贝叶斯MCMC模拟是一个丰富的领域,涵盖了各种算法,共同目标是近似后验模型。
例如,使用的rstan包采用了一个Hamiltonian Monte Carlo算法。用于贝叶斯建模的另一个rjags包采用了Gibbs sampling算法。
尽管细节有所不同,但这两种算法都是基于基本的Metropolis-Hastings算法的变体。
主要思想
考虑以下数值结果为Y的正态-正态模型,其围绕未知均值μ的标准差为0.75:
相应的似然函数L(μ|y)和先验概率密度函数f(μ)对于y∈(−∞,∞)和μ∈(−∞,∞)是:
假设我们观察到一个结果Y=6.25。μ的后验模型是具有均值4和标准差0.6的正态分布:
如果我们无法指定μ的后验模型(假装一下),我们可以使用MCMC模拟来近似它。为了了解这是如何工作的,考虑一个潜在的N=5000次迭代的MCMC模拟结果。左侧的轨迹图显示了游览路线或游览站点的顺序,μ(i)。右侧的直方图显示了你在每个μ区域中停留的相对时间。
我们可以通过简单地使用rnorm()从N(4,0.62)后验中直接抽样来实现这个算法。结果是来自后验的一个很好的独立样本,这反过来又产生了一个准确的后验近似:
set.seed(84375) mc_tour <- data.frame(mu = rnorm(5000, mean = 4, sd = 0.6)) ggplot(mc_tour, aes(x = mu)) + geom_histogram(aes(y = ..density..), color = "white", bins = 15) + stat_function(fun = dnorm, args = list(4, 0.6), color = "blue")视频
马尔可夫链蒙特卡罗方法MCMC原理与R语言实现
视频
马尔可夫链蒙特卡罗方法MCMC原理与R语言实现
Metropolis-Hastings算法
用于构建马尔可夫链游览{μ(1),μ(2),…,μ(N)}的Metropolis-Hastings算法在这里得到了规范。我们将始终乐意将我们的游览移动到更合理的后验区域。为了理解情景2,一个小的R模拟是有帮助的。例如,假设我们的马尔可夫游览当前位于位置“3”:
current <- 3然后,要确定下一个游览站点,我们首先通过从Unif(current – 1, current + 1)模型中随机抽样来提出一个位置(步骤1):
set.seed(8)
proposal

重新查看图,我们观察到所提议的点(2.93)的(未归一化的)后验可能性略微低于当前点(3)。我们可以使用dnorm()计算这两个μ的未归一化后验可能性,即f(μ|y=6.25)∝f(μ)L(μ|y=6.25)。
prolaus <- dnorm(osal, 0, 1) * dnorm(6.25, proal, 0.75)
curaus <- dnorm(curnt, 0, 1) * dnorm(6.25, nt, 0.75)
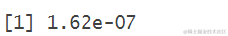
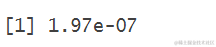
由此可见,尽管不确定,接受并随后移动到所提议位置的概率α的相对高:
alpha <- min(1, prplaus / curr_plaus)
alpha

为了做出最终决定,我们设置了一个加权硬币,它以概率α(0.824)接受提议,并以概率1−α(0.176)拒绝提议。通过sample()函数随机抛掷这个硬币,我们接受了提议,意味着下一点是2.933:
nex_sop <- sape(c(roposl, curet),
size = 1, ob = c(alha, 1-apha))
net_top

这仅仅是对我们的正态后验进行一次Metropolis-Hastings算法迭代的无数可能结果之一。为了简化这个过程,我们将编写自己的R函数one_mh_iteration(),该函数实现从任何给定的当前点开始的单个Metropolis-Hastings迭代,并利用具有任意半宽度w的均匀提议模型。
我们首先指定one_mh_iteration是两个参数的function():均匀分布的半宽度w和当前链值current。
在函数内部,我们执行与上面相同的步骤,并return()三个信息:proposal、接受概率alpha和next_stop。
one_meration <- fntion(w, crret){
# 第一步:提议下一个链位置
prpsal <- runif(1, nt - w, max = crrent+ w)
# 第二步:决定是否移动到新位置
prop_plau <- dnorm(prpoal, 0, 1) * dnorm(625, proosl, 0.75)
curetplaus <- dnorm(cunt, 0, 1) * dnorm(6.25, urent, 0.75)
alpha <- min(1, propoalplaus / current_plaus)
# 返回结果
return(dta.fame(proposa, alph, next_stp))
}
让我们试一试。在种子为8的情况下从当前点3运行onemh_ieration()可以复制上面的结果:
set.seed(8)
one_h_itraton(w = 1, current = 3)
随时关注您喜欢的主题

如果我们使用83这个种子,所提议的下一个点是2.018,对应的接受概率很低,只有0.017:
set.eed(83)
one_mh_itraton(w =1, crrent = 3)

这是有道理的。从图中可以看出,2.018的后验可能性远低于我们当前所在地3的后验可能性。虽然我们确实想要探索这样极端的值,但我们不想经常这样做。事实上,在我们投掷硬币时,提议被拒绝,并且旅游将再次访问位置3。
我们可以确认当所提议的下一个旅游站点(这里是3.978)的后验可能性大于我们当前位置时,接受概率为1,提议将自动接受:
set.seed(7)
onemh_ieratonw = 1, urrnt = 3)

实施Metropolis-Hastings
现在,我们需要一遍又一遍地重复上一个单个迭代的过程来构建一个由N(4,0.62)后验分布组成的Metropolis-Hastings。下面的mh_tour()函数可以构建一个给定长度N的Metropolis-Hastings,利用任何给定半宽度w的均匀提议模型:
mh_tour <- function(N, w){
# 1. 在位置3开始
curet <- 3
# 2. 初始化模拟
mu <- rep(0, N)
# 3. 模拟N个马尔科夫链停止
for(i in 1:N){
# 模拟一个迭代
sim <- onemh_itrationw = w,currnt crrent)
# 记录下一个位置
mu[i] <- si$xt_top
# 重置当前位置
current <- sim$nt_tp
}
# 4. 返回位置
retun(datfrae(tratio= c(:N,mu))
}
在调用此函数时:
- 在位置3处开始,这是一个基于我们对μ的先前了解而做出的相当任意的选择。
- 通过设置“空”向量来初始化模拟,我们最终将在其中存储N次停止的位置(
mu)。 - 利用for循环,在1到
N的每个停留点i中运行on_m_iteaion(),并将结果的next_stop存储在mu向量的第i个元素中。在关闭for循环之前,更新current停止以作为下一次迭代的起点。 - 返回具有迭代号和相应停留点
mu的数据框。
要查看此函数的实际应用,请使用m_our()模拟长度为N = 5000的Markov链,利用半宽度w=1的均匀提议模型:
set.seed(84735)
mh_sulio_1 <- m_our(N = 5000, w = 1)
下面显示了结果的跟踪图和直方图。值得注意的是,产生了对N(4,0.62)后验分布的极其准确的近似。通过严格过程,我们利用了均匀分布的相关采样来近似正态分布。
ggplo= 20) +
stat_fuctin(fun = dnorm,args = ist(4,0.6), color = "blue")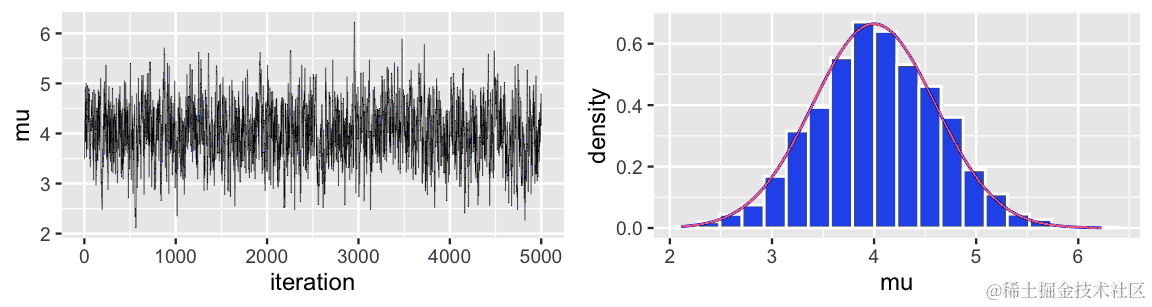
Beta-Binomial模型例子
让我们实现Metropolis-Hastings算法来处理一个Beta-Binomial模型,其中我们观察到在2次尝试中有1次成功,即 Y=1,n=2: 。
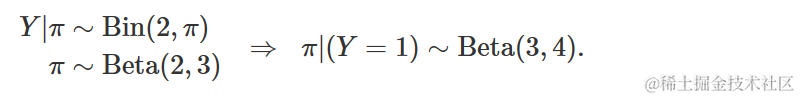
同样,假设我们只能将后验概率密度上定义到某些缺失的归一化常数,
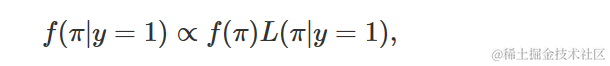
下面的oneiertion()函数实现了该独立采样算法的单次迭代,从任何给定的当前值π开始,并对给定的a和b使用Beta(a,b)建议模型。在计算接受概率α时,请注意我们使用dbeta()来评估先验概率密度函数和建议概率密度函数,以及使用dbinom()来评估具有数据Y=1,n=2,π的二项式似然函数:
one_terton <- function(a, , curnt){
# 第 1 步:提出下一个链位置
proposal <- rbeta(1, a, b)
# 第 2 步:决定
popoal_plas <- deta(prposa, 2, 3) * dbno(1, 2, prosal)
proposlq <- dbeta(prpsal, a, b)
curentplus <- dbea(curet, 2, 3) * dbnom(1, 2, )
curnt_q <- dbeta(curent, a, b)
接下来,我们编写一个betbn_tour()函数,为任何Beta(a,b)建议模型构建一个N长度的Markov链遍历,利用one_iertion()来确定每个停止位置:
beai_tour <- fucton(N, a, b){
# 1. 位置0.5开始链
current <- 0.5
# 2. 初始化模拟
pi <- rp(0, N)
# 3. 模拟N次Markov链停止
for(i in 1:N){
# 模拟一次迭代
sim <- on_ieaion(a = a, b = b, crent = curent)
# 记录下一个位置
pi[i] <- simnet_sop
# 重置当前位置
current <- simnetstop
}
}
我们尝试不同调整的Beta(a,b)建议模型。在这里,为了简单起见,我们使用Beta(1,1),即Unif(0,1)的建议模型进行了5000步的Beta-Binomial后验分布遍历
set.seed(84735)
bebn_im <- betb_tour(N = 5000, a = 1, b = 1)
# 绘制结果
ggplot(beta
总结
本文建立了对基本的Metropolis-Hastings MCMC算法的概念理解。还实现了该算法来研究常见的正态-正态和Beta-Binomial模型。无论是在这些相对简单的单参数模型设置中,还是在更复杂的模型设置中,Metropolis-Hastings算法通过两个步骤之间的迭代产生了后验分布的近似样本:
- 通过从提议概率密度函数中抽取一个新的链位置来提出一个新的位置,这可能取决于当前位置。
- 确定是否接受提议。简单地说,我们是否接受提议取决于其后验可能性相对于当前位置的后验可能性有多有利。
可下载资源
关于作者
Kaizong Ye是拓端研究室(TRL)的研究员。在此对他对本文所作的贡献表示诚挚感谢,他在上海财经大学完成了统计学专业的硕士学位,专注人工智能领域。擅长Python.Matlab仿真、视觉处理、神经网络、数据分析。
本文借鉴了作者最近为《R语言数据分析挖掘必知必会 》课堂做的准备。
非常感谢您阅读本文,如需帮助请联系我们!
 专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据
专题:Python实现贝叶斯线性回归与MCMC采样数据可视化分析2实例|附代码数据 【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用
【视频讲解】R语言海七鳃鳗性别比分析:JAGS贝叶斯分层逻辑回归MCMC采样模型应用 Python用PyMC3马尔可夫链蒙特卡罗MCMC对疾病症状数据贝叶斯推断
Python用PyMC3马尔可夫链蒙特卡罗MCMC对疾病症状数据贝叶斯推断 Matlab贝叶斯估计MCMC分析药物对不同种群生物生理指标数据评估可视化
Matlab贝叶斯估计MCMC分析药物对不同种群生物生理指标数据评估可视化

