在大众旅游蓬勃发展的背景下,乡村旅游已成为推动乡村经济、社会和文化发展的关键力量。
当前,乡村旅游接待设施主要以招待所、小宾馆和农家乐等形式存在。
然而,一方面这些设施的接待能力有限,另一方面为了维护乡村独特的景观特色,住宿设施也不宜完全照搬城市酒店的规模和形制。民宿作为一种利用自家闲置房屋、以家庭经营为主且能提供多种特色服务的接待设施,恰好能满足上述两项需求。
本文分别针对 calendar、reviews 和 listings 三张表进行深入的探索性分析包含:Python分析Airbnb 数据:洞察市场差异、价格因素与旅行价值|附数据代码和房源价格预测模型研究|附数据代码。
通过对客户的这些数据的挖掘和研究,旨在揭示 Airbnb 房源在时间序列变化、用户评论情感分析以及房源各方面特征可视化等方面的规律,为乡村旅游接待设施的发展以及 Airbnb 平台的优化提供有价值的参考依据。同时,通过建模与分析过程,探索影响房源价格的关键因素,进一步提升对房源价格预测的准确性,为房东、租客和平台运营者提供决策支持。
分别针对calendar、reviews和listings三张表进行探索性分析。
1.calendar表
时间序列分析
calendar表展示了西雅图2016年1月到2017年1月3818所房子的是否可定状态和每一天的房屋价格,通过对每一天的房屋价格取均值以及对每一天房屋可定状态的计数,我们可以分别得到价格的时间序列图和每日空闲房屋数量的时间序列图。

Kefan Yu
可下载资源
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测

这里分别采用了移动平均法和指数平均法进行平滑处理,得到下图:
从这个图中我们可以看到民宿房屋的价格在7、8月达到了一个高峰,可以想见是因为7、8月正值放假外出游玩的时候,房屋的价格也相应上涨。于此同时,空闲房屋的数量在1月、7月分别有所下降,也就是说在这两个时间段订房人数急剧增长。由于空闲房间数量图时间序列特征并不明显,我们在此仅对房屋价格进行时间序列分析和预测。由于我们要进行的ARIMA时间序列分析需要的是一个平稳的序列,当我们得到的时间序列不平稳时,通过做时间序列的差分,直到得到一个平稳的时间序列。
视频
Boosting集成学习原理与R语言提升回归树BRT预测短鳍鳗分布生态学实例
视频
【讲解】ARIMA、XGBOOST、PROPHET和LSTM预测比特币价格
视频
【视频讲解】CatBoost、LightGBM和随机森林的海域气田开发分类研究
视频
Python比赛讲解LightGBM、XGBoost+GPU和CatBoost预测学生在游戏学习过程表现
视频
Python用SMOTEBoost、RB-Boost 和 RUS-Boost不平衡数据集的集成分类器
视频
【视频讲解】神经网络、Lasso回归、线性回归、随机森林、ARIMA股票价格时间序列预测
视频
Lasso回归、岭回归等正则化回归数学原理及R语言实例
视频
R语言机器学习高维数据应用:Lasso回归和交叉验证预测房屋市场租金价格
这里分别采用了移动平均法和指数平均法进行平滑处理,得到下图:

从上图可以发现窗口为12的移动平均能较好的剔除年周期性因素,而指数平均法是对周期内的数据进行了加权,能在一定程度上减小月周期因素,但并不能完全剔除,如要完全剔除可以进一步进行差分操作。先用pandas将序列差分好,然后在对差分好的序列进行ARIMA拟合。


从上面的统计检验结果可以看出,经过12阶差分和1阶差分后,该序列满足平稳性的要求了。
1.ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的移动平均模型;
2. ARMA(7,0)模型:即偏自相关图在滞后7阶之后缩小为0,且自相关缩小至0,则是一个阶层p=3的自回归模型;
3. ARMA(7,1)模型:即使得自相关和偏自相关都缩小至零。则是一个混合模型。
4. ARMA(8,0)模型:即偏自相关图在滞后8阶之后缩小为0,且自相关缩小至0,则是一个阶层p=3的自回归模型;
目前选择模型常用如下准则:
* AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
* BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
* HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
以上四个模型得到的AIC、BIC、HQ数值如下:




通过比较得到ARMA(8,0)各项数值都最小,因此是最佳模型。
通过ARMA(8,0)进行2017年-2018年房屋价格预测,得到结果如下:

可以看到房屋均价基本在135-140浮动,将预测数据与原数据进行对比,此处未对原数据进行平稳性处理,但是可以看出预测准确性还是比较好的,

2.reviews表
文本处理——针对Airbnb房屋评论的情感分析
在listings、calendar和reviews这三张表中,含有多个文本型属性,但是对最终房屋的价格预测影响最大的还是用户对各房屋的评论内容。所以对reviews表中的comments内容通过情感分析进行量化处理,并用于最终的模型建立(价格预测)。具体过程如下:
2.1.文本一级清洗
首先查看reviews表中comments这一属性的缺失值情况:在84849条数据中,仅有17条评论信息是缺失的,占比很小而且作为文本型数据无法进行填补,故做删除缺失值处理。


删除后,在review这张表中剩余84832条完整评论信息。将comments的类型转变为字符型,并利用removewords这一函数去除comments中的标点符号和stopwords中的停用词,通过tolower这一函数将所有的评论信息变成小写形式,最后输出前五条评论内容进行查看:


在利用tolower这一函数时,出现了报错:

经查看,发现comments中的文本内容较脏乱,不仅包含英文,还包含中文和日文等多种语言,但是在84832条评论数据中,除英文以外的字符非常少,而且一般形式表现为其他语言掺杂在英文中,英文仍是每条评论的主体,所以将除英文以外以其他语言形式存在的字符作为异常字符进行删除处理。做法是通过removerwords这一函数去除每条comments中除英文(大小写)和空格以外的字符,表现形式是利用正则表达式:[^A-Za-z0-9 _]

去除异常字符后再将comments中的内容转变为小写形式,并查看前五条评论信息:

从以上两次数据对比可以看出小写转换成功。
2.2.文本二级清洗——词频、词云等可视化展示
为了更方便进行可视化内容,将review表中的comments内容赋给r这一变量。
a.保留词根
首先进行只保留词根(stemming)处理,当同一个单词结尾不同,但是却代表相同的含义的时候,我们通过只保留这些单词词根的方法来去掉冗余。例如argue, argued, argues, 以及 arguing代表的是相同的含义,但是被按照不同的单词来计数,因此可以通过只保留词根的方法,让他们用一个共同的词根argu代替。 故利用tm_map函数通过stemdocument这一功能保留r中的词根:

b.创建单词频率矩阵
利用documenttermmatrix函数建立单词频率矩阵,其中每一行代表每一条评论信息,每一列代表对应推文中出现的一个单词,矩阵中的数值为每个单词在每个观测值中出现的频率(次数)。具体过程和结果如下:

由此可见,frequencies中包含了84807个观测值和45881个单词。

查看第1-10行矩阵内容:

查看出现至少1000次的高频词汇:

(部分高频词汇)
我们可以发现,在45881个单词当中,只有504个词出现的频率不少于1000次,因此我们可以去除一些低频词汇,因为这些低频词汇对于模型预测没有较大的帮助,且其存在会导致大量的计算,进而延长模型运算的时间。
随时关注您喜欢的主题

将低频词汇剔除后,sparse中只包含了839个观测值。
c.画制词云
首先利用tm包中的VCorpus函数把comments的内容作为R对象、保存在内存中,建立动态语料库,然后再通过TermDocumentMatrix函数把comments转化为DTM矩阵形式,最后利用wordcloud包中的wordcloud函数画制评论的词云图像,具体过程和结果如下:


词云图像:

2.3.情感分析并评分
首先从CSDN网站上下载英文的正负面情感词汇的txt文件,导入R中,分别命名为negative(消极)和positive(积极)。并将negative和positive中的词语加上权重(weight),设置negative中的每一个词语的权重(weight)都为-1,positive中的权重(weight)都为1,这也意味着最终评分结果越大说明该条评论越积极,评分越小说明该条评论越消极。,然后再利用cbind函数将negative 和positive通过term这一列名相同的属性合并起来,得到posneg这一带有权重的最终情感数据集。
Negative中含有1011条数据和term、weight两个变量,positive中含有773条数据和term、weight两个变量,posneg中含有1784条数据和term、weight两个变量。

在posneg数据集中建立pn这一空数值型属性表示每条评论文本的情感得分情况。评分过程是利用两个for循环嵌套的形式,外面的循环是针对每一条评论信息进行搜索,里面的循环表示为针对每一条评论信息,将posneg中所有的词语搜索一遍,如果词语在评论信息中,pn(评分)则加上相应的weight值,若不在,pn(评分)则加上0。具体过程如下:

由于是双层嵌套,而且数据量较大,在经过10个多小时的等待后,最终在review表中加上了每条评论的情感分析评分值(pn),结果如下:

2.4.合并listings表
首先将review表中的评分以listing_id为依据对pn(评分)进行分类取均值,并将id和av(平均评分)保存在变量av中。再利用merge函数以id为依据连接listings和av两张表,得到用于最终建立模型的lr数据集。lr中包含3191条数据,与最初的listings数据集相比,少627条数据,说明airbnb网站上的这627个房屋是没有用户对其进行过评论的。

3.listings表——可视化
利用ggplot函数对listings表中的信息进行可视化展示,主要从房屋整体评分、房东可信度、房屋情况、地理位置和评论情况五个角度出发探寻房屋各方面信息之间的关系。具体过程和结果如下:
3.1.房屋整体评分——主成分分析
主成分(PCA)分析的一般步骤如下:根据变量间的相关性来推导结果。用户可以输入原始数据矩阵或者相关系数矩阵到principal()和fa()函数中进行计算,在计算前请确保数据中没有缺失值。
(1)判断要选择的主成分数目(这里不涉及因子分析)。
(2)选择主成分(这里不涉及旋转)。
(3)解释结果。
(4)计算主成分得分。
接下来就对我们处理好的数据进行主成分分析,对于3190个房屋,我们通过princomp()函数得到27个主成分,接下来对这些主成分进行筛选。

下图中proportion of variance是它本身对原本所有数据的方差的解释程度,你可以理解为,这个成分包含了原始数据中12.38995%的信息;图中的Loadings那个矩阵就是由相关系数矩阵的特征向量按列组成的,比如Comp.1就是y=0.103*host_since -0.103*host_total_listings_count-0.102*property_type+0.226*room_type-0.298*accommodates-0.343*bathrooms-0.428*bedrooms-0.434*beds-0.298*amenities-0.352*guests_included-0.156*extra_people。




接下来根据碎石图确定主成分个数,一般选择折线中最陡的作为主成分:

根据上图,我们可以看到在1.0以上的主成分较多,而且图中并没有显示完整所有的主成分,于是我们简单地将proportion of variance累计加总超过80%的作为我们需要的主成分,经过计算,我们保留comp.1-comp.17。
接下来我们利用predict()函数计算得到各个样本主成分的数据:

那么最终的指标,就应该是:
a * Comp.1 + b * Comp.2 + c * Comp.3的形式,a、b、c的系数根据方差解释度加权计算。每个主成分的方差解释度就是权重。于是最终得到的结果是:0.144685474*comp1+0.103517783*comp2+0.088334388*comp3+0.080439282*comp4+0.064441851*comp5+0.059679916*comp6+0.054120375*comp7+0.049404508*comp8+0.047919824*comp9+0.043365062*comp10+0.042361952*comp11+0.042054807*comp12+0.040463786*comp13+0.038121588*comp14+0.036172379*comp15+0.032646371*comp16+0.032270655*comp17。
我们可以直接用comp1-comp17作为变量组合进行后续的回归等分析,也可以直接用上面的式子对房屋状况进行打分,分数越高,房子的评价也就越好,我们对前六所房子的打分如下:

3.2. 房东可信度
a.利用变量host_verifications、host_response_rate和host_is_superhost三个变量绘制点图,host_verifications作为x轴,host_response_rate作为y轴,点的不同颜色表示为host_is_superhost不同的值。

从上图可以看出:房东的认证方式越多,平均反应速度越快,可信度越高,而且普遍来看,大房东的平均反应速度快于二房东的平均反应速度。
b.房东入驻airbnb年份统计:
以对host_since进行年份提取后的变量year作为x轴,统计不同年份入住的房东人数并进行对比,结果如下:

从上图可以看出:airbnb的房东入驻人数是在逐年上升的,这说明该平台在不断的壮大,发展前景和趋势很好。但是增加的幅度却在减小,市场竞争压力大,在一定意义上,提醒着airbnb企业关注房屋资源的饱和度问题。
3.3. 地理位置——地理位置对价格的影响程度:
以经度作为x轴,维度作为y轴绘制点图,在平面图中以点的形式表现房屋的位置信息,并通过“color=price”这一表达式,以点的颜色深浅表示price的变化情况,结果如下:

从上图可以看出:房屋主要集中在中间地带,而且价格变化并不剧烈,一般都在250美元以下。
3.4. 房屋情况
a.针对不同房屋类型、房间类型的频数展示
以property_type作为x轴,对3818个房屋的类型进行频数展示,再用不同的颜色表示不同的room_type(房间类型)对每个房屋类型中的房间类型进行划分,结果如下:

从上图可以看出:apartment和house的房屋类型占比最大,而在不同的房屋类型中,房间类型的分布各不相同,但entire home/apt和private room的分布最为广泛。
b.房屋类型与价格的关系
以room_type作为x轴,property_type作为y轴,price作为color,展示房屋、房间的种类对房屋租赁价格的影响,结果如下:

虽然价格的变化并不是很明显,但从上图仍可以看出不同的房间、房屋种类对房屋价格的影响程度。例如相对来说,entire home/apt的房间种类的价格偏高一些;Dorm这一房屋类型只包含shared room这一种房间类型,而且租赁价格很低。
c.最多最少居住时间和价格
以价格作为x轴,房屋的最多、最少居住天数之差作为y轴,绘制柱形图,探寻不同价格的房屋所允许的居住天数变化范围大小情况,结果如下:

从上图可以看出:价格越高的房屋允许居住天数的变化范围越小,价格越低的变化范围越大。这说明有些价格低的房屋可能是以居住时间的灵活性作为竞争优势来吸引用户,而价格高的房屋往往是由于自身的房屋条件和质量好,所以对居住时间的要求较严格。
d.房屋所含房间数量和设备数量:
以amenities(电视、空调等设备数量)作为x轴,acoommodates(房屋包含的房间数量)作为y轴,通过绘制点图探寻两者之间的关系,结果如下:

从上图可以看出:amenities和acoommodates之间呈线性正相关的关系,房间的数量越多,房屋的设备越齐全,符合实际情况。
e.房屋价格的频数统计:
以price作为x轴,统计这3818个房屋的价格分布情况。结果如下:

从上图可以看出:price的分布确实以较小数值(低价格)为主,80%以上的房屋价格都在200美元以内。
3.5.评论情况
评论平均评分和价格的关系:
通过对reviews表中comment的打分,我们得出用户对listings中3818个房屋的平均评分情况——av。以av为x轴,price为y轴,绘制点图,探寻用户评分对于房屋价格的影响,结果如下:

从上图可以看出:用户评分对价格的影响并不大,影响更多的可能是用户对于同等价位房屋的选择,此外,在airbnb的网站上仍存在用户评分很高,但是价格并不高的物美价廉的房屋。
五、数据进一步处理
主要针对reviews和listings合并后的lr数据集做进一步的处理和填补,为建立最终的预测模型做准备。
1.转换
将分类属性转变为因子型
Lr的28个属性中,还包含一些分类属性,例如:host_is_superhost中含有t和f两类,利用factor将其转变为因子型,再通过as.numeric进行数值化转换,最终将分类属性量化成数字形式。由于这些分类属性中所含的类别较少,一般2~3类,故不需进行亚变量处理。此类变量有:is_location_exact、host_identity_verified、cancellation_policy和host_is_superhost。
2.填补
首先因为拿到手的数据集比较脏,里面不仅有明显的含有空值的数据,还有通过文本显示为空的数据,于是我们先将文本型的“NA”、“N/A”统一转化为NA。通过mice包中的md.pattern函数和aggr函数我们可以看到经过变量删除后的缺失值情况:

可以看到缺失值大概占一个属性的15%左右,这是我们可以接受的;而且缺失值集中地分布在几个属性值中,我们可以推测这几个属性的数据是一起缺失的,具有较高的相关性,经过观察,我们发现这些一起缺失的属性都跟评论有关,或许是因为这些房子刚刚投入Airbnb使用,尚未有人居住过。于是我们先对其他属性中零星的缺失值(仅缺失1-2条的数据)进行简单的删除处理,经过此步还有3190条数据。
接下来通过corrplot包对缺失值之间的相关性进行一个分析,将lr中的数据根据是否缺失转化为0-1矩阵后,在这个矩阵中仅留下含缺失值的列,可视化结果如下:

通过图形,我们可以确切地看到所有关于reviews的数据缺失值的相关性已经高度接近1了,但如果采用对所有关于reviews的属性进行补缺,或许得到的完整的数据集可信度不高。经过讨论,我们决定将这些有关评论的属性进行直接删除,因为通过下文的文本挖掘处理,我们能直接得到关于评论的一个平均分数。于是在这一步仅对bedrooms,bathrooms,host_response_rate进行缺失值的插补。
对于bedrooms和bathrooms,因缺失值较少,我们仅进行均值插补处理,sub <- which(is.na(lr$bathrooms)),sub中存储了bathrooms中有缺失的行数,lr1存储了bathrooms无缺失值的整个数据集的子集,而lr2中存储了仅有缺失值的子集。
 通过avg_sales得到的均值,对lr2中的缺失值进行填补,再将lr1和lr2组合起来,得到补全后的数据集,对bedrooms的补缺同理。
通过avg_sales得到的均值,对lr2中的缺失值进行填补,再将lr1和lr2组合起来,得到补全后的数据集,对bedrooms的补缺同理。
而对于host_response_rate,因缺失值高达300余条,我们采用mice包中的函数进行多重插补处理。通过mice()函数利用平均值插补法生成了五个完整的数据集,提取其中的第三个作为我们的最终结果。
六.建模与分析过程
1.自相关分析
对最终数据集lr(listings和reviews连接后)中的28个属性绘制自相关图,结果如下:

从上图可以看出,accommodates和amenities的相关性很大,number_of_reviews和reviews_per_month的相关性很大,所以在对price进行影响因素分析和预测时,可能存在自相关问题。
2.影响因素分析
采用线性回归的方式分析l中各变量对price的影响,并分别选取影响程度大的变量组成新的数据集l,用于对两者模型的建立和预测。


对price影响大的变量有host_is_superhost、longitude、property_type、room_type、bathrooms、bedrooms、beds、guests_included、reviews_per_month这九个变量。整个线性回归模型的R^2为0.5622,调整后为0.5587,并不是很大。此外,在对price的影响自变量进行挑选过程中,剔除掉了自相关性很强的变量,正好解决了上述的自相关问题。
3.划分训练集和测试集
首先进行训练集和测试集的划分,以7:3的比例将数据集listings1分为训练集train和测试集test。

4.建立模型
Price属于连续型数值变量,不能够像分类型变量一样简单地通过table这一操作才评估模型的好坏。因此,在评估price预测模型时,我们选择用R^2和MSE来评估,具体公式如下:


(MSE) (R^2)
4.1.回归分析
由于price是连续型变量,我们采用线性回归模型进行分析,通过lm()函数对测试集进行预测。

调整后的R^2=0,5534,说明线性回归模型的拟合效果一般。
4.2.lasso分析
Lasso回归又称为套索回归,是Robert Tibshirani于1996年提出的一种新的变量选择技术。Lasso是一种收缩估计方法,其基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,进一步得到可以解释的模型。R语言中有多个包可以实现Lasso回归,这里使用lars包实现。

可以看到lasso回归得到的模型拟合度为0.553,较低。框中部分为自变量加入模型的顺序,下图为这个过程的可视化展示。从这个过程中我们发现很有意思的一点是卧室的数量,其次是床的数量对于房屋的价格有着较高的影响,但是房东本人的一些数据反而对房屋价格影响不大,也就是说一个房屋的价格还是更多收到房屋本身的影响,而不怎么受到房东个人品质等的影响,不过这个结果也是情理之中的。

4.3.随机森林
考虑采用随机森林模型对price这一连续型变量进行预测。
首先确定随机森林中包含的最优决策树数量——ntree:


根据上图中的结果显示,在决策树的数量等于200时,曲线稍微出现波动,200过后,趋于平缓,所以选择200作为ntree的值。
建立模型并查看模型变量的重要性以及模型的R^2和MSE值



结果显示,随机森林模型的R^2为0.615,虽然相比线性回归模型,R^2更大一些,但拟合效果仍不是很好。随机森林在解决回归问题时,确实没有像分类时表现的那么好,可能因为它并不能给出一个连续的输出。当进行回归时,随机森林不能够做出超越训练集数据范围的预测,这可能导致在某些特定噪声的数据进行建模时出现过度拟合。
Python分析Airbnb 数据:洞察市场差异、价格因素与旅行价值|附数据代码
本文通过对 Airbnb 数据的深入分析,旨在探讨不同城市间 Airbnb 市场的差异、影响价格的主要因素、评价数据中的趋势和季节性,以及哪个城市提供更高的旅行价值。使用 Python 编程语言和相关数据分析库,对大量的 Airbnb 房源和评价数据进行处理和可视化,以得出有价值的结论。
引言
随着共享经济的兴起,Airbnb 作为全球知名的短租平台,在旅游和住宿领域发挥着重要作用。了解不同城市的 Airbnb 市场特点、价格影响因素以及评价趋势,对于旅行者、房东和平台运营者都具有重要意义。本文将通过对 Airbnb 数据的详细分析,回答以下四个关键问题:
- 不同城市的 Airbnb 市场有哪些主要差异?
- 哪些属性对价格影响最大?
- 能否在评价数据中识别出趋势或季节性?
- 哪个城市提供更好的旅行价值?
数据来源与处理
(一)数据来源
本文使用的 Airbnb 数据包含房源列表(Listings.csv)和评价数据(Reviews.csv)。这些数据涵盖了多个城市的 Airbnb 房源信息和用户评价。
(二)数据处理步骤
- 导入库:首先导入必要的 Python 库,包括
numpy、pandas、datetime、matplotlib.pyplot和seaborn等,用于数据处理、分析和可视化。
import numpy as np import pandas as pdimport datetime as dtimport matplotlib.pyplot as pltimport seaborn as sns- 加载数据集:使用
pandas库读取房源列表和评价数据文件,设置适当的编码和内存参数,以确保数据能够正确加载。
# 加载房源数据集listings = pd.read_csv("/input/airbnb-listings-reviews/Airbnb Data/Listings.csv", encoding='latin', low_memory=False)# 加载评价数据集reviews = pd.read_csv('/input/airbnb-listings-reviews/Airbnb Data/Reviews.csv')- 数据类型转换和内存优化:检查房源数据的信息,确定数据类型和内存使用情况。将某些列的数据类型转换为分类数据类型,以减少内存占用。
# 查看房源数据信息listings.info()# 将特定列转换为分类数据类型cat_cols = ['host_is_superhost', 'host_has_profile_pic', 'host_identity_verified', 'neighbourhood', 'district', 'city', 'property_type', 'room_type', 'instant_bookable']listings[cat_cols] = listings[cat_cols].astype('category')# 再次查看房源数据信息listings.info()- 检查重复值和空值:检查数据中是否存在重复行和空值。确保数据的完整性和准确性,以便进行后续分析。
# 检查重复行duplicates = listings[listings.duplicated()]# 检查特定列中的空值check_nulls = ['listing_id', 'name', 'host_id', 'host_since', 'host_location', 'host_response_time', 'host_response_rate', 'host_acceptance_rate', 'host_is_superhost', 'host_total_listings_count', 'host_has_profile_pic', 'host_identity_verified', 'neighbourhood', 'district', 'city', 'latitude', 'longitude', 'property_type', 'room_type', 'accommodates', 'bedrooms', 'amenities', 'price', 'minimum_nights', 'maximum_nights', 'review_scores_rating', 'review_scores_accuracy', 'review_scores_cleanliness', 'review_scores_checkin', 'review_scores_communication', 'review_scores_location', 'review_scores_value', 'instant_bookable']null_data = listings[listings[check_nulls].isnull().all(axis = 1)]- 日期列处理:将房源数据中的
host_since列转换为日期时间类型,并添加一个新的year_month列,用于后续的时间序列分析。
# 将 host_since 列转换为日期时间类型listings['host_since'] = pd.to_datetime(listings['host_since'])# 添加 year_month 列listings['year_month'] = listings["host_since"].dt.to_period('M')- 数据合并:将房源数据和评价数据按照
listing_id进行合并,以便进行综合分析。
# 合并房源和评价数据df = listings.merge(reviews, how = 'inner', on = 'listing_id')# 添加月份列df['month'] = pd.to_datetime(df['date']).dt.monthdf.info()问题分析与结果
(一)不同城市的 Airbnb 市场差异
- 分析方法:通过对不同城市的房源按照是否可即时预订进行分组计数,并绘制柱状图,直观地展示不同城市之间的差异。
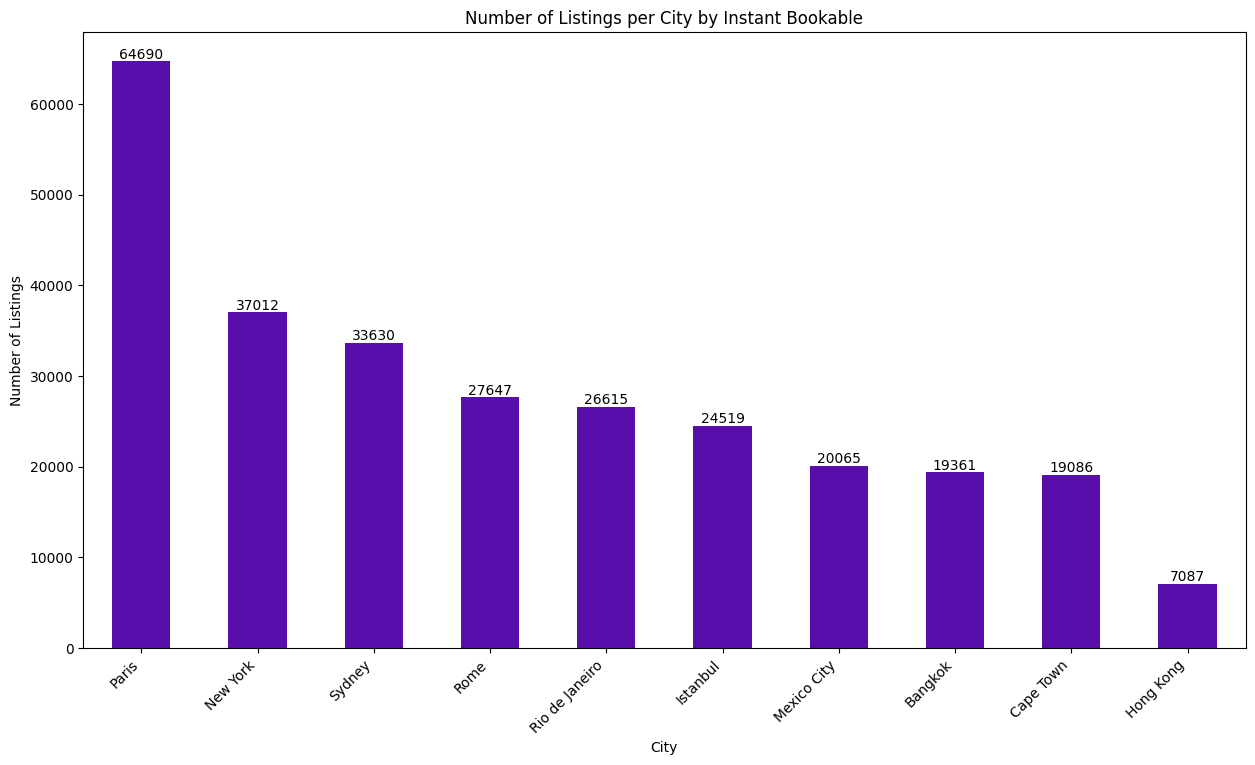
# 按城市分组统计即时预订房源数量并排序city_instantbookable = listings.groupby('city')['instant_bookable'].count().sort_values(ascending=False)print(city_instantbookable)# 绘制柱状图plt.figure(figsize=(15,8))city_instantbookable.plot(kind='bar', color='#570eab')plt.title('Number of Listings per City by Instant Bookable')plt.xlabel('City')plt.ylabel('Number of Listings')plt.xticks(rotation=45, ha='right')for i, v in enumerate(city_instantbookable): plt.text(i, v, str(v), ha='center', va='bottom')plt.show()- 结果解读:巴黎的即时预订房源数量最多,达到 64690 个,而香港的即时预订房源数量最少,为 7087 个。这表明巴黎在 Airbnb 市场上的活跃度较高,而香港的市场相对较小。
(二)影响价格的因素
- 分析方法:首先确定与价格相关的数值型列,创建新的数据框。然后计算这些列与价格列之间的相关性矩阵,并对矩阵进行排序,找出与价格相关性最高的属性。同时,绘制热力图,直观地展示各个属性与价格之间的相关性。
收起
plaintext
复制# 创建数值型列列表numerics = ['accommodates', 'bedrooms', 'minimum_nights', 'maximum_nights','review_scores_rating', 'review_scores_accuracy', 'review_scores_cleanliness', 'review_scores_checkin', 'review_scores_communication', 'review_scores_location', 'review_scores_value']# 创建新的数据框numeric_df = listings[numerics + ['price']]# 计算相关性矩阵correlation_matrix = numeric_df.corr()# 按价格相关性排序price_correlation = correlation_matrix['price'].sort_values(ascending=False)print(price_correlation)# 绘制热力图plt.figure(figsize=(10,8))sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')plt.title('Attributes Correlation with Price')plt.show()

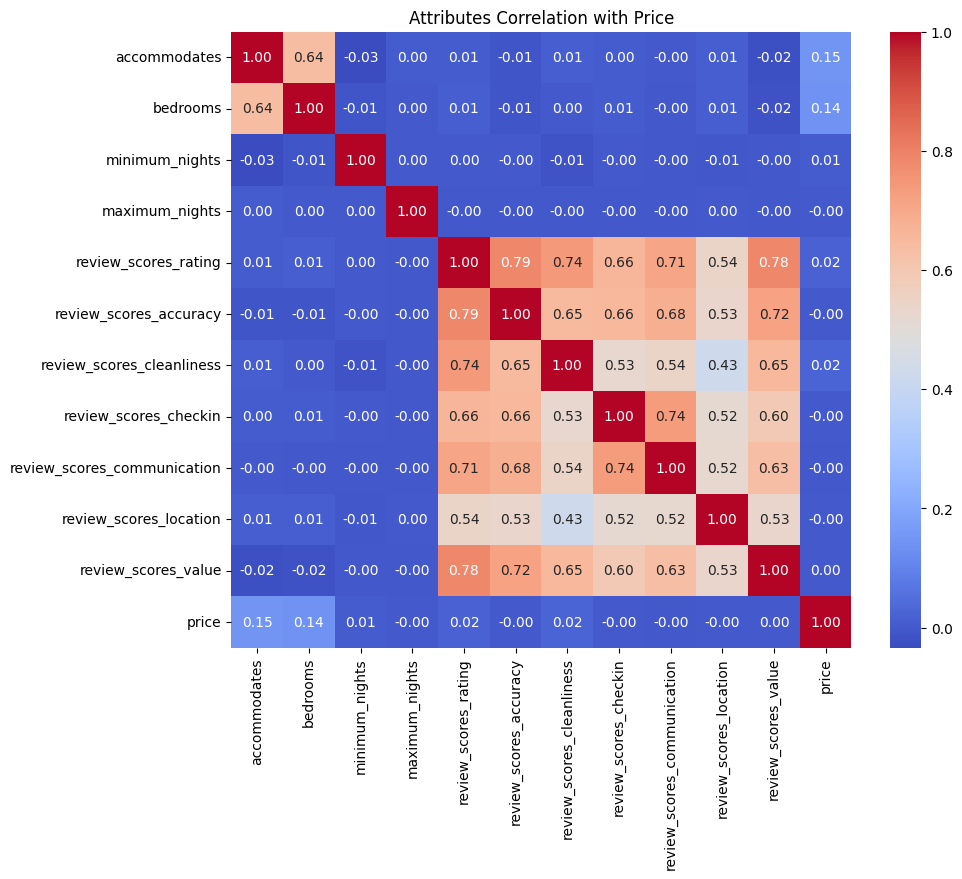
- 结果解读:从相关性矩阵可以看出,评价分数中的清洁度、可容纳人数和卧室数量与价格的相关性较高。这表明这些因素对 Airbnb 房源的价格有较大的影响。
(三)评价数据中的趋势和季节性
- 分析方法:首先统计每个月加入 Airbnb 的房东数量,绘制时间序列图,观察房东加入的趋势。然后统计每天的预订数量,并按月份绘制预订数量的折线图,分析预订的季节性。
# 统计每个月加入的房东数量hosts_per_month = df['year_month'].value_counts().sort_index()# 绘制房东加入趋势图plt.figure(figsize=(10,6))hosts_per_month.plot(kind='line', marker='.', color='#051399')plt.title('Number of Hosts Joined Airbnb Overtime')plt.xlabel('Year-Month')plt.ylabel('Number of Hosts Joined')plt.xticks(rotation=45)plt.grid(True)plt.show()# 统计每天的预订数量datewise_bookings = df['date'].value_counts().sort_values(ascending=False)# 按月份绘制预订数量折线图df.groupby('month').agg('month').count().to_frame().plot(kind='line', figsize=(15,8), linewidth=2, marker='o', color='#e69305')plt.title('Montly Trend of Airbnb Bookings')plt.xlabel('Months')plt.ylabel('No: of Bookings')plt.xticks(range(1,13))plt.show()
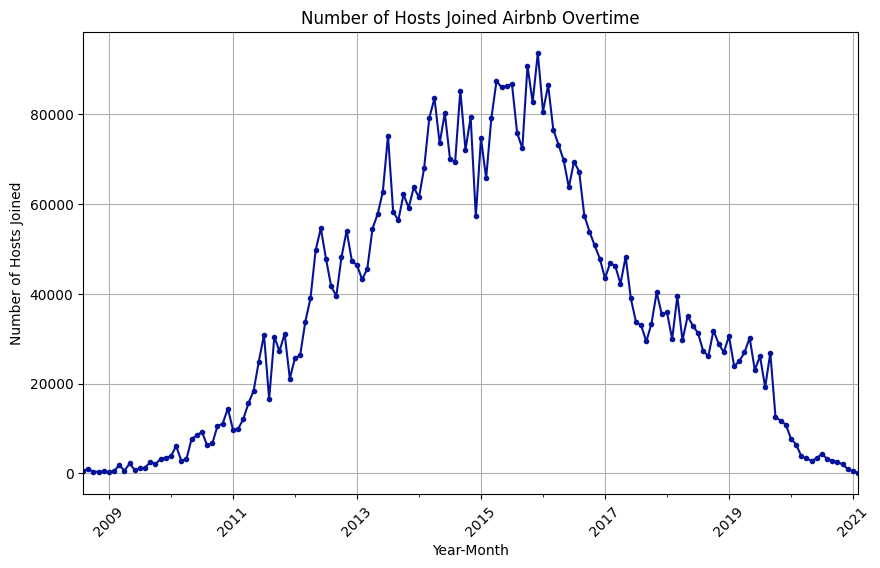
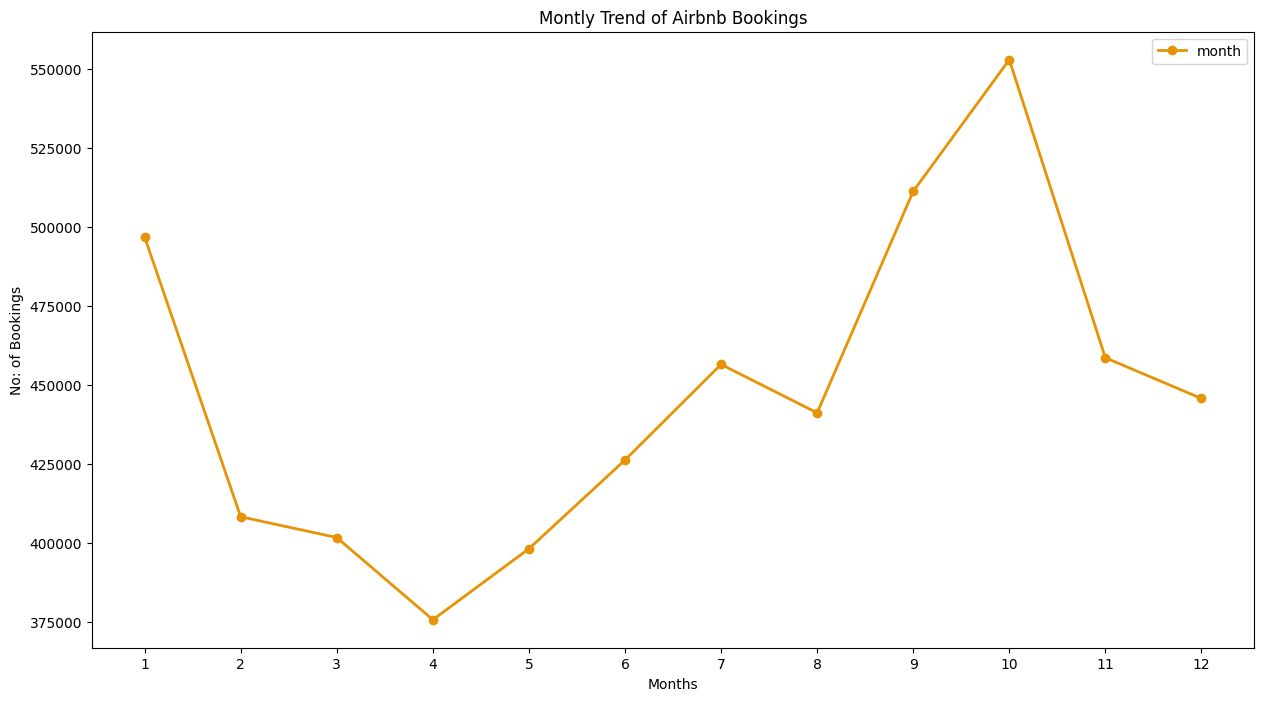
- 结果解读:从房东加入趋势图可以看出,2015 年和 2017 年有大量房东加入 Airbnb,但在 2017 年出现了下降趋势。从预订数量折线图可以看出,9 月和 10 月的预订数量较多。
(四)哪个城市提供更好的旅行价值
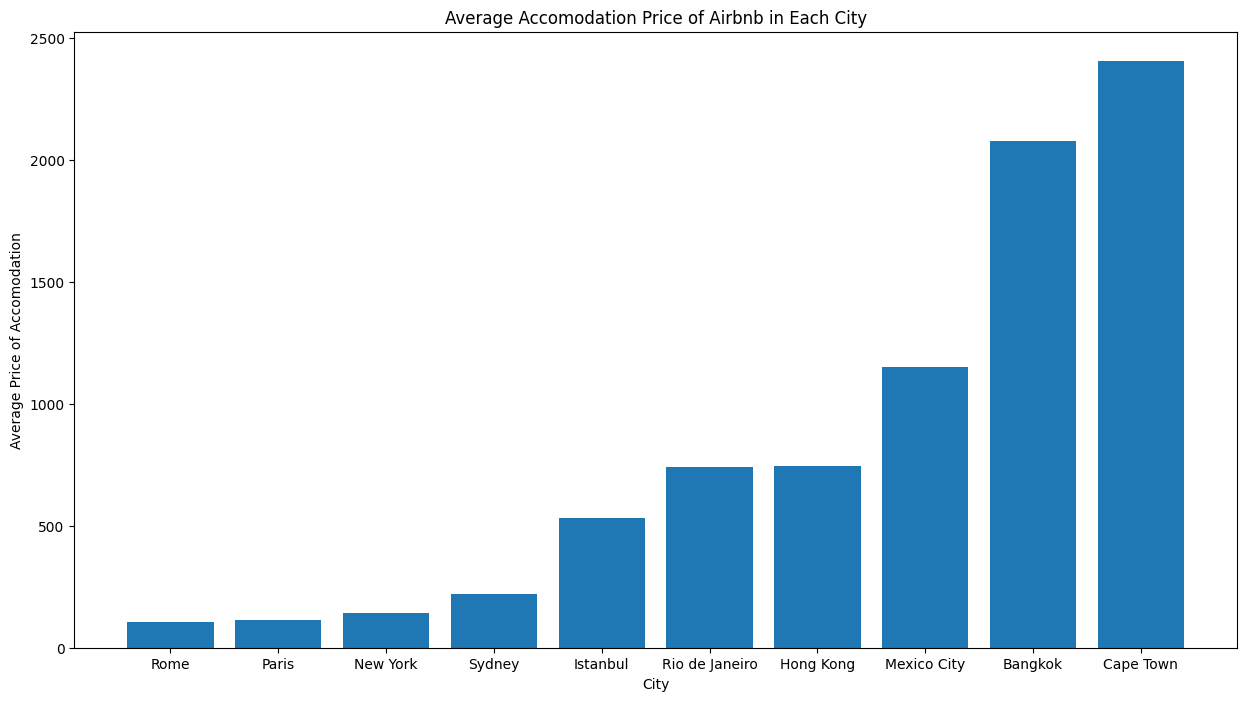
- 分析方法:计算每个城市的平均住宿价格,绘制柱状图,比较不同城市的价格水平。
# 计算每个城市的平均价格avg_price_city = listings.groupby('city')['price'].mean().sort_values()print(avg_price_city)# 绘制平均价格柱状图plt.figure(figsize=(15,8))plt.bar(avg_price_city.index, avg_price_city.values)plt.title('Average Accomodation Price of Airbnb in Each City')plt.ylabel('Average Price of Accomodation')plt.xlabel('City')plt.show()- 结果解读:开普敦的平均住宿价格最高,而罗马的平均住宿价格最低。因此,罗马提供了更好的旅行价值。
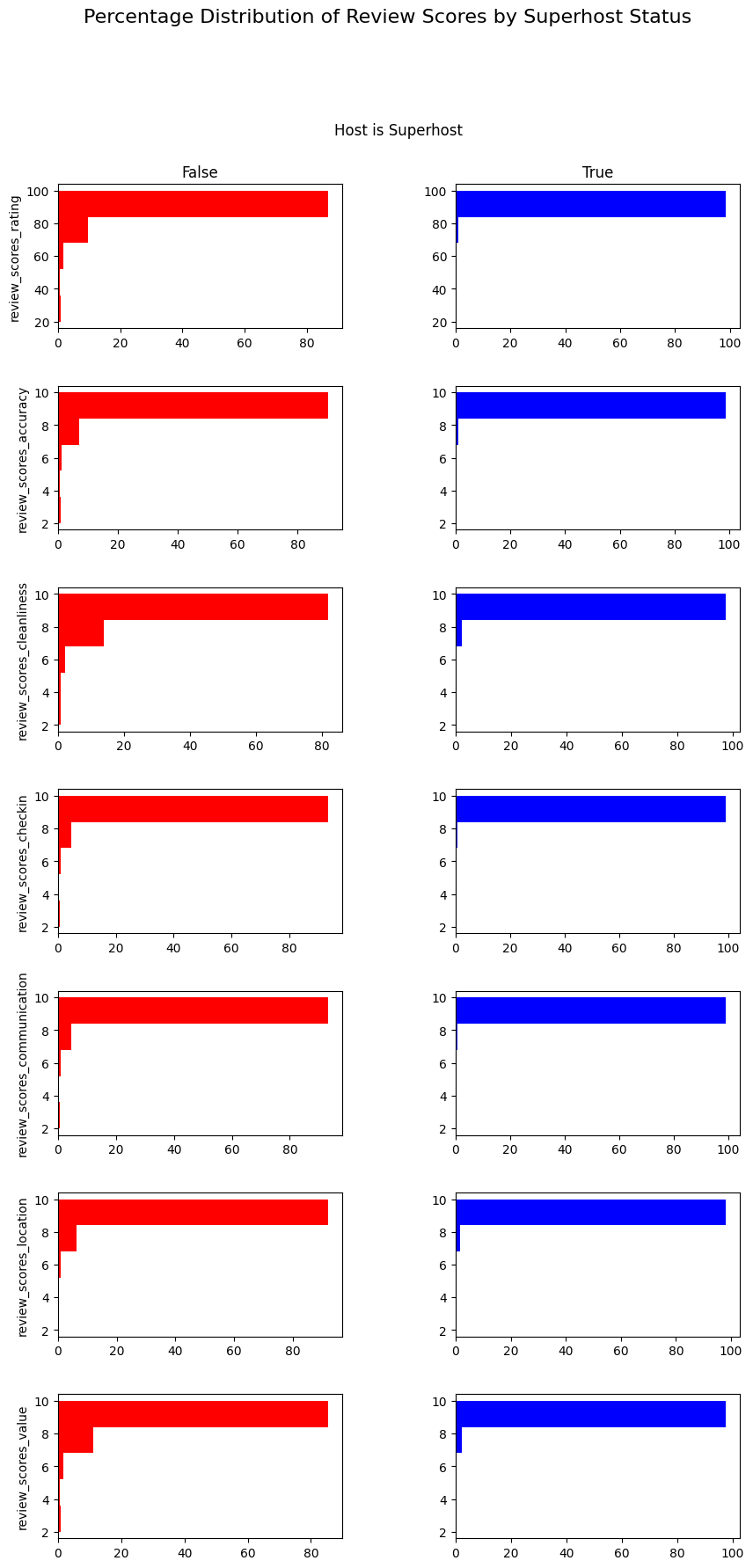
评价分数分布与超级房东状态分析:
首先,从listings_table表中选择与评价分数相关的列和房东是否为超级房东的列,创建Q3_df数据框。
然后,使用plotly.graph_objects和matplotlib.pyplot库分别创建子图和直方图,展示不同超级房东状态下各评价分数的百分比分布。review_scores_columns = [i for i in listings_df.columns if 'review_score' in i]print(review_scores_columns)Q3_df = duckdb.sql('''SELECT host_is_superhost, review_scores_rating as review_scores_rating, review_scores_accuracy, review_scores_cleanliness, review_scores_checkin, review_scores_communication, review_scores_location, review_scores_valueFROM listings_table''').to_df()# 使用 plotly 创建子图fig = make_subplots( rows=len(review_scores_columns), cols=2, subplot_titles=('False', 'True'), vertical_spacing=0.05)# 使用 matplotlib 创建直方图fig, axes = plt.subplots(nrows=len(review_scores_columns), ncols=2, figsize=(10, 20))
香港地区房源分析
通过查询listings_table表,筛选出城市为香港(Hong Kong)的房源数据,创建hong_kong_listings_df数据框。
使用geopandas库将数据转换为地理数据框,并绘制香港地区的房源分布地图,同时添加底图。
使用folium库创建香港地区的交互式地图,展示房源位置。duckdb.sql('''SELECT *FROM listings_tableWHERE lower(city) like '%hong%'limit 2''').to_df()hong_kong_listings_df = duckdb.sql('''SELECT *FROM listings_tableWHERE city = 'Hong Kong'''').to_df()# 转换为地理数据框并绘制地图gdf = gpd.GeoDataFrame( hong_kong_listings_df, geometry=gpd.points_from_xy(hong_kong_listings_df.longitude, hong_kong_listings_df.latitude))gdf.crs = "EPSG:4326"fig, ax = plt.subplots(figsize=(10, 10))gdf.plot(ax=ax, color='blue', marker='o', markersize=10)try: ctx.add_basemap(ax, crs=gdf.crs.to_string(), source=ctx.providers.Stamen.Terrain)except AttributeError: ctx.add_basemap(ax, crs=gdf.crs.to_string(), source=ctx.providers.OpenStreetMap.Mapnik)ax.set_xlim(113.8, 114.4)ax.set_ylim(22.15, 22.6)ax.set_title("Points over Hong Kong Map")ax.axis('off')plt.show()# 创建交互式地图map_hk = folium.Map( location=[22.3193, 114.1694], zoom_start=12, tiles='https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', attr='Map data © OpenStreetData contributors')for _, row in hong_kong_listings_df.iterrows(): folium.CircleMarker( location=[row['latitude'], row['longitude']], radius=5, color='blue', fill=True, fill_color='blue', fill_opacity=0.7, ).add_to(map_hk)map_hk.save('HongKongMap.html')map_hk

房源价格预测模型研究|附数据代码
随着共享经济的快速发展,Airbnb 作为全球知名的短租平台,其房源价格的合理预测对于房东制定价格策略、租客选择合适房源以及平台的运营管理都具有重要意义。本文通过对 Airbnb 房源数据的深入分析,构建不同的回归模型,以提高对房源价格预测的准确性。
数据来源与预处理
- 数据来源:数据来源于
../data/listings_cleaned.csv文件,以房源的唯一标识id作为索引列。 - 数据预处理:
- 删除列:确定要删除的列,如
security_deposit、availability_365、maximum_minimum_nights、minimum_maximum_nights等,通过以下代码实现删除操作:
- 删除列:确定要删除的列,如
to_drop = ['security_deposit','availability_365','maximum_minimum_nights','minimum_maximum_nights']data = data.drop(to_drop,axis=1)- 数据标准化:使用
StandardScaler对数据进行标准化处理,使不同特征具有相同的尺度。例如:
scaler = StandardScaler()X_scaled = scaler.fit_transform(X)y_scaled = scaler.fit_transform(y.values.reshape(-1,1))- 数据集划分:将数据划分为训练集和测试集,使用
train_test_split函数,设置随机种子为 0,测试集比例为 0.25。代码如下:
X_train, X_test, y_train, y_test = train_test_split(X_scaled,y_scaled, random_state=0,test_size = 0.25)
回归模型构建与评估
线性回归:
使用LinearRegression构建线性回归模型,并在训练集上进行训练,然后在训练集和测试集上分别进行预测。通过计算r2_score评估模型性能。代码如下:
linreg = LinearRegression()linreg.fit(X_scaled,y_scaled)y_train_pred = linreg.predict(X_train)y_test_pred = linreg.predict(X_test)print("\nTraining r2:", round(r2_score(y_train, y_train_pred),4))print("Validation r2:", round(r2_score(y_test, y_test_pred),4))- 结果显示,训练集和验证集的
r2值分别为一定数值,表明线性回归模型在一定程度上能够解释房源价格的变化。
Lasso 回归:
通过LassoCV进行 Lasso 回归,设置不同的alpha值范围进行交叉验证,找到最佳的alpha值。
alphas = 10**np.linspace(-2,4,200)lasso = LassoCV(alphas=alphas,cv=10).fit(X_train,y_train.ravel())print("Score without interactions: {:.4f}".format(lasso.score(X_test, y_test)))print('Best alpha value: {:.3f}'.format(lasso.alpha_))- 还绘制了 LASSO 路径图,展示系数随正则化程度的变化。
alphas, _, coefs = lars_path(X_train, y_train.ravel(), method='lasso')xx = np.sum(np.abs(coefs.T), axis=1)xx /= xx[-1]plt.figure(figsize=(12,8))plt.plot(xx, coefs.T)ymin, ymax = plt.ylim()plt.vlines(xx, ymin, ymax, linestyle='dashed')plt.xlabel('|coef| / max|coef|')plt.ylabel('Coefficients')plt.title('LASSO Path')plt.axis('tight')plt.legend(X.columns,loc = 'best')plt.show()- 结果表明 Lasso 回归在一定程度上能够进行特征选择,提高模型的解释性。


带有多项式特征的回归:
- 分别构建带有多项式特征的 Lasso 回归和 Ridge 回归模型。首先使用
PolynomialFeatures生成多项式特征,然后分别使用LassoCV和RidgeCV进行回归。


Ridge 回归:
使用RidgeCV进行 Ridge 回归,设置不同的alpha值范围进行交叉验证。代码如下:
ridge = RidgeCV(normalize=False,alphas=alphas,cv=10).fit(X_train, y_train) print("R^2 Score: {:.4f}".format(ridge.score(X_test, y_test)))print('Best alpha value: {:.3f}'.format(ridge.alpha_))- 结果显示 Ridge 回归也能够在一定程度上提高模型的性能。
带有多项式特征的回归:
分别构建带有多项式特征的 Lasso 回归和 Ridge 回归模型。首先使用PolynomialFeatures生成多项式特征,然后分别使用LassoCV和RidgeCV进行回归。代码如下:poly = PolynomialFeatures(degree=2).fit(X_train)X_train_poly = poly.transform(X_train) X_test_poly = poly.transform(X_test)alphas = 10**np.linspace(-2,2,100)lasso = LassoCV(alphas=alphas,cv=5,tol=0.5).fit(X_train_poly, y_train.ravel()) y_train_pred = lasso.predict(X_train_poly)y_test_pred = lasso.predict(X_test_poly)print("Lasso Regression with Polynomial Features")print("\nTraining r2:", round(r2_score(y_train, y_train_pred),4))print("Validation r2:", round(r2_score(y_test, y_test_pred),4))poly = PolynomialFeatures(degree=2).fit(X_train)X_train_poly = poly.transform(X_train) X_test_poly = poly.transform(X_test)alphas = 10**np.linspace(-2,2,100)ridge = RidgeCV(normalize=True,alphas=alphas,cv=5,).fit(X_train_poly, y_train.ravel()) y_train_pred = ridge.predict(X_train_poly)y_test_pred = ridge.predict(X_test_poly)print("Ridge Regression with Polynomial Features")print("\nTraining r2:", round(r2_score(y_train, y_train_pred),4))print("Validation r2:", round(r2_score(y_test, y_test_pred),4))
带有多项式特征的回归模型在一定程度上可以提高模型的拟合能力,但也可能存在过拟合的风险。
XGBoost:
使用xgb.XGBRegressor构建 XGBoost 回归模型,设置目标函数为reg:squarederror,学习率、最大深度等参数。代码如下:
xg_reg = xgb.XGBRegressor(objective ='reg:squarederror', learning_rate = 0.15, max_depth = 4, booster='gbtree')xg_reg.fit(X_train,y_train)y_train_pred = xg_reg.predict(X_train)y_test_pred = xg_reg.predict(X_test)print("XGBoost")print("\nTraining r2:", round(r2_score(y_train, y_train_pred),4))print("Validation r2:", round(r2_score(y_test, y_test_pred),4))fig, ax = plt.subplots(figsize=(14, 8))plot_importance(xg_reg, ax=ax)XGBoost 模型在训练集和测试集上的表现相对较好,通过绘制特征重要性图,可以了解各个特征对房源价格的影响程度。

结论
通过对 Airbnb 房源和评价数据的分析,我们得出以下结论:
- 巴黎和纽约的 Airbnb 预订数量最多,香港的预订数量最少。
- Airbnb 的价格受到评价分数、清洁度、可容纳人数和卧室数量等因素的影响。
- 2015 年至 2017 年期间,加入 Airbnb 的房东数量大幅增加,但在 2017 年出现了下降趋势。9 月和 10 月是 Airbnb 预订的高峰期。
- 罗马提供了更好的旅行价值,因为其平均住宿价格相对较低,而开普敦的平均住宿价格最高。
- 洗衣机、空调和洗发水是最热门的房源设施。
- 不同城市的房东位置信息中包含城市名称的比例有所不同,纽约、巴黎等城市的比例较高。
- 超级房东在评价分数方面表现相对较好,不同超级房东状态下的评价分数分布存在差异。
- 超级房东的即时预订比例相对较高。
- 香港地区的房源分布可以通过地理数据框和交互式地图进行直观展示。
通过对多种回归模型的构建和评估,我们可以得出以下结论:
- 线性回归、Lasso 回归、Ridge 回归等传统线性模型在一定程度上能够解释 Airbnb 房源价格的变化,但性能相对有限。
- 带有多项式特征的回归模型可以提高模型的拟合能力,但需要注意过拟合的风险。
- XGBoost 模型在训练集和测试集上的表现相对较好,具有较高的预测准确性和泛化能力。
分析师
在此对Kefan Y对本文所作的贡献表示诚挚感谢,她在上海财经大学完成了信息管理与信息系统专业的学位,专注于数据采集、数据清洗和深度学习领域。擅长 R 语言、Python。

关于分析师
Kefan Yu
在此对Kefan Yu对本文所作的贡献表示诚挚感谢,她在上海财经大学完成了信息管理与信息系统专业的学位,专注于数据采集、数据清洗和深度学习领域。擅长 R 语言、Python。
 Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据
Python随机森林、聚类与XGBoost融合模型实现穿戴设备数据身体活动监测与行为分析|附AI智能体、代码和数据 Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据
Python+XGBoost与LangGraph、DeepSeek增强的电商用户好评预测|附AI智能体、代码和数据 Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据
Python Agent多GPU随机变分推断SVI加速层次贝叶斯价格弹性估计|附智能体代码数据 Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据
Python用AI对零售商品层次贝叶斯模型价格弹性估计与个性化定价|附AI智能体、代码和数据

