建地图展示估计值:
oriial_magin = par(mar = rep(1, 4))
# 获取边界
geometry <- sf:st_eoetry(eorgia)
# 绘制地图
plot(geomty,
lwd = 0.2,
col = colors)
# 添加图例
leg
bty = 'n')
执行上述代码后,绘制出的地图如下:
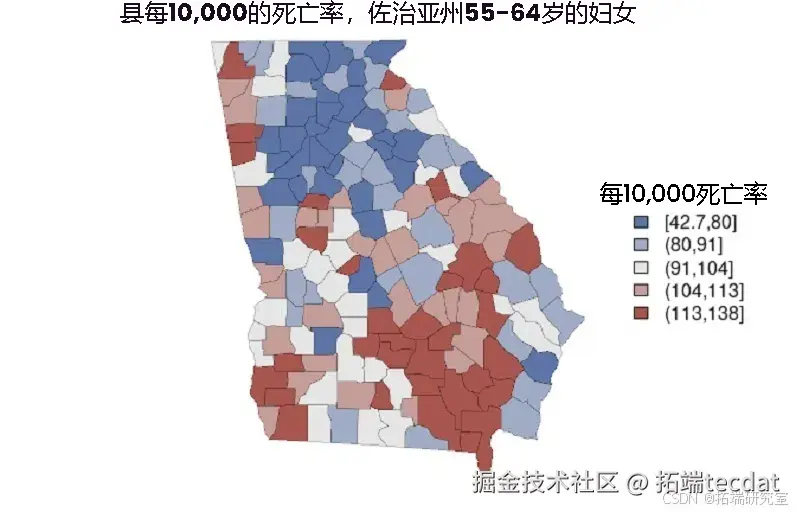
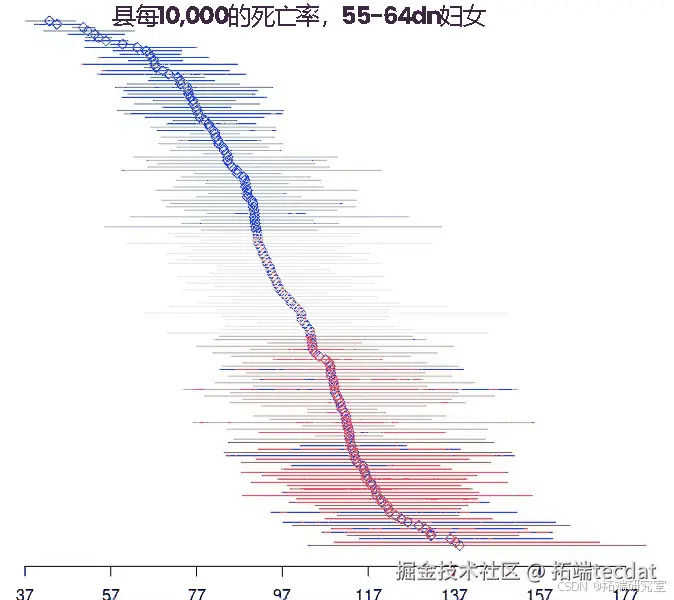
利用可信区间,创建点区间图:借助可信区间这一统计概念,来制作一种点区间图。可信区间是用来估计总体参数的范围,具有一定的可信度。点区间图通常是用一个点来表示某个统计量的值,然后用一个区间来表示该统计量的可信区间范围,这样可以直观地展示统计量的估计值及其不确定性。例如,在对一组数据进行均值估计时,可以计算出均值的可信区间,然后在点区间图中用一个点表示均值估计值,用一个区间表示可信区间范围,从而让人们清楚地看到均值估计的准确性和可靠性。
# 按死亡率对县进行排序
data <- mortality_estimates[index, ]
# 收集估计值和95%可信区间
estimate <- data$mean
lower <- data$`2.5%`
upper <- data$`97.5%`
y <- seq_along(cony_name)
x_limit <- (min(lo), max(upper)) %>% round()
# 设置边距
originalarg = r(ma c(3, , 0)
# 绘制点
plot(esimte,
y,
pch = 5,
col = gray50',
bty 'L,
axes = FALSE,
xlim = _limit,
yl = A,
xlab = NA)
# 绘制区间
segmens(x0 = lower, x1 = upper,
y0 = y,y1 ,
col = olor[index])
# 添加x轴mit[1], x_limit[2], by = 20))行上述代码后,得到的点区间图如下:

点区间图是一种用点来表示数据,并通过区间来展示数据范围的图形。在特定的情境中,运行上述代码后得到的点区间图可以直观地呈现数据的分布和范围情况。例如,可能用不同颜色的点代表不同类型的数据,区间则可以表示数据的波动范围或置信区间等。
随时关注您喜欢的主题
每日分享最新报告和数据资料至会员群
关于会员群
- 本会员社群以垂直产业数据研究、深度行业报告分享、AI数据工具实操交流为核心定位;
- 入群即可解锁全行业数据内容免费阅读与下载权限,同步更新海内外一手优质研究报告文档与产业数据;
- 会员老用户享受专属 9 折续费优惠,可长期锁定社群全部权益;
- 为会员提供一对一免费 PDF 报告专属代找服务。
非常感谢您阅读本文,如需帮助请联系我们!
 2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载
2026汽车出海行业深度报告:新能源出口、全球区域布局、电动两轮车|附200+报告数据合集下载 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据

